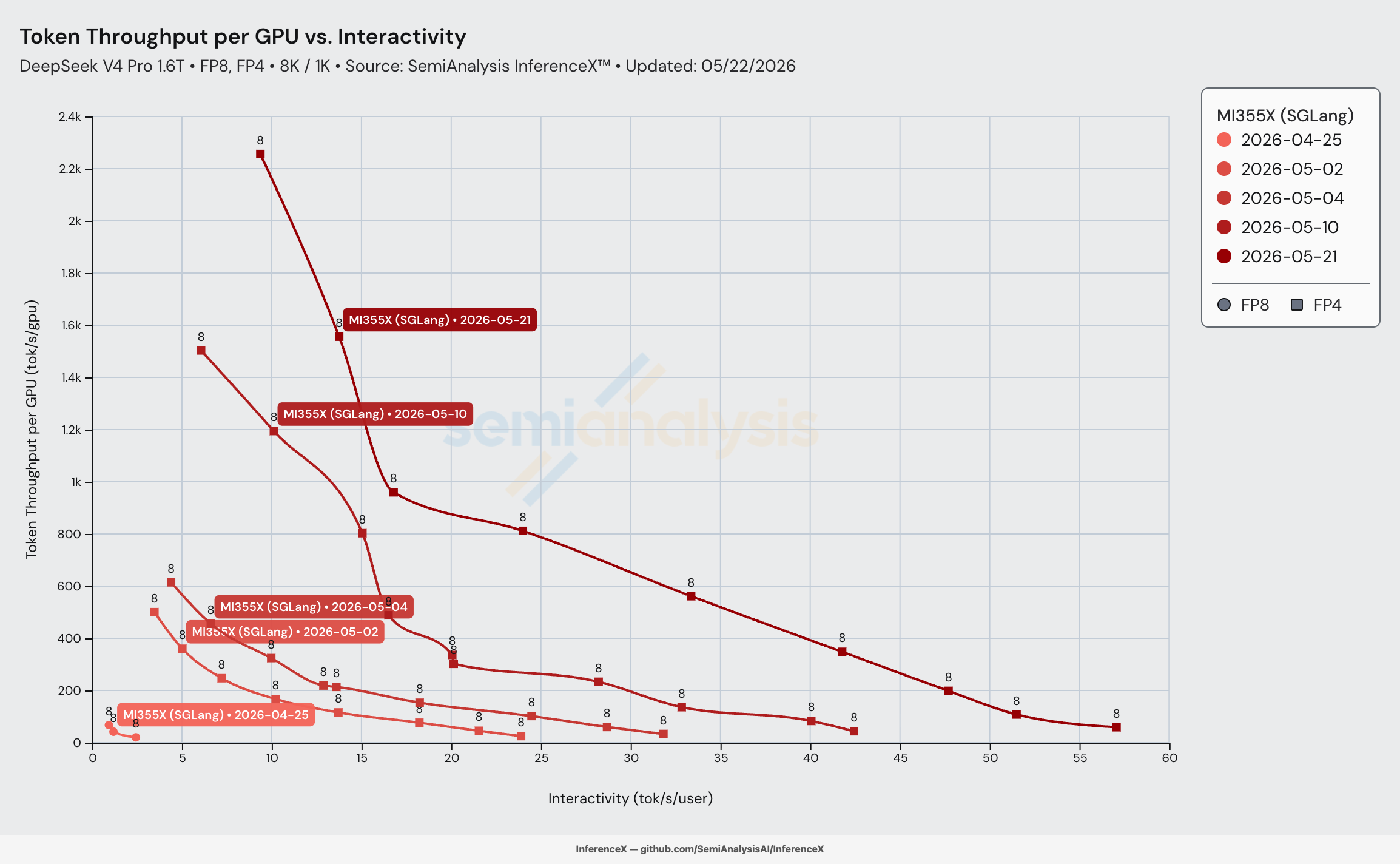
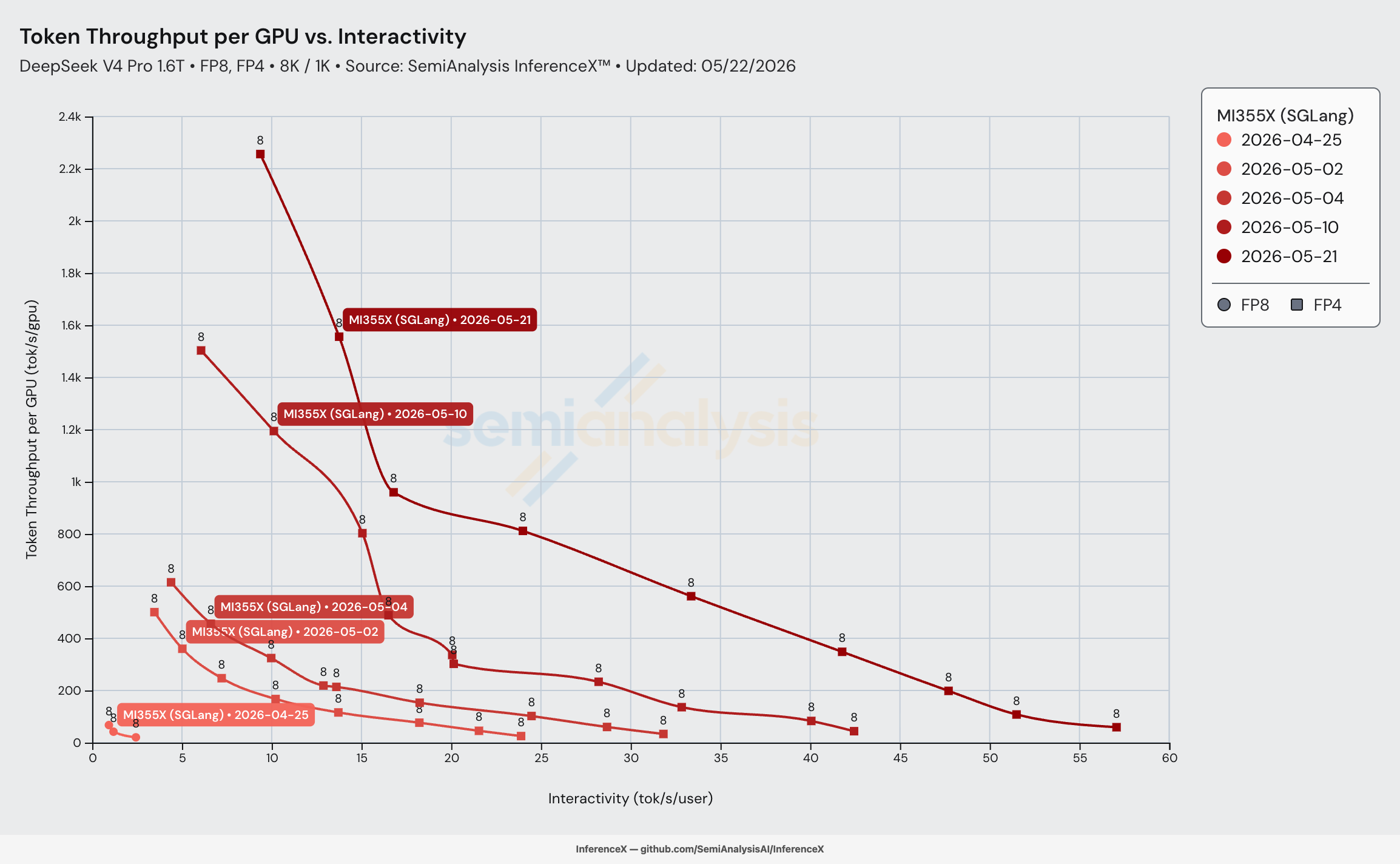
DeepSeek-V4-Pro 于 2026-04-24 发布后仅 26 天,AMD MI355X 上基于 SGLang sgl-project/sglang amd/deepseek_v4 分支 的服务在 8K/1K 负载下达到 2,256 tok/s/GPU、9.4 tok/s/user——相比 2026-04-25 首次点亮时 20.4 tok/s/GPU、2.4 tok/s/user 的水平,每 GPU 吞吐量提升 110.5 倍,而且是罕见的双轴同步提升:每 GPU 吞吐量提升 110.5 倍的同时,交互性也提升了 3.85 倍。SemiAnalysis 此前在 推文中指出 14 天内核心级别的提升约为 75 倍;仪表板现在又记录了此后 12 天的持续优化。
31 个性能优化 PR 在 AMD 分支上紧密接力完成了这些核心工作:FP4 权重启用(#24031)、用于 DeepSeek Sparse Attention 的 TileLang 注意力索引器(#24033、#24050)、Triton 稀疏 MLA 内核及后续融合调度优化(#24930、#25878、#25977)、融合的多头压缩 / RoPE / Hadamard(#24355、#24727、#26014)、FlyDSL MoE(#24971)、融合 hash topk(#24728)、AITER MHC 前处理/后处理,以及六余个压缩器逐元素内核融合。速度就是护城河。
DeepSeek-V4-Pro 模型架构
DeepSeek-V4-Pro 是 DeepSeek 的旗舰 MoE 模型:总参数 1.6T,每 token 激活 49B(据 DeepSeek V4 预览公告)。该架构将新颖的逐 token 压缩路径与 DSA(DeepSeek Sparse Attention) 相结合——这是 DeepSeek 在 V3.2 中引入的稀疏注意力模式,现扩展至更长的上下文(官方服务默认在 1M 上下文下运行 DSv4)。V4-Pro 的官方定位是"极致效率:世界领先的长上下文能力,大幅降低计算和显存开销";开源权重发布于 deepseek-ai/DeepSeek-V4-Pro。
注意力机制是 SGLang AMD 分支需要编写大量内核的根本原因。逐 token 压缩引入了围绕注意力块的多头压缩(mHC)前/后处理对——运行时将其与 RoPE 和 Hadamard 变换融合——而解码路径上的 DSA 需要单独的注意力索引器以及一个稀疏 MLA 内核来仅遍历被路由到的位置。整个技术栈足够新,以至于上游 main 分支在发布时无法在 Blackwell 或 ROCm 上运行 DeepSeek-V4-Pro;AMD 分支正是在 MI355X 上弥合了这一差距。
