本文最初于 2026 年 6 月 9 日发布在 SemiAnalysis 通讯。
DeepSeek v4 的发布标志着开源模型社区又迈出了重要一步——毫不意外,它再次出自中国实验室之手。其推理性能的演进对整个 AI 生态系统至关重要。开源 InferenceX 工程团队连续多个通宵,在第 0 天、第 1 天、第 2 天及之后持续测量该模型的性能表现,并将结果公之于众。在本文中,我们将重点介绍 DeepSeek v4 的第 0 天性能,并解释模型发布后数周内所取得的重大改进。我们还将阐述 DeepSeek v4 模型架构的核心组件,并探讨其部分设计如何针对 Huawei Ascend 推理进行了协同优化。
在博客文章的第二节中,我们对 DeepSeekv4 在 Huawei Ascend 950DT 上的第 0 天推理进行了全面分析。本文是 Ascend 950DT 上 DeepSeekv4 推理的首篇分析报告,我们详细拆解了 Huawei 为优化性能所做的计算↔通信重叠以及不同的计算流设计。
InferenceX 的一个核心目标,尤其是在模型第 0 天发布窗口期间,是使用开源镜像和配方,尽可能多地在各种框架上记录每种 SKU 的性能表现,无论这些镜像和配方的实际性能如何。这使我们能够追踪性能的持续改进,我们认为这最能反映每种芯片真实可部署的性能。下方视频展示了 vLLM/SGLang 从第 0 天起非 MTP 配置的迭代改进过程。访问 inference.com 查看从第 0 天起的 MTP 配置。
vLLM 非 MTP DeepSeek V4 Pro 配置从第 0 天起的改进过程。来源:SemiAnalysis InferenceX
这些图表反映了数千小时的工程投入,用于调优 DeepSeek v4 推理性能,且大部分优化已合并到 SGLang/vLLM 的主分支。InferenceX 的核心目标之一是展示性能随时间的迭代改进,而非仅仅呈现性能的静态快照。毕竟在工程领域,探索过程中学到的东西往往与最终结果同等重要。
SGLang 非 MTP DeepSeek V4 Pro 配置从第 0 天起的改进过程。来源:SemiAnalysis InferenceX
在 DeepSeek v4 Pro 发布初期,CUDA vLLM、CUDA SGLang 以及 CUDA vLLM 分离式 prefill 均可开箱即用且表现出色,这证明了 vLLM 和 SGLang 开源生态的强大实力。这两个推理引擎对全球 ML 生态系统至关重要,以至于两个团队都已成立自己的公司——Inferact 和 RadixArk,各自融资数亿美元以持续推动其开源推理引擎的发展。
Huawei Ascend 也在其文档中描述并展示了 DeepSeekV4 的第 0 天推理性能支持。目前中国在开源模型领域占据主导地位,Kimi K2.6 在编程方面仍然击败了 Jensen 的 Nemotron Committee Coalition 的 Nemotron 3 Ultra。此外,Nvidia 自研的 TensorRT-LLM 对 DeepSeek v4 的支持不佳,我们 SemiAnalysis 不得不修复了他们开源的 mHC kernel 启动代码。感谢 NVIDIA 工程师的 rebase 和合并我们的补丁!
ROCm 在 DeepSeek v4 发布的头几天同样表现不佳。不过,在 HaiShaw 的技术领导下,AMD SGLang 工程团队在首月内大幅提升了性能——在第 26 天实现了超过 100 倍的性能提升。我们将在即将发布的综合性 State of AMD 2026 文章中更多地讨论 AMD 软件进展的优劣。
所有性能追踪数据均记录在我们的开源 GitHub 仓库中。如果您觉得这个仓库有用,欢迎给我们一个 star:https://github.com/SemiAnalysisAI/InferenceX。
SemiAnalysis InferenceX 推理项目得到了 ML 社区众多伙伴的支持,包括 OpenAI、Oracle、Microsoft、Weka、PyTorch Foundation、vLLM、SGLang 和 CoreWeave 等。

InferenceX 团队非常感谢 vLLM 社区维护者和 Inferact 持续投入的工程努力,也感谢全球各地的 SGLang 维护者——来自 RadixArk、Meta 及其他机构。我们还要特别感谢 Nvidia 工程师 Kedar Potdar、Ankur Singh、Xin Li、Alec Flowers 以及许多其他 Nvidia 工程师在此项目第 0 天提供的支持。同时也向 AMD 工程团队致以谢意,感谢他们在 DeepSeek v4 Pro 发布后持续支持 ROCm 栈。
不巧的是,DeepSeek v4 发布时我们的 GB300 集群恰好宕机了。幸运的是,CoreWeave 伸出援手,为开源社区和维护者贡献了算力,紧急调配了两个备用开发 GB300 NVL72 机架。 我们的 GB300 测试结果完全得益于他们的支持,目前我们正全天候使用这些资源来推动进一步的性能改进。

如果您有兴趣从事底层基准测试(benchmark)、InferenceX 或其他有趣的技术工作,请将简历发送至 letsgo@semianalysis.com,并附上三条要点来展示您的工程能力。如果方便,请附上 GitHub 仓库链接、个人网站或博客来展示您的项目、工作成果和专业知识。
