在 MiniMax-M2.5 8K/1K 负载下使用 vLLM,NVIDIA 的 NVFP4 量化版 MiniMax-M2.5 在 B200 上实现了等交互性下相比 H100 vLLM FP8 最高 8.2 倍的每美元性能提升——110 tok/s/user 时 H100 为 $0.74/M tokens,B200 NVFP4 为 $0.09/M tokens。提升幅度在 H100 的 21–111 tok/s/user 工作区间内单调递增,从低端的 4.0 倍(22 tok/s/user,$0.12 vs $0.031)增长到高端的 8.2 倍。测量于 2026-05-22 的 InferenceX。
这 8.2 倍在峰值处可以清晰分解。在 110 tok/s/user 时,B200 vLLM FP8 相比 H100 vLLM FP8 实现了 2.94 倍的每美元性能提升——这是纯硬件代际提升,两个 SKU 上使用相同的 MiniMaxAI/MiniMax-M2.5 权重和相同的 vLLM 构建。将 B200 权重切换为 nvidia/MiniMax-M2.5-NVFP4 后又叠加了 2.77 倍——这是纯精度提升,由 vllm-project/vllm #36307 解锁——该 PR 添加了 trtllm-gen FP8 MoE 内核的模块化变体,使 MiniMax 的非标准路由方法得以使用该内核。2.94 × 2.77 ≈ 8.14。精度提升随交互性增长而扩大(22 tok/s/user 时 1.65 倍 → 110 时 2.77 倍),这是因为 trtllm-gen 内核相比旧版 triton 路径的优势在 GEMM 天花板成为瓶颈时更为突出。
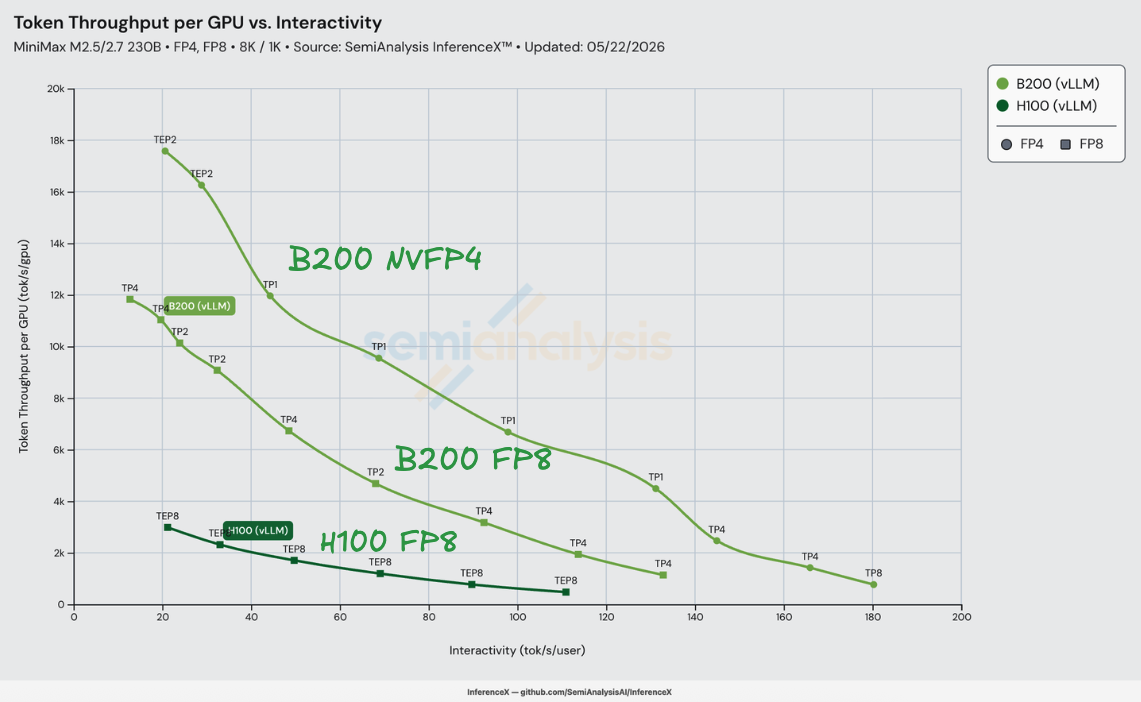
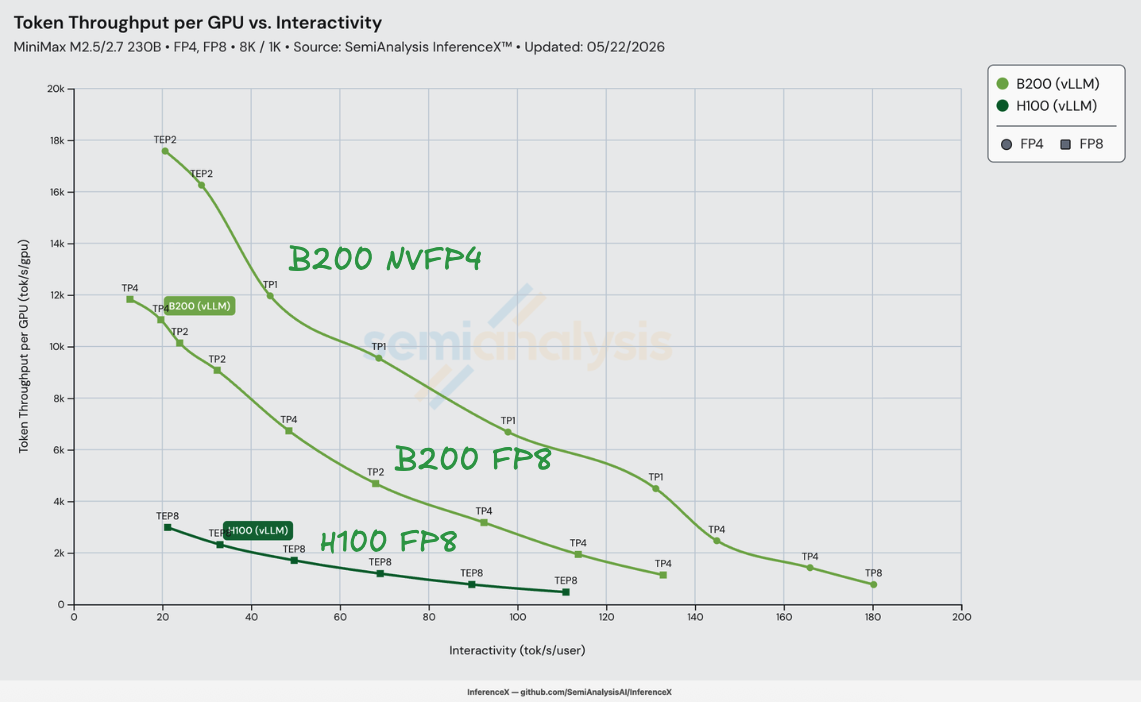
MiniMax-M2.5 是 MiniMax AI 的旗舰 MoE 模型:总参数 230B,每 token 激活 10B,采用 256 个小专家(架构不同于早期 MiniMax-Text-01 的 32 个大专家)。公开权重发布于 MiniMaxAI/MiniMax-M2.5,NVIDIA 发布了量化版 nvidia/MiniMax-M2.5-NVFP4,将所有 MoE GEMM 权重从 BF16/FP8 重新量化为 NVFP4(16 元素分组、FP8 逐组缩放因子、FP32 逐张量缩放因子)。KV cache 保持 FP8。图表中 B200 NVFP4 曲线加载 NVIDIA 量化权重;B200 FP8 和 H100 FP8 曲线加载原始 MiniMaxAI 权重。
