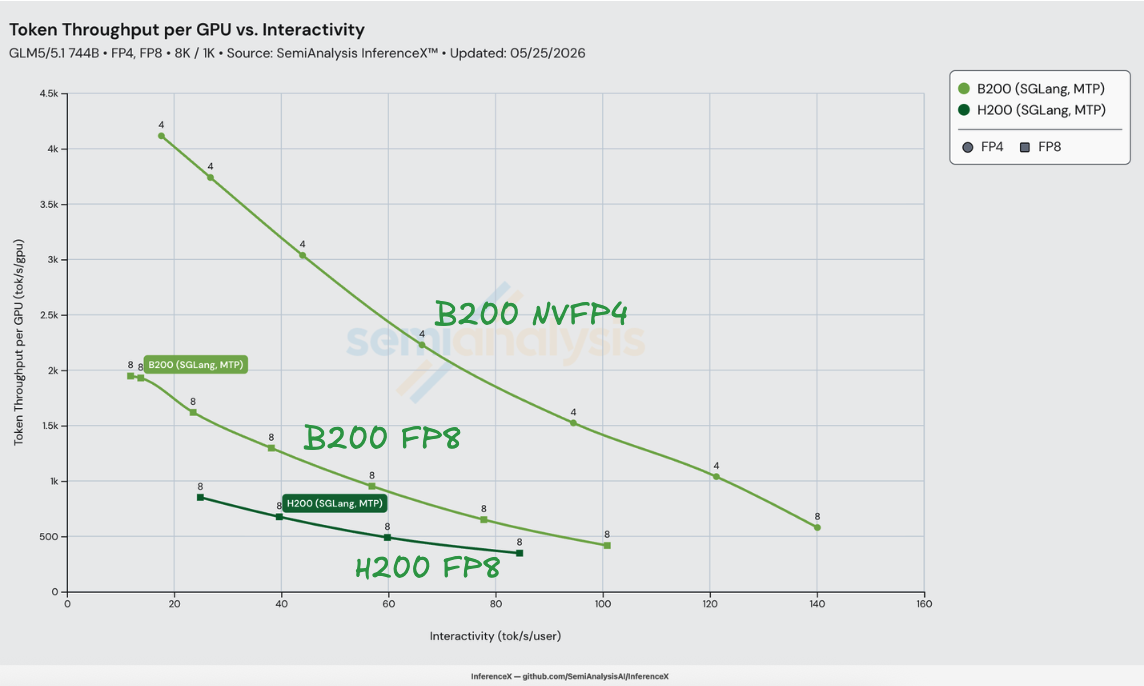
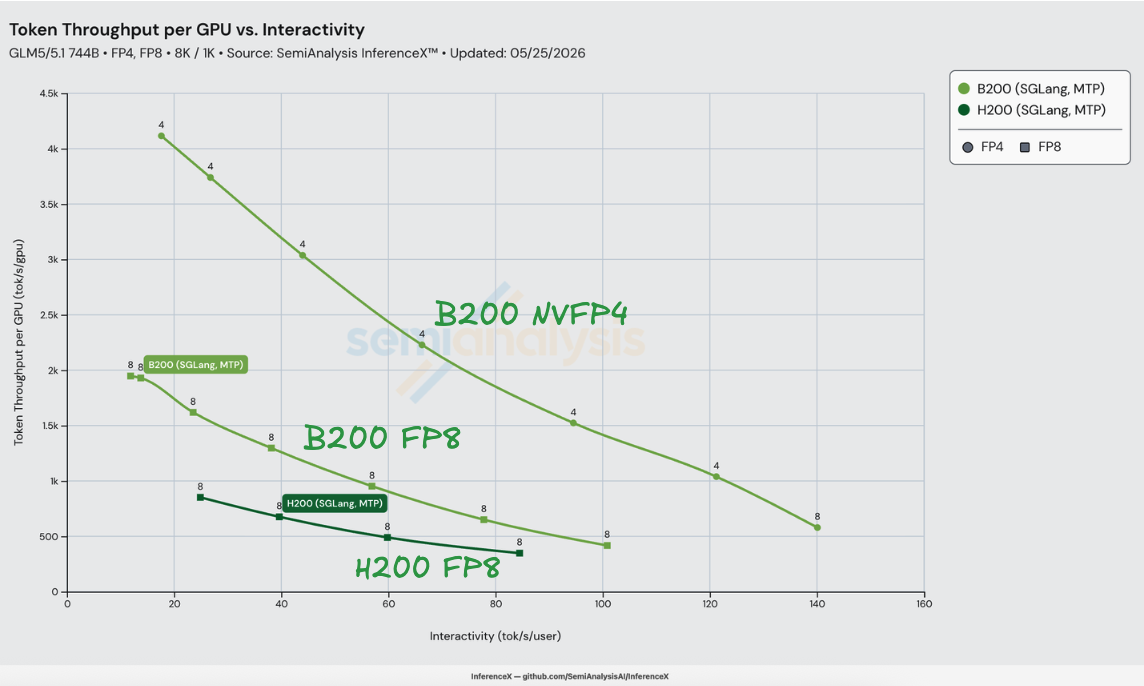
在 GLM-5 8K/1K 工作负载下,H200 和 B200 均运行 SGLang 时,NVIDIA 的 GLM-5-NVFP4 检查点在 B200 上实现了等交互性(iso-interactivity)下性价比最高达 H200 SGLang FP8 的 3.65 倍——在 80 tok/s/user 时,H200 的成本为 $1.06/M tokens,而 B200 NVFP4 仅为 $0.29/M tokens。该优势在 H200 的整个 25–84 tok/s/user 运行区间内保持在 3.24x–3.65x 范围。数据基于 2026-05-25 InferenceX 基准测试(benchmark),使用 SGLang v0.5.12。
这 3.65 倍的提升在峰值处可清晰分解。在 80 tok/s/user 时,B200 SGLang FP8 + MTP 的性价比是 H200 SGLang FP8 + MTP 的 1.22 倍——这是在相同精度和相同 EAGLE 方案下,仅靠 Blackwell 世代硬件 + 软件带来的提升。将 B200 的权重从 zai-org/GLM-5-FP8 切换为 nvidia/GLM-5-NVFP4 再叠加 2.98 倍——这是仅靠精度切换带来的提升,得益于 FlashInfer 的 TRT-LLM 稀疏 MLA 内核——该内核已在 sgl-project/sglang #21783 中被设为 sm100/sm103 的默认后端。1.22 × 2.98 ≈ 3.65。在不同运行区间,两个因素的贡献比例会互换——世代因素在低交互性时贡献更大(50 tok/s/user 时为 1.36x),精度因素在高交互性时贡献更大(84 tok/s/user 时为 3.07x)——但组合提升始终保持稳定。
GLM-5 是智谱(ZAI/Zhipu)的 MoE 旗舰模型,发布于 2026-02-11——距本次测试约 14 周。它是一个 744B 参数的稀疏 MoE,每个 token 激活约 40B 参数:256 个专家 + top-8 路由(约 5.9% 稀疏度)加共享专家,解码阶段使用 DeepSeek Sparse Attention(DSA) 并搭配 Multi-head Latent Attention(MLA)进行 KV 缓存压缩,上下文窗口为 200K。发布的架构名称为 glm_moe_dsa——与 DeepSeek 在 V3.2 中引入的稀疏注意力模式相同,也是 SGLang 在 Blackwell 上的 TRT-LLM 稀疏 MLA 后端所针对优化的架构。
