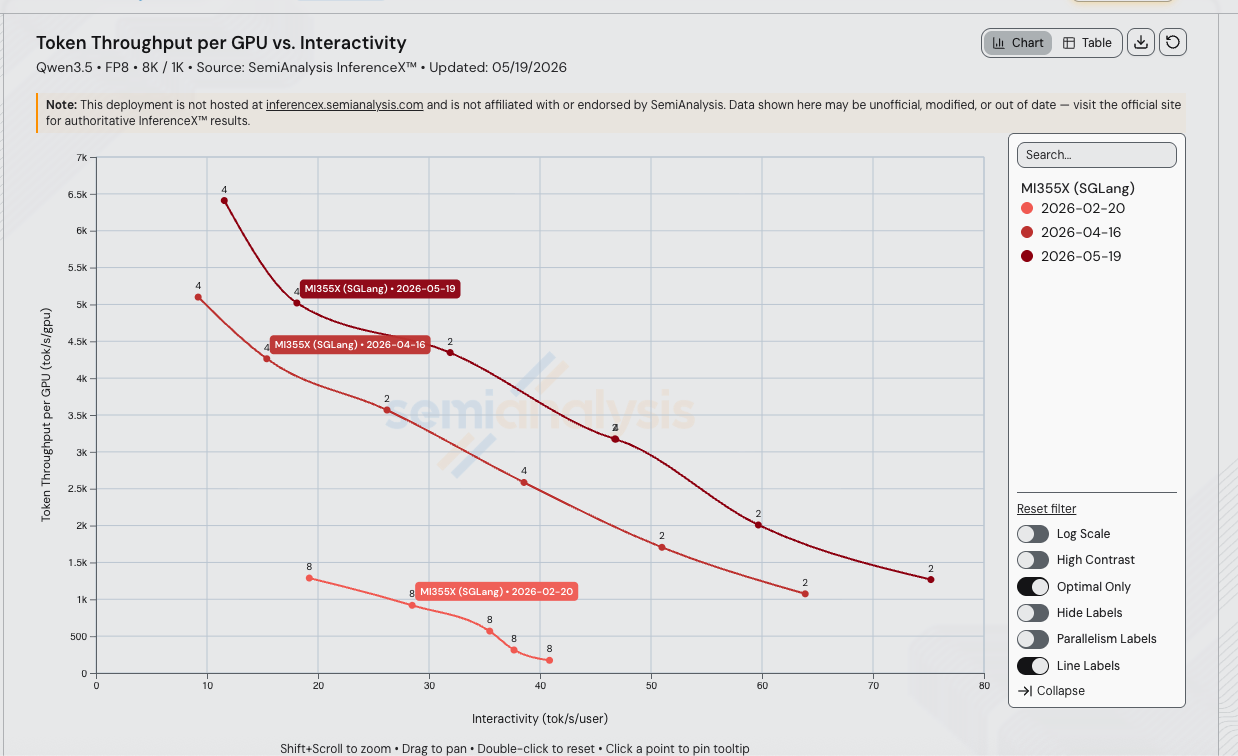
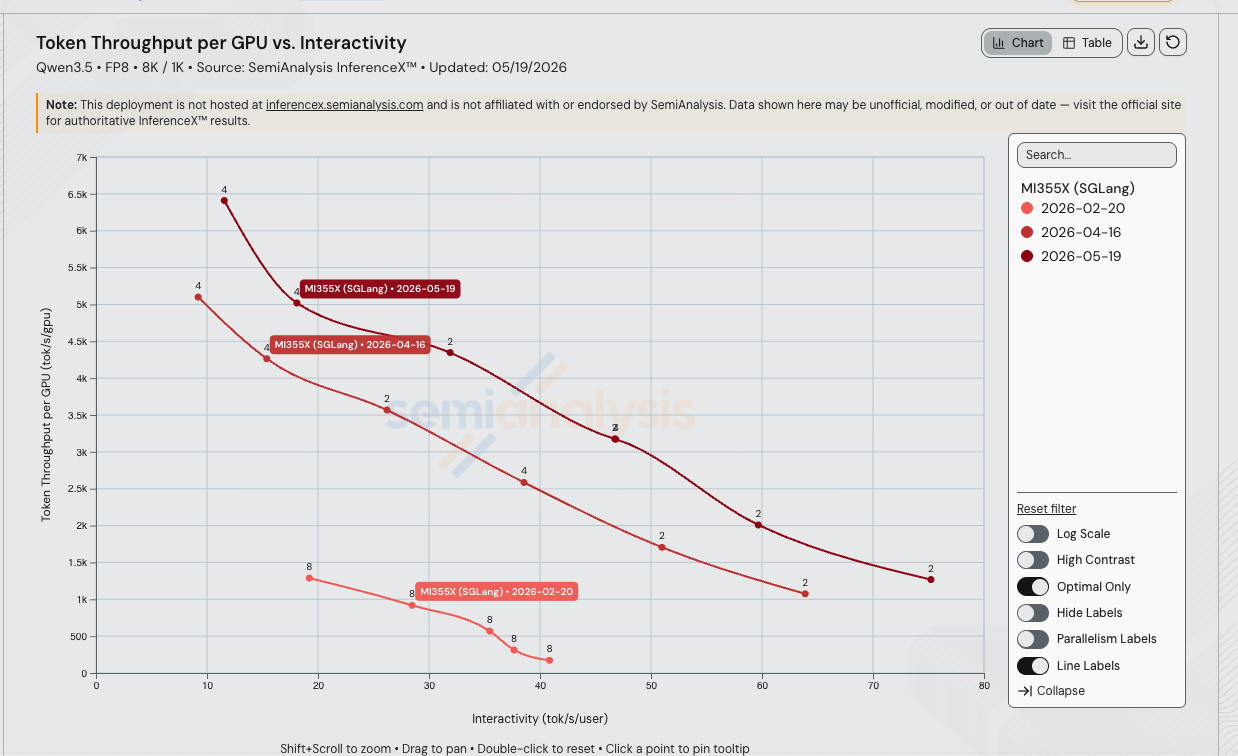
13 weeks after Alibaba's Qwen3.5-397B-A17B release on 2026-02-16, AMD MI355X SGLang FP8 throughput per GPU on the 8k/1k workload has moved up to 19.0x at iso-interactivity at 40 tok/s/user (192 → 3,660 tok/s/GPU between the 2026-02-20 v0.5.8.post1 baseline and the 2026-05-19 v0.5.12 run, on the dashboard's monotone-cubic-Hermite Pareto interpolation). The gains compound across three SGLang releases plus three AITER MoE kernel landings drove most of the move, with another ~1.5x from the May v0.5.10rc0 → v0.5.12 image bump on top.
The story is software-only — same MI355X CDNA4 silicon at $1.48/GPU/hr the whole time. The receipts: sgl-project/sglang#20736, sgl-project/sglang#21188, and sgl-project/sglang#21421, all merged Mar–Apr and all gated on SGLANG_USE_AITER=1. Speed of the upstream-to-benchmark loop is the moat.
Qwen3.5-397B-A17B is Alibaba's MoE flagship, released 2026-02-16 is an 397B total parameters with 17B activated per token across 512 experts (top-K routing), with a hybrid attention stack interleaving Gated DeltaNet and Gated Attention layers. The first InferenceX benchmark ran on MI355X four days after the release.
What Shipped to Make This Happen
Some of the performance optimizations that lead to these massive gains are:
- sgl-project/sglang PR #20736 by zhentaocc (with co-author yichiche), merged 2026-04-15 — fuses the shared expert with routed experts in Qwen2 MoE and Qwen3.5 MoE. When
