B200 running SGLang 0.5.6 on DeepSeek R1 NVFP4 reaches 907 tok/s/GPU at concurrency 4 on the 8k/1k workload, up 1.79x from 508 tok/s/GPU on 0.5.5. Both runs use the same 16 GPU pool at TP 4 / EP 4. The only change was the Docker image being updated from lmsysorg/sglang:v0.5.5-cu129-amd64 to lmsysorg/sglang:v0.5.6-cu129-amd64.
SGLang 0.5.6 shipped on 2025-12-03 and the InferenceX benchmark caught the full effect 28 days later, on 2025-12-31, the same day the image bump landed. This is the reason we built InferenceX's automated benchmark loop, to catch software-driven performance changes on the same hardware as soon as they land.
The performance gain is largest at low concurrency. At concurrency 4 and 8 the decode loop spends a meaningful fraction of each step in Python scheduler and kernel dispatch code rather than in matmuls, so the 0.5.6 scheduler and graph changes apply most directly. At high concurrency the tensor cores are near saturation and the smaller throughput gain (1.03x at conc 64, 1.16x at conc 128) comes from the refactored attention kernel path.
What Shipped in SGLang 0.5.6
SGLang 0.5.6 shipped on 2025-12-03. Three release items apply to the low-concurrency throughput gains. Piecewise CUDA graph support was extended to DeepSeek V3 and the MLA attention path, reducing the per-step Python cost of constructing and replaying graphs. The event loop was unified across PD-disaggregated, overlap, and DP-attention serving modes, reducing inner-loop overhead. JIT kernels were introduced, reducing startup cost and allowing kernel compilation to specialize for shapes seen at run time.
Three other 0.5.6 changes affect the attention kernel path. MHA and MLA KV caches were refactored to support FP4. The FlashInfer TRTLLM GEN MHA path was re-enabled. FlashInfer bumped to 0.5.2. These matter at high concurrency where the KV cache is large and attention is the dominant cost. The 1.16x at concurrency 128 comes from this path.
The Numbers
All rows are DeepSeek R1 NVFP4 at ISL 8192 / OSL 1024 on InferenceX. 0.5.5 data is from the 2025-12-15 run on the image set by InferenceX PR #204, which moved the B200 SGLang configs from v0.5.3rc1-cu129-b200 to v0.5.5-cu129-amd64 on 2025-11-10. 0.5.6 data is from the 2025-12-31 run, triggered by InferenceX PR #276 which bumped the Docker image to v0.5.6-cu129-amd64 with no other configuration change.
B200 SGLang, DeepSeek R1 NVFP4, TP 4 / EP 4 decode, 16 GPU non-disaggregated pool. The recipe follows the SGLang DeepSeek V3/R1 deployment guide.
| Version | Conc | tok/s/GPU | TPOT (ms) | tok/s/user | Gain |
|---|---|---|---|---|---|
| 0.5.5 | 4 | 508 | 9.2 | 108.4 | baseline |
| 0.5.5 | 8 | 903 | 11.6 | 86.5 | baseline |
| 0.5.5 | 16 | 1,471 | 15.7 | 63.8 | baseline |
| 0.5.5 | 32 | 2,302 | 22.2 | 45.1 | baseline |
| 0.5.5 | 64 | 3,323 | 33.7 | 29.6 | baseline |
| 0.5.5 | 128 | 4,430 | 54.9 | 18.2 | baseline |
| 0.5.6 | 4 | 907 | 9.2 | 108.5 | 1.79x |
| 0.5.6 | 8 | 1,437 | 11.6 | 86.0 | 1.59x |
| 0.5.6 | 16 | 1,500 | 15.5 | 64.6 | 1.02x |
| 0.5.6 | 32 | 3,063 | 22.0 | 45.6 | 1.33x |
| 0.5.6 | 64 | 3,419 | 32.9 | 30.4 | 1.03x |
| 0.5.6 | 128 | 5,145 | 53.7 | 18.6 | 1.16x |
The bolded row is the headline: 907 tok/s/GPU on 0.5.6 at concurrency 4 vs 508 on 0.5.5, a 1.79x lift on identical hardware and recipe. Interactivity at matched concurrency is almost identical across versions. TPOT at each concurrency is unchanged within rounding. 0.5.6 serves more users per GPU at the same per-user token rate.
