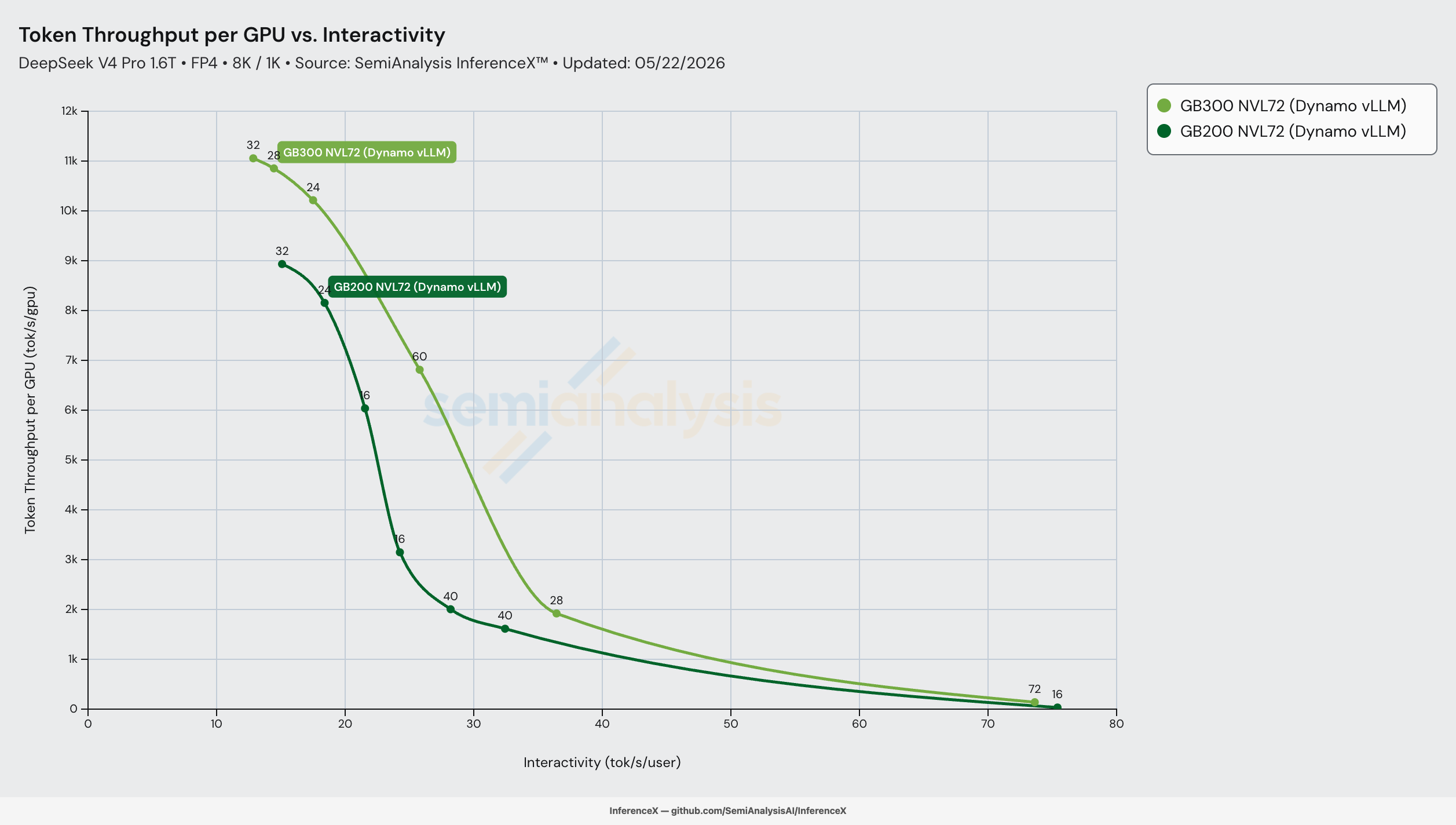
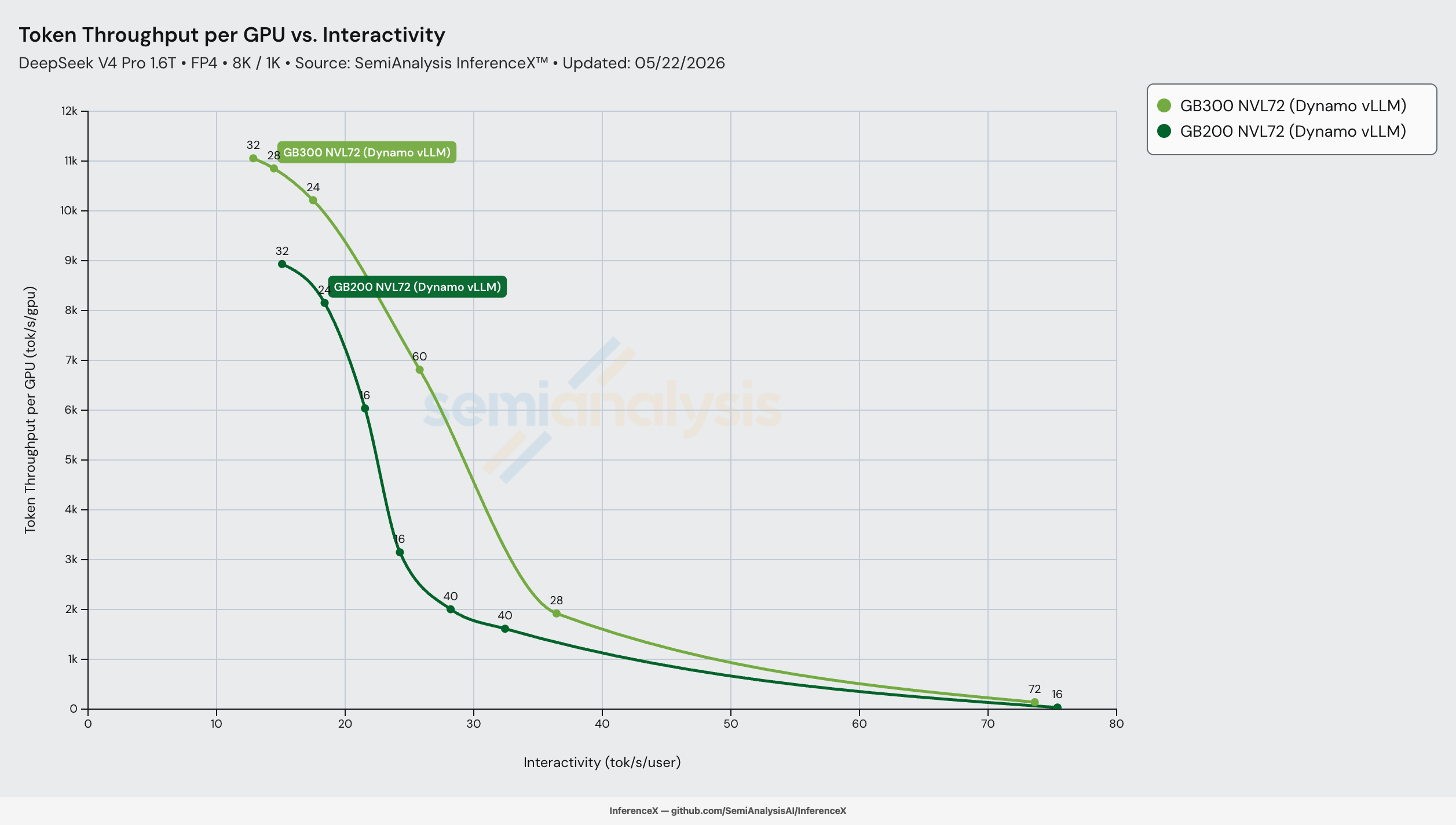
在 DeepSeek-V4-Pro FP4、8K/1K 输入输出长度、Dynamo vLLM 框架以及两套机架均启用分离式预填充/解码的条件下,GB300 NVL72 在等交互性下每 GPU 吞吐量最高达 GB200 NVL72 的 2.83 倍,峰值出现在 27 tok/s/user(GB300 为 6,182 tok/s/GPU,GB200 为 2,189 tok/s/GPU)。纸面上两者的硅片差异看似不大——相同的显存带宽、相同的 NVLink 互联、相同的 scale-up 规模,仅多出 1.5 倍 HBM 容量和 1.5 倍 FP4 算力——但曲线中段的差距远超任何静态比率,因为 GB300 额外的 HBM 消除了 GB200 必须为之付出代价的一个软件约束。
其机制在于 HBM 余量。DSv4-Pro 1.6T 参数量下,仅 FP4 权重就约占 800 GB,GB200 在窄预填充形态下可用 HBM 相当紧张,配方不得不在批大小上做出妥协以将模型装入显存。GB300 的 1.5 倍 HBM 容量(每 GPU 288 GB vs 192 GB)在相同形态下仍有数百 GB 的余量,使得预填充可以运行更大的批次来保持更宽解码池的饱和。在每 GPU TCO 溢价 20%($2.65 vs $2.21/GPU/hr,数据来自 SemiAnalysis AI Cloud TCO 模型)之后,GB300 在 27 tok/s/user 下每百万 token 的成本仍便宜 2.31 倍。更多 HBM,更多节省。
DeepSeek-V4-Pro 模型架构
DeepSeek-V4-Pro 是 DeepSeek 的旗舰 MoE 模型:总参数量 1.6T,每 token 激活 49B(来自 DeepSeek V4 预览公告)。该架构将 token 级压缩与 DSA(DeepSeek 稀疏注意力) 结合——这是 DeepSeek 在 V3.2 中引入的稀疏注意力模式,并扩展到更长的上下文(官方服务默认以 1M 上下文运行 DSv4)。开源权重检查点为 deepseek-ai/DeepSeek-V4-Pro。