NVIDIA 还发布了量化权重版本 nvidia/GLM-5-NVFP4——与 zai-org/GLM-5-FP8 采用相同的模型架构,但所有 MoE GEMM 权重从 FP8 重新转换为 NVFP4(16 元素分块、FP8 逐块缩放因子、FP32 逐张量缩放因子)。KV 缓存保持 FP8。这就是图表(chart)中 B200 曲线所加载的检查点;H200 曲线加载 zai-org/GLM-5-FP8,因为 Hopper 没有 FP4 张量核心。
纸面规格
在介绍具体方案之前,先看硬件。H200 SXM(Hopper)和 B200 SXM(Blackwell)相隔一代。下方雷达图(chart)将每个轴归一化到 /gpu-specs 中所有 NVIDIA + AMD SKU 的最大值——因此 H200 和 B200 的多边形在 GB200/GB300 NVL72 设定上限的轴上显得较小(特别是 Scale-up Domain Memory 和 Scale-up Domain Memory Bandwidth,它们随 72-GPU NVLink 域的机架级规模而扩展)。
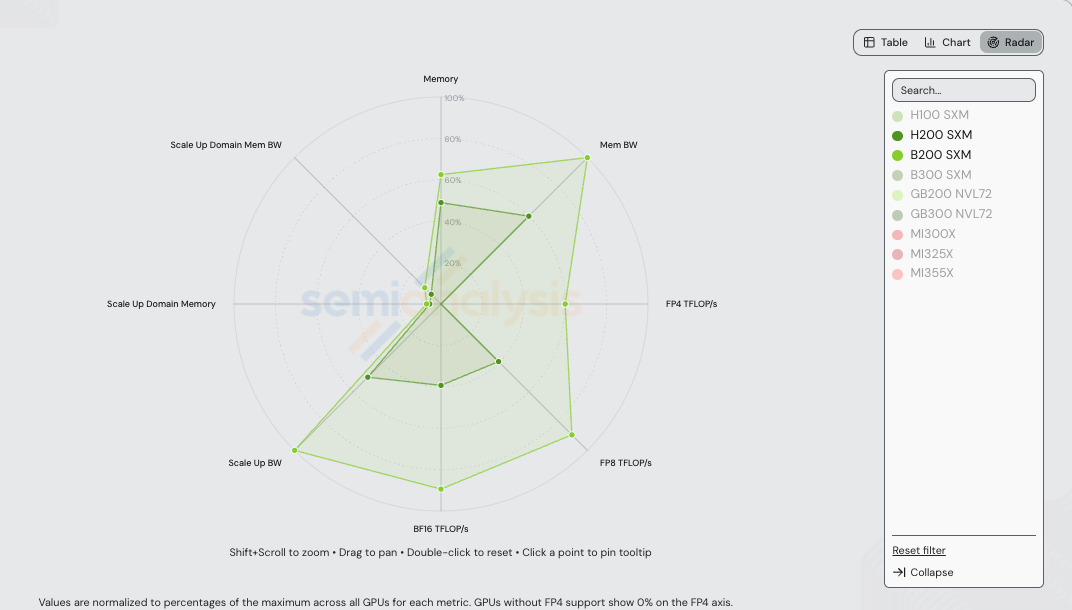
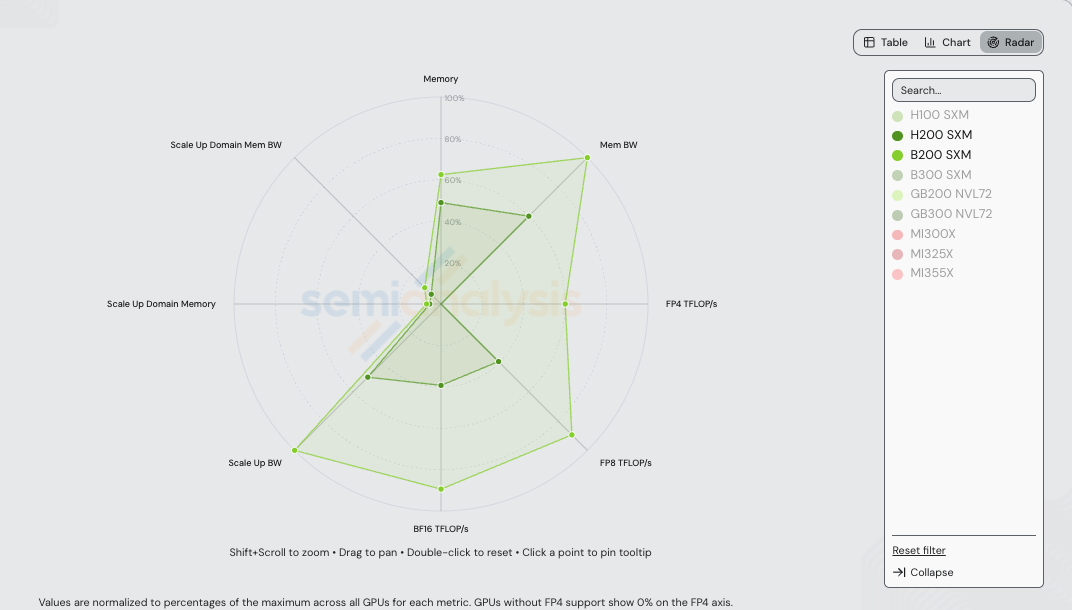
本次基准测试中两款 SKU 的绝对值:
| 规格 | H200 SXM | B200 SXM | B200 / H200 |
|---|---|---|---|
| HBM 容量 | 141 GB (HBM3e) | 180 GB (HBM3e) | 1.28x |
| HBM 带宽 | 4.8 TB/s | 8.0 TB/s | 1.67x |
| Dense FP4 (TFLOP/s) | — | 9,000 | — |
| Dense FP8 (TFLOP/s) | 1,979 | 4,500 | 2.27x |
| Dense BF16 (TFLOP/s) | 989 | 2,250 | 2.28x |
| Scale-up 每 GPU 带宽(单向) | 450 GB/s (NVLink 4) | 900 GB/s (NVLink 5) | 2.00x |
| Scale-up 节点规模 | 8 | 8 | 1.00x |
| Scale-up Domain HBM 容量 | 1,128 GB | 1,440 GB | 1.28x |
| Scale-up Domain HBM 带宽(聚合) | 38.4 TB/s | 64.0 TB/s | 1.67x |
| TCO(SemiAnalysis AI Cloud 模型) | $1.41/GPU/hr | $1.95/GPU/hr | 1.38x |