MI355X 上的 FP4 权重支持在发布时同样不存在。 2026-04-25 的首次点亮测量使用的是 FP8——并且需要 SGLANG_HACK_FLASHMLA_BACKEND=torch 加上 --time=300 的 SLURM 扩展才能在不触及 3 小时 CI 上限的情况下通过约 30 分钟的 MoE JIT 编译——因为 PR #24031(kk,2026-04-29)尚未在 ROCm 上启用 FP4 模型路径。一旦该 PR 合入(加上 2026-05-02 的 InferenceX 配方更新——启用 SGLANG_DSV4_FP4_EXPERTS=True 并拉取了 deepseek-ai/DeepSeek-V4-Pro 的 FP4 权重),曲线就进入了可量测的服务区间。本文从 2026-05-02 起的所有日期均使用 FP4;仅 2026-04-25 使用 FP8。
DeepSeek-V4-Pro 与 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro 的对比
DeepSeek 在预览发布时公布了 V4-Pro-Max 与 Claude Opus 4.6、GPT-5.4-xHigh 和 Gemini 3.1-Pro-High 在知识/推理及智能体基准测试(benchmark)上的评估(evaluation)。从质量角度看,这是一个开源前沿编码模型:
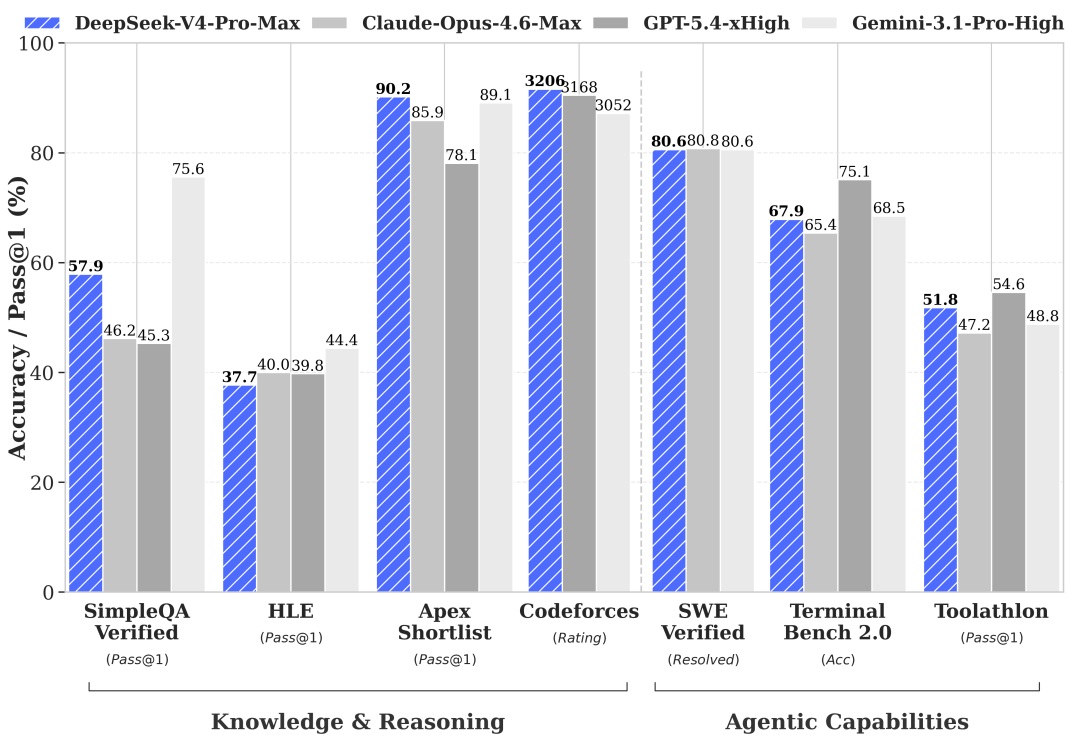
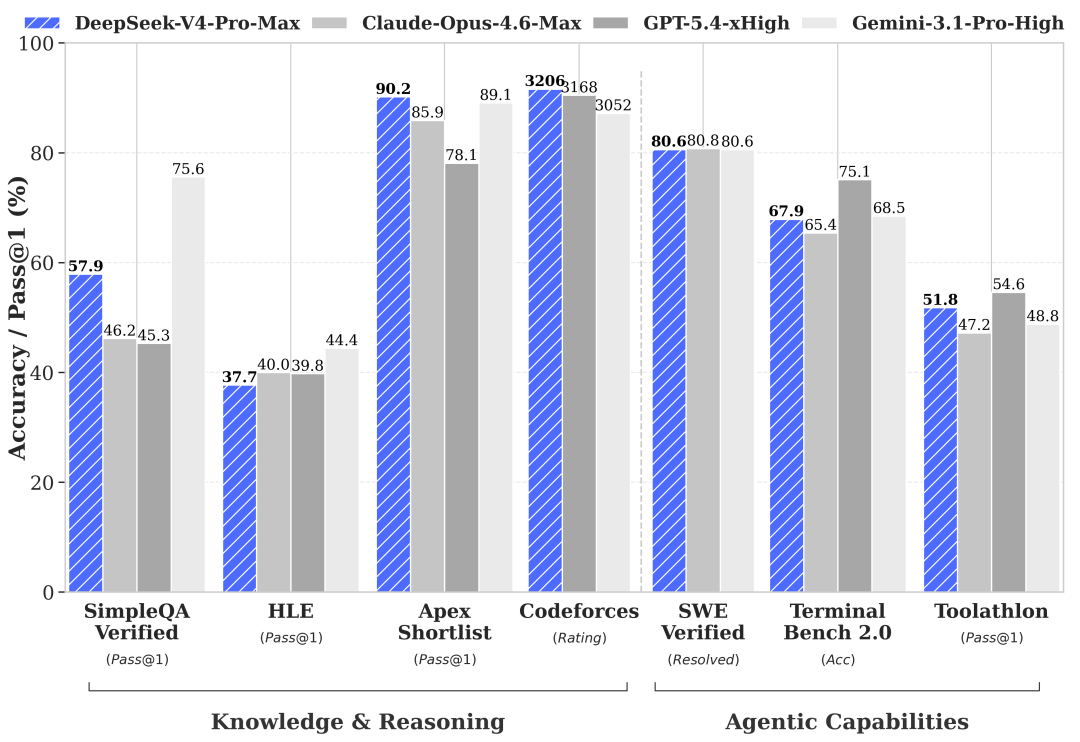
这一质量水准正是 HaiShaw 领导的 AMD SGLang 团队将 MI355X 服务视为 14 天冲刺的原因:一个前沿的开源编码模型值得投入工程力量,而一旦在 AMD 硅片上形成可用的性能曲线,服务栈上每一个百分点的性能/成本改进都会推动真实工作负载的迁移。
实现这一切的关键贡献
上游技术栈:amd/deepseek_v4 SGLang 分支。 sgl-project/sglang amd/deepseek_v4 是一个持续 rebase 的分支,以编号的性能优化 PR 形式合入 AMD 专用的 DeepSeek-V4-Pro 内核。截至 2026-05-22 共 31 个 PR,四位主要贡献者。本文中的每一次测量均基于该分支的镜像,而非 SGLang main(关于上游合并的情况请参见后续计划)。按机制分组的关键优化:
- DSA 注意力(TileLang 索引器 + Triton 稀疏 MLA)。 #24033(Thomas Wang,04-29)将 TileLang 注意力路径移植至 ROCm;#24050(Thomas Wang,04-29)在 TileLang 中添加了注意力索引器;#24930(amd-danli103,05-11)引入了 Triton 稀疏 MLA 内核;#25878(05-20)和 #25977(jacky.cheng,05-22)分别将 prefill 和 extend 的 gather + attention 路径融合为单次调度。