纸面规格对比
GB300 NVL72(Blackwell Ultra)和 GB200 NVL72(Blackwell)共享相同的 NVLink 5 scale-up 互联、相同的 72 GPU 规模、相同一代 NVSwitch 以及相同的每 GPU 8 TB/s HBM 带宽。差异在于 HBM 容量和 dense FP4 算力。数值直接取自 /gpu-specs:
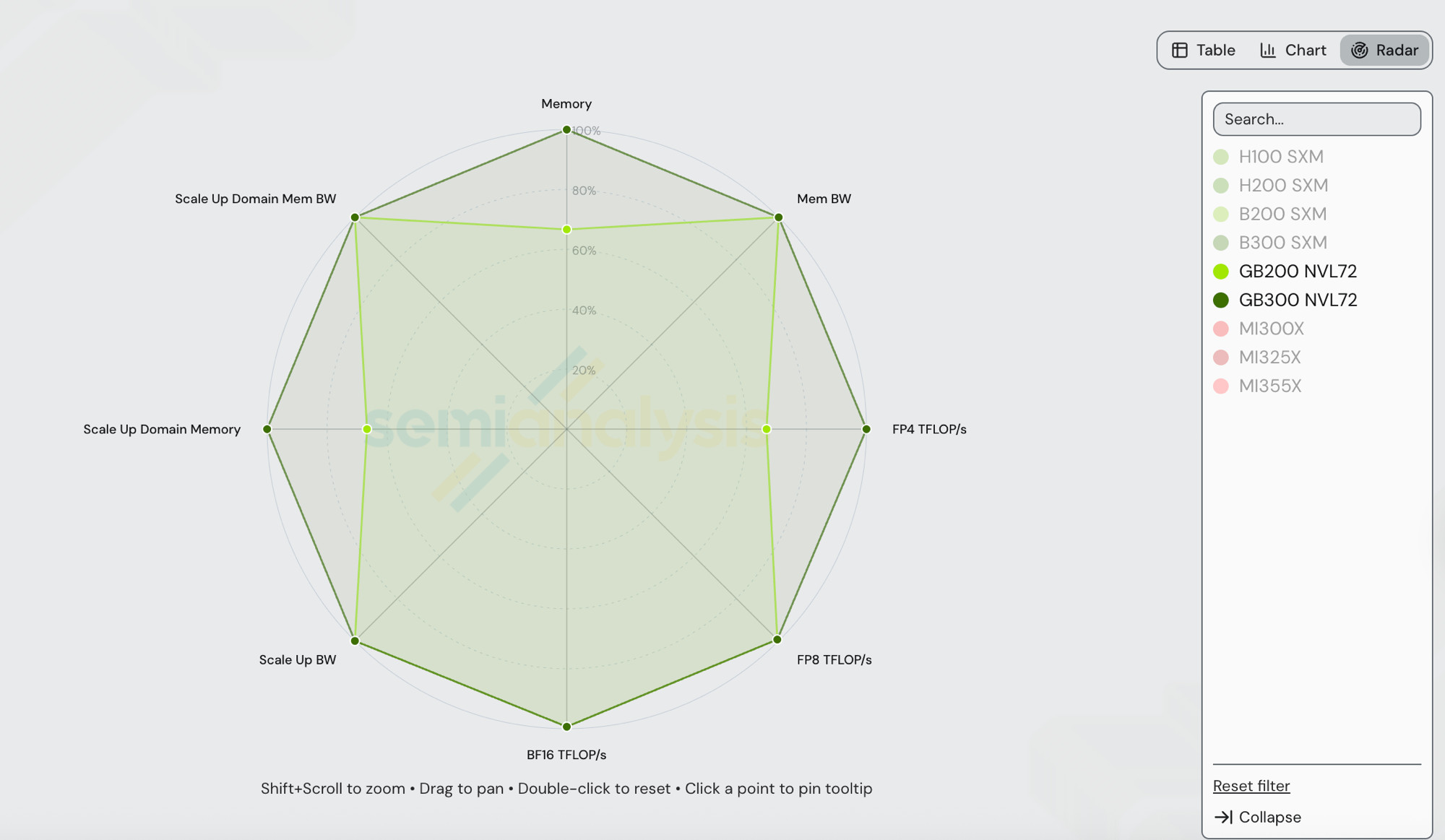
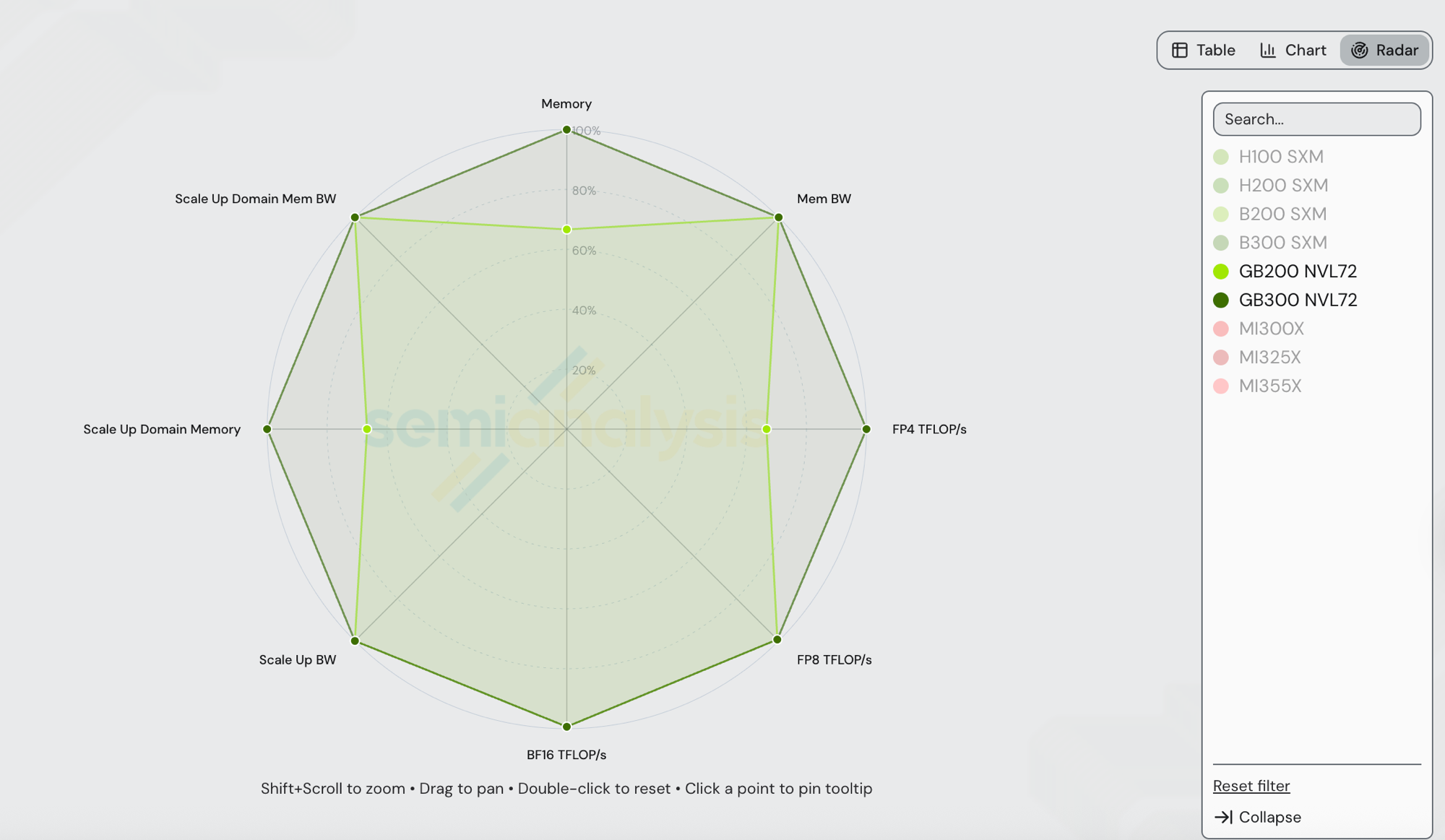
| 规格 | GB200 NVL72 | GB300 NVL72 | GB300 / GB200 |
|---|---|---|---|
| HBM 容量 | 192 GB | 288 GB | 1.50x |
| HBM 带宽 | 8 TB/s | 8 TB/s | 1.00x |
| Dense FP4 (TFLOP/s) | 10,000 | 15,000 | 1.50x |
| Dense FP8 (TFLOP/s) | 5,000 | 5,000 | 1.00x |
| Dense BF16 (TFLOP/s) | 2,500 | 2,500 | 1.00x |
| 每 GPU Scale-up 带宽(单向) | 900 GB/s (NVLink 5) | 900 GB/s (NVLink 5) | 1.00x |
| Scale-up 规模 | 72 | 72 | 1.00x |
| Scale-up 域 HBM 容量 | 13.5 TB | 20.25 TB | 1.50x |
| Scale-up 域 HBM 带宽(聚合) | 576 TB/s | 576 TB/s | 1.00x |
| TCO(SemiAnalysis AI Cloud 模型) | $2.21/GPU/hr | $2.65/GPU/hr | 1.20x |
如果解码纯粹受 HBM 带宽限制,预填充纯粹受 FP4 算力限制,则纸面性价比上限在任一瓶颈上均为 1.50 / 1.20 = 1.25x。实测 2.31 倍性价比峰值比该上限高出 1.85 倍——这正是本文的核心要点。提升来自一个 硅片比率低估系统增益的区间:HBM 容量是一个离散的解锁条件(决定哪种配方能装下),而非连续旋钮;一种配方在一套机架上能跑而另一套跑不了所带来的倍数增益,不会出现在任何规格表上。