第一节:DeepSeekV4 Pro 第 0 天性能
在本节中,我们将首先讨论 DeepSeek v4 Pro 在第 0 天的开箱即用性能。我们将引用吞吐量(throughput)-交互性曲线,说明不同并行策略如何在吞吐量和交互性之间取舍,以及 MTP 和分离式推理等其他推理优化技术——这些在 InferenceX V2 文章中已有详细解释。
请注意,为了避免潜在的"推理世界大战 3"以及防止又一轮 vLLM vs SGLang 的推特骂战/说唱对决,本文不会在同一图表上同时展示同一硬件 SKU 的 vLLM 和 SGLang 结果。

以下两张图表展示了我们记录的所有第 0 天配方(recipe),大多数配方使用原生模型检查点,采用混合 FP4 MoE-FP8 Attention 量化权重(H200 和 MI355X SKU 除外)。由于 DeepSeekV4 Pro 的原生 FP4+FP8 检查点在第 0 天无法在 MI355X 上使用,我们只能选择使用完整 FP8 非原生检查点。
不幸的是,AMD SGLang 和 AMD vLLM 的分布式推理在 DeepSeekV4 Pro 上仍然无法工作。
转向 SGLang 和 vLLM,两者均在 CUDA 平台上于模型公开发布的第一时间支持了原生 DeepSeek v4 Pro。大多数发布的配方,特别是针对 B200/B300 等较新 SKU 的配方,均可开箱即用且无重大问题。
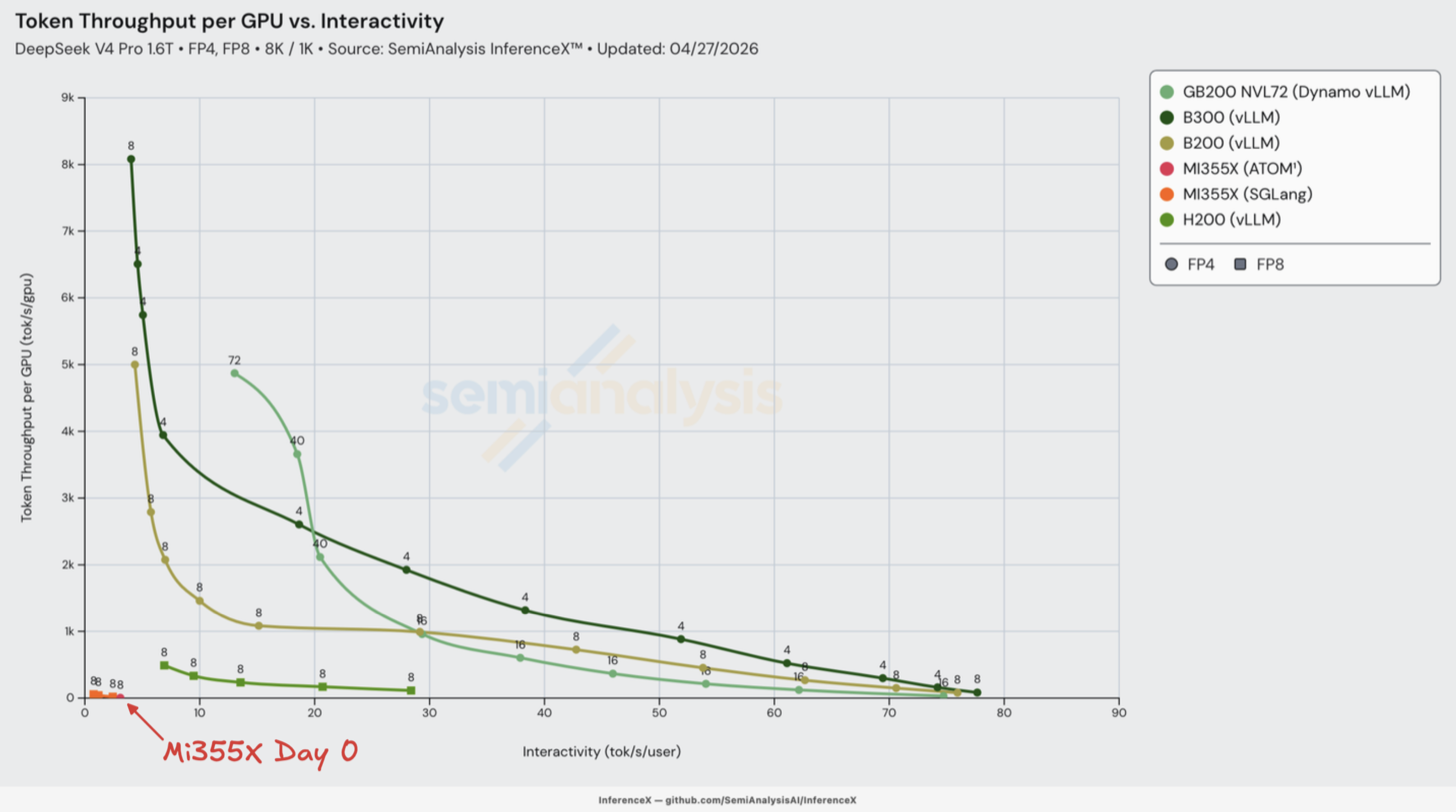
下图展示了 SGLang 第 0 天的性能表现:
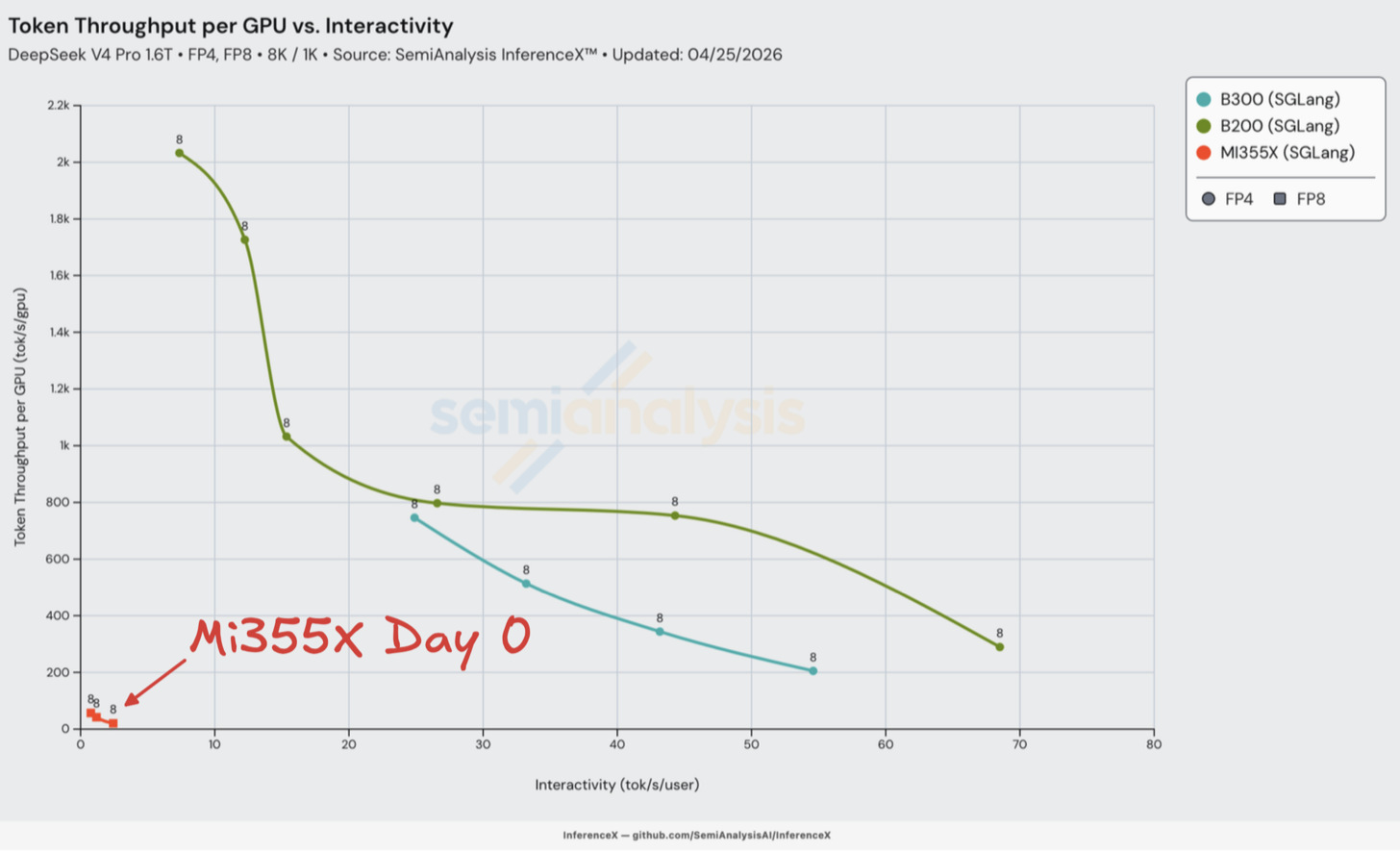
现在让我们深入了解每组第 0 天结果的细节。
第 0 天 GB200 NVL72 多节点分离式 Prefill
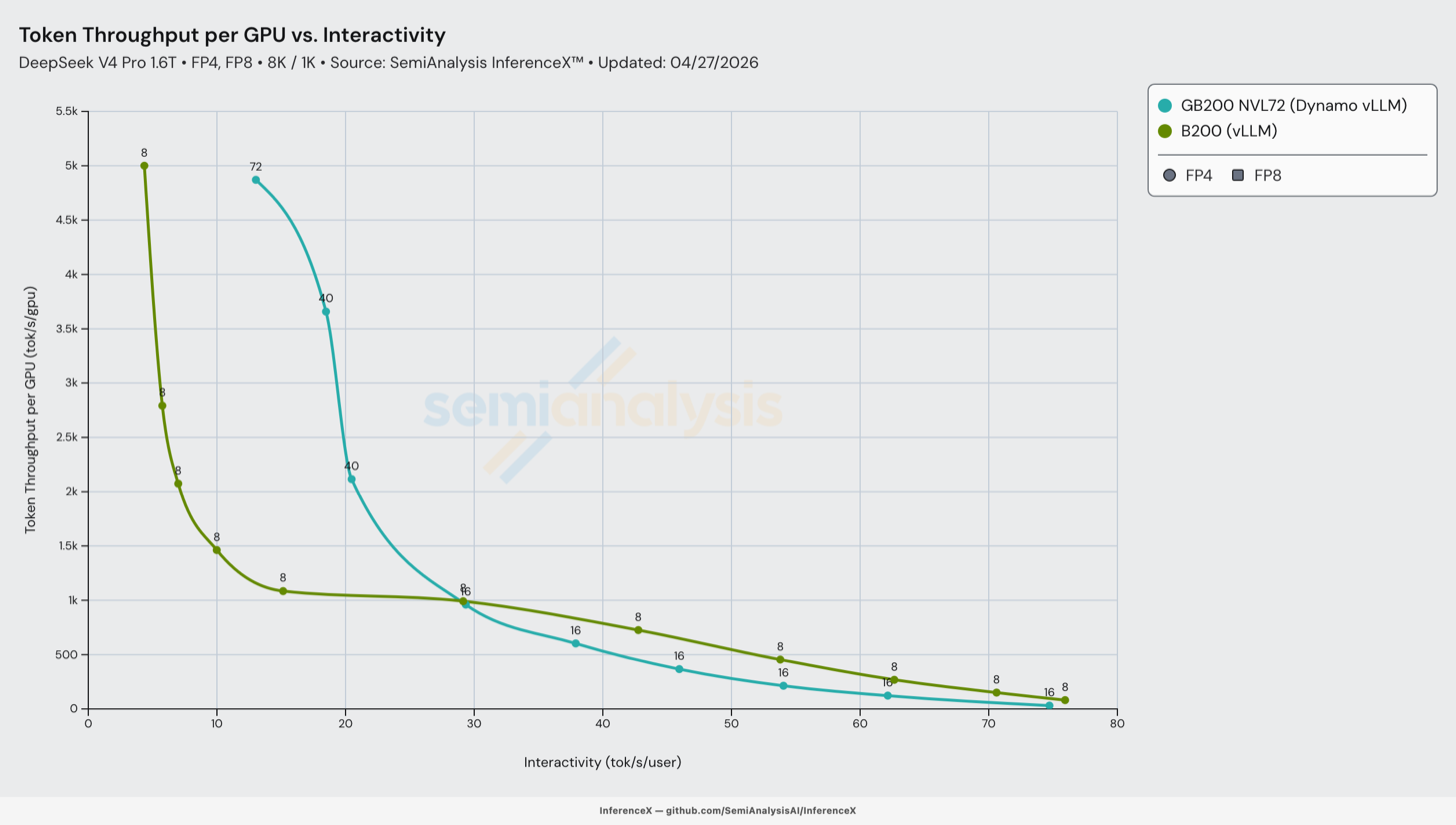
vLLM 和 Nvidia 非常快速地在 srt-slurm 中交付了他们的 GB200 分布式推理 Dynamo vLLM 配方。分离式推理(disaggregated inference)和宽专家并行(WideEP)是能够显著提升每美元性能的推理优化技术——读者可以在我们的 InferenceX V2 文章中了解更多。该配方本身较为基础:prefill 使用 eager 模式,通过 NIXL 进行 KV cache 传输。我们独立复现了该配方,在使用较低交互性配置时,实现了比 B200 运行最高 5 倍的性能提升。
这是 CUDA 护城河的一个典型案例:借助 CUDA,分布式推理通常能在最新开源模型发布的第 0 天附近即获得支持。
第 3 天 多 token 预测(MTP)推测性解码
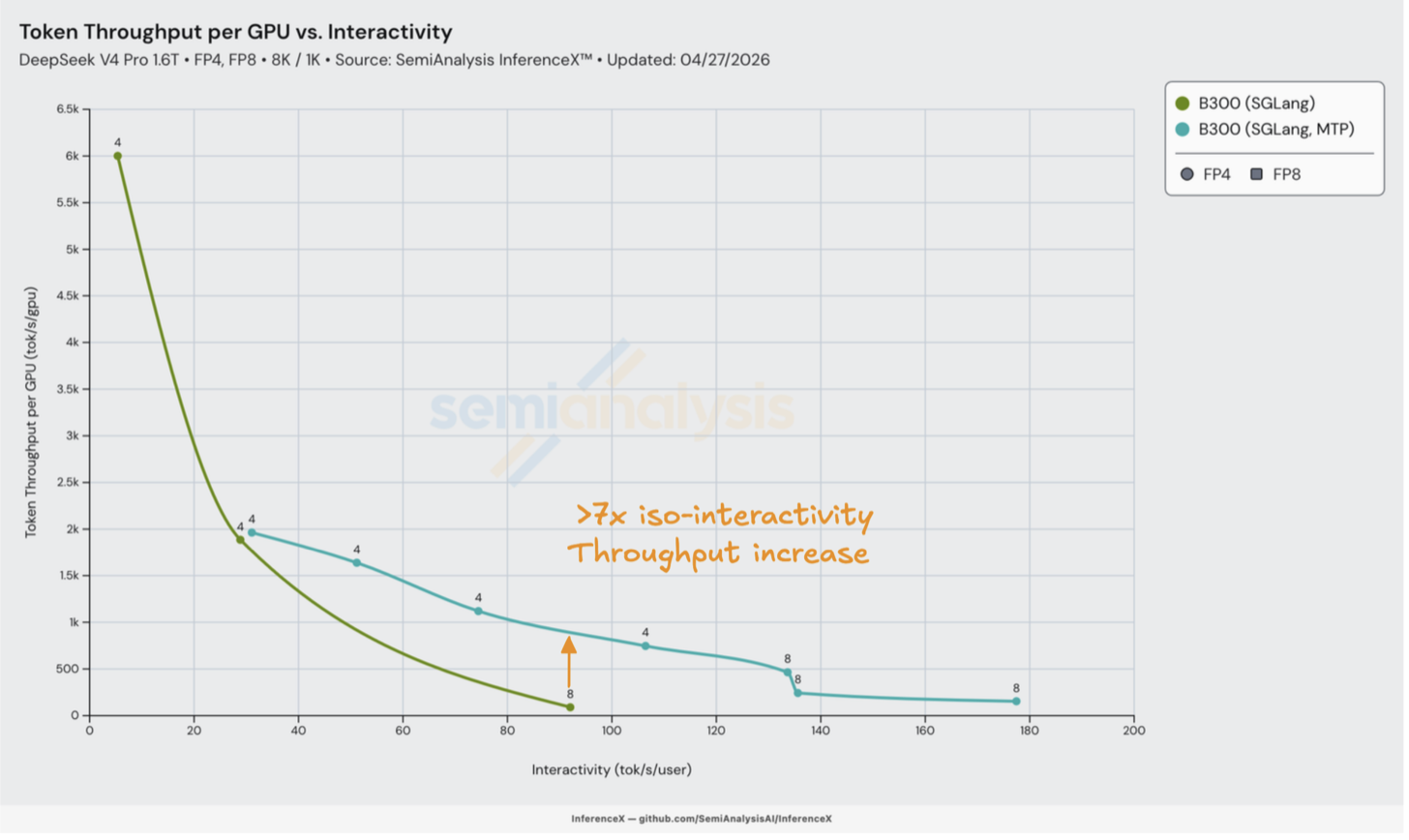
DeepSeek v4 的首个 MTP 支持在第 3 天由 SGLang 交付。使用 MTP 在较高交互性下带来了吞吐量的大幅提升。关于 MTP 及其如何惠及内存受限的小批量解码,可参阅我们的 InferenceX V2 文章。
第 0 天 ROCm AMD MI355X 的失望表现
转向 AMD MI355X 上的 ROCm,我们第 0 天 DeepSeek v4 的结果令人困惑。大多数开源生态系统中的 AMD 用户也同样感到迷茫。MI355X 在第 0 天只能运行 FP8,在下方总览图表中的位置位于左下角。推理在技术上是可以运行的,但由于交互性极低——仅 1-2 tok/s/user,远低于用户平均阅读速度——使用体验极差。
我们使用了 AMD 的 HaiShaw 等人通过 SGLang PR 提供的第 0 天 WIP 配方。这是我们在第 0 天能找到的唯一可用配方。不幸的是,其性能令人失望且原生 FP4+FP8 检查点无法使用——这可能是由于 ROCm 生态系统相对不够成熟。然而,正如我们将在文章后面讨论的,HaiShaw 的团队最终交出了出色的答卷,通过一系列基于第一性原理的经典工程工作,从第 0 天到第 26 天实现了超过 100 倍的性能提升。
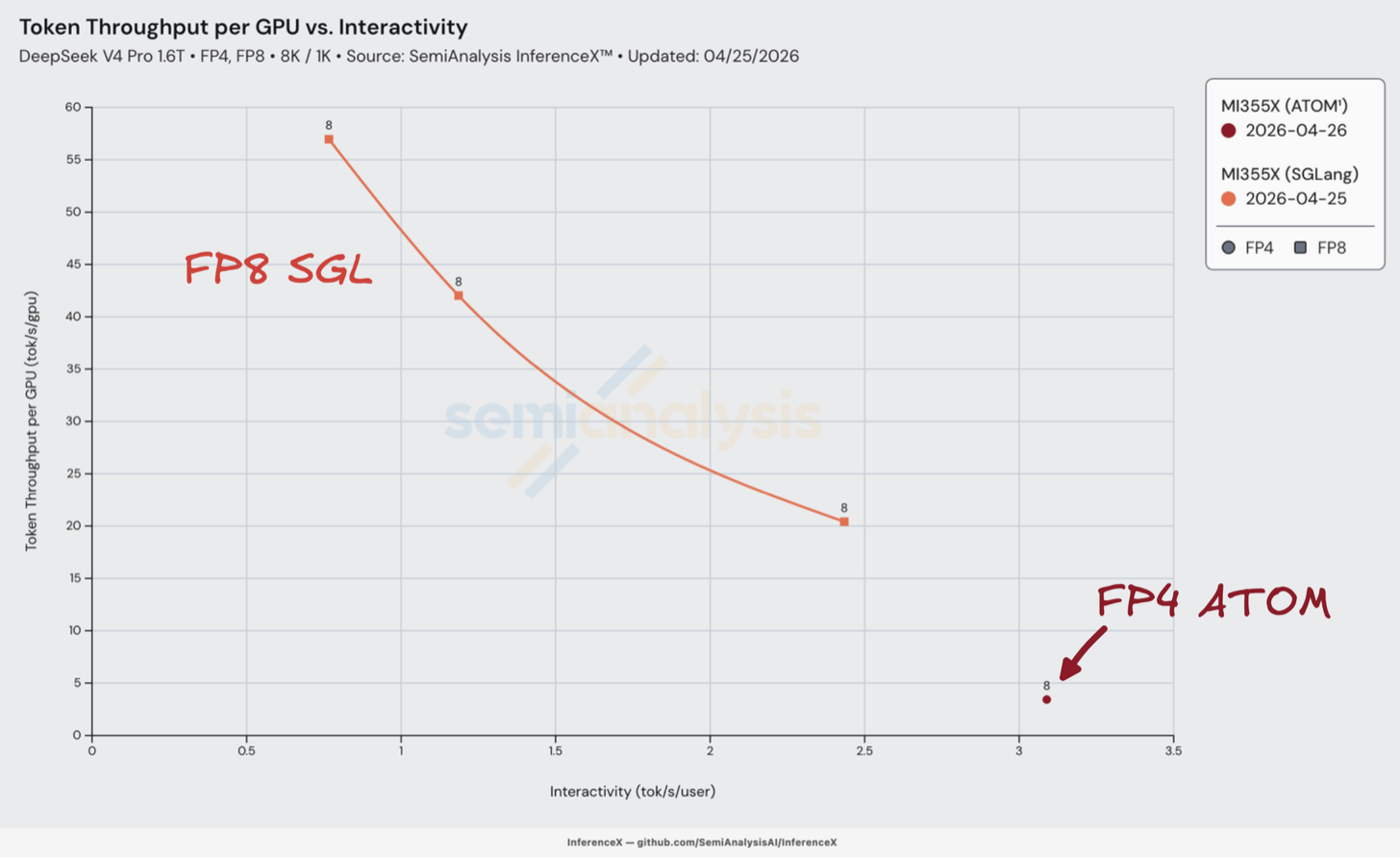
AMD ATOM 推理引擎的失望表现
ATOM 在交互性方面稍好一些,但在并发数(concurrency)大于 1 时仍然力不从心。在 DeepSeek v4 早期,我们使用的 ATOM #650 硬编码了 kv_cache[:1,...],这意味着 KV cache 被锁定在单个序列槽位上。只有一个槽位可用,第二个并发请求便无处存储其 KV 状态。这是因为实现批处理的基础设施尚未就位,所以我们只能运行批大小为 1 的单用户请求。
ATOM 的几乎每条热路径也都走了 fallback:FP4 MoE 被迫使用 Triton(因为 AITER 的 fused_moe 在 GFX950 上损坏了),mHC 的 pre-projection 也回退到了 Torch(因为 AITER 的 kernel 会崩溃),从而强制使用 eager 模式执行。
NVIDIA TensorRT-LLM 的 Bug 及缺乏第 0 天 DeepSeekV4 Pro 支持