- mHC 融合(多头压缩,逐 token 压缩路径)。 #24355(kk,05-04)"优化 mhc 性能";#24424(Thomas Wang,05-05)压缩器逐元素内核融合;#25020(Xinyi Song,05-12)压缩器优化;#25245(jacky.cheng,05-15)融合 softmax pool Triton 内核用于压缩器;#25353(Xinyi Song,05-15)"启用新压缩器路径";#26014(Xinyi Song,05-22)低并发下的 Triton 融合 mhc_post_pre。
- RoPE + Hadamard 融合。 #24727(Xinyi Song,05-09)使用
rope_rotate_activation融合 RoPE Hadamard——消除了 CPU 侧的一次 launch 调用,改善了每步解码循环的 HBM 利用率。#24249(Xinyi Song,05-02)完成了类似的融合 compress-decode 内核。 - MoE:FlyDSL + FP4 + 融合 hash topk。 #24031(kk,04-29)启用 FP4 模型路径;#24728(Xinyi Song,05-09)融合 hash topk 路由步骤;#24971(Thomas Wang,05-11)合入 FlyDSL MoE 后端用于 ROCm;#25070(Thomas Wang,05-12)添加了 swiglu-limit 密集 MoE / shared expert 路径。
- AITER 内核 + 其他融合。 05-07 cherry-pick 了 AITER MHC 前/后处理修复(commit b639cb6);#25043(jacky.cheng,05-12)将注意力路径上的 input_layernorm 与 FP8 per-128 group 量化融合;#25251(jacky.cheng,05-19)为全 greedy 采样使用 AITER
greedy_sample;#25097(Raiden Makoto,05-13)ROCm 上的 Triton 融合 store cache;#25375(Thomas Wang,05-18)wqb 输入的 rmsnorm_quant 融合。
InferenceX 配方迭代循环。 InferenceX 基准测试(benchmark)配方通过大约每 2–3 天一次的镜像更新吸收每一波上游改进:容器镜像从 rocm/sgl-dev:v0.5.10rc0-rocm720-mi35x-20260414(04-25,仅 FP8,配方需要 SGLANG_HACK_FLASHMLA_BACKEND=torch 才能编译)→ rocm/sgl-dev:rocm720-mi35x-583b1b6-20260501-DSv4(05-02,通过 SGLANG_DSV4_FP4_EXPERTS=True 