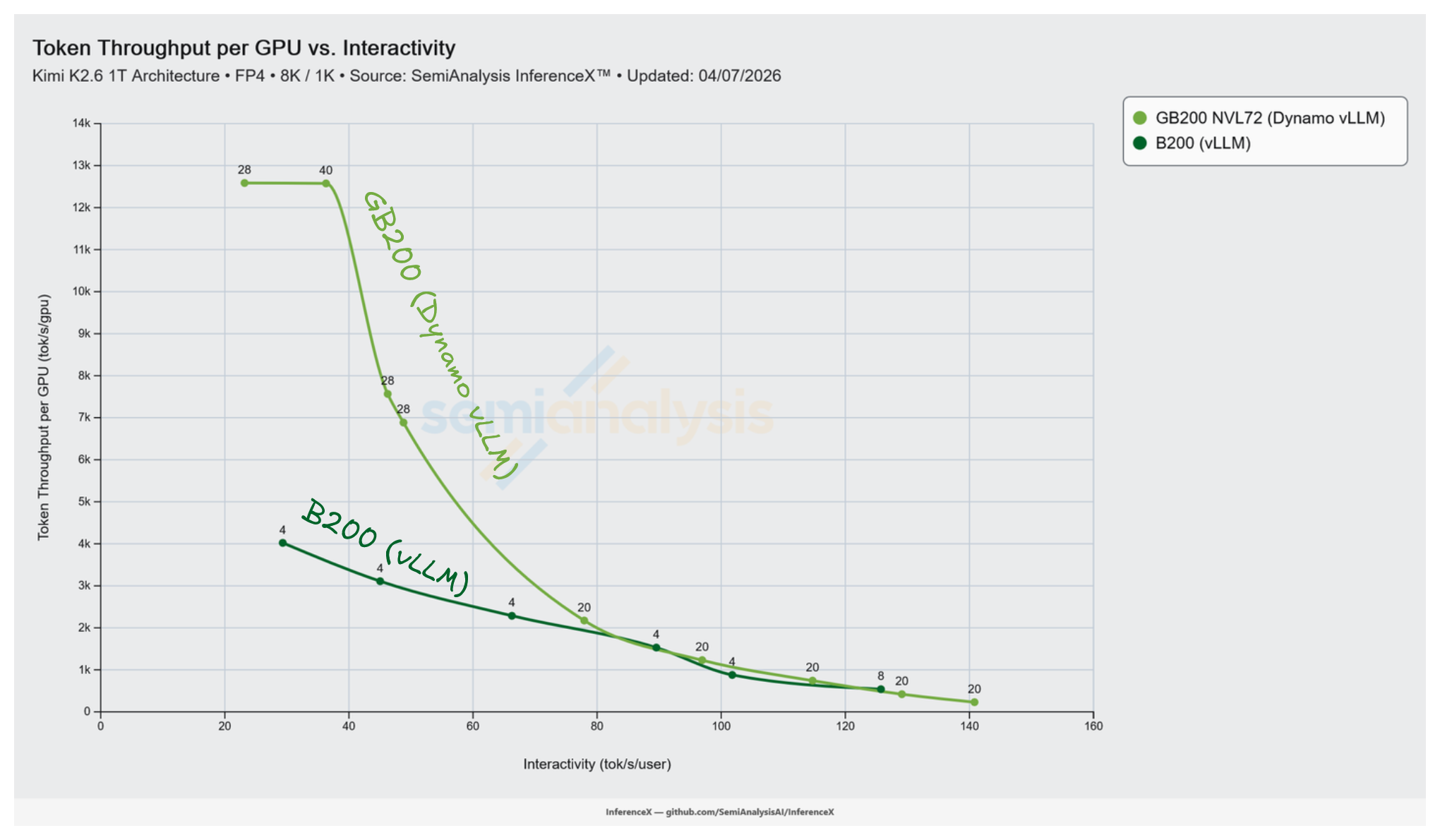
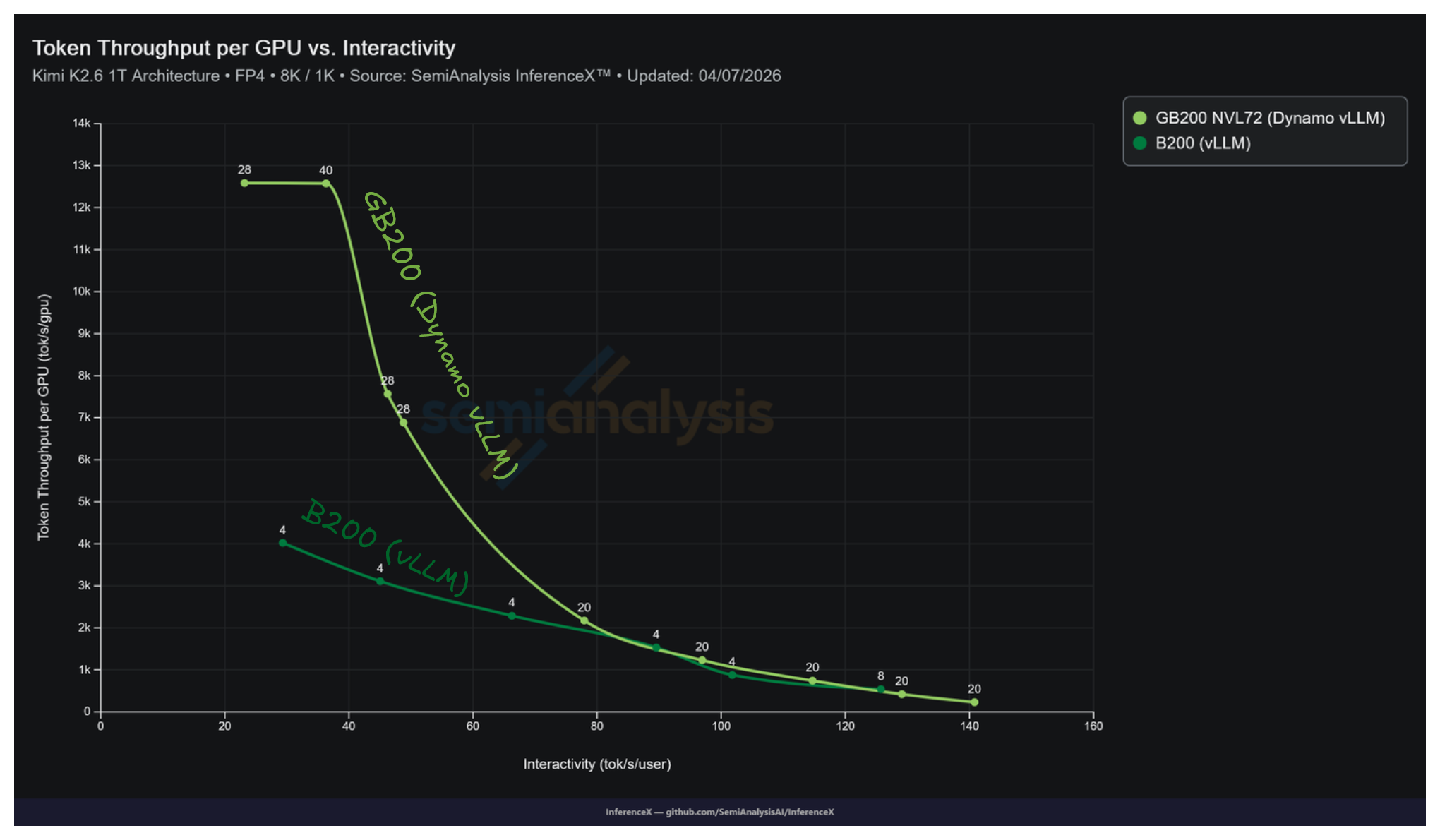
NVIDIA GB200 NVL72 运行 Dynamo vLLM 在 Kimi K2.5 NVFP4 8k/1k 上峰值达到 12,587 tok/s/GPU,而最优 B200 单节点 vLLM 配方在同一工作负载上峰值为 4,021 tok/s/GPU。这意味着每 GPU 峰值吞吐量有 3.13 倍的优势。NVL72 的机架级 NVLink 互联让解码端可以使用最高 Decode EP 16 的宽专家并行(在已测试的配方中),峰值配方为 8 GPU 解码池上的 Decode EP 8。B200 在最优实测配方上止步于 Decode EP 4。超过该点后,专家 all-to-all 通信开始受到 scale-out 互联延迟的制约。
Kimi K2.5 是一个 1T 参数的 MoE 模型,拥有 384 个路由专家加 1 个共享专家,每 token 激活 8 个专家,共 60 层 MoE 层。每个 MoE 层执行一次路由式 all-to-all 分发加一次 all-to-all 汇聚,因此单次前向传播在 60 层中总共约有 120 次 all-to-all 操作。在 NVL72 上,这些流量始终运行在 NVLink 5 上,每 GPU 1.8 TB/s,聚合互联带宽达 130 TB/s。而在 B200 上,宽 EP 超过 8 GPU 后就离开了 NVLink 域,退回到 ConnectX 7 InfiniBand 的每 GPU 400 Gb/s,约为 NVL72 NVLink 带宽的 1/36。稀疏度为 48 的 MoE(如 K2.5)无法在规模化时容忍这种差距。
宽 EP 对 Kimi K2.5 为何重要
在 EP 4 下,每个 GPU 持有 Kimi K2.5 384 个专家中的 96 个。解码受限于每步从 HBM 重新加载这些专家权重所需的显存带宽。将 EP 扩展到 16 会将每 GPU 的专家占用降至 24 个。每次专家权重读取被摊销到更大的有效批次上——更多对等 GPU 通过该 rank 分发 token。这使解码从权重带宽受限转向算力和通信受限。在这种模式下,Blackwell 的 FP4 tensor core 和 NVLink 带宽都能发挥优势。
