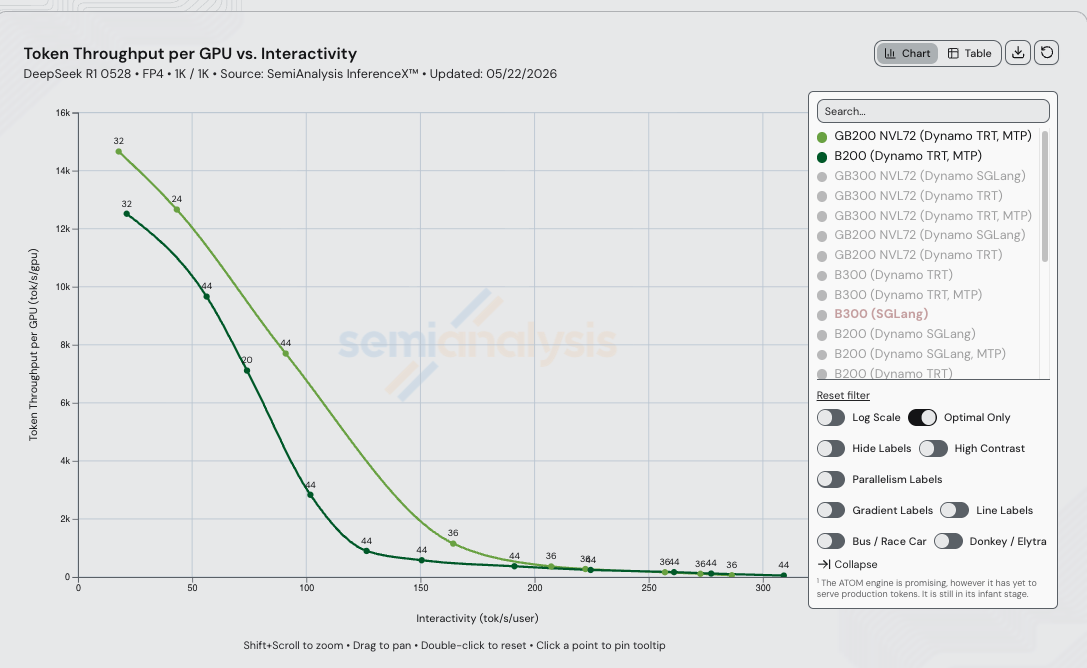
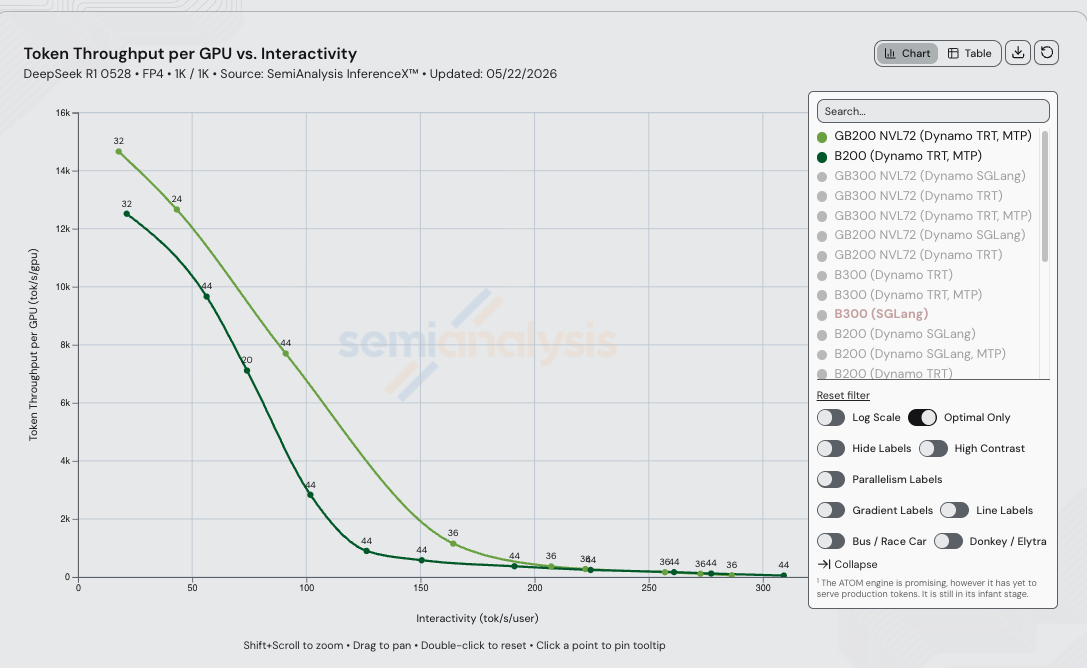
在 DeepSeek R1 0528 FP4 1k/1k 工作负载下,使用 Dynamo TRT-LLM + MTP 并在两款 SKU 上均采用分离式预填充/解码,GB200 NVL72 在等交互性下的每 GPU 吞吐量最高可达 B200 的 4.39 倍 — 峰值出现在 125 tok/s/user(GB200 NVL72 为 4,130 tok/s/GPU,B200 为 941 tok/s/GPU)。
NVIDIA GB200 NVL72 通过 NVLink 5 连接全部 72 块 GPU,单向带宽 900 GB/s/GPU(双向 1.8 TB/s,Jensen 计算法 rx + tx 之和)。B200 服务器仅通过 NVLink 连接 8 块 GPU;当解码 EP 需要超过 8 个 rank 时,all-to-all 通信必须离开 NVLink 岛,转而通过 ConnectX-7 RoCEv2 以太网,每 GPU 400 Gbit/s。因此任何超过 8 路 EP 的集合通信可用每 GPU 带宽从 900 GB/s 降至 50 GB/s,降幅 18 倍。DeepSeek R1 的 256 个路由专家在 all-to-all 通信全程通过 NVLink 在 16 或 32 个 rank 间传输时能充分摊薄开销。


DeepSeek R1 0528 是 DeepSeek 于 2025 年 5 月发布的 671B 参数 MoE 模型 — 采用多头潜在注意力(MLA)进行 KV 缓存压缩,256 个路由专家中每 token 激活 8 个外加 1 个共享专家,共 61 层 transformer。每个 MoE 层在每次前向传播时触发一次路由 all-to-all 分发(dispatch)和一次 all-to-all 汇聚(combine):大约每 token 120 次 all-to-all 通信。这一通信量级正是 NVLink 级别扩展带宽的用武之地。
GB200 NVL72 为何在曲线中段胜出
在曲线中段 — 该工作负载下大约 75–175 tok/s/user — 解码变为网络受限,瓶颈在 EP 分发和汇聚集合通信上。每个 MoE 层在每 token 触发两次 all-to-all 集合通信:一次分发,将每个 token 路由到被分配的 256 个专家中的 8 个(在宽 EP 下通常位于远程 rank 上);一次汇聚,将专家输出收集回每个 token 的主 rank。在 DeepSeek R1 的约 60 个 MoE 层中,每次前向传播大约有 120 次集合通信。
当网络足够快时,运行时可以将每次分发和汇聚与其所服务的矩阵乘法计算重叠:发起分发,对已到达的 token 开始专家 GEMM 计算,在剩余字节到达期间大致完成 GEMM,然后发起汇聚。集合通信延迟基本从关键路径上消失,因为 GPU 始终在执行有用的计算。
在 ConnectX-7 RoCEv2 以太网每 GPU 50 GB/s — 比 NVLink 低 18 倍的每 rank 带宽下 — 这种重叠无法实现。同样的集合通信每字节传输时间长达 18 倍,不再能适配 GEMM 时间预算,暴露为纯粹的通信等待时间。
基准测试数据
所有数据均为 DeepSeek R1 0528 FP4,ISL 1024 / OSL 1024,Dynamo TRT-LLM 启用 MTP,两款 SKU 均采用分离式预填充/解码、多节点部署,于 2026-05-22 在 InferenceX 上测量(run 26306422380)。每百万总 token 成本计算方式为 TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6),B200 为 $1.95/GPU/hr,GB200 NVL72 为 $2.21/GPU/hr,数据来源 SemiAnalysis AI Cloud TCO 模型。
GB200 NVL72(Dynamo TRT,MTP),DeepSeek R1 FP4 1k/1k 分离式部署:
| 并发数 | 预填充 | 解码 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tok |
|---|---|---|---|---|---|---|
| 4 | 4 GPU, TP=4 | 32 GPU, EP=8 | 60.7 | 286.40 | 3.49 | $10.12 |
| 8 | 4 GPU, TP=4 | 32 GPU, EP=8 | 111.8 | 272.64 | 3.67 | $5.49 |
| 12 | 4 GPU, TP=4 | 32 GPU, EP=8 | 165.2 | 257.11 | 3.89 | $3.72 |
| 24 | 4 GPU, TP=4 | 32 GPU, EP=8 | 274.8 | 222.28 | 4.50 | $2.23 |
| 48 | 4 GPU, TP=4 | 32 GPU, EP=8 | 363.3 | 207.30 | 4.82 | $1.69 |
| 180 | 4 GPU, TP=4 | 32 GPU, EP=32 | 1,149.1 | 164.37 | 6.08 | $0.53 |
| 2,253 | 12 GPU, TP=12 | 32 GPU, EP=32 | 7,698.0 | 90.99 | 10.99 | $0.08 |
| 4,301 | 8 GPU, TP=8 | 16 GPU, EP=16 | 12,659.7 | 43.29 | 23.10 | $0.05 |
| 16,130 | 12 GPU, TP=12 | 20 GPU, EP=4 | 14,659.4 | 17.82 | 56.11 | $0.04 |
B200(Dynamo TRT,MTP),DeepSeek R1 FP4 1k/1k 分离式多节点部署:
| 并发数 | 预填充 | 解码 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tok |
|---|---|---|---|---|---|---|
| 6 | 4 GPU, TP=4 | 40 GPU, EP=8 | 49.3 | 309.17 | 3.23 | $10.99 |
| 10 | 4 GPU, TP=4 | 40 GPU, EP=8 | 118.7 | 277.39 | 3.61 | $4.56 |
| 15 | 4 GPU, TP=4 | 40 GPU, EP=8 | 168.9 | 261.09 | 3.83 | $3.21 |
| 25 | 4 GPU, TP=4 | 40 GPU, EP=8 | 242.4 | 224.59 | 4.45 | $2.23 |
| 45 | 4 GPU, TP=4 | 40 GPU, EP=8 | 369.9 | 191.18 | 5.23 | $1.46 |
| 90 | 4 GPU, TP=4 | 40 GPU, EP=8 | 577.3 | 150.56 | 6.64 | $0.94 |
| 180 | 4 GPU, TP=4 | 40 GPU, EP=8 | 897.9 | 126.42 | 7.91 | $0.60 |
| 875 | 4 GPU, TP=4 | 40 GPU, EP=8 | 2,832.9 | 101.79 | 9.82 | $0.19 |
| 1,214 | 4 GPU, TP=4 | 16 GPU, EP=8 | 7,111.4 | 74.04 | 13.51 | $0.08 |
| 4,968 | 12 GPU, TP=12 | 32 GPU, EP=8 | 9,660.7 | 56.35 | 17.75 | $0.06 |
| 10,860 | 12 GPU, TP=12 | 20 GPU, EP=4 | 12,515.7 | 21.34 | 46.86 | $0.04 |
等交互性吞吐量对比
| 交互性 (tok/s/user) | GB200 NVL72 tok/s/GPU | B200 tok/s/GPU | GB200 NVL72 / B200 |