对 FP8 对 FP8 对比的启示:在相同精度和相同方案下,B200 相对 H200 的性价比上限在完全计算瓶颈的工作负载上约为 2.27 / 1.38 ≈ 1.64x,在完全显存带宽瓶颈的工作负载上约为 1.67 / 1.38 ≈ 1.21x(以 HBM 为带宽轴;若以 NVLink 带宽计,则上限为 2.00 / 1.38 ≈ 1.45x)。实测在 80 tok/s/user 时为 1.22x,落在显存带宽瓶颈区间内——GLM-5 在此并发度下的解码阶段主要受 MoE 权重和 KV 缓存的 HBM 读取限制,而非 FP8 GEMM 吞吐量,因此 Blackwell 的 dense 计算余量大部分未被利用。NVFP4 才是打破 GEMM 天花板的关键杠杆:H200 没有 FP4 张量核心,而 B200 拥有 9 PFLOP/s,由此带来的精度提升在世代提升之上再叠加 2.41x–3.07x。
促成此结果的上游变更
上游软件栈。 SGLang v0.5.10(2026-04-07)是 GLM-5 首次在 Blackwell 上跨所有四个精度/MTP/分离式推理变体完整端到端运行的稳定版本——跟踪 issue #19380 在同日将每个 Functional 和 Baseline Perf 行标记为 DONE。本文的基准测试运行于 v0.5.12(发布于 2026-05-16),它继承了相同的 Blackwell 默认配置并增加了第一轮性能优化。关键内核变更:
- sgl-project/sglang #21783 将 FlashInfer TRT-LLM 稀疏 MLA 内核设为 sm100/sm103(B200/B300)的默认注意力后端。DSA prefill 和 decode 现在运行在 GLM-5/V3.2 所针对调优的内核上,而非曾在 B200 上引发 GLM-5 精度回归 的旧
flashmla_kv路径。 - sgl-project/sglang #21405 为稀疏 MLA 启用了 IndexCache,在连续 decode 步骤间复用索引张量,在相同内核调用序列上带来 >10% 的 decode 吞吐量提升。
- flashinfer-ai/flashinfer #2726(FlashInfer v0.6.6.post1)修复了一个间歇性 NVFP4 非法内存访问 bug,此前一直阻塞 NVFP4 的功能验证签核;flashinfer-ai/flashinfer #2836(v0.6.7)提升了 trtllm-gen 稀疏 MLA 的性能上限。
MTP。 GLM-5 复用了 SGLang 为 DeepSeek V3.2 构建的 EAGLE 推测解码管线(--speculative-algorithm EAGLE --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4),并通过 SGLANG_ENABLE_SPEC_V2=1 启用 overlap 调度器。H200 和 B200 使用完全相同的参数集——两款 SKU 在下面方案中唯一的不同是模型检查点和注意力后端的选择。
详细数据
