GLM-5 发布 14 周后,AMD MI355X SGLang FP8 在 8k/1k 工作负载的大部分单节点 Pareto 前沿上,每百万 token 成本低于 NVIDIA B200 SGLang FP8(从约 10 到约 77 tok/s/user;B200 在约 90 tok/s/user 以上重新反超)。峰值差距为使用 MTP 时在 18 tok/s/user 下达到 1.41 倍(B200 $0.30/M vs MI355X $0.22/M — 降低 40%),不使用 MTP 时在 10 tok/s/user 下达到 1.36 倍($0.31/M vs $0.23/M)。两项测试均使用 SGLang v0.12,MI355X 的 ROCm 软件栈在此版本上已与 B200 的 CUDA 软件栈功能对齐:均支持 MTP 和非 MTP 方案,均支持 FP8 KV 缓存,均基于 SGLang 最新的 TileLang MLA 路径。
这正是关键的节奏。GLM-5 发布后,一个季度内 AMD 就完成了上游 SGLang 内核的合入(sgl-project/sglang PR #21511)及其他优化,并提交了配套的 InferenceX 方案(InferenceX PR #1440),将该模型的 FP8 单节点成本曲线翻转为 AMD 占优。速度就是护城河。
GLM-5 是智谱(ZAI)的 MoE 旗舰模型,于 2026-02-11 发布 — 距本文所述的 InferenceX 测试正好 14 周。该模型拥有 744B 参数的稀疏 MoE 架构,每 token 激活约 40B:256 个专家采用 top-8 路由(约 5.9% 稀疏度),外加共享专家。公开的架构名称为 glm_moe_dsa — 模型在解码路径中集成了 DeepSeek 稀疏注意力(DSA),这与 DeepSeek 在 V3.2 中引入的稀疏注意力模式相同,也是 SGLang 的 TileLang 后端所围绕构建的核心,同时采用多头潜在注意力(MLA)进行 KV 缓存压缩以支持其 200K 上下文窗口。
在 MI355X 上,等效能力在四月中旬通过 SGLang 的 TileLang 后端落地,由此带来的解码吞吐量提升使得 MI355X 较低的单 GPU TCO($1.48/GPU/hr,B200 为 $1.95/GPU/hr,数据来源 SemiAnalysis AI Cloud TCO 模型)得以转化为真正的每 token 成本优势,而非被软件差距所淹没。
推动这一结果的关键优化
AMD 方面的标志性性能优化之一是 sgl-project/sglang PR #21511(由 HaiShaw 提交,2026-04-03 合入)。该 PR 通过 SGLang 的 TileLang 后端为 MI300/MI355 启用了 FP8 KV 缓存和 FP8 注意力内核(在 DeepSeek-V3.2 和 GLM-5 上均已测试),并针对不同硬件代际采用了不同的融合策略:
- 在 MI355 上,该 PR 复用了现有的
fused_qk_rope_cat_and_cache_mla内核来同时处理 Q 和 KV 的 FP8 量化。QK rope 拼接、MLA 缓存写入以及 Q 和 KV 的 FP8 量化全部合并到每个解码步骤的单次内核调用中 — 无需额外的 HBM 往返,无需单独的量化内核启动。
TileLang 依赖版本已更新以在 AMD 上启用 FP8 GEMM,并新增了 sparse_mla_fwd_decode_partial_fp8 内核用于部分解码归约路径。该 PR 报告 MI355 吞吐量提升超过 5%(MI300 超过 10%),gsm8k 准确率无下降(DeepSeek-V3.2 0.945 → 0.946;GLM-5 0.946 → 0.950),通过 --kv-cache-dtype fp8_e4m3 配合 TileLang 预填充/解码后端激活。
基准测试数据