分离式部署 + 宽 EP 实际带来了什么
稀疏 MoE 的推理有两个资源特征截然相反的阶段。预填充受算力限制:请求中的每个 token 都并行通过整个模型处理,因此 DSv4-Pro 的 384 个路由专家在每个提示的每一层都被全部激活。解码受显存带宽限制:每个生成 token 每层仅激活 384 个路由专家中的 6 个(加 1 个共享专家),每步开销主要取决于从 HBM 流式读取被路由到的专家权重。在相同 GPU 上同时运行两者,预填充的突发流量会不断干扰解码的稳态运行,最终两者都无法充分利用。
分离式部署将两者拆分到独立调优的 GPU 池中。预填充实例以足够宽的配置运行,以摊销全专家激活的计算步骤;解码实例以最佳的 (TP, EP, DP) 形态运行,以在稳态负载下获得最大的每步 token 数。两个池通过 NVLink 互联通信(预填充 → 解码的 KV 传输),且可独立扩展。
宽专家并行(EP) 则将解码侧的路由专家分片到多个 rank 上。在 EP=4 时,每个 GPU 持有 DSv4-Pro 384 个路由专家中的 96 个,所有这些都必须常驻 HBM 并随时准备响应路由到它们的 token。在 EP=8 时每 GPU 持有 48 个。在 EP=16 时每 GPU 持有 24 个——每 rank 的路由专家权重占用近似线性缩减,余下的 HBM 用于 KV 缓存和激活值。分片越宽,每个 GPU 的 HBM 带宽在服务路由到其专家的请求时分摊越均匀,每 GPU 解码效率也就越高。EP 组中每增加一个 rank 都在为其他所有 rank 做有用功——这就是"买得越多,省得越多"的杠杆,应用的不是批量硬件折扣,而是实际的硅片利用率。
代价在于宽 EP 需要在每个 MoE 层的专家 GEMM 前后分别执行一次路由式 all-to-all 分发和 all-to-all 汇聚。在 DSv4-Pro 的 MoE 层中,这意味着每个 token 需要数百次集合通信。它们必须在 GEMM 计算背后重叠,否则就暴露为裸延迟。