所有行均为 GLM-5 在 ISL 8192 / OSL 1024 下的单节点非分离式推理结果,数据来自 2026-05-25 的 InferenceX 基准测试,使用 SGLang v0.5.12 并在每个方案中启用基于 EAGLE 的 MTP。每百万 total tokens 成本计算公式为 TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6),H200 为 $1.41/GPU/hr,B200 为 $1.95/GPU/hr,来源于 SemiAnalysis AI Cloud TCO 模型。
容器镜像:两款 SKU 均使用 lmsysorg/sglang:v0.5.12-cu130。
H200 SGLang FP8 + MTP,TP=8,8 GPU(模型 zai-org/GLM-5-FP8):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 347.9 | 84.49 | 11.84 | $1.13 |
| 8 | 489.7 | 59.82 | 16.72 | $0.80 |
| 16 | 675.9 | 39.64 | 25.22 | $0.58 |
| 32 | 851.9 | 24.90 | 40.16 | $0.46 |
| 64 | 847.2 | 20.80 | 48.08 | $0.46 |
并发 64 时 tok/s/GPU 略有回落,因为首 token 延迟(TTFT)开始主导请求时间预算——并发 32 在此方案下设定了 H200 的吞吐量上限和成本下限。Pareto 前沿剔除了并发 64,因为并发 32 在两个轴上都优于它。
B200 SGLang FP8 + MTP,TP=8,8 GPU(模型 zai-org/GLM-5-FP8):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 417.0 | 100.85 | 9.92 | $1.30 |
| 8 | 650.1 | 77.82 | 12.85 | $0.83 |
| 16 | 952.7 | 56.93 | 17.57 | $0.57 |
| 32 | 1,296.8 | 38.16 | 26.21 | $0.42 |
| 64 | 1,619.3 | 23.56 | 42.45 | $0.33 |
| 128 | 1,929.5 | 13.78 | 72.59 | $0.28 |
| 256 | 1,947.3 | 11.88 | 84.15 | $0.28 |
B200 SGLang NVFP4 + MTP,TP=4,4 GPU(模型 nvidia/GLM-5-NVFP4)——成本前沿的锚点:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,038.7 | 121.22 | 8.25 | $0.52 |
| 8 | 1,523.5 | 94.53 | 10.58 | $0.36 |