所有数据均为 GLM-5 FP8,ISL 8192 / OSL 1024,单节点非分离式部署,于 2026-05-20 在 InferenceX 上测量,CUDA(B200)和 ROCm(MI355X)均使用 SGLang v0.12。每百万总 token 成本计算方式为 TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6),B200 为 $1.95/GPU/hr,MI355X 为 $1.48/GPU/hr。
容器镜像:
- B200:
lmsysorg/sglang:v0.5.12-cu130 - MI355X:
lmsysorg/sglang-rocm:v0.5.12-rocm720-mi35x-20260517
B200 SGLang FP8 MTP,TP=8,8 GPU:
| 并发数 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 417.0 | 100.85 | 9.92 | $1.30 |
| 8 | 650.1 | 77.82 | 12.85 | $0.83 |
| 16 | 952.7 | 56.93 | 17.57 | $0.57 |
| 32 | 1,296.8 | 38.16 | 26.21 | $0.42 |
| 64 | 1,619.3 | 23.56 | 42.45 | $0.34 |
| 128 | 1,929.5 | 13.78 | 72.59 | $0.28 |
| 256 | 1,947.3 | 11.88 | 84.15 | $0.28 |
MI355X SGLang FP8 MTP,TP=4,4 GPU(Pareto 锚定方案):
| 并发数 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 625.5 | 76.80 | 13.02 | $0.66 |
| 8 | 911.7 | 54.59 | 18.32 | $0.45 |
| 16 | 1,208.1 | 35.82 | 27.92 | $0.34 |
| 32 | 1,707.4 | 24.83 | 40.27 | $0.24 |
| 64 | 1,895.0 | 18.19 | 54.99 | $0.22 |
| 128 | 1,911.7 | 18.05 | 55.40 | $0.22 |
MI355X SGLang FP8 MTP,TP=8,8 GPU(高交互性分支):
| 并发数 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 373.4 | 90.43 | 11.06 | $1.10 |
| 8 | 534.2 | 65.05 | 15.37 | $0.77 |
B200 SGLang FP8 非 MTP,TP=8,8 GPU:
| 并发数 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 231.3 | 54.25 | 18.43 | $2.34 |
| 8 | 382.4 | 46.07 | 21.71 | $1.42 |
| 16 | 613.2 | 36.65 | 27.28 | $0.88 |
| 32 | 933.7 | 27.47 | 36.40 | $0.58 |
| 64 | 1,291.8 | 18.42 | 54.28 | $0.42 |
| 128 | 1,669.1 | 11.87 | 84.23 | $0.32 |
| 256 | 1,746.1 | 10.72 | 93.27 | $0.31 |
MI355X SGLang FP8 非 MTP,TP=4,4 GPU:
| 并发数 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 358.8 | 42.03 | 23.79 | $1.15 |