在 NVLink 5 上(每 GPU 单向 900 GB/s,双向 1.8 TB/s),该分发在 EP=8 到 EP=16 的中等批解码中可以嵌入 GEMM 时间预算内,运行时将其隐藏。而在 scale-out 侧(ConnectX-7 RoCEv2 Ethernet 或 InfiniBand,每 GPU 单向 50 GB/s,慢 18 倍),相同的集合通信需要 18 倍时间并暴露为延迟——这就是为什么宽 EP 需要机架级 NVLink 域,也是为什么无论谁先出货,GB200 NVL72 和 GB300 NVL72 在该负载上都优于任何 8-GPU HGX 节点。
测试数据
所有行均为 DeepSeek-V4-Pro FP4、ISL 8192 / OSL 1024、NVL72、Dynamo vLLM、分离式预填充/解码、无投机解码,在 InferenceX 上于 2026-05-22 测量(GHA 运行编号 26306422380)。每百万总 token 成本按 TCO_$/GPU/hr × 1e6 / (3600 × tput_per_gpu) 计算,GB200 NVL72 为 $2.21/GPU/hr,GB300 NVL72 为 $2.65/GPU/hr,来自 SemiAnalysis AI Cloud TCO 模型。
GB200 NVL72 (Dynamo vLLM),DSv4-Pro FP4 8K/1K 分离式:
| Conc | Prefill | Decode | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tok |
|---|---|---|---|---|---|---|
| 1 | 8 GPU, TP=8 | 8 GPU, EP=1 | 32.8 | 74.13 | 13.26 | $18.72 |
| 256 | 8 GPU, TP=8 | 32 GPU, EP=1 | 1,613.8 | 32.69 | 30.83 | $0.38 |
| 512 | 8 GPU, TP=8 | 32 GPU, EP=1 | 2,004.5 | 28.31 | 35.46 | $0.31 |
| 256 | 8 GPU, TP=8 | 8 GPU, EP=8 | 3,148.0 | 24.42 | 41.23 | $0.20 |