| 16 | 2,228.1 | 66.27 | 15.09 | $0.24 |
| 32 | 3,037.3 | 43.99 | 22.73 | $0.18 |
| 64 | 3,739.7 | 26.78 | 37.33 | $0.14 |
| 128 | 4,115.5 | 17.63 | 56.73 | $0.13 |
| 256 | 4,090.7 | 17.37 | 57.57 | $0.13 |
B200 SGLang NVFP4 + MTP,TP=8,8 GPU——单个高交互性数据点,向右延伸 FP4 前沿:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 579.2 | 140.08 | 7.14 | $0.94 |
TP=8 / 8 GPU 配置以牺牲一半的每 GPU 吞吐量为代价,在相同并发下获得了比 TP=4 高 16% 的交互性——额外的 GPU 将 TPOT 从 8.25 ms 降至 7.14 ms。FP4 的综合 Pareto 前沿从 $0.13/M(TP=4,并发 128)的 18 tok/s/user 延伸至 $0.94/M(TP=8,并发 4)的 140 tok/s/user。
等交互性下的性价比对比
在匹配的交互性水平下,沿每款 SKU 的 Pareto 前沿插值得出的每 GPU 吞吐量和每百万 tokens 成本。最后一列的性价比提升倍数为 $/M 比值的倒数——B200 NVFP4 相对于 H200 的性价比。超出前沿测量范围的单元格标记为 unreachable。
| 交互性 (tok/s/user) | H200 FP8 MTP $/M | B200 FP8 MTP $/M | B200 NVFP4 MTP $/M | B200 NVFP4 性价比 vs H200 |
|---|---|---|---|---|
| 25 | $0.46 | $0.34 | $0.14 | 3.24x |
| 30 | $0.50 | $0.37 | $0.15 | 3.32x |
| 40 | $0.58 | $0.43 | $0.17 | 3.44x |
| 50 | $0.69 | $0.51 | $0.19 | 3.54x |
| 60 | $0.80 | $0.60 | $0.22 | 3.60x |
| 70 | $0.93 | $0.72 | $0.26 | 3.63x |
| 80 | $1.06 | $0.87 | $0.29 | 3.65x |
| 84 | $1.12 | $0.94 | $0.31 | 3.64x |
| 100 | unreachable | $1.28 | $0.38 | ∞ |
| 120 | unreachable | unreachable | $0.51 | ∞ |