启用 FP4)→ a8410de6-20260502(05-03,融合 compress-decode)→ bfd32b6-20260507(05-08,AITER MHC 前/后处理 + Triton SWA prepare)→ 0363e6c-20260509 → b19052c-20260518(05-19,稳定的 lmsysorg/sglang:v0.5.12-rocm720-mi35x 仓库,含 Triton 注意力后端、FlyDSL MoE、融合 hash topk)→ 8c3b5aa-20260521(05-21 最终版)。镜像更新之间的配方调优收紧了 --num-continuous-decode-steps(4 → 8,+4.7%),将 --max-running-requests 和 --cuda-graph-max-bs 调整为矩阵并发值,并在 DP attention 配置上启用了 --enable-prefill-delayer。
数据详情
所有数据行均为 DeepSeek-V4-Pro 在 ISL 8192 / OSL 1024 下,使用单台 MI355X 8-GPU 节点,于 2026-04-25 至 2026-05-21 期间在 InferenceX 上测量。吞吐量(throughput)为每 GPU 值。精度:2026-04-25 为 FP8(发布时唯一可用的路径);2026-05-02 起为 FP4,使用 deepseek-ai/DeepSeek-V4-Pro 并设置 SGLANG_DSV4_FP4_EXPERTS=True。后期运行在高并发下启用了 DP attention。
2026-04-25(FP8,基线首次点亮):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 8 | 20.4 | 2.43 | 411 |
| 32 | 42.0 | 1.19 | 843 |
| 64 | 67.4 | 0.93 | 1,074 |
2026-05-02(FP4 首次点亮,+TileLang 注意力,FP4 启用):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 25.2 | 23.89 | 41.86 |
| 2 | 45.4 | 21.65 | 46.41 |
| 4 | 76.5 | 18.38 | 54.87 |
| 8 | 115.8 | 13.87 | 72.92 |
| 16 | 167.2 | 10.07 | 97.87 |
| 32 | 247.0 | 7.33 | 138.64 |
| 64 | 359.9 | 5.23 | 199.14 |
| 128 | 500.2 | 3.61 | 288.50 |
2026-05-04(+融合 compress-decode,+TileLang MHC 后处理,移除 Torch 回退):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 33.3 | 31.82 | 31.43 |