| 512 | 8 GPU, TP=8 | 8 GPU, EP=8 | 5,336.2 | 21.26 | 47.43 | $0.10 |
| 1024 | 8 GPU, TP=8 | 8 GPU, EP=8 | 6,036.2 | 21.60 | 46.42 | $0.10 |
| 4096 | 16 GPU, TP=8 | 8 GPU, EP=8 | 8,153.1 | 18.51 | 54.34 | $0.08 |
| 4096 | 24 GPU, TP=8 | 8 GPU, EP=8 | 8,933.0 | 15.26 | 66.26 | $0.07 |
GB300 NVL72 (Dynamo vLLM),DSv4-Pro FP4 8K/1K 分离式:
| Conc | Prefill | Decode | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tok |
|---|---|---|---|---|---|---|
| 18 | 4 GPU, TP=4 | 68 GPU, EP=1 | 138.8 | 73.43 | 13.58 | $5.31 |
| 192 | 4 GPU, TP=4 | 24 GPU, EP=1 | 1,920.0 | 36.78 | 27.44 | $0.38 |
| 3072 | 28 GPU, TP=8 | 32 GPU, EP=16 | 6,812.0 | 25.91 | 38.77 | $0.11 |
| 4096 | 16 GPU, TP=8 | 8 GPU, EP=8 | 10,214.0 | 17.58 | 57.12 | $0.07 |
| 4096 | 20 GPU, TP=8 | 8 GPU, EP=8 | 10,853.1 | 14.74 | 69.17 | $0.07 |
| 4096 | 24 GPU, TP=8 | 8 GPU, EP=8 | 11,055.6 | 13.12 | 77.83 | $0.07 |