shared_expert_intermediate_size == moe_intermediate_size, the shared expert is treated as an additional expert (top-K + 1) inside a single AITER MoE dispatch. One fewer kernel launch per MoE layer, fewer HBM round-trips for the shared-expert weights. Reported +4.6% total throughput, −4% TPOT on Qwen3.5 at concurrency 16; FP8 accuracy initially required an AITER split-K fix before being enabled. - sgl-project/sglang PR #21188 by yichiche, merged 2026-03-23 — adds a
forward_hippath toGemmaRMSNormso AMD GPUs use fused RMSNorm kernels (AITERfused_add_rms_norm/rms_norm) instead of the native fallback. The native path was scalar-bound on MI355X; the fused path absorbs the Gemma-styleweight + 1.0offset into the kernel. Reported on 8x MI355X at conc 1, 8k/1k: −23.1% median E2E latency, +30.0% total throughput, −17.0% median TTFT, with GSM8K accuracy rising from 0.943 to 0.955. - sgl-project/sglang PR #21421 by zhentaocc, merged 2026-03-26 — integrates AITER's
fused_topkkernel into SGLang'sfused_topkfor softmax-scored MoE top-K selection. Auto-dispatches toaiter.fused_moe.fused_topkwhen AITER is enabled. Kernel microbenchmarks: ~1.31x to 6.29x faster than the sgl-kernel baseline on Qwen3.5 shapes (E=512, top-K=10), with the largest gains at high token counts. End-to-end bs=64 1k/1k: +1.9% total throughput, GSM8K within ±0.001 of baseline.
The Numbers
All rows are Qwen3.5-397B-A17B FP8 at ISL 8192 / OSL 1024 on a single non-disaggregated MI355X node, measured on InferenceX. Cost per million total tokens is computed as TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6) with MI355X TCO at $1.48/GPU/hr per the SemiAnalysis AI Cloud TCO Model.
