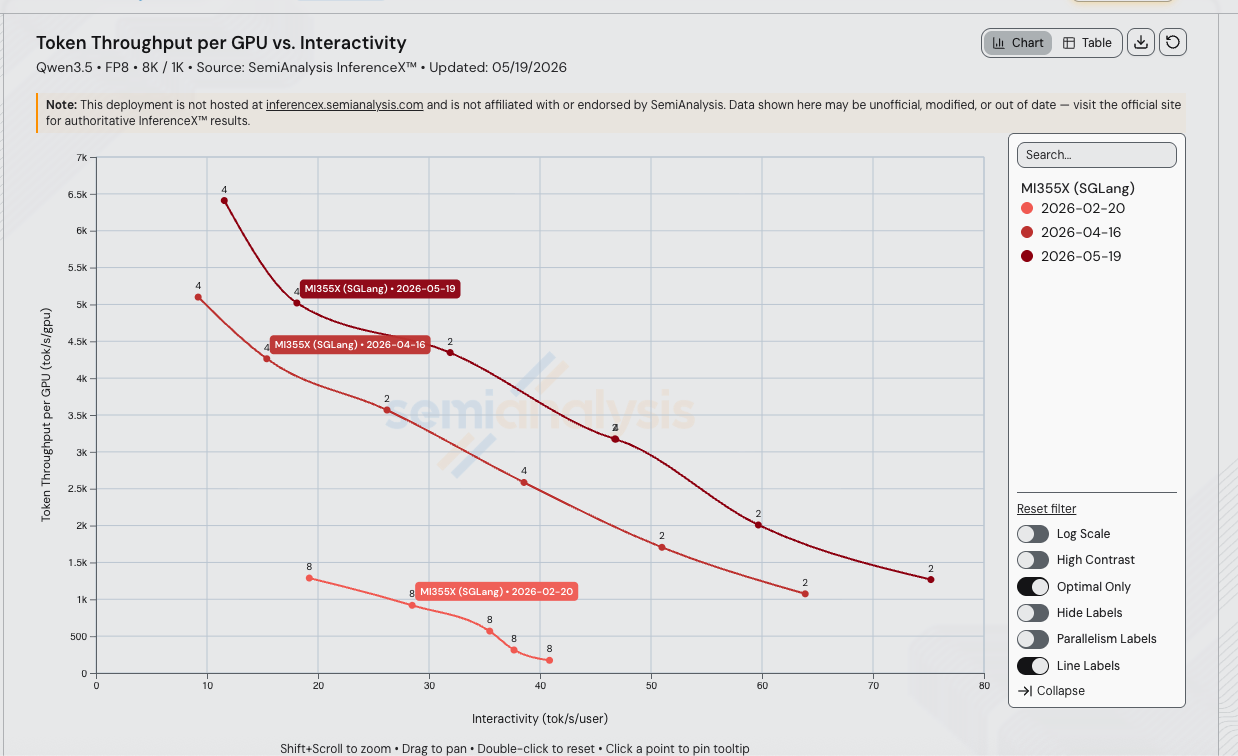
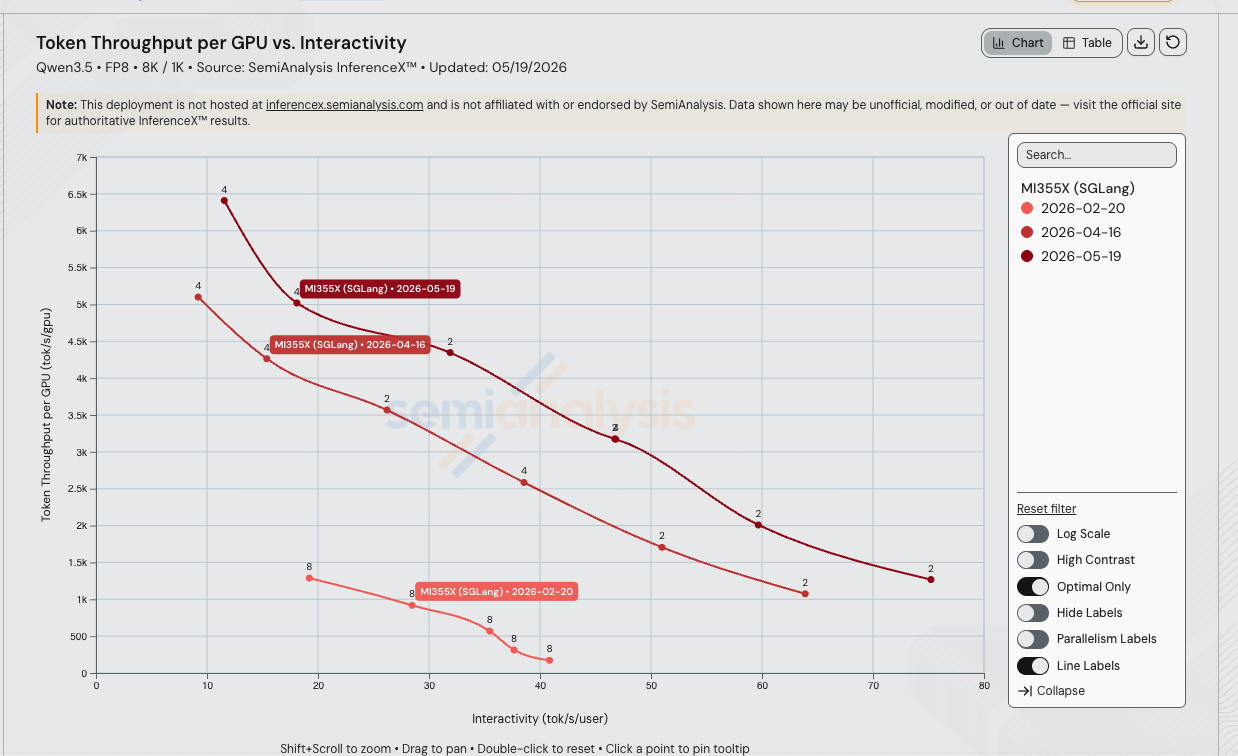
阿里巴巴于 2026-02-16 发布 Qwen3.5-397B-A17B 后 13 周,AMD MI355X 上 SGLang FP8 在 8k/1k 工作负载下的每 GPU 吞吐量在 40 tok/s/user 的等交互性下最高提升至 19.0 倍(在仪表板的单调三次 Hermite Pareto 插值上,从 2026-02-20 v0.5.8.post1 基线的 192 tok/s/GPU 提升至 2026-05-19 v0.5.12 运行的 3,660 tok/s/GPU)。这一增长叠加了三个 SGLang 版本以及三次 AITER MoE 内核合入带来的大部分提升,5 月的 v0.5.10rc0 → v0.5.12 镜像升级又在此基础上额外贡献了约 1.5 倍。
这完全是软件优化——全程使用相同的 MI355X CDNA4 硅片,TCO 始终为 $1.48/GPU/hr。相关记录:sgl-project/sglang#20736、sgl-project/sglang#21188 和 sgl-project/sglang#21421,均在 3–4 月合入,且均通过 SGLANG_USE_AITER=1 开关控制。上游到基准测试的闭环速度本身就是护城河。
Qwen3.5-397B-A17B 是阿里巴巴的 MoE 旗舰模型,于 2026-02-16 发布,总参数量 397B,每 token 激活 17B,拥有 512 个专家(top-K 路由),并采用混合注意力架构,交替使用 Gated DeltaNet 和 Gated Attention 层。首次 InferenceX 基准测试在模型发布四天后便在 MI355X 上完成。
推动性能提升的具体优化
带来这些巨大性能提升的部分优化包括:
- sgl-project/sglang PR #20736,由 zhentaocc 提交(合著者 yichiche),2026-04-15 合入——在 Qwen2 MoE 和 Qwen3.5 MoE 中将共享专家与路由专家融合。当
shared_expert_intermediate_size == moe_intermediate_size时,共享专家被视为额外的一个专家(top-K + 1),在单次 AITER MoE 分发中一并处理。每个 MoE 层减少一次内核启动,共享专家权重的 HBM 往返次数也减少。据报告在 Qwen3.5 并发 16 时总吞吐量提升 +4.6%,TPOT 降低 -4%;FP8 精度最初需要 AITER split-K 修复后才能启用。 - sgl-project/sglang PR #21188,由 yichiche 提交,2026-03-23 合入——为
GemmaRMSNorm添加forward_hip路径,使 AMD GPU 使用融合 RMSNorm 内核(AITERfused_add_rms_norm/rms_norm)而非原生回退路径。原生路径在 MI355X 上受标量运算限制;融合路径将 Gemma 风格的weight + 1.0偏移吸收进内核中。据报告在 8x MI355X、并发 1、8k/1k 下:中位端到端延迟降低 -23.1%,总吞吐量提升 +30.0%,中位首 token 延迟(TTFT)降低 -17.0%,同时 GSM8K 精度从 0.943 提升至 0.955。 - sgl-project/sglang PR #21421,由 zhentaocc 提交,2026-03-26 合入——将 AITER 的