本文涉及的关键架构细节是路由方法。MiniMax M2 的专家路由层生成的 routing logits 使用的数据类型不被原始("单体式")trtllm-gen FP8 MoE 内核接受——这就是为何 MiniMax 在 B200 上一直被限制在较慢的 triton MoE 路径上,直到 vLLM PR #36307 添加了在外部处理路由的模块化内核变体。我们将在"关键技术贡献"部分详细展开。
为何 MiniMax-M2.5 值得投入优化
MiniMax-M2.5 是 M2 系列中面向编码和智能体的开源权重模型。其 256 小专家路由层针对软件工程工作负载进行了调优(SWE-Bench 系列、Terminal Bench、智能体工具使用评估),在主要编码质量评估中与 Claude Opus 4.5/4.6 在每项基准测试上的差距仅 1–4 分,并在 Multi-SWE-Bench(51.3 vs 42.7)和 VIBE-Pro(54.2 vs 36.9)上领先 Gemini 3 Pro。特别是 Multi-SWE-Bench——Opus 4.5 得分 50.0、Opus 4.6 得分 50.3——M2.5 以 51.3 领先。
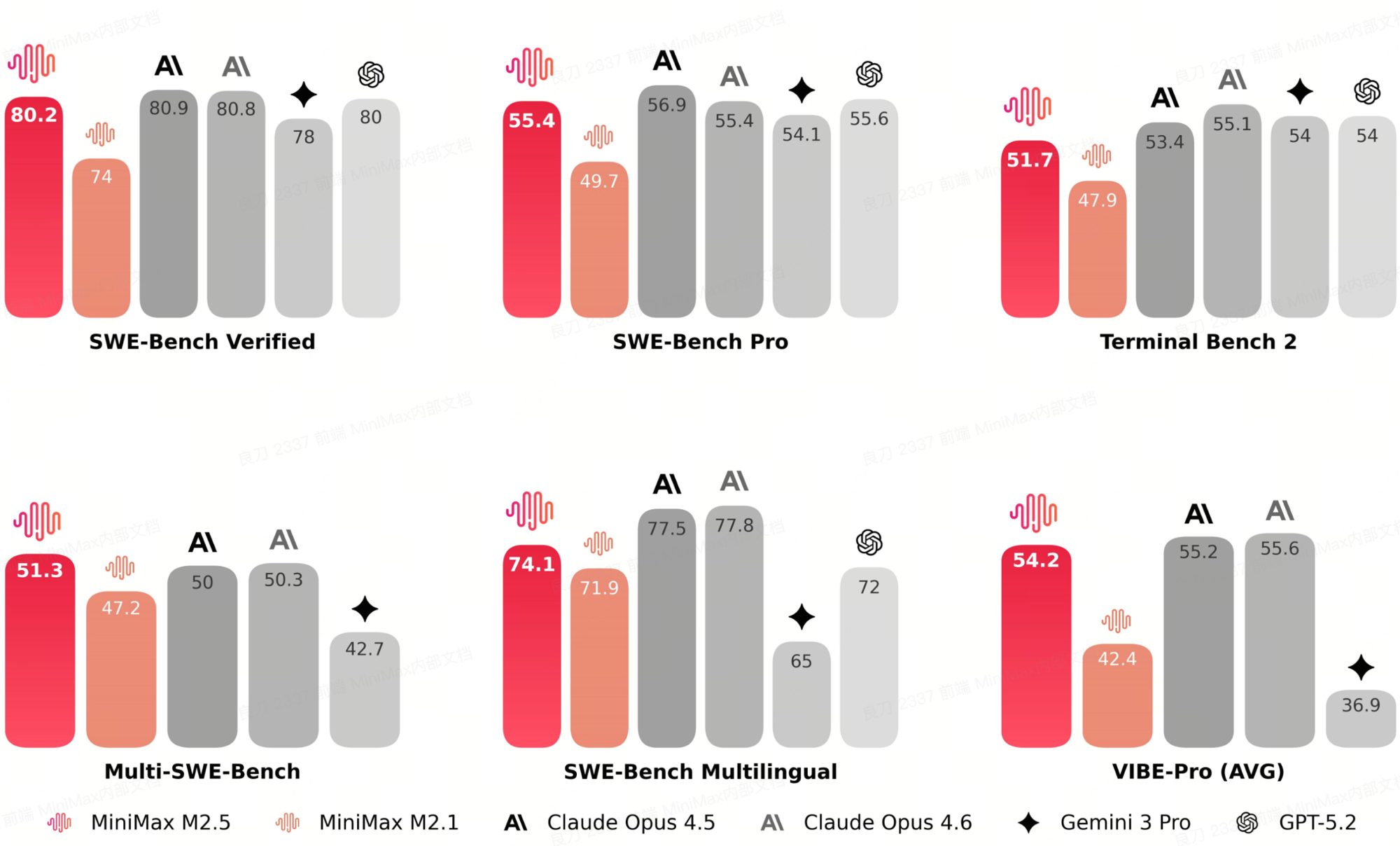
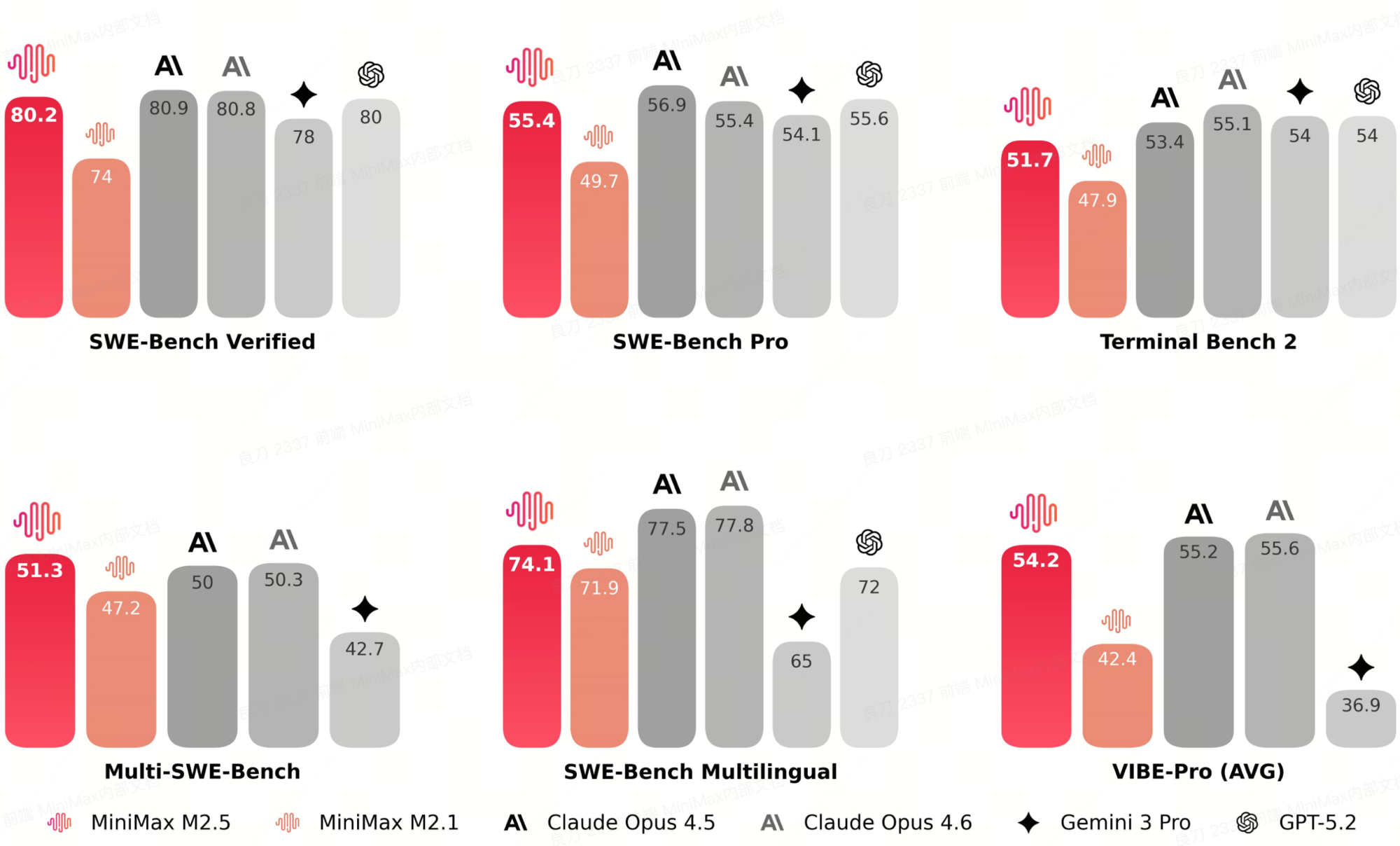
质量水准是服务成本故事的前提。一个激活参数仅 10B 的开源 MoE 模型,在前沿专有编码模型的射程范围内——在 B200 NVFP4 的吞吐量锚点处仅需 $0.031/M tokens——相比将同样的工作负载路由到闭源 API 前沿模型,完全是不同的部署成本量级。下文介绍的 vLLM PR + NVFP4 + B200 技术栈,将这类智能体/SWE 循环工作负载的推理成本从"连续运行成本高昂"压缩到了可以让自主编码智能体持续运行数小时而不至于账单本身成为架构约束的区间。
H100 vs B200 纸面规格对比