TensorRT 无法开箱即用地支持 DeepSeek v4,因为 mhcFusedHcKernel.cu 中有一个硬编码的 FHC_HIDDEN = 4096 常量。问题在于 SHAPE_K、residual/x TMA 描述符以及 MMA kernel 模板实例化都绑定在该隐藏维度大小上。所有之前的 DeepSeek 模型和 DeepSeek v4 flash 的隐藏维度均为 4096,因此暂时不出问题。但尝试对 DeepSeek v4 Pro 进行推理时,会触发 "mhcFusedHcLaunch: hidden_size=7168 not supported (only 4096)" 的保护错误。
Nvidia 工程师也遇到了这个保护错误,但他们没有添加代码来支持 DeepSeek v4 Pro 的 7168 隐藏维度,而是直接移除了保护检查。毫不意外,错误确实消失了。
由于这个"修复",有超过一周的时间,除非使用环境变量 TRTLLM_MHC_ENABLE_FUSED_HC=0,否则 kernel 会专门为 4096 编译,且没有任何检查拒绝 7,168 的调用。在默认设置下(fused HC 默认开启;B300 = SM10x → MMA 路径),stock trtllm-serve 运行 DeepSeek v4 Pro 时会将 7,168 张量送入为 4,096 编译的 kernel。在这些设置下运行推理不会立即崩溃,但会产生隐藏的后果:引擎最终会损坏隐藏状态并产生无效生成结果。这个问题通过我们编写的 PR 得到了修复,令人惊讶的是,这样一个简单的问题竟然过了一周才被发现,而且 PR 又花了好几天才被批准。
从诊断问题并将其缩小到 fused HC 隐藏维度不匹配所花费的时间来看,我们已经到了 DeepSeek v4 Pro 发布后的第 9 天。这一事件是一个很好的案例研究,证明了原生 SGLang 和原生 vLLM 引擎开源生态的强大。正因为有了这些健壮的生态系统,第 0 天支持将始终首先到达原生 SGLang 和原生 vLLM,然后才是 TensorRT-LLM 或 AMD 的 ATOM 引擎(顺便说一下,ATOM 目前零生产客户)。
在下方图表中,我们可以看到截至目前,TRT-LLM 在较大批量时性能更优,但在较高交互性水平下往往落后。
第 1.5 节:性能随时间的演进
如文章前面提到的,我们捕获第 0 天各推理引擎和配方的性能快照,将其作为衡量性能随时间改进的基线。有了这一基线性能,我们便能测量并呈现以下分析性能提升的数据。
DeepSeek v4 Pro 在 MI355X 上 — 不到 1 个月内提升 100 倍
在第 0 天,DeepSeek v4 Pro 在 MI355X 上技术上可以运行,但显然无法部署到任何生产工作流中。然而,此后的改进令人惊叹——在 HaiShaw 的领导下,AMD 团队在 DeepSeek v4 发布后不到一个月内实现了超过 100 倍的吞吐量提升。
MI355X DeepSeek V4 Pro 性能从第 0 天起的改进过程。来源:SemiAnalysis InferenceX
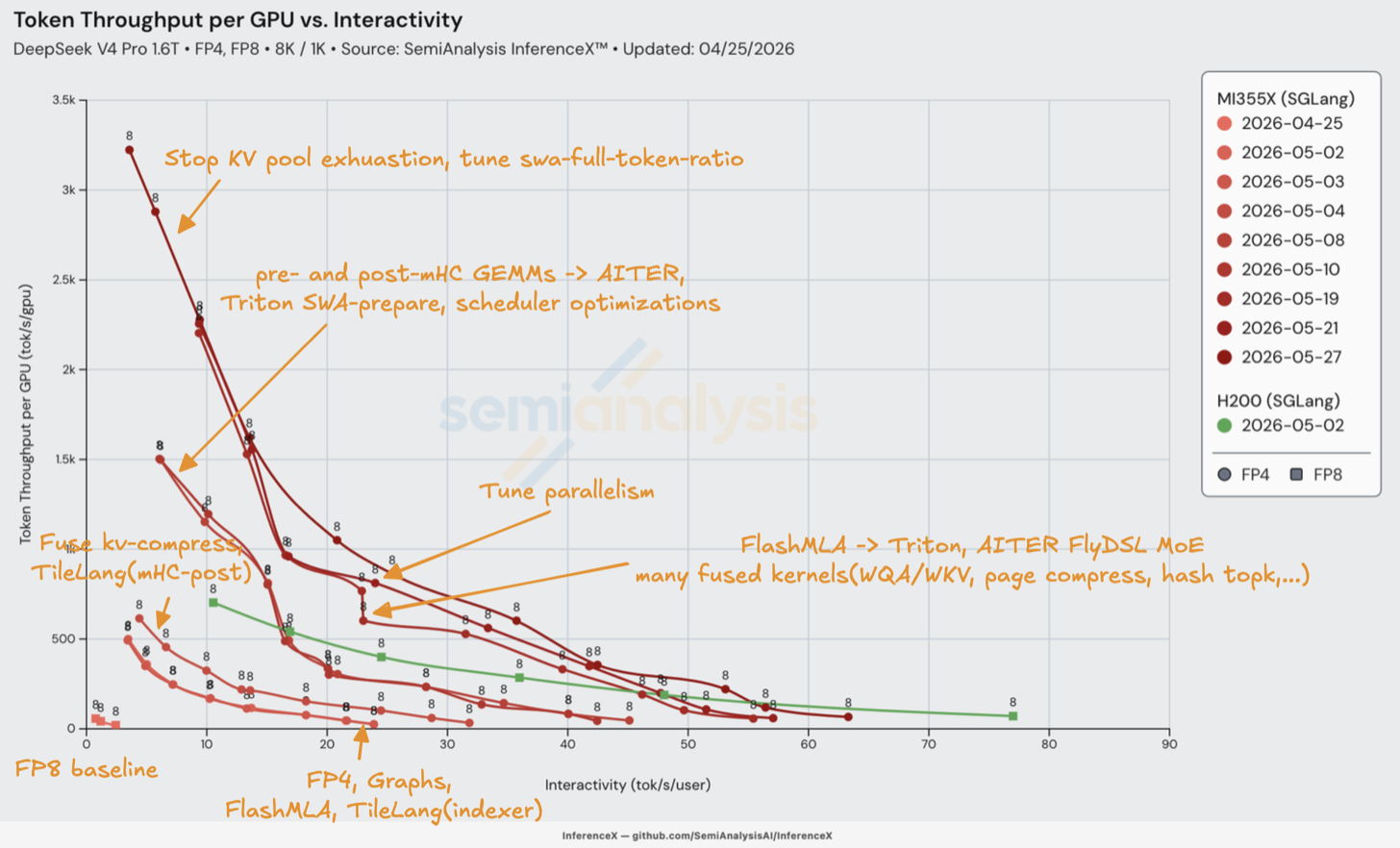
上方图表显示了从 4 月 25 日第 0 天发布的 FP8 构建到 5 月 27 日发布的 FP4 构建之间,吞吐量 Pareto 最优前沿的攀升。性能提升几乎完全来自 AMD 用真正的 AITER、Triton、TileLang 和 FlyDSL kernel 替换 PyTorch 原生 fallback 路径。
推动最大份额性能提升的有两个关键步骤。最大百分比的改进实际上来自基线第 0 天提交之后的第一次 commit——团队清理了大量低垂果实,显著改善了 FP8 基线的首次迭代。下一个最大改进在几天后到来,AMD 团队终于让 FP4 权重 MoE 正常工作,使我们能将 MoE 专家从 FP8 切换到原生 FP4 (MXFP4),改善了专家权重的带宽。这也将 FlashMLA 和稀疏注意力索引器从 torch fallback 移至 TileLang kernel,并启用了 HIP graphs。
我们看到的下一个重大改进来自 AITER mHC kernel 的引入,这些 kernel 在每一层都会使用。这一改进使得 MI355X 在较低交互性水平下首次超越了 H200 的 DeepSeek v4 Pro 性能。
在窗口注意力 kernel 运行之前,需要知道每个查询的窗口覆盖了哪些 KV-cache 槽位。这由 SWA-prepare 完成,其在 Triton 中的实现也有助于性能改进。
下一个重大跳跃出现在 5 月 19 日,团队退役了剩余的 fallback:FlashMLA 从 TileLang 迁移到了 Triton,AITER FlyDSL FP4 MoE kernel 也已落地。团队还启用了 fused hash-topk、DSv4 radix attention、fused store-cache、fused WQA/WKV projection 和 fused paged-compress,进一步提升了性能。并发扫描范围也增加到了 1024,绘制出此前不存在的高吞吐、低交互性端的前沿。
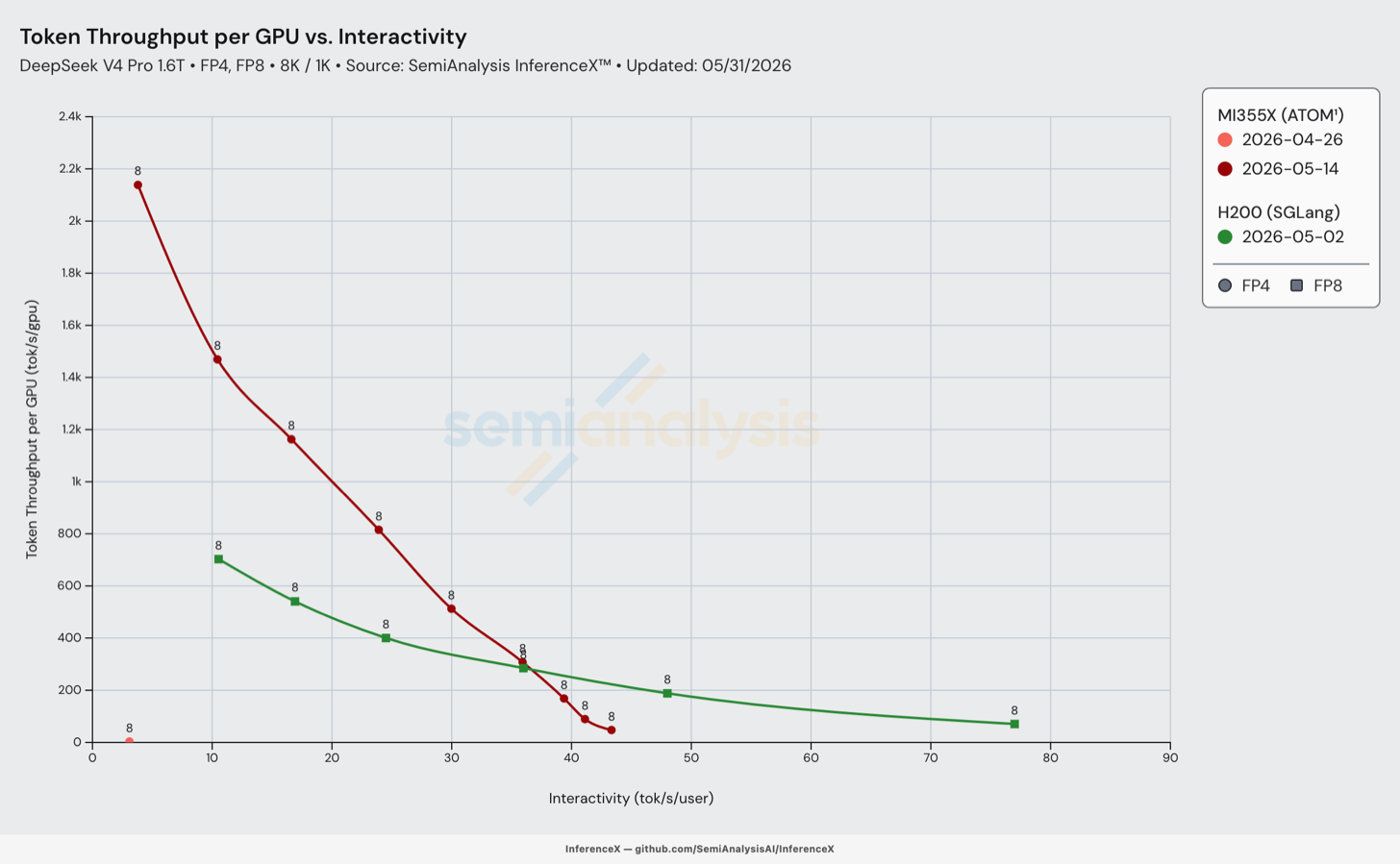