Container images per date:
- 2026-02-20:
rocm/sgl-dev:v0.5.8.post1-rocm720-mi35x-20260218 - 2026-04-16:
lmsysorg/sglang-rocm:v0.5.10rc0-rocm720-mi35x-20260414 - 2026-05-19:
lmsysorg/sglang-rocm:v0.5.12-rocm720-mi35x-20260517
2026-02-20, MI355X SGLang FP8, TP=8 on 8 GPUs (baseline):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 171.9 | 40.86 | 24.47 | $2.39 |
| 8 | 312.1 | 37.66 | 26.55 | $1.32 |
| 16 | 568.0 | 35.47 | 28.19 | $0.72 |
| 32 | 917.8 | 28.48 | 35.11 | $0.45 |
| 64 | 1,288.0 | 19.22 | 52.03 | $0.32 |
2026-04-16, MI355X SGLang FP8, TP=2 on 2 GPUs (post-retune + AITER PRs):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,074.3 | 63.89 | 15.65 | $0.38 |
| 8 | 1,704.6 | 50.98 | 19.61 | $0.24 |
| 16 | 2,571.9 | 38.50 | 26.51 | $0.16 |
| 32 | 3,567.8 | 26.22 | 38.15 | $0.12 |
2026-04-16, MI355X SGLang FP8, TP=4 on 4 GPUs (high-throughput arm):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 32 | 2,584.9 | 38.56 | 25.94 | $0.16 |
| 64 | 3,426.6 | 24.84 | 40.25 | $0.12 |
| 128 | 4,263.2 | 15.38 | 65.01 | $0.10 |
| 256 | 5,099.3 | 9.20 | 108.64 | $0.08 |
2026-05-19, MI355X SGLang FP8, TP=2 on 2 GPUs (v0.5.12 bump):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,267.5 | 75.22 | 13.29 | $0.32 |
| 8 | 2,008.1 | 59.67 | 16.76 | $0.20 |
| 16 | 3,175.6 | 46.73 | 21.40 | $0.13 |
| 32 | 4,346.8 | 31.91 | 31.34 | $0.09 |
2026-05-19, MI355X SGLang FP8, TP=4 on 4 GPUs (v0.5.12 bump):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 32 | 3,171.8 | 46.82 | 21.36 | $0.13 |
| 64 | 4,113.4 | 29.83 | 33.53 | $0.10 |
| 128 | 5,019.6 | 18.09 | 55.27 | $0.08 |
| 256 | 6,409.1 | 11.56 | 86.53 | $0.06 |
Iso-Interactivity Throughput Comparison
Each date is interpolated on its Pareto frontier (the higher of TP=2 and TP=4 throughput at each interactivity for the April and May runs; TP=8 only for the Feb baseline). Ratios are throughput-per-GPU at matched tok/s/user:
| Interactivity (tok/s/user) | Feb v0.5.8 tok/s/GPU | Apr v0.5.10rc0 tok/s/GPU | May v0.5.12 tok/s/GPU | May / Feb | May / Apr |
|---|---|---|---|---|---|
| 20 | 1,259 | 3,906 | 4,861 | 3.86x | 1.24x |
| 30 | 859 | 3,278 | 4,449 | 5.18x | 1.36x |
| 35 | 612 | 2,867 | 4,114 | 6.72x | 1.44x |
| 40 | 192 | 2,476 | 3,660 | 19.0x | 1.48x |
| 50 | unreachable | 1,765 | 2,959 | ∞ | 1.68x |
| 60 | unreachable | 1,244 | 1,985 | ∞ | 1.60x |
The 19x peak at 40 tok/s/user is partly a regime extension — the Feb TP=8 recipe had a 24.5 ms TPOT floor at conc 4 (40.86 tok/s/user) and couldn't run cheaper than that on this workload, so the comparison band tops out where the old recipe was already in collapse. By 50 tok/s/user the v0.5.8 curve doesn't exist at all; by 75 tok/s/user only the v0.5.12 curve still has a point. The May v0.5.12 image alone adds 1.44x to 1.68x on top of the April baseline across the entire shared band — a clean version-bump win.
Live chart, pre-filtered to MI355X SGLang Qwen3.5 FP8 across all three runs.
What's Next for MI355X on Qwen3.5
- Disaggregated Serving. Qwen3.5's 512-expert pool is exactly the regime where a disaggregated prefill/decode split should shine. There is no MI355X Qwen3.5 disagg recipe yet, and AMD has still not shipped disagg for Qwen3.5.
Acknowledgments
This 3-month curve move is the work of zhentaocc (Todd Chen) and yichiche (Jacky Cheng) at AMD, who authored all three upstream SGLang PRs, with HaiShaw reviewing and merging. Speed of the upstream-to-benchmark loop is the moat.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.