| 4 | 102.1 | 24.65 | 40.86 |
| 8 | 153.0 | 18.43 | 54.82 |
| 16 | 218.9 | 13.04 | 77.62 |
| 32 | 324.2 | 10.10 | 100.26 |
| 64 | 455.7 | 6.86 | 151.33 |
| 128 | 614.6 | 4.54 | 227.59 |
2026-05-10(+AITER MHC 前/后处理,+Triton SWA prepare,+FlyDSL MoE 预览版):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 43.9 | 42.44 | 23.56 |
| 4 | 136.0 | 33.11 | 30.45 |
| 8 | 233.4 | 28.63 | 35.44 |
| 16 | 336.1 | 20.33 | 49.86 |
| 32 | 488.3 | 16.80 | 60.58 |
| 64 | 802.9 | 14.81 | 66.43 |
| 128 | 1,194.3 | 10.17 | 98.80 |
| 256 | 1,503.2 | 6.14 | 164.86 |
2026-05-21(最新:SGLang v0.5.12 + Triton 注意力后端 + 融合 hash topk + FlyDSL MoE):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 59.2 | 57.06 | 17.52 |
| 4 | 198.5 | 47.71 | 20.96 |
| 8 | 348.2 | 41.78 | 23.94 |
| 16 | 561.3 | 33.37 | 29.97 |
| 32 | 811.7 | 23.99 | 41.68 |
| 64 | 959.6 | 16.79 | 59.56 |
| 128 | 1,556.0 | 13.76 | 72.69 |
| 256 | 2,256.1 | 9.37 | 106.75 |
| 512 | 1,814.4 | 5.59 | 178.90 |
加粗行即为标题数据:在并发 256 + DP attention 下达到 2,256 tok/s/GPU、9.4 tok/s/user——相比 04-25 首次点亮时 20.4 tok/s/GPU、2.4 tok/s/user 提升 110.5 倍(即使与 04-25 峰值 67.4 tok/s/GPU、0.9 tok/s/user 相比也有 33.5 倍提升,而那已经不是可用的服务工作点)。MI355X 上 DSv4-Pro 单节点聚合服务的全新性能天花板。
等交互性吞吐量对比