ATOM 也取得了巨大进步,从单个 conc=1 数据点扩展到在整个 Pareto 前沿提供可观的吞吐量,部分数据点甚至超越了 H200。第一个提升来自 AITER fix #2916,该修复纠正了导致 mHC 崩溃的设备分配 bug,使 ATOM 得以恢复该 AITER kernel。接着,FP4 专家迁移到了 AITER 的 fused MoE kernel(移除了 Triton override),稀疏注意力的 OOM 问题被清除,eager 模式和单序列限制得以解除。批处理支持也已实现,将并发扫描从 conc=1 扩展到 conc 1–512,性能大幅改善。
MI355X MTP
到第 4 周,MTP 已在 AMD 所有框架上正常工作,在等交互性(iso-interactivity)条件下实现了数倍的吞吐量提升。不过我们注意到一个一致的特征:MTP 在较高吞吐量下往往效果更差。这是因为 MTP 利用的是内存受限解码中的计算空闲,因此计算受限的大批量解码任务中,MTP 的开销会超过草稿 token 带来的收益。
B300
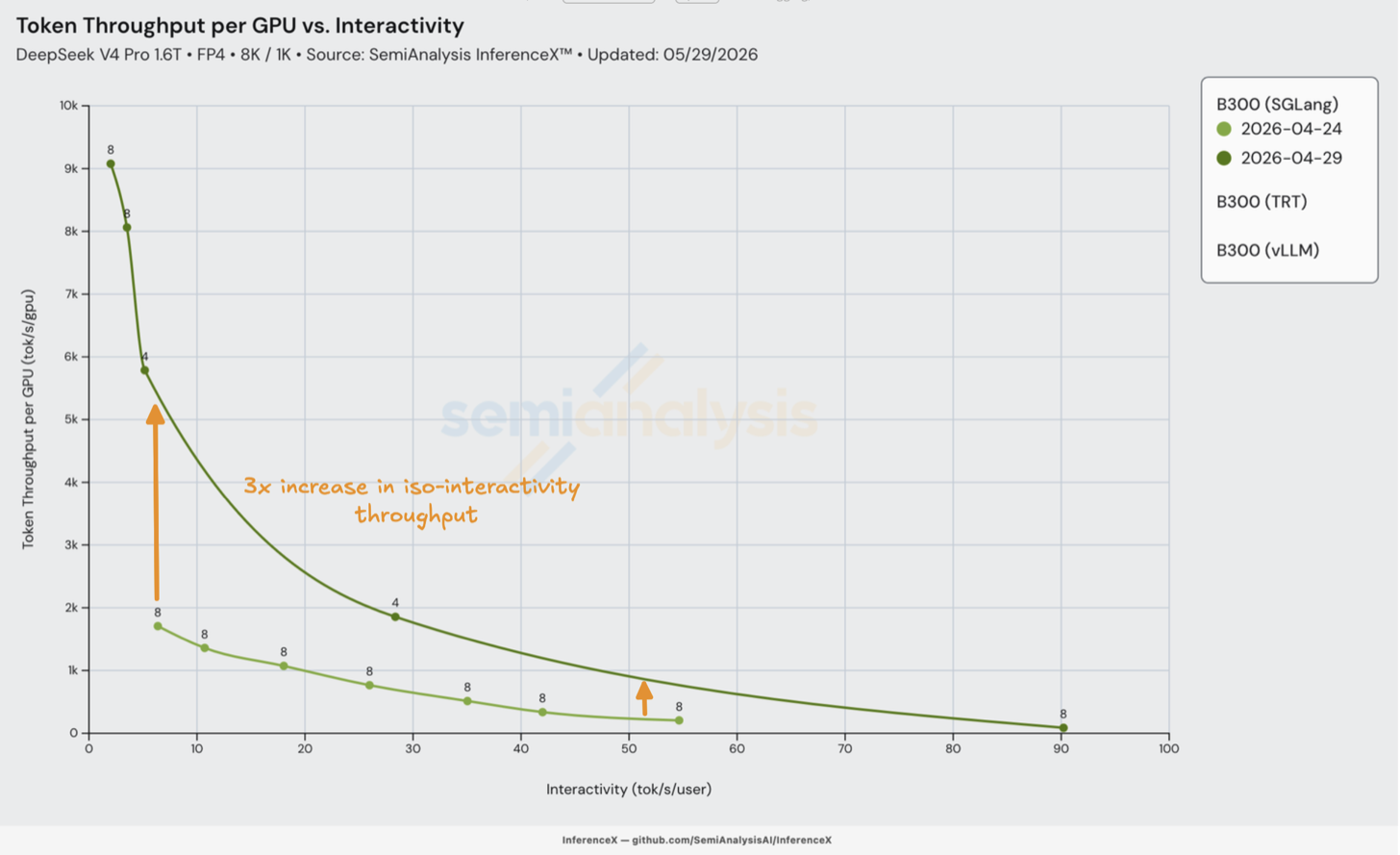
对于 B300 上的 SGLang,DeepGEMM MegaMoE 的结果显示不到一周内实现了 3 倍性能提升,这得益于分组 FP4 MoE GEMM(将专家保持驻留并执行一次 mega-dispatch 而非逐专家 kernel 调度),以及从 EP8 调优至 EP4。
B200
B200 的性能与 B300 较为相似,在较低交互性下 TRT 对 B200 表现更优。但 TRTLLM 无法开箱即用,相比之下 CUDA vLLM 和 SGLang vLLM 可以直接使用。
GB300 NVL72
GB300 NVL72 DeepSeek V4 Pro 性能随时间的改进。来源:SemiAnalysis InferenceX
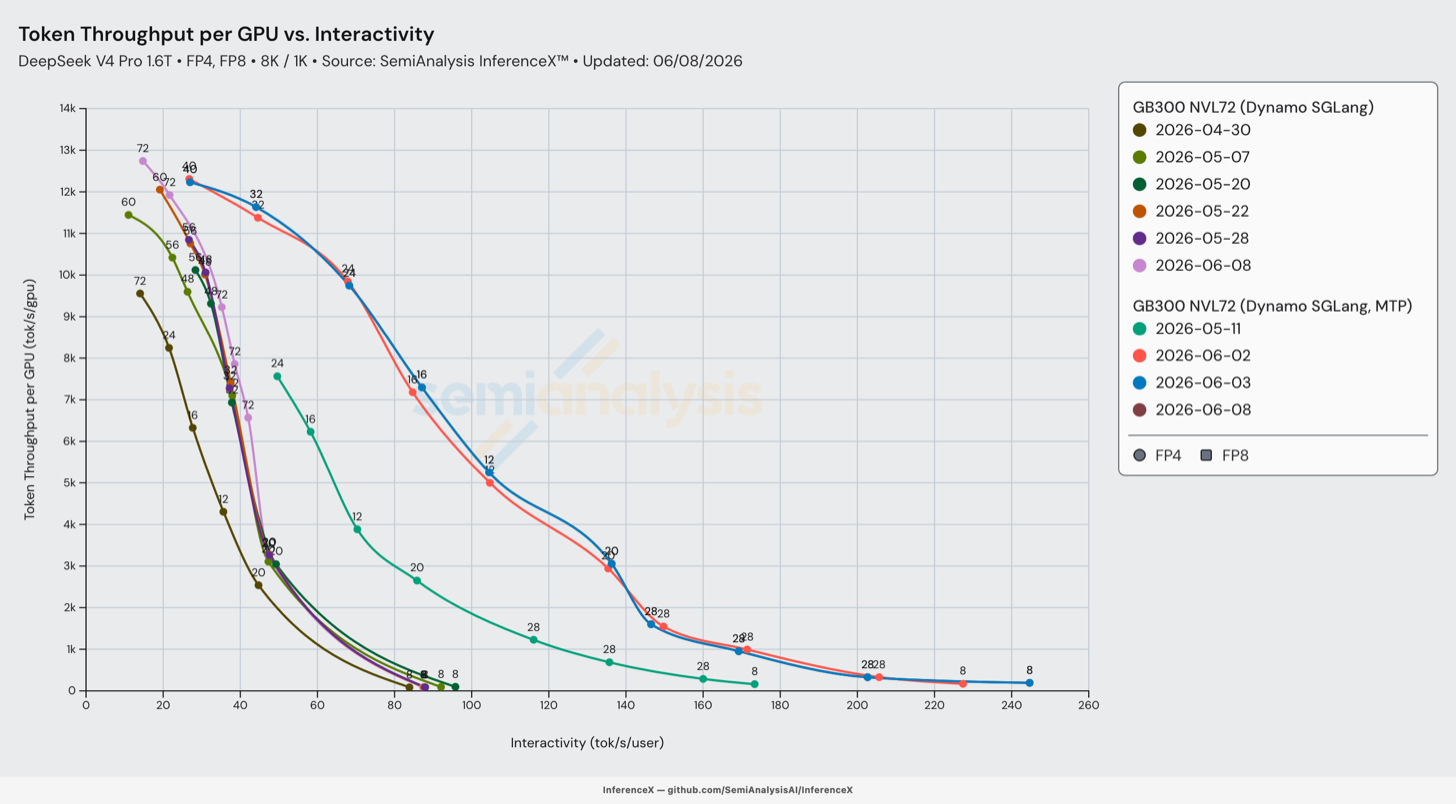
GB300 SGLang MTP 最显著的改进出现在 6 月 2 日,源自 W4A4 (MXFP4) MegaMoE 的实现。相比 5 月 7 日使用的非 MTP 实现,6 月 2 日版本的主要改进完全来自 GB300 解码拓扑的重构,而非触及 kernel 或精度。第 0 天的配方大多数点以窄 EP=8 运行,由一到两个 prefill worker 供给,并发上限为 16,384;5 月 20 日的运行将解码扩展到 EP=16,prefill 扩展到每个解码 worker 对应四到十二个 prefill worker,并将并发推到了 21,504。
根据上述图表和分析,我们可以看到,正如预期的那样,对于更大 world size 的推理系统,宽专家并行(Wide EP)是 GB300 卓越性能的主要杠杆,这通过在更多 GPU 之间分摊权重加载来实现。阅读 InferenceX V2 文章了解更多关于 Wide EP 的内容。
这些 GB300 的测试结果完全得益于 CoreWeave 的支持。
B200 每兆瓦(MW)token 吞吐量改进
对于使用 vLLM 引擎的 B200,在 50 tok/s/user 交互性下,每全电源配置(all-in provisioned utility)兆瓦的 token 吞吐量在第 0 天达到每秒每 MW 300,000 token,到 6 月 5 日提升至接近每秒每 MW 500,000 token。
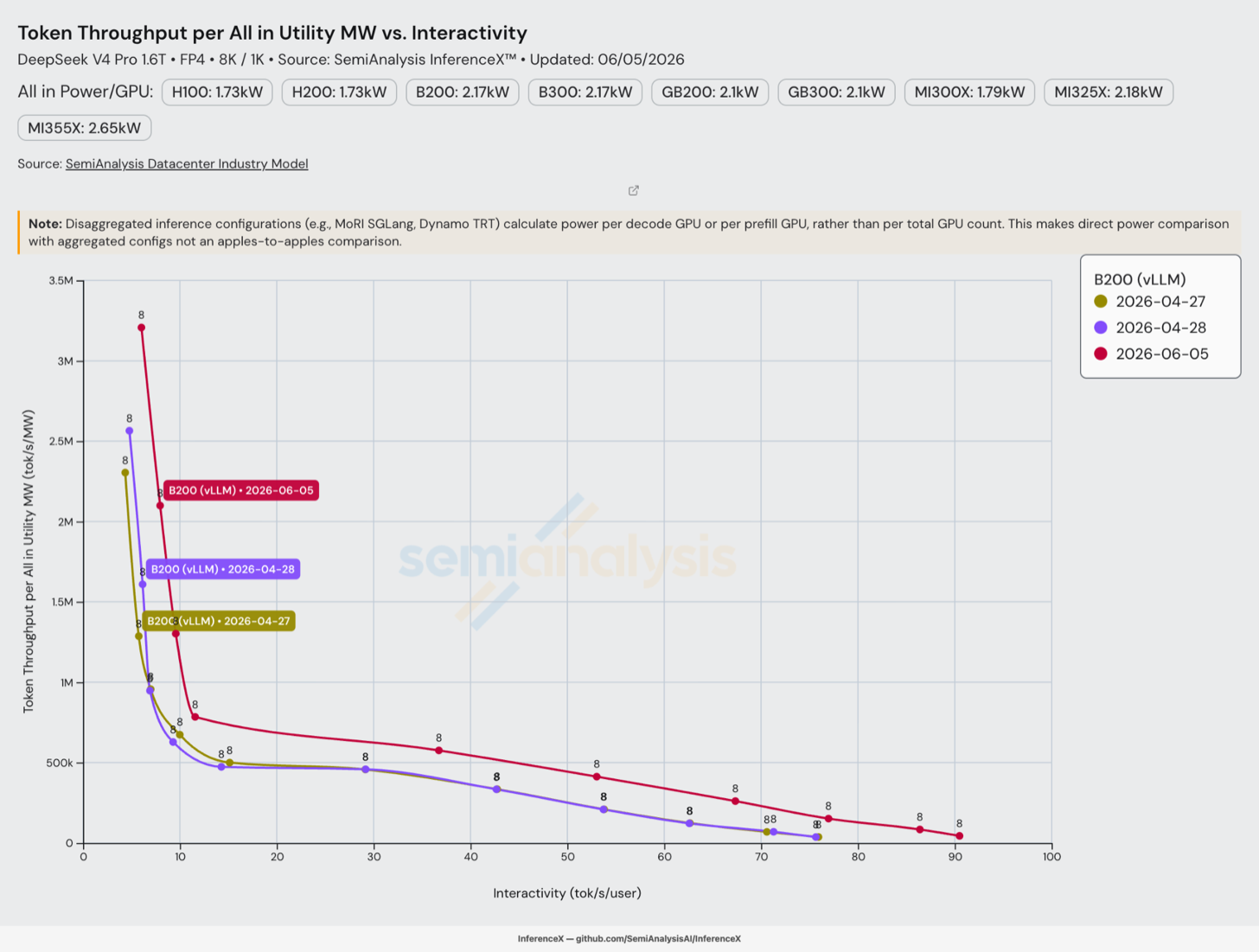
每全电源配置兆瓦 token 数是评估机群规模投资回报的最佳指标:它比单纯的每 GPU token 吞吐量承载更多信息,因为它反映了 PUE 和数据中心开销。由于 B200 的全电源配置功率大约固定在 2.17 kW/GPU,从约 300k 到约 500k tok/s/MW 的约 1.7 倍跃升反映的是纯软件优化收益。
推动吞吐量前沿的同类优化(MegaMoE 分组 FP4 GEMM、更宽的 EP、FP4 权重路径、调度器调优)直接传导至能效提升,因为以 MW 计的全电源配置功率保持不变。
许多组织从最大化稀缺电力资源的角度来评估推理机群。核心问题是如何将配置的 MW 在给定利用率和价格下转化为尽可能多的计费 token。最佳分析方式是参考每 MW 收入、每全电源配置功率 token 数、每 MW 资本支出等指标。这正是我们的 Tokenomics 模型所要解决的商业问题。
截至 2026 年 6 月 6 日的当前性能
让我们通过快速回顾各系统和推理引擎的最佳性能来结束性能改进这一部分。使用 SGLang 时,GB300 继续碾压所有其他推理系统,展示了 GB300 NVL72 机架级 world size 的优势。
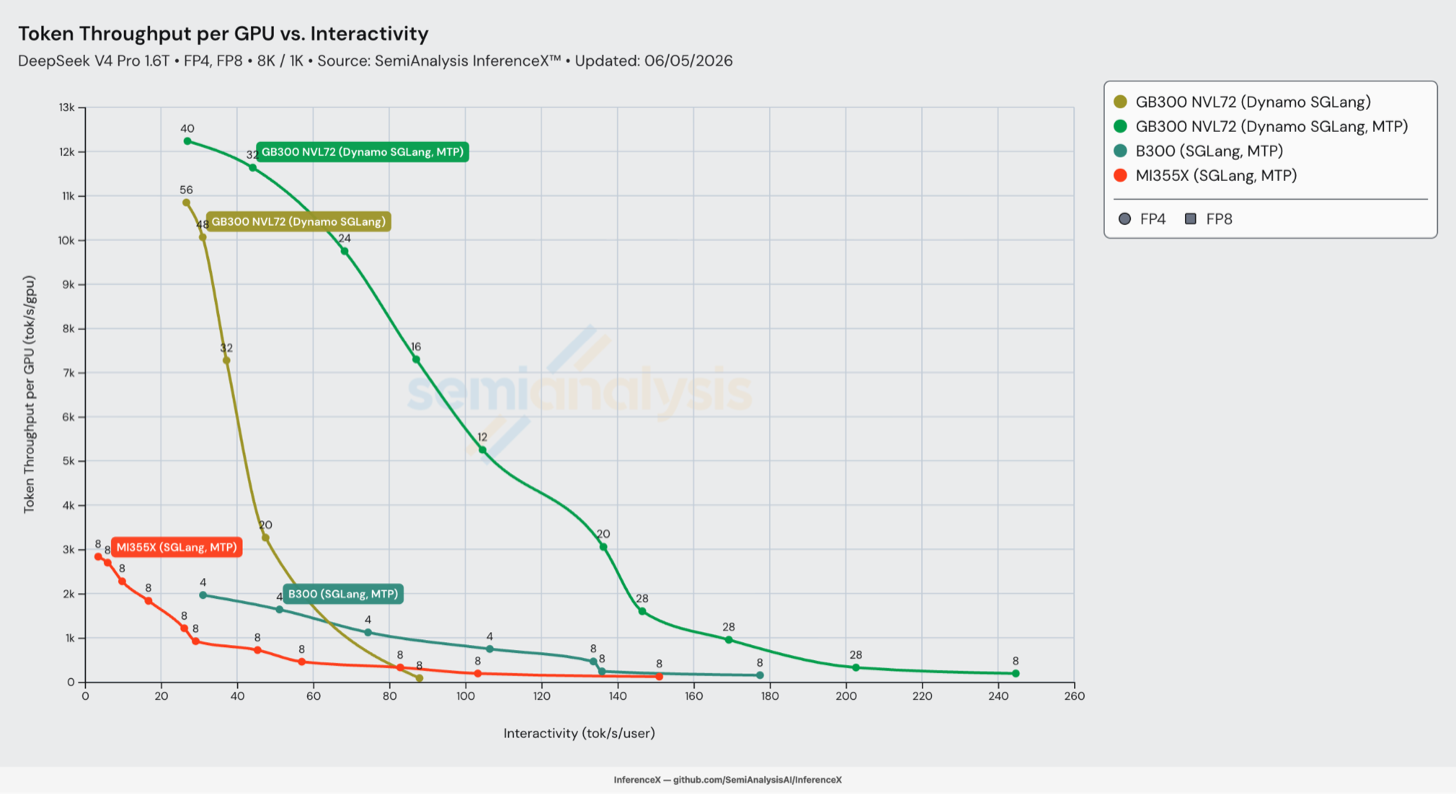
开启 MTP 后,GB300 在我们分析的所有交互性水平上都无可匹敌。GB300 每百万输出 token 的成本在 50 tok/s/user 下达到 $0.156(假设 8k token 输入、1k token 输出)。欲了解更多关于我们如何计算总拥有成本(TCO)的信息,请参阅我们的 TCO 模型。
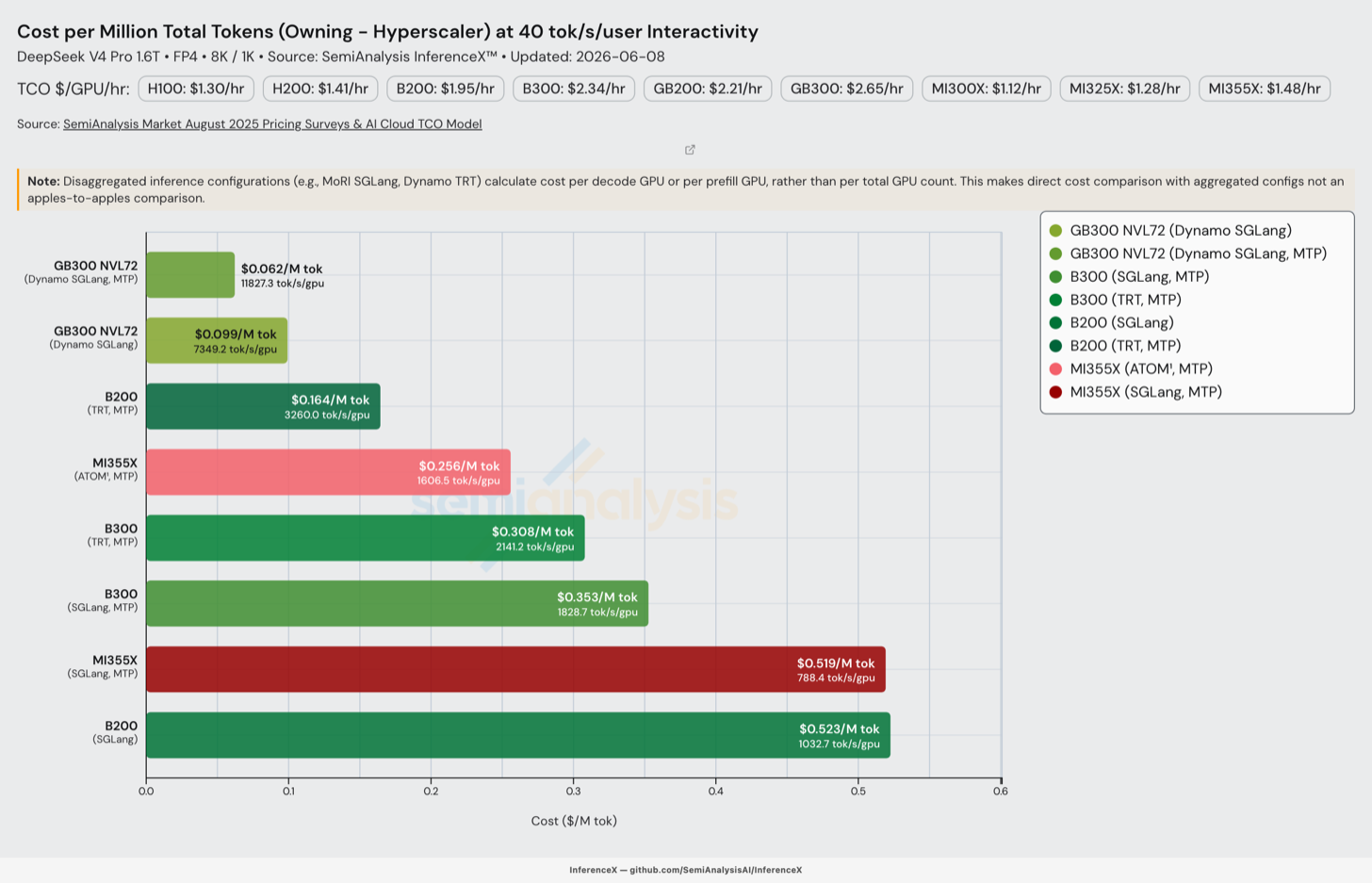