fused_topk内核集成到 SGLang 的fused_topk中,用于 softmax 评分的 MoE top-K 选择。启用 AITER 时自动分发到aiter.fused_moe.fused_topk。内核微基准测试显示:在 Qwen3.5 形态(E=512, top-K=10)上比 sgl-kernel 基线快约 1.31x 到 6.29x,在高 token 数下增益最大。端到端 bs=64 1k/1k 下:总吞吐量提升 +1.9%,GSM8K 精度与基线偏差在 ±0.001 以内。
测试数据
所有行均为 Qwen3.5-397B-A17B FP8、ISL 8192 / OSL 1024、单节点非分离式 MI355X,在 InferenceX 上测量。每百万总 token 成本按 TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6) 计算,MI355X TCO 为 $1.48/GPU/hr,来自 SemiAnalysis AI Cloud TCO 模型。
各日期使用的容器镜像:
- 2026-02-20:
rocm/sgl-dev:v0.5.8.post1-rocm720-mi35x-20260218 - 2026-04-16:
lmsysorg/sglang-rocm:v0.5.10rc0-rocm720-mi35x-20260414 - 2026-05-19:
lmsysorg/sglang-rocm:v0.5.12-rocm720-mi35x-20260517
2026-02-20,MI355X SGLang FP8,TP=8、8 GPU(基线):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 171.9 | 40.86 | 24.47 | $2.39 |
| 8 | 312.1 | 37.66 | 26.55 | $1.32 |
| 16 | 568.0 | 35.47 | 28.19 | $0.72 |
| 32 | 917.8 | 28.48 | 35.11 | $0.45 |
| 64 | 1,288.0 | 19.22 | 52.03 | $0.32 |
2026-04-16,MI355X SGLang FP8,TP=2、2 GPU(重新调优 + AITER PR 后):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,074.3 | 63.89 | 15.65 | $0.38 |
| 8 | 1,704.6 | 50.98 | 19.61 | $0.24 |
| 16 | 2,571.9 | 38.50 | 26.51 | $0.16 |
| 32 | 3,567.8 | 26.22 | 38.15 | $0.12 |
2026-04-16,MI355X SGLang FP8,TP=4、4 GPU(高吞吐量分支):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 32 | 2,584.9 | 38.56 | 25.94 | $0.16 |
| 64 | 3,426.6 | 24.84 | 40.25 | $0.12 |
| 128 | 4,263.2 | 15.38 | 65.01 | $0.10 |
| 256 | 5,099.3 | 9.20 | 108.64 | $0.08 |
2026-05-19,MI355X SGLang FP8,TP=2、2 GPU(v0.5.12 升级):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,267.5 | 75.22 | 13.29 | $0.32 |