| 8 | 579.6 | 34.68 | 28.83 | $0.71 |
| 16 | 870.8 | 25.86 | 38.67 | $0.47 |
| 32 | 1,274.0 | 18.57 | 53.86 | $0.32 |
| 64 | 1,660.1 | 11.83 | 84.56 | $0.25 |
| 128 | 2,071.4 | 7.33 | 136.36 | $0.20 |
| 256 | 2,189.4 | 6.69 | 149.45 | $0.19 |
等交互性成本对比
对两条 Pareto 前沿在匹配交互性下进行插值。对于 MI355X MTP,Pareto 前沿取 TP=4 和 TP=8 在每个交互性水平上的较低值 — TP=4 在约 77 tok/s/user 以下占优,TP=8 并发数 4 在高交互性端(约 90 tok/s/user)接管,因为 TP=4 无法达到该区间。
MTP:
| 交互性 (tok/s/user) | B200 SGLang MTP $/M tok | MI355X SGLang MTP $/M tok | B200 / MI355X |
|---|---|---|---|
| 18 | $0.30 | $0.22 | 1.41x |
| 24 | $0.34 | $0.24 | 1.40x |
| 35 | $0.40 | $0.34 | 1.17x |
| 55 | $0.55 | $0.45 | 1.22x |
| 77 | $0.82 | $0.66 | 1.25x |
| 90 | $1.08 | $1.10 | 0.98x |
非 MTP:
| 交互性 (tok/s/user) | B200 SGLang $/M tok | MI355X SGLang $/M tok | B200 / MI355X |
|---|---|---|---|
| 15 | $0.37 | $0.28 | 1.31x |
| 20 | $0.45 | $0.35 | 1.27x |
| 30 | $0.66 | $0.58 | 1.14x |
| 40 | $1.07 | $1.03 | 1.05x |
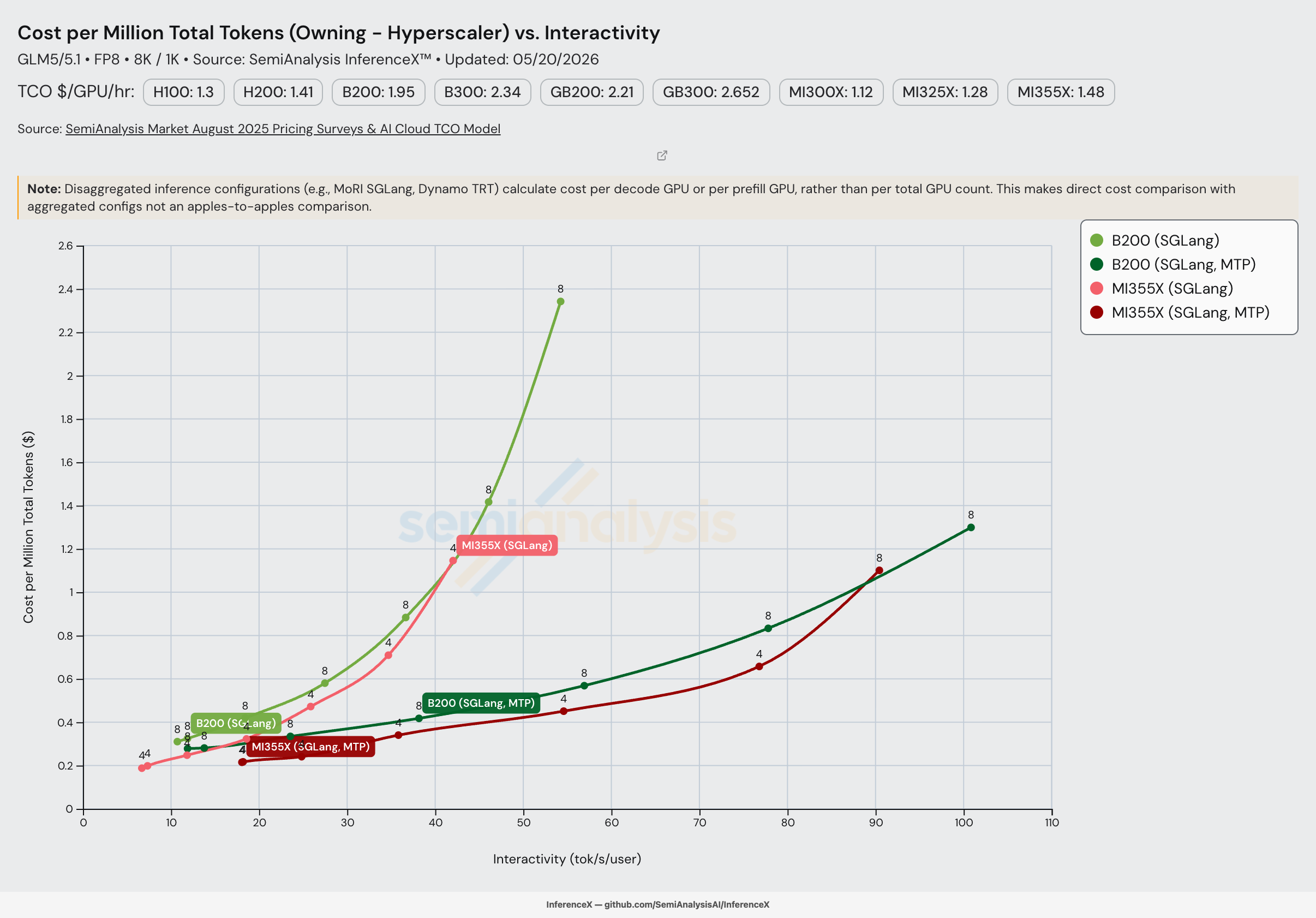
实时图表,预筛选为 2026-05-20 测试中 B200 和 MI355X SGLang 上的 GLM-5 FP8。
MI355X 在 GLM-5 上的后续展望
此次结果为单节点、聚合、仅 FP8。仍有两个差距待弥合:
- FP4 可组合性。 本次对比中 B200 使用的是 CUDA nightly 上的 FP8。B200 NVFP4 SGLang 的 GLM-5 方案已开始交付,将进一步压缩 B200 的成本曲线。MI355X MXFP4 GLM-5.1 SGLang 已通过 InferenceX PR #1098 于 2026-04-21 交付,但 MI355X 上的 FP4 + MTP 组合尚未达到本文展示的 FP8 + MTP 方案的水平。
- 分离式部署和宽专家并行。 MI355X 上的 GLM-5 尚无分离式部署或宽 EP 方案。NVIDIA 的 GB200 NVL72 Dynamo TRT-LLM 和 Dynamo vLLM 方案在 Kimi K2.5 上已展示了机架级宽 EP 带来的约 3 倍每 GPU 吞吐量优势。AMD 尚未为 GLM-5 交付分离式部署方案。
致谢
该方案的快速落地得益于 Anush Elangovan、HaiShaw 及更广泛的 AMD AI 团队在 GLM-5 发布后 14 周内完成了上游 SGLang TileLang 融合 MLA + FP8 KV 内核的提交。SGLang 维护者在提交后数天内即完成了审查与合入。从上游到基准测试的闭环速度就是护城河。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。