在介绍具体配方之前,先看硬件。H100 SXM(Hopper,2023)和 B200 SXM(Blackwell,2025)相隔两代。下方雷达图将每个轴归一化到 /gpu-specs 中所有 NVIDIA + AMD SKU 的最大值——因此 H100 和 B200 的可见多边形在 GB200/GB300 NVL72 设定天花板的轴上(特别是扩展域显存容量和扩展域显存带宽,按 72-GPU NVLink 域扩展)被压缩。
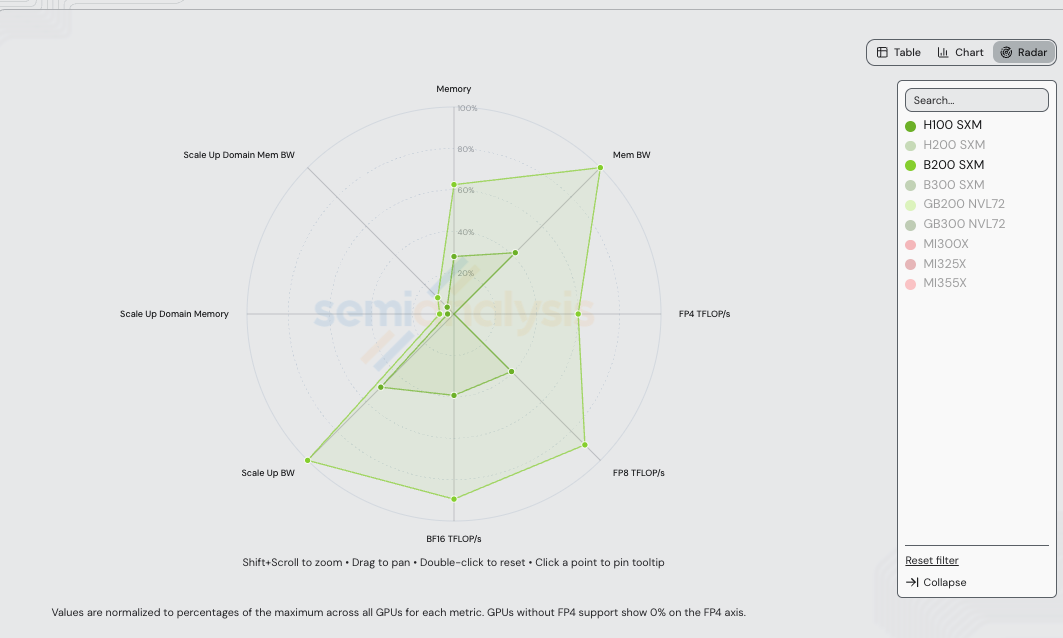
本次基准测试涉及的两个 SKU 的绝对值:
| 规格 | H100 SXM | B200 SXM | B200 / H100 |
|---|---|---|---|
| HBM 容量 | 80 GB (HBM3) | 180 GB (HBM3e) | 2.25x |
| HBM 带宽 | 3.35 TB/s | 8.0 TB/s | 2.39x |
| 密集 FP4 (TFLOP/s) | — | 9,000 | — |
| 密集 FP8 (TFLOP/s) | 1,979 | 4,500 | 2.27x |
| 密集 BF16 (TFLOP/s) | 989 | 2,250 | 2.28x |
| 每 GPU 扩展带宽(单向) | 450 GB/s (NVLink 4) | 900 GB/s (NVLink 5) | 2.00x |
| 扩展域 GPU 数 | 8 | 8 | 1.00x |
| 扩展域 HBM 容量 | 640 GB | 1,440 GB | 2.25x |
| 扩展域 HBM 带宽(聚合) | 26.8 TB/s | 64.0 TB/s | 2.39x |
| TCO(SemiAnalysis AI Cloud 模型) | $1.30/GPU/hr | $1.95/GPU/hr | 1.50x |
硅片本身带来了什么?B200 的 FP8 算力是 H100 的 2.27 倍(4,500 vs 1,979 TFLOP/s),B200 的 FP4 算力是 H100 FP8 算力的 4.55 倍(9,000 vs 1,979 TFLOP/s——Hopper 没有 FP4 张量核心,因此精度步骤是跨精度算力提升,而非同精度对比),HBM 带宽提升 2.39 倍(8.0 vs 3.35 TB/s),TCO 仅为 1.50 倍。这些原始比率限定了性能/成本的天花板:FP8 vs FP8 计算瓶颈下为 1.51 倍(2.27 / 1.50),HBM 带宽瓶颈下为 1.59 倍(2.39 / 1.50),或者 B200 NVFP4 vs H100 FP8 跨精度算力轴下为 3.03 倍(4.55 / 1.50)。