扩宽 EP 的代价是每个 MoE 层增加一次 all-to-all 集合通信。如果该集合通信命中 scale-out 互联,交互性预算在吞吐量收益回本之前就会崩溃。NVL72 的 scale-up 域使得 EP 8 到 EP 16 的宽 EP 在 K2.5 解码池上可行。B200 的 8 GPU NVLink 域使得跨两个节点的 Decode EP 4 成为 scale-out 接管前的天花板。
峰值吞吐量与并发曲线
所有数据均为 Kimi K2.5 NVFP4、ISL 8192 / OSL 1024,在 InferenceX 上测量。B200 数据来自 2026-03-27 运行,由 InferenceX PR #926 触发,该 PR 在随机数据集上禁用了 Kimi K2.5 vLLM 基准测试的前缀缓存。GB200 NVL72 数据来自 2026-04-07 运行,由 InferenceX PR #1008 触发,该 PR 添加了 GB200 Dynamo vLLM 分离式多节点配方(vLLM 0.18.0、nvidia/Kimi-K2.5-NVFP4、NixlConnector KV 传输、FLASHINFER_MLA 注意力)。两次运行间隔 11 天。两者均为各自硬件上峰值吞吐量配方的最新可用数据。
B200 vLLM,2026-03-27 运行,非分离式,16 GPU 池:
| Prefill | Decode | Conc | tok/s/GPU | TPOT (ms) | tok/s/user |
|---|---|---|---|---|---|
| TP 4, EP 4 | TP 4, EP 4 | 4 | 878 | 9.8 | 101.8 |
| TP 4, EP 4 | TP 4, EP 4 | 8 | 1,529 | 11.2 | 89.5 |
| TP 4, EP 4 | TP 4, EP 4 | 16 | 2,286 | 15.1 | 66.3 |
| TP 4, EP 4 | TP 4, EP 4 | 32 | 3,108 | 22.2 | 45.0 |