GB200 的每 GPU 峰值吞吐量为 8,933,交互性为 15.3 tok/s/user。GB300 的峰值为 11,056,交互性为 13.1 tok/s/user——在更低交互性下限处,每 GPU 吞吐量高出 1.24 倍,计入软件开销后接近 1.5 倍的硅片比率。峰值处的单位成本性价比基本持平($0.069 vs $0.067),因为 GB300 的 20% TCO 溢价吃掉了 1.24 倍吞吐提升的大部分。标题中的倍数差异出现的位置不在峰值,而在曲线中段——GB300 的 HBM 余量在那里带来了 GB200 不具备的配方。
等交互性对比
在匹配交互性下的每 GPU 吞吐量和每百万 token 成本,沿各 SKU 的 Pareto 前沿插值。超出前沿实测范围的单元格标记为 _unreachable_。
| 交互性 (tok/s/user) | GB200 tok/s/GPU | GB300 tok/s/GPU | GB300 / GB200 | GB200 $/M tok | GB300 $/M tok | GB200 / GB300 |
|---|---|---|---|---|---|---|
| 16 | 8,835 | 10,608 | 1.20x | $0.07 | $0.07 | 1.00x |
| 18 | 8,366 | 10,094 | 1.21x | $0.07 | $0.07 | 1.01x |
| 20 | 7,283 | 9,401 | 1.29x | $0.08 | $0.08 | 1.07x |
| 22 | 5,650 | 8,562 | 1.52x | $0.11 | $0.08 | 1.31x |
| 25 | 2,846 | 7,208 | 2.53x | $0.21 | $0.10 | 2.11x |
| 27 | 2,189 | 6,182 | 2.83x | $0.28 | $0.12 | 2.31x |
| 28 | 2,058 | 5,789 | 2.81x | $0.30 | $0.13 | 2.30x |
| 32 | 1,661 | 3,570 | 2.15x | $0.36 | $0.21 | 1.76x |
| 36 | 1,376 | 2,036 | 1.48x | $0.65 | $0.35 | 1.88x |
| 50 | 649 | 941 | 1.45x | $4.78 | $1.58 | 3.03x |