| 140 | unreachable | unreachable | $0.93 | ∞ |
B200 NVFP4 相对 H200 的性价比提升在 80 tok/s/user 时达到峰值 3.65 倍,且在整个 H200 运行区间内保持在 3.24x–3.65x 范围——不存在 H200 FP8 + MTP 能在 3 倍以内接近 B200 NVFP4 + MTP 的交互性点。仅精度切换带来的提升(B200 FP8 → B200 NVFP4)随交互性单调递增,从 25 tok/s/user 时的 2.41 倍到 84 tok/s/user 时的 3.07 倍,因为 B200 FP8 的性价比随批量减小而下降得更快。在 84 tok/s/user 以上,对比便不复存在:H200 没有任何方案能再提供一个 tok/s/user 的交互性,而 B200 NVFP4 的运行区间还可以延伸 60 tok/s/user,直达 TP=8 下的 140 tok/s/user。
在线图表,已预筛选为 2026-05-25 测试中 H200 + B200 上的 GLM-5 SGLang MTP。在线成本视图展示相同对比的成本维度。
GLM-5 在 Blackwell 上的后续进展
三个方向仍有望进一步提升当前数字,均已在上游跟踪中:
- NVL72 上的分离式推理。 上述数字均为单节点聚合方式。跟踪 issue 正在积极推进 FP8 B200 分离式 8K/1K 及 GB300 分离式 MTP 的工作。宽 EP(Expert Parallelism)在 NVL72 上已在 Kimi K2.5 上展示了每 GPU 吞吐量约 3 倍的优势——同样的杠杆应该能在 FP4 前沿趋于平台的低交互性/高吞吐量端进一步提升 GLM-5 的性价比。
对于在 25–84 tok/s/user 区间的聊天场景 GLM-5 推理,B200 NVFP4 + MTP 在使用 SGLang 的每个可测量运行点上均实现了 H200 FP8 + MTP 3.2x–3.65 倍的性价比优势。
致谢
本轮方案优化进展迅速,得益于 SGLang 与 NVIDIA 的协作在大约一个季度内完成了 Blackwell 上 no-MTP/MTP 和 Agg/Disagg 的所有 Functional 和 Baseline Perf 行——FlashInfer 中的 NVFP4 IMA 修复、sm100/sm103 上的稀疏 MLA 默认配置、IndexCache、GLM-5 的基于 EAGLE 的 MTP——而 InferenceX 方案循环在上游稳定后一周内即完成了 H200 MTP 兄弟方案的接入。感谢 SGLang 维护者、FlashInfer 团队、NVIDIA SGLang 协作线程以及在跟踪 issue 上提交 PR 的所有人。上游到基准测试的闭环速度就是护城河。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。