实测数据更为出色。2.94 倍的 FP8 代际提升几乎是 FP8 硅片天花板的 2 倍,8.16 倍的综合提升约为跨精度 FP4 硅片天花板的 2.7 倍——超出硅片天花板的部分来自 trtllm-gen 模块化 FP8 MoE 内核(vLLM PR #36307),实现了旧版 triton MoE 路径无法做到的优化。H100 上的 vLLM 技术栈在运行 MiniMax-M2.5 时相比 B200 上 trtllm-gen 内核路径的发挥还留有大量空间。NVFP4 在此基础上叠加了精度步骤的提升,因为 B200 拥有 9 PFLOP/s 的 FP4 算力,而 H100 为零。
TensorRT-LLM MoE 内核集成至 vLLM
上游:vLLM PR #36307——TRTLLM FP8 MoE 模块化内核。 vllm-project/vllm #36307,由 Wei Zhao 提交,2026-03-12 合入,为 Blackwell 添加了 trtllm-gen FP8 MoE 内核的模块化变体。此前的"单体式"trtllm-gen 内核仅接受特定数据类型的 routing logits,这排除了 MiniMax M2 等路由层输出不同数据类型的模型。模块化内核在外部完成路由,从而消除了数据类型约束——MiniMax M2(及更广泛的 MoE 模型)现在可以使用 DeepSeek/Kimi/GLM-5 在 B200 上已有的快速 attention + MoE 内核路径。该 PR 的测试计划在 MiniMaxAI/MiniMax-M2.5 上以 TP=2 + 专家并行运行,与下方 B200 前沿使用的配方形状相同。
内核的选择至关重要。以下是 MiniMax-M2.5 上的逐内核对比(1K/1K——不是 8K/1K,但内核排序一致),展示了 vLLM 中各 MoE 后端的表现:
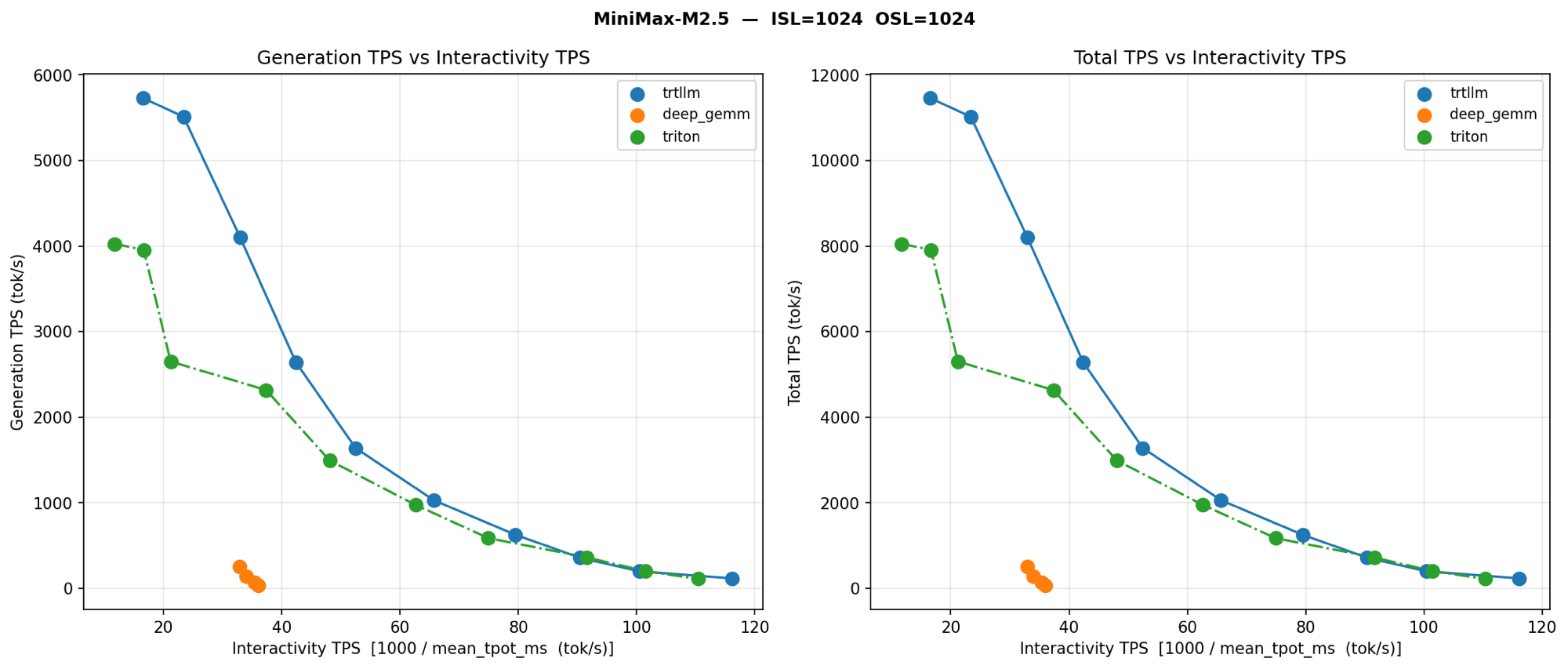
数据详情