| TP 4, EP 4 | TP 4, EP 4 | 64 | 4,021 | 34.1 | 29.3 |
GB200 NVL72 Dynamo vLLM,2026-04-07 运行,分离式:
| Prefill | Decode | Conc | tok/s/GPU | TPOT (ms) | tok/s/user |
|---|---|---|---|---|---|
| TP 4, EP 4 | TP 4, EP 4 | 4 | 231 | 7.1 | 140.8 |
| TP 4, EP 4 | TP 4, EP 4 | 8 | 421 | 7.7 | 129.1 |
| TP 4, EP 4 | TP 4, EP 4 | 16 | 744 | 8.7 | 114.7 |
| TP 4, EP 4 | TP 4, EP 4 | 32 | 1,230 | 10.3 | 96.9 |
| TP 4, EP 4 | TP 4, EP 4 | 128 | 2,173 | 12.8 | 77.9 |
| TP 4, EP 4 | TP 16, EP 16 | 512 | 6,885 | 20.5 | 48.8 |
| TP 4, EP 4 | TP 16, EP 16 | 1,024 | 7,565 | 21.6 | 46.2 |
| TP 4, EP 4 | TP 8, EP 8 | 2,048 | 12,587 | 43.1 | 23.2 |
| TP 4, EP 4 | TP 16, EP 16 | 4,096 | 12,576 | 27.5 | 36.3 |
B200 在并发 64 时每 GPU 吞吐量饱和于 4,021 tok/s,此时 16 GPU 池已满载。NVL72 持续吸收并发直到 2,048 甚至更高。解码池是 8 到 16 个 GPU 的宽 EP 运行在 scale-up 互联上。增加用户使 MoE all-to-all 保持带宽受限而非延迟受限。
等交互性对比
在 B200 峰值吞吐量工作点(并发 64,29.3 tok/s/user,4,021 tok/s/GPU)处,最接近的 GB200 NVL72 数据点为:
| 交互性 (tok/s/user) | GB200 NVL72 tok/s/GPU | 配置 |