标题中 2.83 倍每 GPU 吞吐量峰值出现在 27 tok/s/user(性价比 2.31 倍),位于曲线中段而非峰值吞吐处。在 20 tok/s/user 以下,两套机架都运行足够宽的预填充批次,HBM 余量优势被抹平;在 36 tok/s/user 以上,两者都运行窄批次,没有哪套机架拥有宽 EP 能充分利用的配方。22–32 tok/s/user 区间是 GB300 的 1.5 倍 HBM 容量让其停留在一个更高 Pareto 节点上的地方(conc=3072, 28 GPU 预填充, 32 GPU 解码 EP=16, 6,812 tok/s/GPU at 25.9 tok/s/user),而 GB200 在同等交互性下没有等效配方——其最接近的配方是在 32-GPU 解码池上 conc=256 / 512,仅能提供 1,614–2,005 tok/s/GPU。
50 tok/s/user 行显示成本比率(3.03x)再次扩大,因为两条曲线都进入了右侧的陡峭衰减区。这里的解读需要更谨慎——两套机架在该区域的 Pareto 覆盖都很薄(GB200 在约 33 tok/s/user 处各有一个节点,GB300 在约 37 tok/s/user 处各有一个节点,然后是到约 73 tok/s/user 的长尾),因此插值是在两个间隔较大的实测节点之间读取差距。22–32 tok/s/user 区间才是 GB300 优势的可靠甜蜜点;将 50 tok/s/user 行视为方向性参考。
在线图表,已预筛选为 2026-05-22 运行中 GB200 NVL72 和 GB300 NVL72 Dynamo vLLM 的 DSv4-Pro FP4 8K/1K 数据。
致谢
感谢 NVIDIA 的 Dynamo 和 vLLM 团队——包括 Jatin Gangani、Kedar Potdar、Sridhar Ramaswamy、Ishan Dhanani 和 Sahithi Chigurupati——以及 vLLM 团队,是他们将 GB200 和 GB300 的 DSv4-Pro 配方交付落地,使得机架间对比成为可能。配套文章:GB200 NVL72 vs B200 DeepSeek R1 对比,覆盖了 SKU 梯队下一级的 scale-up 互联优势。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。