所有数据行均为 MiniMax-M2.5 在 ISL 8192 / OSL 1024 下,使用单节点非分离式配置,于 2026-05-22 在 InferenceX 上使用 vLLM 测量。每百万总 token 的成本计算公式为 TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6),其中 H100 为 $1.30/GPU/hr,B200 为 $1.95/GPU/hr,参照 SemiAnalysis AI Cloud TCO 模型。
H100 vLLM FP8,TP=8,8 GPU(模型 MiniMaxAI/MiniMax-M2.5):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 476.5 | 110.93 | 9.01 | $0.76 |
| 8 | 771.4 | 89.71 | 11.15 | $0.47 |
| 16 | 1,193.7 | 69.09 | 14.47 | $0.30 |
| 32 | 1,707.6 | 49.70 | 20.12 | $0.21 |
| 64 | 2,317.0 | 33.00 | 30.31 | $0.16 |
| 128 | 2,985.6 | 21.19 | 47.19 | $0.12 |
B200 vLLM FP8,TP=2,2 GPU(大部分曲线的吞吐量锚点):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,926.8 | 112.30 | 8.90 | $0.28 |
| 8 | 3,143.5 | 92.25 | 10.84 | $0.17 |
| 16 | 4,684.8 | 68.04 | 14.70 | $0.12 |
| 32 | 6,514.0 | 47.40 | 21.10 | $0.08 |
| 64 | 9,079.0 | 32.35 | 30.91 | $0.06 |
| 128 | 10,053.9 | 23.91 | 41.82 | $0.05 |
| 256 | 10,134.1 | 23.92 | 41.81 | $0.05 |
| 512 | 10,112.2 | 23.85 | 41.93 | $0.05 |
B200 vLLM FP8,TP=4,4 GPU(延伸低交互性段):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 256 | 11,035.8 | 19.67 | 50.85 | $0.05 |