|---|---|---|
| 36.3 | 12,576 | Decode TP 16, EP 16 at conc 4,096 |
| 23.2 | 12,587 | Decode TP 8, EP 8 at conc 2,048 |
GB200 NVL72 在 23 到 36 tok/s/user 区间内维持约 12,580 tok/s/GPU 的平台,在接近 B200 峰值的等交互性下给出 3.13 倍的吞吐量比率。
在线图表,已预筛选为 4 月 7 日的 Kimi K2.5 数据。
NVL72 上的 vLLM 宽 EP
vLLM 在 v0.9 中推出了 PPLX all-to-all 后端,随后添加了 DeepEP。v0.11 完成了 V1 引擎迁移,并通过 PR #24845 扩展了双批重叠(DBO,Dual Batch Overlap)路径,添加了 DeepEP 高吞吐量内核以及 DBO 的预填充支持,使 all-to-all 通信可以隐藏在计算之后。上述基准测试运行的是 v0.18.0,未启用投机解码。
GB200 NVL72 配置在 NVIDIA Dynamo 中以 vLLM 作为 worker 运行时,在 InferenceX 数据集中标记为 dynamo-vllm。Dynamo 将预填充(4 GPU、TP 4、EP 4)与解码(8 到 16 GPU,TP 和 EP 均扩展至 16)分离,并通过 NVL72 互联在两者之间路由请求。SGLang 和 TRT-LLM 在 NVL72 上也有类似的分离式 + 宽 EP 路径,其中 SGLang 公开的 GB200 结果目前最为成熟。
各 SKU 的优势场景
B200 在 16 GPU 池上以 30 tok/s/user 的交互性提供约 4k tok/s/GPU。TP 4、EP 4 配方在并发 64 附近饱和。超过此点后延迟下限崩溃。
GB200 NVL72 在并发 2,048 到 4,096 范围内以 23 到 36 tok/s/user 的交互性提供 12.5k tok/s/GPU。已测试的单节点 B200 配方没有可比的工作点。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。