机架级优势本质上是一个纵向扩展(scale-up)的故事。NVL72 将 72 个 GPU 置于单个 NVLink 域中,使服务栈能够以足够宽的专家并行运行,让 DeepSeek V4 的 MoE dispatch/combine all-to-all 完全运行在 NVLink 上而无需溢出到较慢的横向扩展(scale-out)网络,同时在更多 rank 之间分摊专家权重加载。
B200 和 B300 的 8 GPU NVLink 岛通过 InfiniBand 横向扩展会更早遇到瓶颈,而 MI355X 在纵向扩展域规模和通信栈成熟度上都更为落后。将这些每机架吞吐量优势转化为实际部署的服务容量是另一个问题,取决于每种 SKU 实际上线的数量:各 SKU 的出货量和平均售价、按客户和季度统计的装机量和有效 FLOPS——这些我们在 Accelerator & HBM 模型中持续追踪。
ROCm vLLM DeepSeek v4 Pro 的失望表现
在 ROCm 方面,原生 vLLM 的进展远慢于原生 SGLang。ROCm vLLM 的性能远远落后于其 CUDA vLLM 对应版本。部分原因是 AMD 正在将重心转向 ATOM(一个服务零生产 token 的推理引擎),而非专注于原生 vLLM(一个许多主要客户都在使用的推理引擎)。我们将在即将发布的 State of AMD 2026 文章中详细讨论(涵盖 AMD 推理的优点、缺点和问题)。我们将提到的一个积极进展是,开源上游 AMD vLLM 的分布式推理功能终于在非 DeepSeekv4 模型上实现了开箱即用。虽然走到这一步花了很多个月,但 AMD vLLM 团队仍有大量工作要做。
DeepSeek v4 的下一步
vLLM
vLLM 的计划在 DeepSeek V4 路线图 issue (#40902) 中追踪,已落地的代码在实现 PR #40860 中,并描述了针对 SemiAnalysis InferenceX 仪表板的基准测试。FP4 Indexer 和初始 MegaMoE 支持已经实现,Hopper 也已支持。vLLM 针对 DeepSeek v4 的剩余工作涵盖五个方面:
- 核心模型支持:持续 MegaMoE 工作(PR #40833)和 NVFP4 支持。
- 运行时与并行:Model Runner V2 集成、MTP 优化、prefill/decode (PD) 优化、pipeline parallelism 支持。
- Kernel 集成:paged prefill kernel、fast top-k kernel、更多水平融合、DeepEP V2,以及与 DeepSeek 自研 TileKernels 的集成。
- KV cache:KV cache 卸载,涵盖 PD + CPU 卸载(PR #39654)和分布式 KV 卸载。
- 硬件支持:在已完成 Hopper 支持的基础上,SM120 和 AMD 支持仍是关键待办项。
这里的核心主题聚焦在周边系统:新的模型运行器、pipeline parallelism、KV 卸载,以及更广泛的硬件覆盖。
即将到来的 InferenceX 更新——SemiAnalysis 的开源公共 EcosystemX 仪表板——将可视化所有主要 ML 开源库在所有主要 AI 芯片上的软件演进、CI 覆盖率和队列时间:NVIDIA、AMD、TPU、Trainium、Huawei 等。
SGLang
SGLang 的计划记录在性能优化追踪 (#23666) 中,Nvidia 围绕 DeepSeek v4 的网络架构图逐模块推进;部分项可能已被初始支持 PR (#23600) 部分覆盖,欢迎社区贡献。
这里反映了三个高层目标:解码的 CUDA graph 支持、prefill 的分段 CUDA graph 支持,以及无运行时权重处理。此外,权重准备应只执行一次而非每步重复。在这三个高层目标之下,检查清单按 V4 的组件分组:
- mHC:尝试对
fc_hc_fnGEMM(N 维度较小,可能需要特殊 kernel)使用 TF32/BF16,1/RMS + multiply 融合,单 kernelhc_split_sinkhorn和hc_post,以及在 attention 和 MoE 模块中融合 MulSum + RMSNorm(+ FP8/MXFP8 量化)。 - HCA(含 Compressor):将
fc_qa+fc_kv水平融合为一个 FP8 GEMM,q-norm/k-norm 和 RMSNorm+RoPE 融合,去掉topk_idx的非稀疏 MQA 路径,MQA 直接从压缩和 SWA KV-cache 读取而无需拷贝/拼接,单 kernel InvRoPE,融合的 Compressor 状态更新(kv-update + ape-Add + score-update),以及使 HCA(尤其是 Compressor)兼容解码的 CUDA graph。 - CSA(Indexer + Compressor):稀疏路径类似的直接缓存读取,可选的(P1)fc_compressor + fc_idx_compressor 和 fc_qb + fc_idx_qb 融合,(RoPE +) Hadamard + MXFP4 量化融合,高效的 MXFP4 BMM+ReLU kernel(可能与 MulSum 甚至 Top-1024 融合),以及使 Indexer 和 Compressor 兼容 CUDA graph。