| 512 | 11,827.1 | 12.71 | 78.68 | $0.05 |
B200 vLLM NVFP4,TP=2,2 GPU(左侧成本前沿锚点,模型 nvidia/MiniMax-M2.5-NVFP4):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 128 | 16,256.5 | 28.82 | 34.70 | $0.03 |
| 256 | 17,407.3 | 20.61 | 48.51 | $0.03 |
| 512 | 17,577.0 | 20.63 | 48.47 | $0.03 |
B200 vLLM NVFP4,TP=1,1 GPU(中高交互性段):
| 并发 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 4,488.8 | 131.18 | 7.62 | $0.12 |
| 8 | 6,683.0 | 97.87 | 10.22 | $0.08 |
| 16 | 9,546.6 | 68.76 | 14.54 | $0.06 |
| 32 | 11,698.0 | 44.16 | 22.65 | $0.05 |
| 256 | 11,962.0 | 44.29 | 22.58 | $0.05 |
B200 vLLM NVFP4,TP=4 和 TP=8,4 和 8 GPU(在 conc=4 处延伸高交互性段):
| 配方 | 并发 | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|---|
| TP=4 / 4 GPUs | 4 | 1,423.3 | 165.92 | 6.03 | $0.38 |
| TP=4 / 4 GPUs | 8 | 2,468.9 | 144.91 | 6.90 | $0.22 |
| TP=8 / 8 GPUs | 4 | 768.6 | 180.26 | 5.55 | $0.70 |
NVFP4 组合帕累托前沿从 21 tok/s/user 时的 $0.031/M(TP=2,conc=512)延伸到 180 tok/s/user 时的 $0.70/M(TP=8,conc=4)。
等交互性每美元性能
