B200 运行 SGLang 0.5.6 处理 DeepSeek R1 NVFP4 在 8k/1k 工作负载并发数 4 下达到 907 tok/s/GPU,相比 0.5.5 的 508 tok/s/GPU 提升了 1.79 倍。两次测试使用相同的 16 GPU 资源池,TP 4 / EP 4 配置。唯一的变化是 Docker 镜像从 lmsysorg/sglang:v0.5.5-cu129-amd64 更新为 lmsysorg/sglang:v0.5.6-cu129-amd64。
SGLang 0.5.6 于 2025-12-03 发布,InferenceX 基准测试在 28 天后的 2025-12-31(镜像更新当天)捕捉到了完整的性能提升效果。这正是我们构建 InferenceX 自动化基准测试循环的原因 — 在硬件不变的情况下,第一时间捕捉软件驱动的性能变化。
性能提升在低并发下最为显著。在并发数 4 和 8 时,解码循环的每步耗时中有相当比例花在 Python 调度器和内核分发代码上而非矩阵乘法中,因此 0.5.6 的调度器和计算图优化效果最为直接。在高并发下 tensor core 接近饱和,较小的吞吐量提升(并发数 64 为 1.03 倍,并发数 128 为 1.16 倍)来自重构后的注意力内核路径。
SGLang 0.5.6 中的关键更新
SGLang 0.5.6 于 2025-12-03 发布。三项更新与低并发吞吐量提升直接相关。分段 CUDA graph 支持扩展到了 DeepSeek V3 和 MLA 注意力路径,减少了构建和回放计算图的每步 Python 开销。事件循环在 PD 分离式、重叠式和 DP 注意力服务模式间统一,降低了内部循环开销。引入了 JIT 内核,减少了启动成本并允许内核编译针对运行时观察到的形状进行特化。
另外三项 0.5.6 更新影响注意力内核路径。MHA 和 MLA KV 缓存重构以支持 FP4。FlashInfer TRTLLM GEN MHA 路径重新启用。FlashInfer 更新至 0.5.2。这些在高并发下更为重要,此时 KV 缓存较大且注意力计算是主要开销。并发数 128 下的 1.16 倍提升即来自此路径。
基准测试数据
所有数据均为 DeepSeek R1 NVFP4,ISL 8192 / OSL 1024,来自 InferenceX。0.5.5 数据来自 2025-12-15 的测试,镜像由 InferenceX PR #204 设置,该 PR 于 2025-11-10 将 B200 SGLang 配置从 v0.5.3rc1-cu129-b200 升级至 v0.5.5-cu129-amd64。0.5.6 数据来自 2025-12-31 的测试,由 InferenceX PR #276 触发,该 PR 将 Docker 镜像更新至 v0.5.6-cu129-amd64,无其他配置更改。
B200 SGLang,DeepSeek R1 NVFP4,TP 4 / EP 4 解码,16 GPU 非分离式资源池。该方案遵循 SGLang DeepSeek V3/R1 部署指南。
