14 weeks after GLM-5's release, AMD MI355X SGLang FP8 undercuts NVIDIA B200 SGLang FP8 on cost per million tokens across most of the single-node Pareto frontier on the 8k/1k workload (from ~10 to ~77 tok/s/user; B200 noses back ahead above ~90 tok/s/user). The peak gap is 1.41x at 18 tok/s/user with MTP ($0.30/M on B200 vs $0.22/M on MI355X — a 40% reduction) and 1.36x at 10 tok/s/user without MTP ($0.31/M vs $0.23/M). Both runs are on SGLang v0.12, where the MI355X ROCm stack is now feature-matched with the CUDA stack on B200: both MTP and non-MTP recipes, both with FP8 KV cache, both on SGLang's latest TileLang-backed MLA path.
This is the cadence that matters. GLM-5 dropped, and within a quarter AMD shipped an upstream SGLang kernel (sgl-project/sglang PR #21511) along with other optimizations plus the matching InferenceX recipes (InferenceX PR #1440) that flipped the FP8 single-node cost curve on the model. Speed is the moat.
GLM-5 is ZAI's (Zhipu) MoE flagship, released 2026-02-11 — exactly 14 weeks before the InferenceX run in this post. It's a 744B-parameter sparse MoE with ~40B activated per token: 256 experts with top-8 routing (~5.9% sparsity) plus shared experts. The published architecture name is glm_moe_dsa — the model integrates DeepSeek Sparse Attention (DSA) on the decode path, the same sparse-attention pattern DeepSeek introduced in V3.2 and that SGLang's TileLang backend was built around, paired with Multi-head Latent Attention (MLA) for KV-cache compression to support its 200K context window.
On MI355X, the equivalent capability landed via SGLang's TileLang backend in mid-April, and the resulting decode throughput moved enough that MI355X's lower per-GPU TCO ($1.48/GPU/hr vs B200 at $1.95/GPU/hr per the SemiAnalysis AI Cloud TCO Model) now compounds into a real cost-per-token advantage instead of being swamped by software gaps.
What Shipped to Make This Happen
One of the headline performance optimizations on the AMD side is sgl-project/sglang PR #21511 by HaiShaw, merged 2026-04-03. The PR enables FP8 KV cache and an FP8 attention kernel on MI300/MI355 using SGLang's TileLang backend (tested on both DeepSeek-V3.2 and GLM-5), with a different fusion strategy per generation:
- On MI355, the PR reuses the existing
fused_qk_rope_cat_and_cache_mlakernel for both Q and KV FP8 quantization. The QK rope concat, MLA cache write, and FP8 quant for both Q and KV all collapse into one kernel pass per decode step — no extra HBM round-trips, no separate quantization launches.
The TileLang dependency was bumped to enable FP8 GEMM on AMD, and a new sparse_mla_fwd_decode_partial_fp8 kernel was added for the partial-decode reduction path. The PR reports throughput gains of greater than 5% on MI355 (greater than 10% on MI300), no accuracy regression on gsm8k (DeepSeek-V3.2 0.945 → 0.946; GLM-5 0.946 → 0.950), and activates with --kv-cache-dtype fp8_e4m3 alongside the TileLang prefill/decode backends.
The Numbers
All rows are GLM-5 FP8 at ISL 8192 / OSL 1024 on a single non-disaggregated node, measured on InferenceX on 2026-05-20 on SGLang v0.12 for both CUDA (B200) and ROCm (MI355X). Cost per million total tokens is computed as TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6), with B200 at $1.95/GPU/hr and MI355X at $1.48/GPU/hr.