在匹配交互性水平下的每 GPU 吞吐量和每百万 token 成本,沿各 SKU 的帕累托前沿插值。最后一列的每美元性能提升为 $/M 比率的倒数——B200 NVFP4 相对于 H100 的性能/成本。超出前沿测量范围的单元格显示为 unreachable。
| 交互性 (tok/s/user) | H100 FP8 $/M | B200 FP8 $/M | B200 NVFP4 $/M | B200 NVFP4 性能/$ vs H100 |
|---|---|---|---|---|
| 22 | $0.12 | $0.05 | $0.031 | 3.96x |
| 30 | $0.15 | $0.06 | $0.034 | 4.32x |
| 40 | $0.18 | $0.07 | $0.042 | 4.23x |
| 50 | $0.21 | $0.08 | $0.048 | 4.39x |
| 60 | $0.25 | $0.10 | $0.052 | 4.85x |
| 70 | $0.31 | $0.12 | $0.058 | 5.36x |
| 80 | $0.38 | $0.14 | $0.065 | 5.84x |
| 90 | $0.47 | $0.16 | $0.073 | 6.41x |
| 100 | $0.60 | $0.20 | $0.083 | 7.19x |
| 110 | $0.74 | $0.25 | $0.091 | 8.16x |
| 130 | unreachable | $0.44 | $0.118 | ∞ |
| 150 | unreachable | unreachable | $0.250 | ∞ |
| 175 | unreachable | unreachable | $0.569 | ∞ |
B200 NVFP4 相对于 H100 的性能/成本优势从 22 tok/s/user 时的 3.96 倍单调递增至 110 tok/s/user 时的 8.16 倍,峰值 8.23 倍出现在 110.8 tok/s/user——H100 可测量范围的右端。与同代对比中提升基本恒定不同,此处提升增长迅速:H100 的前沿在右端急剧下降(其 conc=4 点仅为 476 tok/s/GPU、$0.76/M),而 B200 NVFP4 在相同交互性下仍有 4–5 倍的吞吐量。