| 8 | 2,008.1 | 59.67 | 16.76 | $0.20 |
| 16 | 3,175.6 | 46.73 | 21.40 | $0.13 |
| 32 | 4,346.8 | 31.91 | 31.34 | $0.09 |
2026-05-19,MI355X SGLang FP8,TP=4、4 GPU(v0.5.12 升级):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 32 | 3,171.8 | 46.82 | 21.36 | $0.13 |
| 64 | 4,113.4 | 29.83 | 33.53 | $0.10 |
| 128 | 5,019.6 | 18.09 | 55.27 | $0.08 |
| 256 | 6,409.1 | 11.56 | 86.53 | $0.06 |
等交互性吞吐量对比
每个日期沿其 Pareto 前沿插值(4 月和 5 月运行取 TP=2 和 TP=4 中较高的每交互性吞吐量;2 月基线仅有 TP=8)。比率为匹配 tok/s/user 下的每 GPU 吞吐量:
| 交互性 (tok/s/user) | 2 月 v0.5.8 tok/s/GPU | 4 月 v0.5.10rc0 tok/s/GPU | 5 月 v0.5.12 tok/s/GPU | 5 月 / 2 月 | 5 月 / 4 月 |
|---|---|---|---|---|---|
| 20 | 1,259 | 3,906 | 4,861 | 3.86x | 1.24x |
| 30 | 859 | 3,278 | 4,449 | 5.18x | 1.36x |
| 35 | 612 | 2,867 | 4,114 | 6.72x | 1.44x |
| 40 | 192 | 2,476 | 3,660 | 19.0x | 1.48x |
| 50 | unreachable | 1,765 | 2,959 | ∞ | 1.68x |
| 60 | unreachable | 1,244 | 1,985 | ∞ | 1.60x |
40 tok/s/user 处的 19 倍峰值部分源于区间延伸——2 月 TP=8 配方在并发 4 时有 24.5 ms 的 TPOT 下限(40.86 tok/s/user),在该工作负载上无法再降低,因此对比区间的上限恰好是旧配方已开始崩溃的位置。到 50 tok/s/user 时 v0.5.8 曲线已不存在;到 75 tok/s/user 时只有 v0.5.12 曲线仍有数据点。仅 5 月 v0.5.12 镜像就在整个共享区间内在 4 月基线基础上额外贡献了 1.44x 到 1.68x——这是纯粹的版本升级收益。
在线图表,已预筛选为 MI355X SGLang Qwen3.5 FP8 三次运行的数据。
MI355X 上 Qwen3.5 的下一步
- 分离式推理服务。 Qwen3.5 的 512 专家池恰好是分离式预填充/解码拆分能大显身手的场景。目前尚无 MI355X Qwen3.5 分离式配方,AMD 也尚未为 Qwen3.5 交付分离式推理方案。
致谢
这条三个月的性能提升曲线来自 AMD 的 zhentaocc(Todd Chen)和 yichiche(Jacky Cheng),他们编写了全部三个上游 SGLang PR,由 HaiShaw 审核并合入。上游到基准测试的闭环速度本身就是护城河。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。