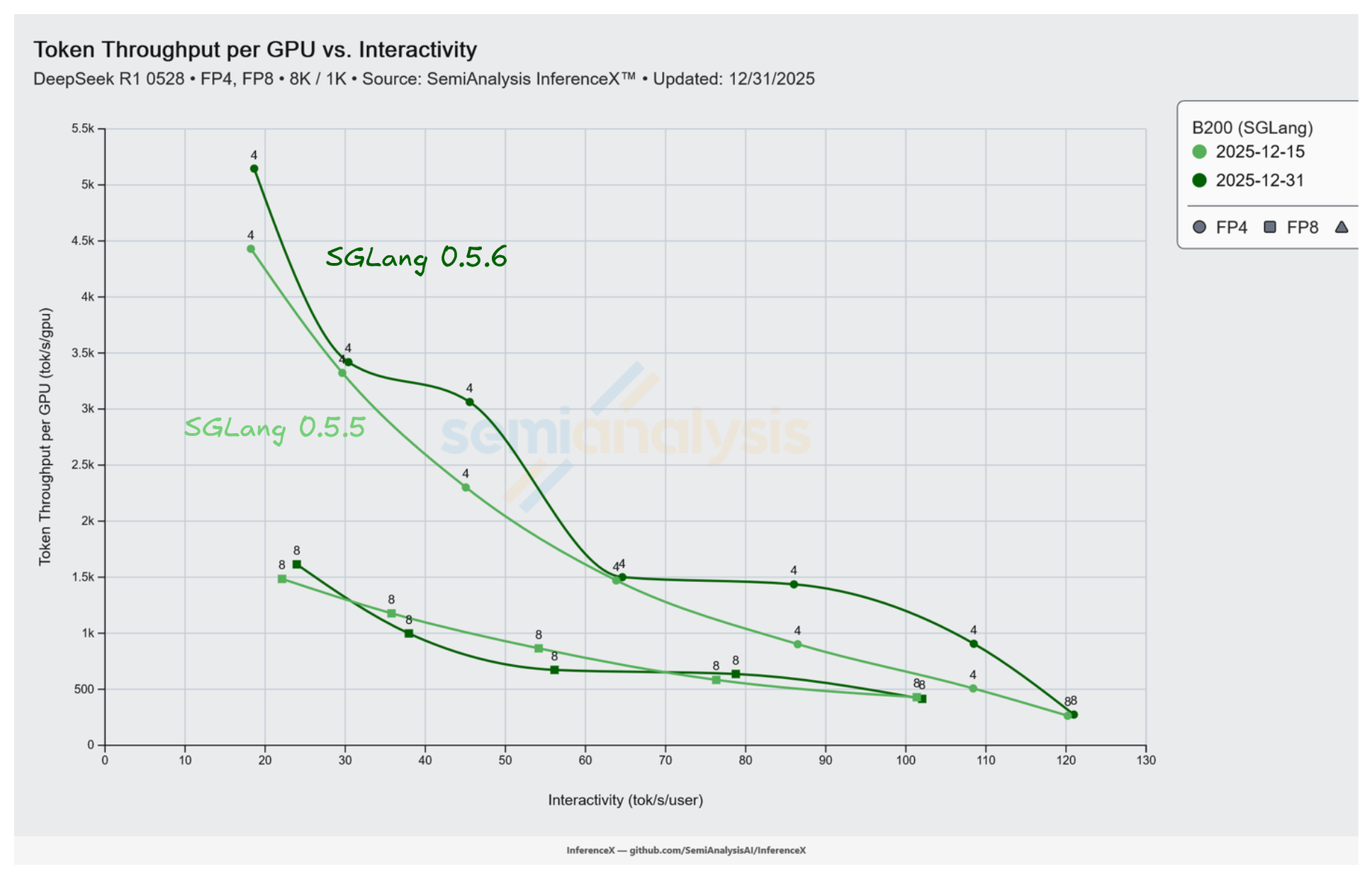
Live chart, pre-filtered to B200 SGLang DeepSeek R1 across the 0.5.5 and 0.5.6 runs.
Where Each Improvement Lands on the Curve
Decode on a TP 4 / EP 4 DeepSeek R1 NVFP4 deployment has a fixed per-step cost. Kernel launches, Python scheduler work, and graph construction are the main contributors alongside attention and MoE GEMMs. At concurrency 4 the GEMMs are small enough that fixed cost is a meaningful slice of the step. Reducing fixed cost speeds up the step directly, which is why the biggest ratios (1.79x at conc 4, 1.59x at conc 8) appear at low concurrency. Piecewise CUDA graphs and JIT kernels are the relevant release items.
At concurrency 128 the KV cache is large and attention is the dominant cost per step. The refactored MHA and MLA KV caches for FP4 and the re-enabled FlashInfer TRTLLM GEN MHA path produce a 1.16x ratio at conc 128 even though the scheduler-overhead reduction has flattened at that point. At middle concurrencies (16, 32, 64) neither effect is dominant and the throughput gain is smaller and less stable (1.02x, 1.33x, 1.03x).
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.