在匹配交互性水平下的每 GPU 吞吐量,沿各日期的帕累托前沿进行插值。2026-04-25 的交互性未超过 2.5 tok/s/user,因此该日期每行均显示 _unreachable_——模型当时尚未进入服务区间。超出前沿测量范围的单元格显示为 _unreachable_。
| 交互性 (tok/s/user) | 04-25 | 05-02 | 05-04 | 05-10 | 05-21 | 05-02 → 05-21 |
|---|---|---|---|---|---|---|
| 8 | unreachable | 221 | 401 | 1,363 | unreachable | ∞ |
| 10 | unreachable | 169 | 328 | 1,208 | 2,162 | 12.8x |
| 12 | unreachable | 136 | 247 | 1,065 | 1,855 | 13.6x |
| 15 | unreachable | 104 | 194 | 775 | 1,272 | 12.2x |
| 17 | unreachable | 88 | 169 | 473 | 951 | 10.8x |
| 20 | unreachable | 61 | 139 | 361 | 876 | 14.3x |
| 25 | unreachable | unreachable | 99 | 266 | 788 | ∞ |
| 30 | unreachable | unreachable | 50 | 205 | 653 | ∞ |
| 40 | unreachable | unreachable | unreachable | 89 | 393 | ∞ |
| 50 | unreachable | unreachable | unreachable | unreachable | 140 | ∞ |
核心结论是从 2026-05-02 到 2026-05-21,在 10–20 tok/s/user 的服务区间内,等交互性下的每 GPU 吞吐量提升了 12–14 倍。提升逐日期层层累加——每次镜像更新都将曲线再推高 1.6–4.4 倍。高交互性段(25+ tok/s/user)在 05-04 之后才完全打开,而 50 tok/s/user 仅在 05-21 配合最新的 FlyDSL MoE + 融合 hash topk 内核(lmsysorg/sglang:v0.5.12-rocm720-mi35x)后才可量测。
实时图表,已预过滤为 MI355X SGLang DSv4-Pro 在 5 个测量日期的数据。
MI355X DeepSeek-V4-Pro 的后续计划
MI355X 与 NVIDIA 在 DSv4-Pro 上的差距不在硅片——在于软件。 从纸面参数看,MI355X 的 HBM 更大(288 GB vs B200 的 180 GB——1.60 倍容量),HBM 带宽相同(均为 8 TB/s),密集计算在各精度下均略高(FP4 / FP8 / BF16 均为 B200 的 1.12 倍)。B200 唯一领先的硅片参数是节点内扩展带宽——NVLink 5 单向 900 GB/s vs 第五代 Infinity Fabric 的 576 GB/s,1.56 倍优势——但在单节点 TP=8 运行 1.6T 激活 49B 的 MoE 模型时,这一差距的影响小于 AMD 分支仍在弥合的内核栈成熟度差距。