- MoE:检验路由 GEMM 是否适用 TF32/BF16,将路由路径(softplus + sqrt + bias-add + Top-6 + gather + norm + multiply)尽可能压缩为最少的 kernel,融合 block-wise FP8 和 MXFP8 激活量化,确保 shared-expert 和 routed-expert FC13 均为单 kernel,并审计路由专家前的微型排序 kernel。
SGLang 的重点是用单个融合 kernel 替换小算子链,使新注意力变体就地读取缓存,并将解码路径完全纳入 CUDA graph。
第二节:Huawei 950DT 第 0 天 DeepSeek v4 分析
DeepSeek v4 是首个在 Huawei Ascend 上获得一流第 0 天支持的重要开源模型,事实上,DeepSeek 官方 API 的部分服务从第 0 天起就运行在 Huawei 上。我们已获得 Huawei 在 DeepSeek v4 上的性能数据,并计划发布后续文章,深入对比 Huawei 与 H200 和 B200 上的推理性能,使用相同的基准测试(benchmark)工具进行苹果对苹果的比较。
我们即将推出的公开开源 SemiAnalysis EcosystemX 仪表板将可视化所有主要 ML 开源库在所有主要 AI 芯片上的软件演进和 CI 覆盖率,包括 Ascend 栈。
CANN
CANN(Compute Architecture for Neural Networks)是 Huawei 为在自家 Ascend 芯片上运行 AI 工作负载而开发的软件工具包。自 2025 年 8 月起,他们开源了 CANN 以吸引更多开发者,并"蚕食" Nvidia 的主导地位——尤其是在中国,鉴于美国政府严格限制 CUDA 芯片出口到中国。

在第 0 天,CANN 发布了 Ascend 芯片的优化指南和基准测试数据。通过这些信息,我们可以看到 Huawei 的 CANN 策略:通过面向中国国产模型发布的全栈推理优化,使 Ascend 具备竞争力。Huawei 试图向中国生态系统表明,如果 DeepSeek 发布新架构,CANN 能够交付 kernel、graph 路径、量化、服务集成和部署配方。
我们在基准测试 MTP 时观察到 CANN 团队的一个有趣方法论,不得不在此提及:他们如何处理 MTP 草稿 token 的 AR(acceptance rate,接受率)或 AL(acceptance length,接受长度)。基准测试 MTP 并非易事,因为基准测试的 AR/AL 可能与用户的实际用例不同。例如,基准测试平均每三个草稿 token 可能接受两个,但在极其多样化的实际部署场景中,可能平均只能接受 1.5 个。
这意味着用户可能看到的性能低于基准测试,从而错误地认为他们的设置有问题。我们在 InferenceX v2 文章中通过与 MTBench 的 AR 对比来解决这个问题。我们基准测试的未来迭代将通过使用真实 trace 来全面解决这一差距。
为应对这一问题,Huawei 选择将完整解码步骤的计时对齐到最后一个 MTP 模块,从而记录每解码步骤的时间而非每 token 的时间。最终发布的基准测试结果需要用户乘以其用例的 MTP AL 来得出可比较的性能指标——这是一种非常优雅的性能比较方式。
嘿 NVIDIA Goliath,来了一位新 David — Ascend 950
Huawei 对 Ascend 950 芯片的内部代号是"David",这一代号在 CANN 代码库中被多次引用。毫无疑问,这是因为他们认为自己是对抗 Nvidia Goliath(巨人歌利亚)的 David(大卫)。

SIMT/SIMD 950 芯片有两个型号:950PR 和 950DT。PR 代表 Prefill and Recommendation(预填充与推荐),是成本更低、性价比更高的芯片。DT 代表 Decode and Training(解码与训练),该型号具有更高的内存带宽和更高的性能。两者基于同一 Ascend 950 Die,使用双 die UMA 架构,但封装了不同的内存。每季度各 Huawei 芯片的路线图预估和出货量可在 SemiAnalysis Accelerator 模型中查看。
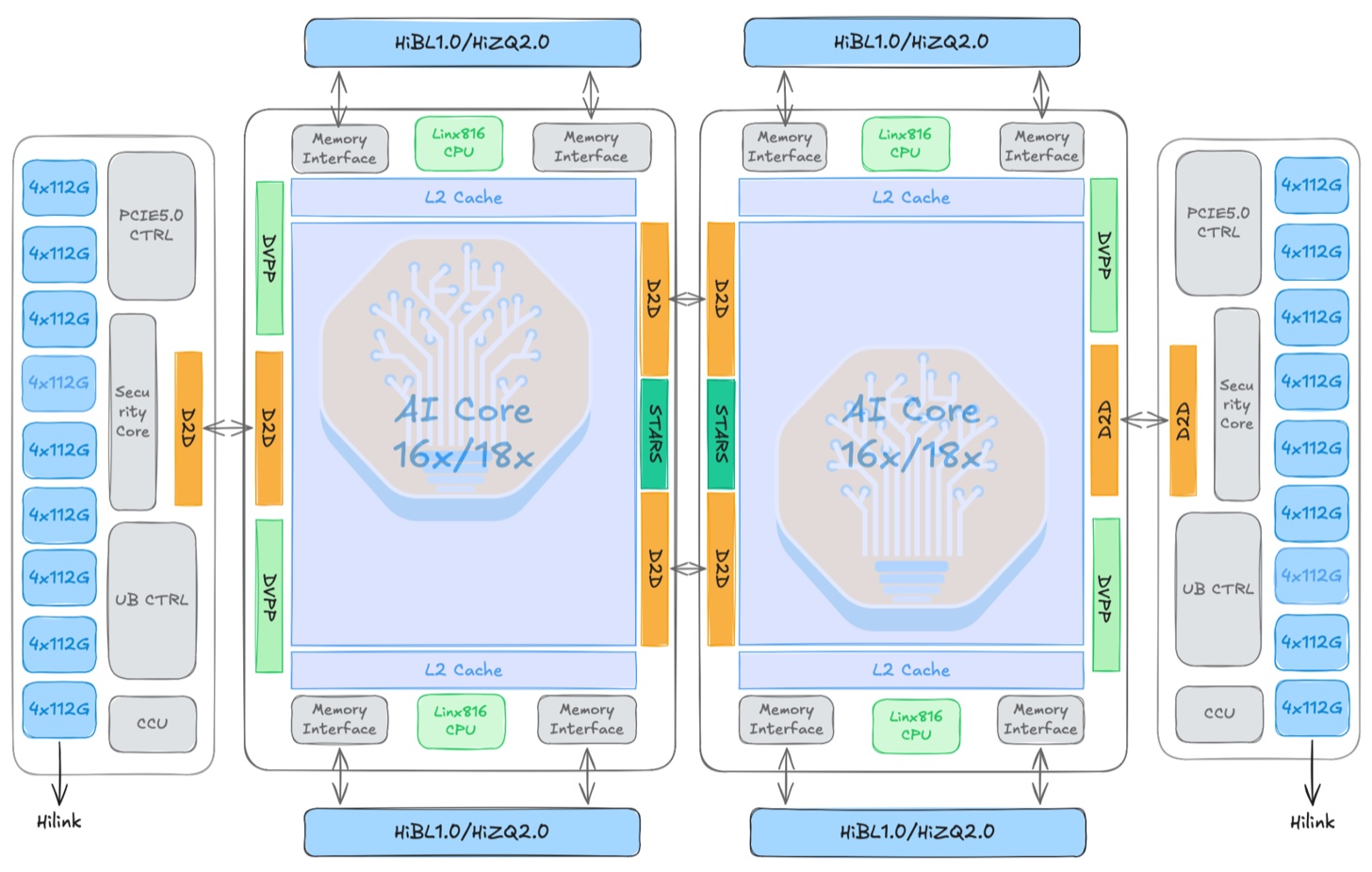
芯片架构中有两个重要组件值得讨论:AIC(AI Cube)和 AIV(AI Vector)。AIC 是 Ascend AI Core 的矩阵/张量核心部分,用于密集矩阵运算:GEMM、matmul、类卷积张量操作、attention 投影、FFN 线性层等。Huawei 文档将 AIC 描述为分离式 AI Core 架构中的矩阵计算核心。AIV 是向量核心部分,处理逐元素/向量运算:激活函数、归一化组件、掩码、规约、类型转换、布局变换、matmul 的后处理等。
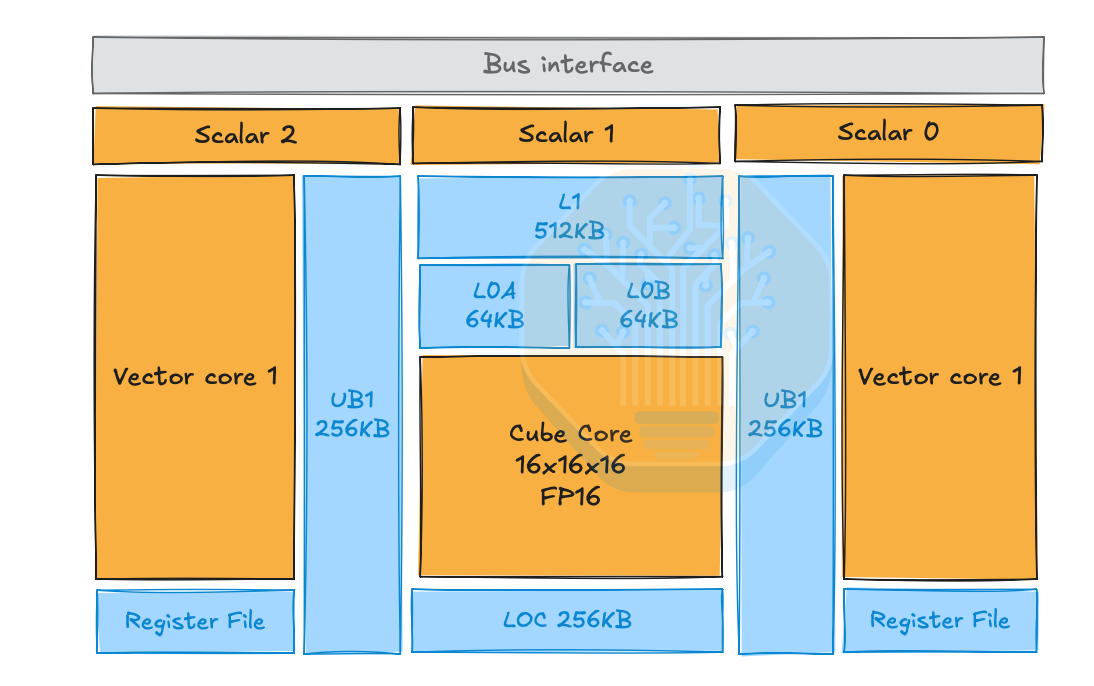
这与 TPU 的 MXU 类似。不过 Ascend 将两种功能更直接地暴露为独立的分离核心,每个核心都能加载自己的代码段,并且支持"双主模式"——AIC 和 AIV 独立运行代码,而非由 AIV 通过消息驱动 AIC。