Container images used:
- B200:
lmsysorg/sglang:v0.5.12-cu130 - MI355X:
lmsysorg/sglang-rocm:v0.5.12-rocm720-mi35x-20260517
B200 SGLang FP8 MTP, TP=8 on 8 GPUs:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 417.0 | 100.85 | 9.92 | $1.30 |
| 8 | 650.1 | 77.82 | 12.85 | $0.83 |
| 16 | 952.7 | 56.93 | 17.57 | $0.57 |
| 32 | 1,296.8 | 38.16 | 26.21 | $0.42 |
| 64 | 1,619.3 | 23.56 | 42.45 | $0.34 |
| 128 | 1,929.5 | 13.78 | 72.59 | $0.28 |
| 256 | 1,947.3 | 11.88 | 84.15 | $0.28 |
MI355X SGLang FP8 MTP, TP=4 on 4 GPUs (the Pareto-anchor recipe):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 625.5 | 76.80 | 13.02 | $0.66 |
| 8 | 911.7 | 54.59 | 18.32 | $0.45 |
| 16 | 1,208.1 | 35.82 | 27.92 | $0.34 |
| 32 | 1,707.4 | 24.83 | 40.27 | $0.24 |
| 64 | 1,895.0 | 18.19 | 54.99 | $0.22 |
| 128 | 1,911.7 | 18.05 | 55.40 | $0.22 |
MI355X SGLang FP8 MTP, TP=8 on 8 GPUs (the high-interactivity arm):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 373.4 | 90.43 | 11.06 | $1.10 |
| 8 | 534.2 | 65.05 | 15.37 | $0.77 |
B200 SGLang FP8 non-MTP, TP=8 on 8 GPUs:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 231.3 | 54.25 | 18.43 | $2.34 |
| 8 | 382.4 | 46.07 | 21.71 | $1.42 |
| 16 | 613.2 | 36.65 | 27.28 | $0.88 |
| 32 | 933.7 | 27.47 | 36.40 | $0.58 |
| 64 | 1,291.8 | 18.42 | 54.28 | $0.42 |
| 128 | 1,669.1 | 11.87 | 84.23 | $0.32 |
| 256 | 1,746.1 | 10.72 | 93.27 | $0.31 |
MI355X SGLang FP8 non-MTP, TP=4 on 4 GPUs:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 358.8 | 42.03 | 23.79 | $1.15 |
| 8 | 579.6 | 34.68 | 28.83 | $0.71 |
| 16 | 870.8 | 25.86 | 38.67 | $0.47 |
| 32 | 1,274.0 | 18.57 | 53.86 | $0.32 |
| 64 | 1,660.1 | 11.83 | 84.56 | $0.25 |
| 128 | 2,071.4 | 7.33 | 136.36 | $0.20 |
| 256 | 2,189.4 | 6.69 | 149.45 | $0.19 |
Iso-Interactivity Cost Comparison
Interpolating both Pareto frontiers at matched interactivity. For MI355X MTP the Pareto frontier is the lower of TP=4 and TP=8 at each interactivity — TP=4 dominates up to ~77 tok/s/user, with TP=8 conc 4 taking over at the high-interactivity end (~90 tok/s/user) where TP=4 can't reach.