| 规格 | MI355X | B200 SXM | MI355X / B200 |
|---|---|---|---|
| HBM 容量 | 288 GB | 180 GB | 1.60x |
| HBM 带宽 | 8 TB/s | 8 TB/s | 1.00x |
| 密集 FP4 (TFLOP/s) | 10,066 | 9,000 | 1.12x |
| 密集 FP8 (TFLOP/s) | 5,033 | 4,500 | 1.12x |
| 密集 BF16 (TFLOP/s) | 2,516 | 2,250 | 1.12x |
| 每 GPU 扩展带宽(单向) | 576 GB/s (Infinity Fabric) | 900 GB/s (NVLink 5) | 0.64x |
| 扩展域 GPU 数 | 8 | 8 | 1.00x |
| 扩展域 HBM 容量 | 2.30 TB | 1.44 TB | 1.60x |
| 扩展域 HBM 带宽(聚合) | 64 TB/s | 64 TB/s | 1.00x |
因此,当实测的 B200 SGLang DSv4-Pro 曲线在 15–30 tok/s/user 服务区间内比 MI355X SGLang 高出约 5 倍(完全相同的 FP4 / 8K / 1K 负载)时,这一差距不来自算力,不来自 HBM 容量,不来自 HBM 带宽,也几乎与扩展带宽无关。差距在于上游内核覆盖度、融合完整性以及调度器调优——正是 amd/deepseek_v4 分支持续 rebase 追赶的方向,也是 26 天内缩小了 110.5 倍的差距所在:
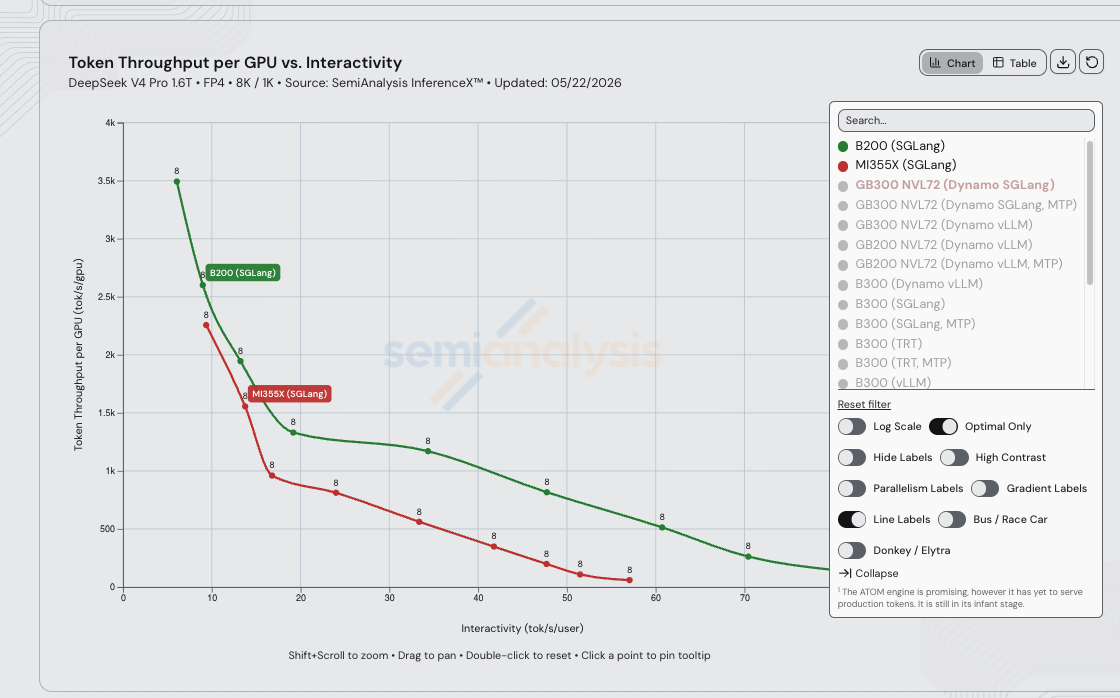
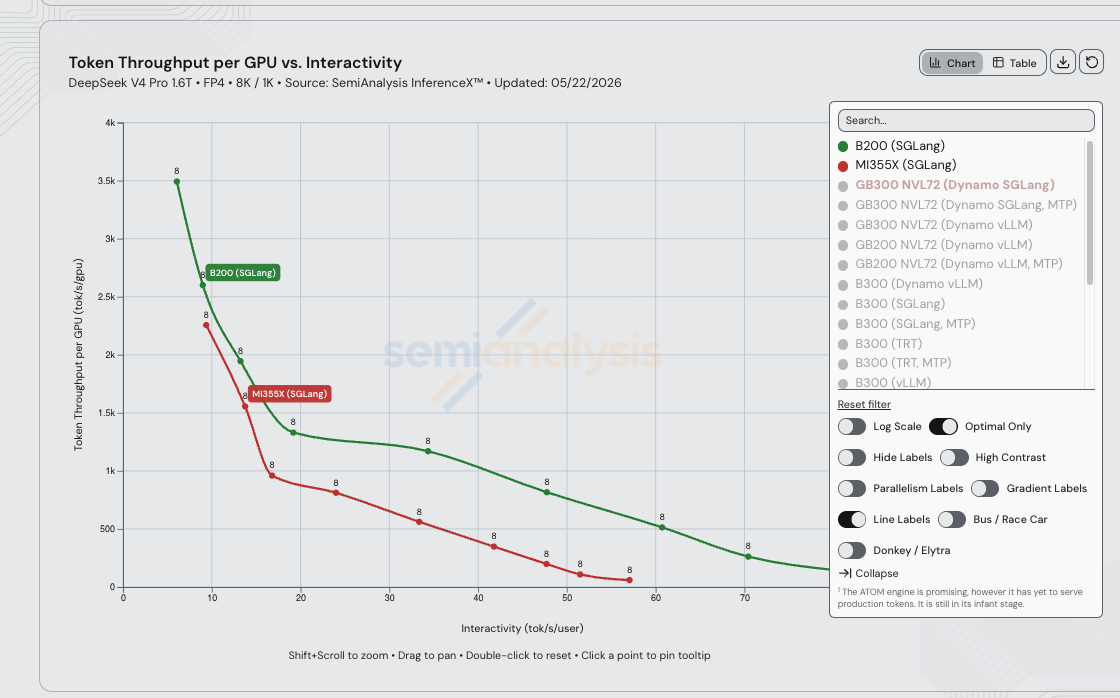
据 SemiAnalysis 评估,接下来需要弥合的差距:
- 还需约 5 倍吞吐量才能追平单节点聚合 B200。 B200 上的 SGLang DSv4-Pro 技术栈在 70+ tok/s/user 时已达到数千 tok/s/GPU 区间,而 MI355X SGLang 仅在低交互性的左侧边缘触及此水平。按照
amd/deepseek_v4分支当前的 PR 节奏,AMD 在未来几周内追平这一差距是现实可行的——硅片具备能力,内核只需继续追赶。 - 还需额外约 1.5 倍以追平 PD 分离式 B200。 InferenceX 尚未发布 MI355X DSv4-Pro 的分离式配方。