AI CPU 是一个具有直接设备内存访问权限的设备端 ARM64 执行单元。它作为 AI Core 的补充,处理不适合在 SIMD/SIMT 核心上执行的工作:分支密集的控制流、标量逻辑、动态形状处理,以及 kernel 运行前需要的值依赖的调度/分块元数据。由于 AI CPU 位于设备上,Ascend 可以将这些不规则的控制型工作保留在本地,而非在主机 CPU 之间来回传输——后者是延迟(latency)和流水线气泡的主要来源。AI CPU 也是在专用 CCU 分担通信编排之前,历史上位于旧有 AICore → AICPU → SDMA 路径上的单元。
与 TPU 和 Trainium 类似,Ascend 950 增加了专用的 CCU 通信引擎。该引擎与计算 die 并列,处理集合通信工作而不消耗 AI Core 的计算容量,支持远程读取 + 规约 + 本地写入,以及本地读取 + 远程写入。其优势在于更低的通信延迟、更少的 HBM 流量、更少的用户缓冲区拷贝,以及将计算核心从通信编排中解放出来,避免走旧有的 AICore → AICPU → SDMA 路径。
Huawei DeepSeekV4 Pro 950DT Profile
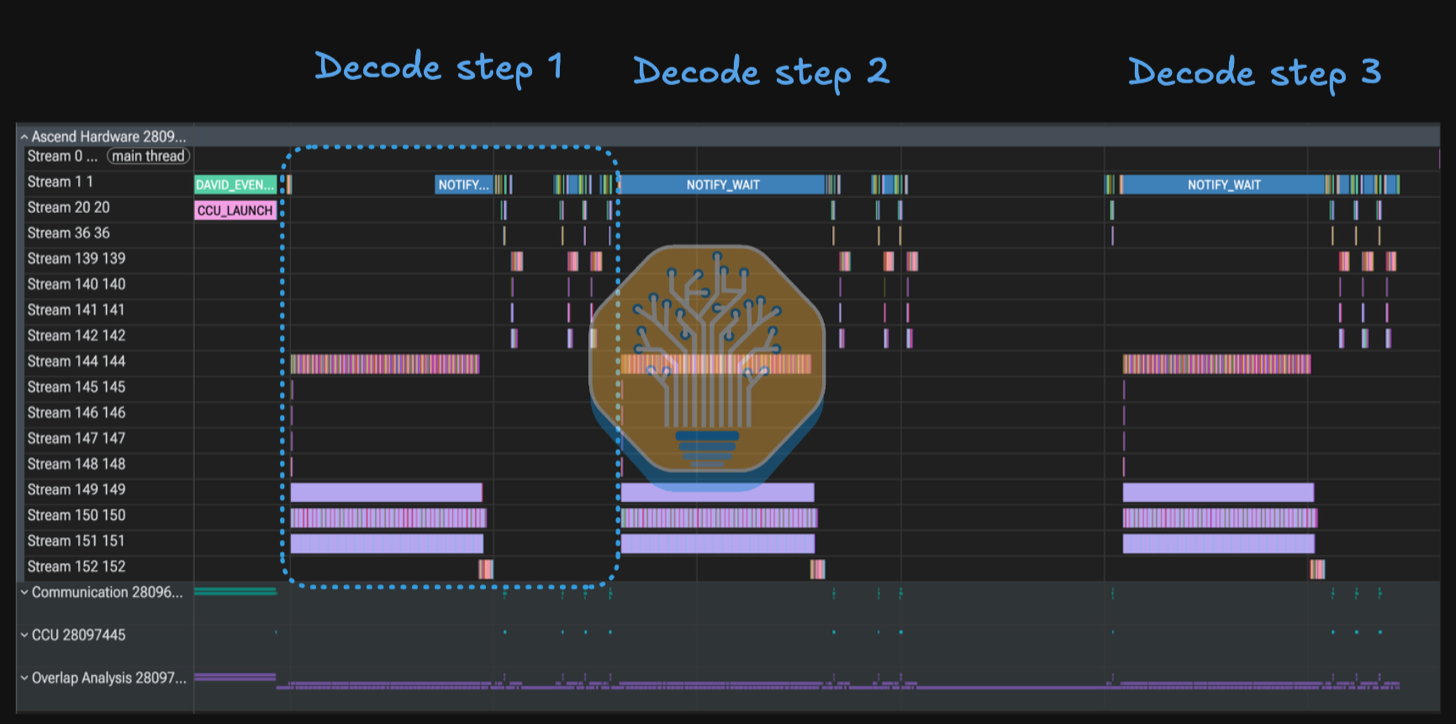
上图展示了 DeepSeek flash v4 在 Ascend 950DT 上的三步 profile,使用 16 rank DP/EP 部署配置运行。它显示了 16 rank 集合通信参与以及活跃的 MoE dispatch/combine 流量。
与大多数栈目前的标准做法一样,CANN 也使用可在多个流上运行的独立计算和通信算子——通过控制 Cube 和 Vector 核心分配来避免资源争用从而提升性能。Prolog、Compressor 和 LightningIndexer 等操作可以重叠执行,C4A Compressor 可以完全隐藏,shared expert 计算可以隐藏在 routed expert 执行之下而不降低 routed expert 性能。
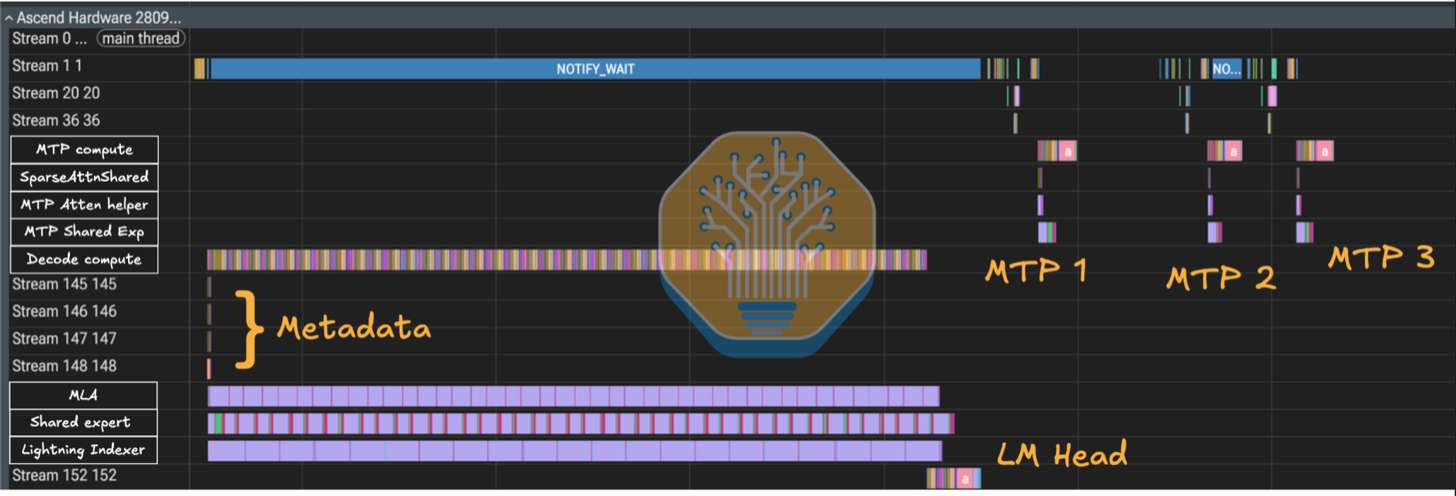
放大某个解码步骤,我们可以看到不同组件如何被分配到不同的流。不同流上的操作在设备有空闲的合适资源时可以并行运行。模型使用多个流,因为一层可能不是单一的串行链,而可以包含只需在结果合并时才同步的分支——例如 shared-expert 计算与 routed-expert 计算 100% 重叠。
上图中的 Streams 145-148 对应元数据流。这些算子每次解码步骤触发一次,预计算后续 kernel 复用的值依赖调度/分块元数据。它们是解码步骤中唯一的 AI CPU 操作,占总时间的极小比例,且完全被 AI Core 计算重叠。其影响在更长上下文的基准测试中可能更显著,因为需要提前解析更多序列长度和掩码相关的分区。
在 DeepSeek v4 中,Huawei 将稀疏注意力和 LightningIndexer 的值依赖调度阶段移到了 AI CPU 上,而非回弹到主机。这些元数据操作根据运行时序列长度、掩码和分页 KV 信息构建可复用的每核心分区张量;SparseAttnSharedkv 和 QuantLightningIndexer 随后使用它们来决定每个 cube 核心处理哪些 Batch/Head/Q-block/K-block 工作,以及相应的 vector 核心规约任务。从概念上讲,这类似于 FlashInfer 在主机端为分页 attention 所做的 planning 阶段:一个低成本、动态形状感知的设置步骤,只运行一次因此在各层间摊销——唯一区别是 Huawei 将同样的 planning 工作推到了设备端 AI CPU 上而非主机端。
上图中的 Stream 152 包含 LM head、最后一层,以及倒数第二层的 o_proj 和 MoE。这是 npugraph_ex 图编译器的决策,可能是为了让 npugraph_ex 运行时将 stream 144 上的主图视为"完成",同时尾部工作继续异步执行。
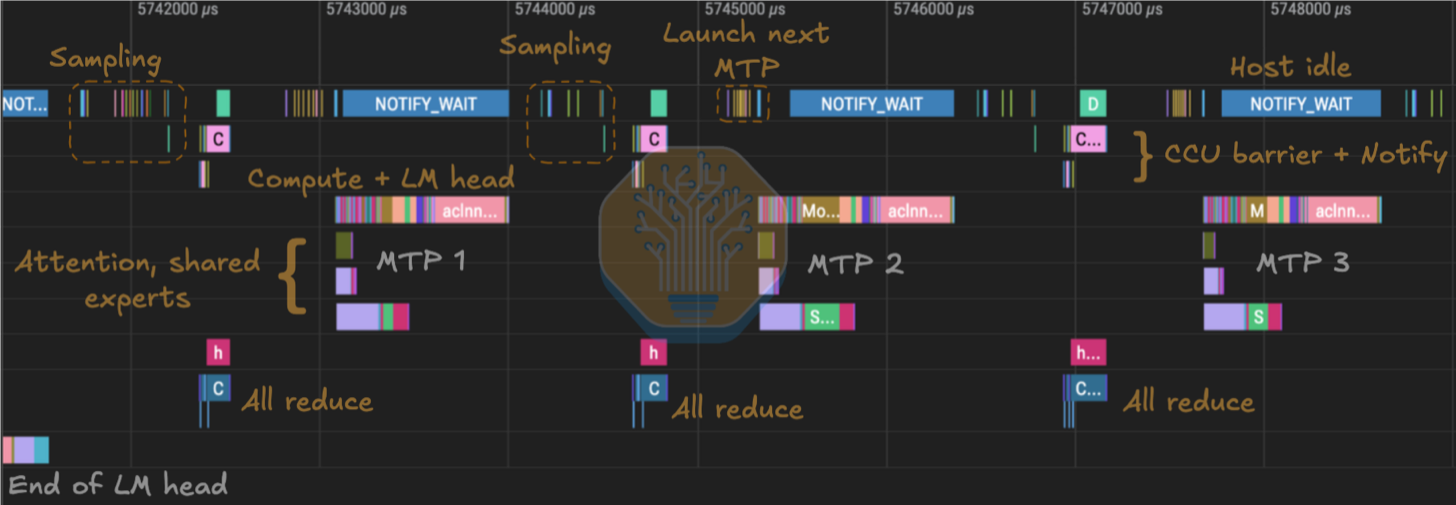
CANN 早在 2024 年就引入了 MC²(merged compute-communication,计算-通信融合)。这是一类既非普通 kernel 也非 HCCL 集合通信的融合算子,它们将通信和计算嵌入一个 kernel 中。在 DeepSeek v4 解码中,我们可以看到 MoeDistributeDispatchV2 和 MoeDistributeCombineV2 MC² EP 算子被使用。
这里的核心要点是 Ascend 在第 0 天即交付了可用的、经过优化的 DeepSeek v4 推理基础设施。Huawei CANN 栈是仅有的两个具备 DeepSeekV4 第 0 天支持的栈之一,另一个是 Nvidia 的 CUDA。如文章前面所述,AMD 的栈在第 0 天不幸未能良好运行。这与去年 DeepSeek v3/R1 发布时形成了鲜明对比。当时只有一个栈在第 0 天可用:Nvidia CUDA 栈。
赋予 Ascend 950 内部代号的那个圣经故事以巨人倒地收场。但故事中的 Goliath 是站着不动让 David 投石的,而 Nvidia 的 Goliath 却在不断运动,每年推出新架构并改进现有架构。Huawei 已经证明它能在第 0 天投出一块石头;至于能否击倒一个不断移动的巨人,尚待观察。