纯精度提升(B200 FP8 → B200 NVFP4)从 22 tok/s/user 时的 1.65 倍扩大到 110 时的 2.77 倍——随着批量缩小,trtllm-gen 内核的 GEMM 优势相比 triton 路径成为主导约束。在 110 tok/s/user 以上,对比不再成立:H100 没有任何配方能再提供一个 tok/s/user,而 B200 NVFP4 将可用范围延伸至 TP=8 下的 180 tok/s/user。
实时图表,已预过滤为 MiniMax-M2.5 vLLM 在 H100 + B200 上 2026-05-22 运行的数据。实时成本视图展示相同对比。
Blackwell 在 MiniMax-M2.5 上的后续方向
仍有三个方向可以进一步扩大或强化标题数据:
- NVL72 分离式(无需宽专家并行)。 更宽的专家并行对此模型不是正确的杠杆——在 10B 激活参数、256 个小专家的情况下,TP=2 / 8-GPU 配置中每个 rank 已经只持有少量专家,因此在 72-GPU NVLink 域中扩展 EP 不会显著缩小每 rank 权重占用(不同于 DeepSeek R1 或 Kimi K2.5,后者可通过 EP 集合上的计算-通信重叠实现复合增益)。分离式 prefill + decode 仍然可行:当前的单节点聚合配方将两个阶段放在同一个 TP=2 岛上,在 conc 256+ 饱和拐点处争抢 HBM 带宽;GB200/GB300 NVL72 上的分离式配方将 KV 通过 NVLink 5 在专用 prefill 和 decode 池之间传输,使 decode 池在饱和前能吸收更多并发。InferenceX 尚未发布 MiniMax 在 NVL72 上的分离式配方。
对于当前的 MiniMax-M2.5 服务,B200 NVFP4 在 H100 可达的每个交互性点上都是更经济的选择,优势为 4 倍至 8.2 倍。
致谢
NVIDIA 的 Wei Zhao 于 2026-03-12 在 vLLM 中合入了 trtllm FP8 MoE 模块化内核。感谢 Wei Zhao 和 vLLM TRT-LLM 内核协作者、InferenceX 配方维护者以及 MiniMax AI 团队发布的开源权重。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。