mori-sglangAMD 分离式分支具备 prefill/decode 分离原语,但尚未接入 InferenceX 循环中的 DSv4-Pro 配方。 - AMD 分支上的持续内核节奏。 31 个 PR 的开发节奏造就了 110.5 倍的提升;开放的 compare 视图仍在每 2–3 天添加新的性能优化 PR,因此本文中的曲线到下周就会过时。新的压缩器路径(#25353)和 extend 的融合 nosplitk 注意力调度(#25977)在 2026-05-21 数据集之后才合入,尚未反映在图表中。
- 分支 → SGLang main 上游迁移。 第一批代码在 PR #24933(kk,2026-05-18 合入,跨 17 个文件 +3,678 / -70)中合入——足以通过
is_hip/use_aiter门控、替换无法在 ROCm 上编译的 JIT 融合内核的 Triton 版本,以及新的 HIP 注意力后端在 SGLang main 上以 eager 模式运行 DSv4-Pro。PR 描述明确标注了后续工作:"后续 PR 将从amd/deepseek_v4分支合入剩余的 DSv4 优化"——压缩流融合、多流启用、TileLang 注意力索引器、FlyDSL MoE 以及关键的 SGLANGOPT* 开关截至 2026-05-22 仍为分支专有。在这些迁移完成之前,MI355X 在 SGLangmain上的 DSv4-Pro 服务性能将比本文测量结果低一个数量级——分支镜像(lmsysorg/sglang:v0.5.12-rocm720-mi35x-*)仍是复现上述曲线的唯一途径。
对于当前的 MI355X DSv4-Pro 服务,基于 lmsysorg/sglang:v0.5.12-rocm720-mi35x-20260517 的 2026-05-21 配方是生产前沿——任何早于 05-10 的版本不应作为基准测试对比对象。
致谢
31 个性能优化 PR 是以下贡献者的工作成果:Thomas Wang(TileLang 注意力索引器、FlyDSL MoE、压缩器逐元素融合、带 CUDA graph 的 attn early-exit、rmsnorm-quant 融合)、Xinyi Song(融合 compress-decode、融合 RoPE Hadamard、融合 hash topk、压缩器优化)、HaiShaw(集成协调 + 环境配置)、amd-danli103(Triton 稀疏 MLA + 融合调度)、jacky.cheng(input_layernorm + FP8 per-group 量化融合、softmax pool、AITER greedy_sample)、kk(FP4 启用、MHC 性能、fuse_wqkv)、Raiden Makoto(Triton 融合 store cache)、Xinyu Jiang(radix 优化),以及更广泛的 AMD AI 团队。从上游到基准测试的迭代速度就是护城河。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。