DeepSeek V4 架构深度解析与协同设计
针对 1M 上下文长度的推理优化
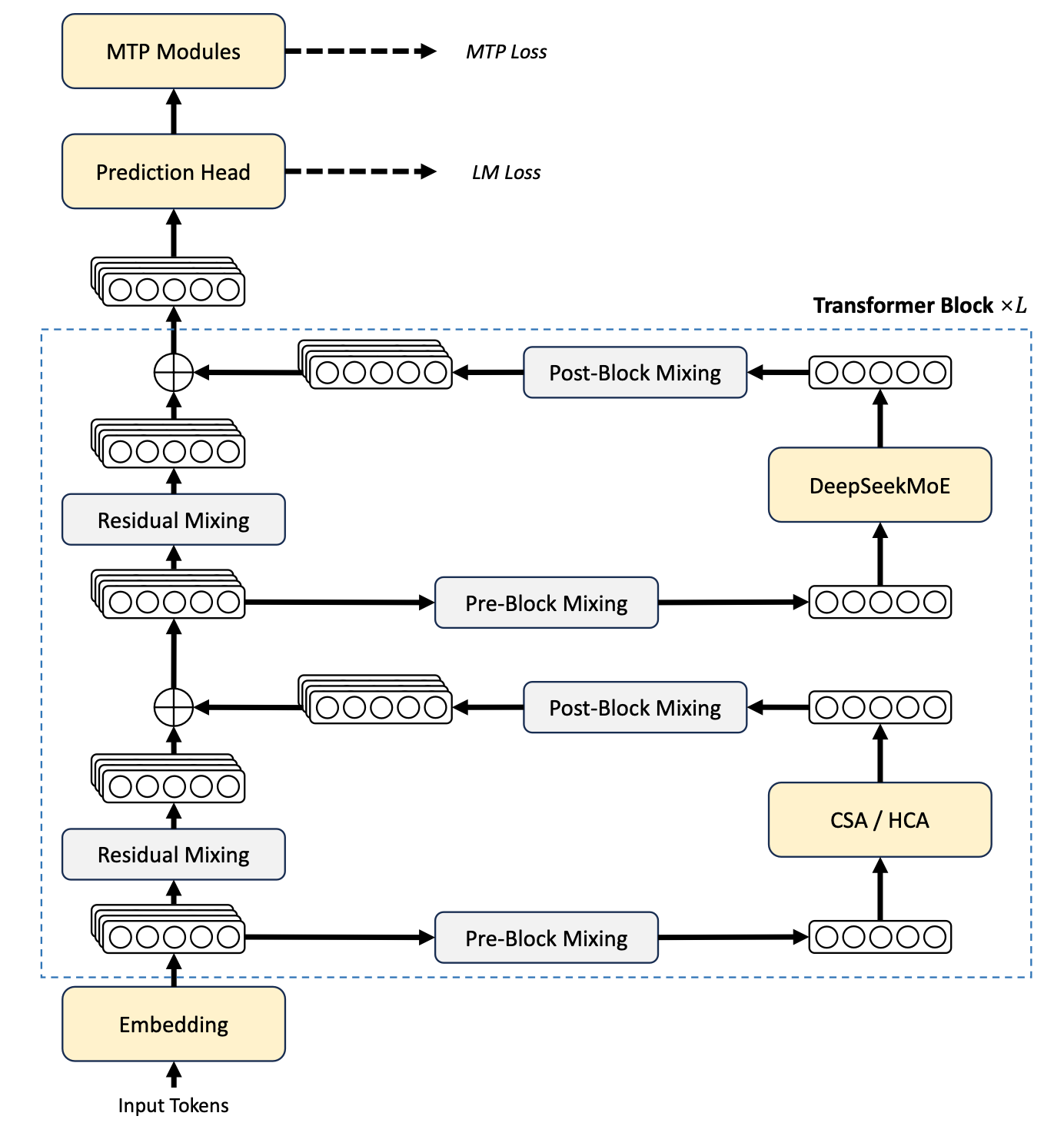
DeepSeek v4 引入了压缩稀疏注意力(Compressed Sparse Attention, CSA)和高度压缩注意力(Heavily Compressed Attention, HCA),告别了多头潜在注意力(Multi-head Latent Attention, MLA)。该设计的核心动机是减小 KV cache 大小。
本质上,HCA 的 KV cache 由 KV embedding 的滑动窗口和一组压缩 KV 条目组成,其中每个条目将 key/value 压缩为一个并跨越 m′ 个 token(DeepSeek V4 Pro 中 m′ = 128)。
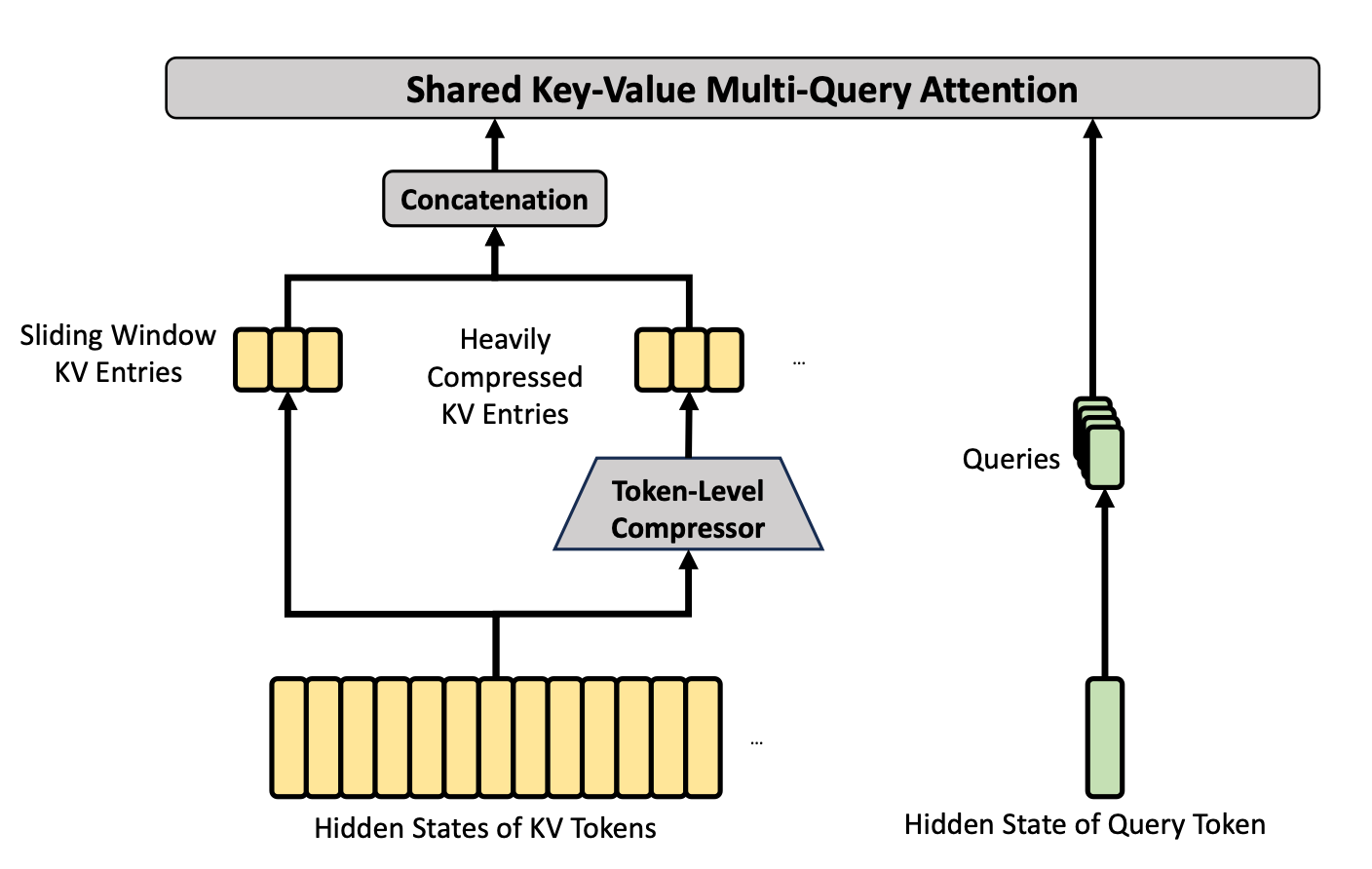
CSA 使用与 HCA 相同的 KV cache 压缩技术,但压缩率较低(m=4)。CSA 还通过 lightning indexer 选择要 attend 的 token,对压缩后的 KV 条目应用稀疏注意力。该稀疏注意力继承自 DeepSeek v3.2 中的 DeepSeek Sparse Attention。
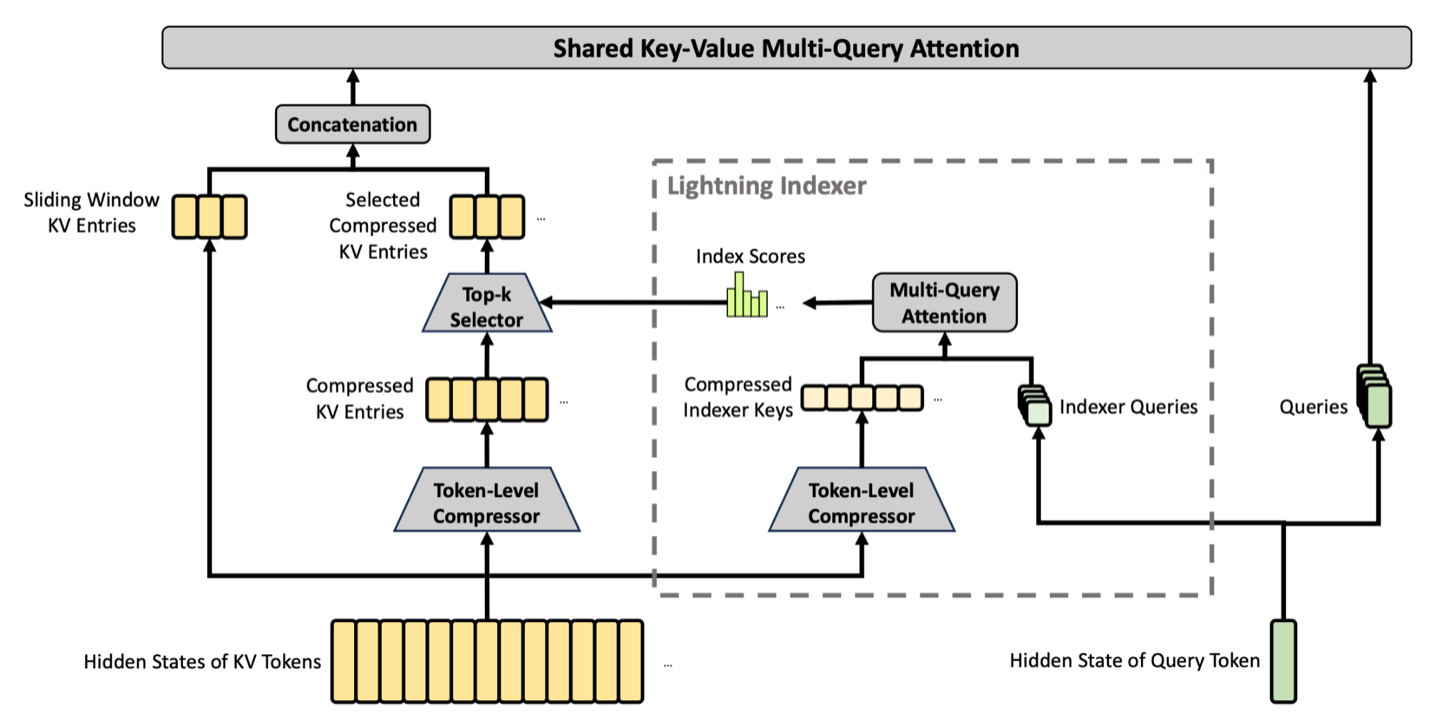
通过交错使用 CSA 和 HCA,DeepSeek v4 大幅压缩了 KV cache 大小,在 1M 上下文长度下实现了 50 倍的 KV cache 缩减。
然而,CSA 和 HCA 的新颖性给服务框架带来了 KV cache 管理挑战。例如,vLLM 的 KV cache 内存分配器实现了复杂的策略来确保高效的内存加载模式并支持前缀缓存(prefix caching)等服务特性。这包括设置逻辑块大小使其能整除 CSA 和 HCA 的 KV 压缩率,以及页面大小分桶策略以避免因 KV cache、compressor 状态、indexer KV 各自每条目大小不同而导致的内存碎片。
确定性
为确保 RL 训练的稳定性,DeepSeek 全力推进计算的确定性。这一努力在 GPU kernel 及其部署基础设施中均有体现。DeepSeek 为所有操作编写了自定义 kernel 以实现批不变性(batch invariance),通过强制执行特定的规约顺序(无论批大小如何)来保证确定性。这包括批不变的 split KV attention forward、GEMM 和 MoE backward kernel。批不变 kernel 会带来性能损失,因为使用它们意味着无法采用许多流行的不保证确定性规约顺序的算法技术。DeepSeek 通过编写针对自身工作负载定制的 kernel 来缓解性能损失,例如为特定矩阵形状特化 kernel。在部署基础设施方面,DeepSeek 着力于容错以使所有 rollout 可复现。DeepSeek 为每个生成请求构建了 token 粒度的预写日志(WAL),因此在 prefill 或 decode 期间被抢占的任何请求都可以在不重新计算的情况下恢复。
MegaMoE
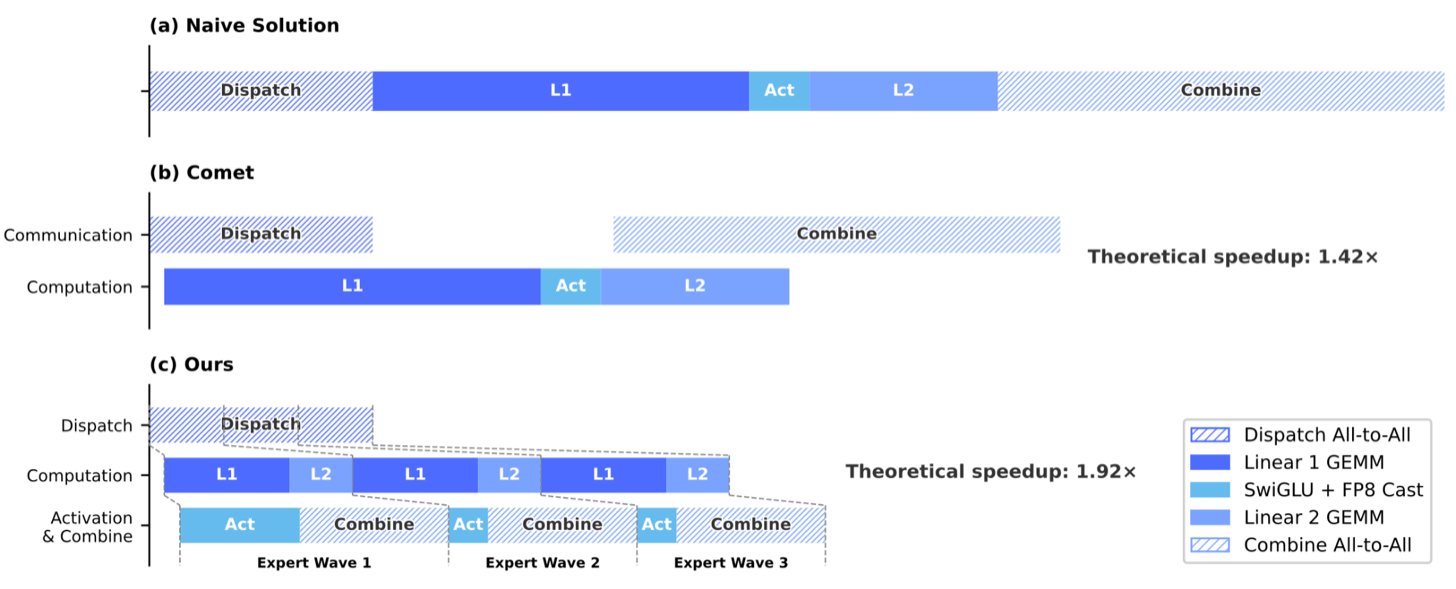
DeepSeek V4 的发布还包含了一个新的融合 MoE kernel,实现了 MoE 层中所有操作的更好重叠。使用专家并行(Expert Parallelism)的 MoE 首先进行 token dispatch all-to-all,然后是 Linear1、Activation、Linear 2,最后是 token combine all-to-all。Linear 1 和 Linear 2 是分组 GEMM 操作,其中给定 rank 中的每个专家将其权重应用于其路由到的 token。作者在 DeepSeek V4 论文中提到,其他实现将 token dispatch 与 Linear 1 以及 Combine 与 Linear 2 进行重叠/交错,但在操作边界——Linear 1、Activation 和 Linear 2 之间——仍然存在跨所有专家的同步。MegaMoE 则将专家拆分为多个 wave,分别调度每个 wave,实现更细粒度的操作重叠,从而隐藏更多通信延迟。这让人联想到分布式 GEMM 等计算-通信融合,即将计算 kernel 和依赖的通信 kernel 通过拆分为更小的片段并流水线化来重叠,以隐藏通信延迟。
论文声称在 DeepSeek v4 Flash 配置下,理论加速比相对于 naive kernel 为 1.92 倍,这意味着 naive kernel 必须将接近 50% 的时间花在 Dispatch 和 Combine 通信上!
在详细讨论了性能基准测试之后,让我们来讨论在 H200 和 GB200 NVL72 上运行 DeepSeek v4 的总拥有成本和每 token 成本。
本文后续包含 H200 和 GB200 NVL72 的完整总拥有成本和每 token 成本分析,详见 SemiAnalysis 通讯订阅版。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。