|---|---|---|---|
| 25 | 14,125 | 12,292 | 1.15x |
| 45 | 12,508 | 10,853 | 1.15x |
| 60 | 11,017 | 9,185 | 1.20x |
| 75 | 9,379 | 6,968 | 1.35x |
| 90 | 7,796 | 4,512 | 1.73x |
| 100 | 6,781 | 3,047 | 2.23x |
| 125 | 4,130 | 941 | 4.39x |
| 150 | 1,922 | 583 | 3.30x |
| 175 | 826 | 429 | 1.93x |
| 200 | 432 | 332 | 1.30x |
| 225 | 262 | 241 | 1.09x |
| 250 | 186 | 193 | 0.97x |
| 275 | 103 | 126 | 0.82x |
| 300 | 不可达 | 67 | ∞(B200 胜出) |
以及同一对比按每百万 token 成本归一化的结果,GB200 NVL72 每 GPU 小时 TCO 高 13%($2.21 vs $1.95)削弱了其吞吐量优势:
| 交互性 (tok/s/user) | GB200 NVL72 $/M tok | B200 $/M tok | B200 / GB200 NVL72 |
|---|---|---|---|
| 25 | $0.0435 | $0.0441 | 1.01x |
| 45 | $0.0491 | $0.0499 | 1.02x |
| 60 | $0.0557 | $0.0590 | 1.06x |
| 75 | $0.0655 | $0.0777 | 1.19x |
| 100 | $0.0905 | $0.1778 | 1.96x |
| 125 | $0.1486 | $0.5755 | 3.87x |
| 150 | $0.3194 | $0.9292 | 2.91x |
| 175 | $0.7430 | $1.2638 | 1.70x |
| 200 | $1.4215 | $1.6314 | 1.15x |
| 225 | $2.3450 | $2.2454 | 0.96x |
| 250 | $3.2962 | $2.8067 | 0.85x(B200 胜出) |
4.39 倍的吞吐量峰值(3.87 倍的成本差距)出现在 125 tok/s/user,此时宽 EP 跨 NVLink 互联域发挥最大作用。
实时图表,预筛选为 2026-05-22 测试中 B200 和 GB200 NVL72 Dynamo TRT MTP 在 DeepSeek R1 FP4 1k/1k 上的结果。
各 SKU 的优势区间
- GB200 NVL72 Dynamo TRT 在 75 至 200 tok/s/user 区间内是最佳选择,此区间内 72-GPU NVLink 互联域支撑的宽 EP 是主导因素。成本差距在 125 tok/s/user 时达到峰值,GB200 NVL72 便宜 3.87 倍 — 聊天式和推理服务在生产级交互性目标下恰好落在此区间。
NVIDIA 的 SGLang GB200 NVL72 结果在 SGLang 软件栈上展现了相同的扩展域优势。AMD 的 MI300/MI355X 在 2026 年下半年工程样片之前没有对应的机架级 UALoE72 产品出货,因此目前在 AMD 侧无法进行该工作负载的机架级对比。
致谢
感谢 NVIDIA 的 Dynamo 和 TensorRT-LLM 团队 — 包括 Jatin Gangani、Kedar Potdar、Sridhar Ramaswamy、Ishan Dhanani 和 Sahithi Chigurupati — 交付了 B200 多节点 RoCEv2 和 GB200 NVL72 上的分离式部署方案。请查看我们另一篇关于 GB200 NVL72 对比 B200 运行 Kimi K2.5 的博文。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。