| 版本 | 并发数 | tok/s/GPU | TPOT (ms) | tok/s/user | 提升 |
|---|---|---|---|---|---|
| 0.5.5 | 4 | 508 | 9.2 | 108.4 | 基准 |
| 0.5.5 | 8 | 903 | 11.6 | 86.5 | 基准 |
| 0.5.5 | 16 | 1,471 | 15.7 | 63.8 | 基准 |
| 0.5.5 | 32 | 2,302 | 22.2 | 45.1 | 基准 |
| 0.5.5 | 64 | 3,323 | 33.7 | 29.6 | 基准 |
| 0.5.5 | 128 | 4,430 | 54.9 | 18.2 | 基准 |
| 0.5.6 | 4 | 907 | 9.2 | 108.5 | 1.79x |
| 0.5.6 | 8 | 1,437 | 11.6 | 86.0 | 1.59x |
| 0.5.6 | 16 | 1,500 | 15.5 | 64.6 | 1.02x |
| 0.5.6 | 32 | 3,063 | 22.0 | 45.6 | 1.33x |
| 0.5.6 | 64 | 3,419 | 32.9 | 30.4 | 1.03x |
| 0.5.6 | 128 | 5,145 | 53.7 | 18.6 | 1.16x |
加粗行是本文的核心数据:0.5.6 在并发数 4 下达到 907 tok/s/GPU,相比 0.5.5 的 508 提升 1.79 倍,硬件和方案完全相同。在匹配并发数下,两个版本的交互性几乎一致。各并发数下 TPOT 在四舍五入范围内不变。0.5.6 以相同的每用户 token 速率服务了更多用户。
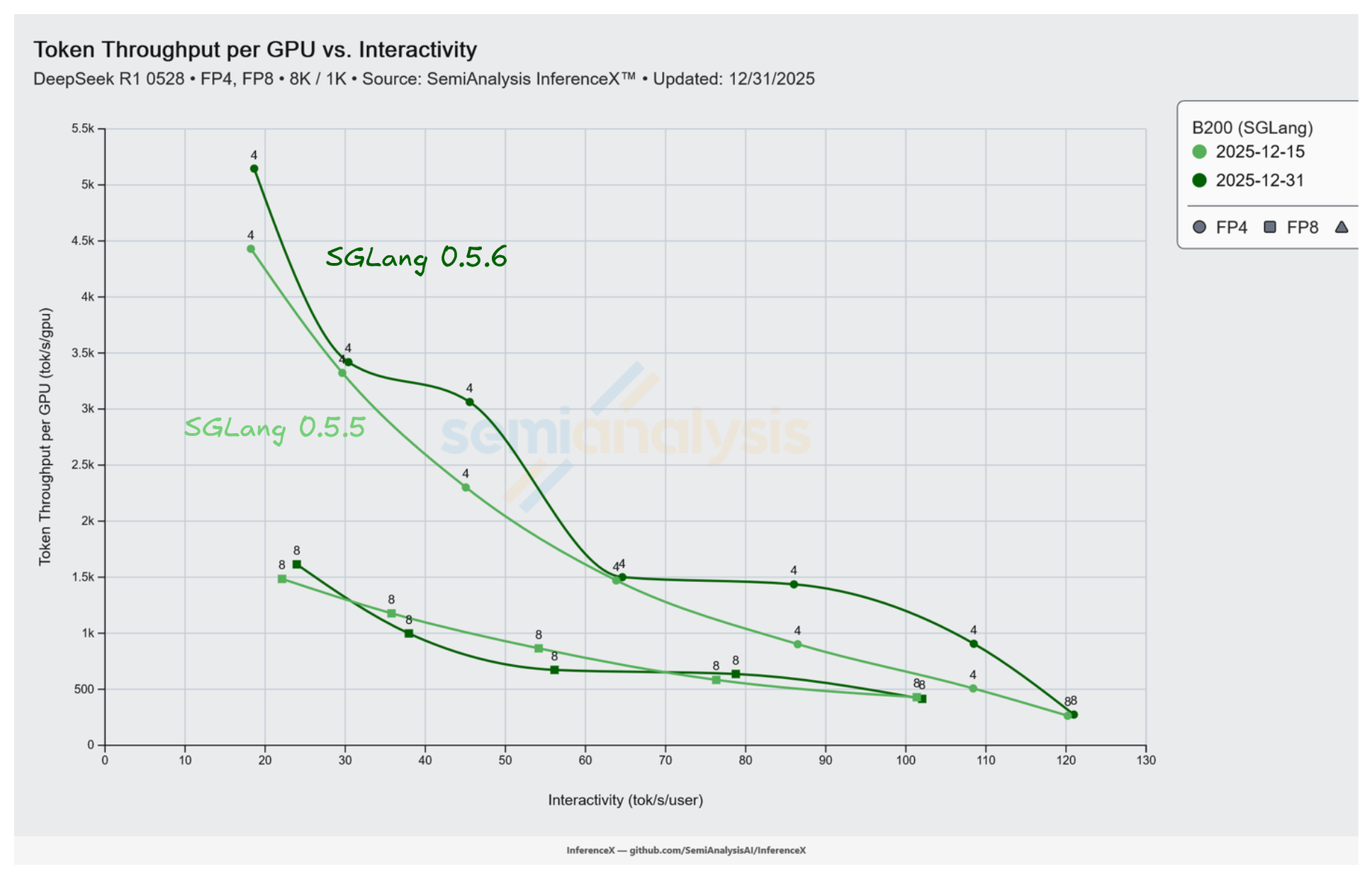
实时图表,预筛选为 0.5.5 和 0.5.6 两次测试中 B200 SGLang 上的 DeepSeek R1。
各项优化在曲线上的作用位置
TP 4 / EP 4 配置下 DeepSeek R1 NVFP4 的解码有固定的每步开销。内核启动、Python 调度器处理和计算图构建是主要贡献项,与注意力和 MoE GEMM 计算并列。在并发数 4 时,GEMM 规模较小,固定开销占步骤耗时的比例显著。减少固定开销直接加速了每步执行,这就是最大提升比(并发数 4 为 1.79 倍,并发数 8 为 1.59 倍)出现在低并发的原因。分段 CUDA graph 和 JIT 内核是相关的发布项。
在并发数 128 时,KV 缓存较大,注意力计算是每步的主要开销。重构后的 MHA 和 MLA KV 缓存对 FP4 的支持以及重新启用的 FlashInfer TRTLLM GEN MHA 路径在并发数 128 下产生了 1.16 倍的提升,尽管调度器开销的减少在此并发量级已趋于平坦。在中等并发数(16、32、64)下,两种效果均不占主导,吞吐量提升较小且不太稳定(1.02 倍、1.33 倍、1.03 倍)。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。