MTP:
| Interactivity (tok/s/user) | B200 SGLang MTP $/M tok | MI355X SGLang MTP $/M tok | B200 / MI355X |
|---|---|---|---|
| 18 | $0.30 | $0.22 | 1.41x |
| 24 | $0.34 | $0.24 | 1.40x |
| 35 | $0.40 | $0.34 | 1.17x |
| 55 | $0.55 | $0.45 | 1.22x |
| 77 | $0.82 | $0.66 | 1.25x |
| 90 | $1.08 | $1.10 | 0.98x |
Non-MTP:
| Interactivity (tok/s/user) | B200 SGLang $/M tok | MI355X SGLang $/M tok | B200 / MI355X |
|---|---|---|---|
| 15 | $0.37 | $0.28 | 1.31x |
| 20 | $0.45 | $0.35 | 1.27x |
| 30 | $0.66 | $0.58 | 1.14x |
| 40 | $1.07 | $1.03 | 1.05x |
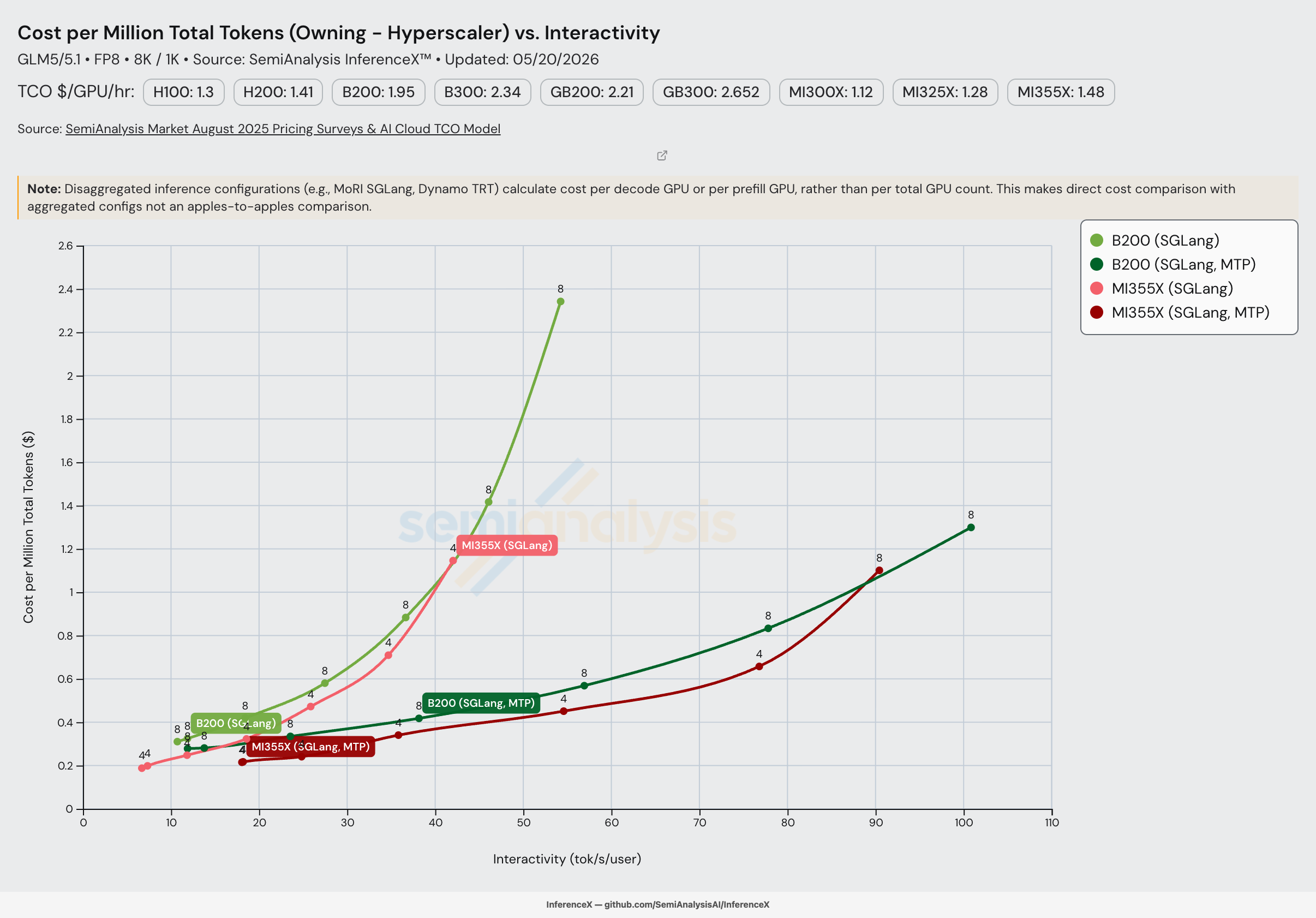
Live chart, pre-filtered to GLM-5 FP8 on B200 and MI355X SGLang for the 2026-05-20 run.
What's Next for MI355X on GLM-5
This result is single-node, aggregated, FP8 only. Two gaps still need closing:
- FP4 composability. B200 in this comparison is FP8 on a CUDA nightly. B200 NVFP4 SGLang for GLM-5 is now shipping and will further compress B200's cost curve. MI355X MXFP4 GLM-5.1 SGLang shipped via InferenceX PR #1098 on 2026-04-21, but the FP4 + MTP composition on MI355X is not yet at parity with the FP8 + MTP recipe shown here.
- Disaggregation and wide expert parallelism. MI355X GLM-5 has no disagg or wide-EP recipe yet. NVIDIA's GB200 NVL72 Dynamo TRT-LLM and Dynamo vLLM recipes on Kimi K2.5 already demonstrated a ~3x throughput-per-GPU advantage from rack-scale wide EP. AMD has still not shipped disagg for GLM-5 yet.
Acknowledgments
This recipe loop moved fast because Anush Elangovan, HaiShaw, and the broader AMD AI team landed both the upstream SGLang TileLang fused MLA + FP8 KV kernel in a 14-week window after GLM-5 dropped. The SGLang maintainers reviewed and shipped the kernel within days of submission. Speed of the upstream-to-benchmark loop is the moat.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.