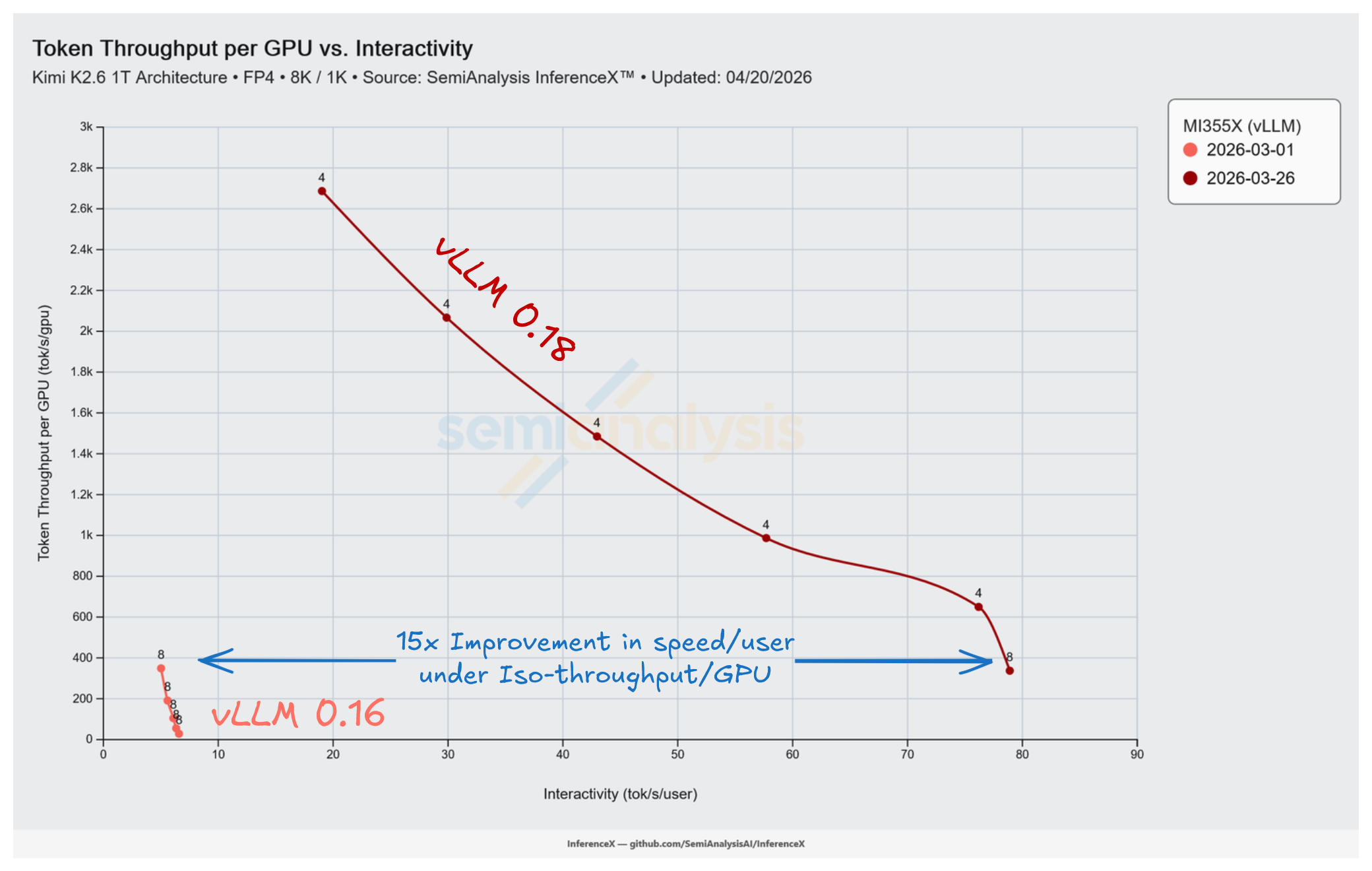
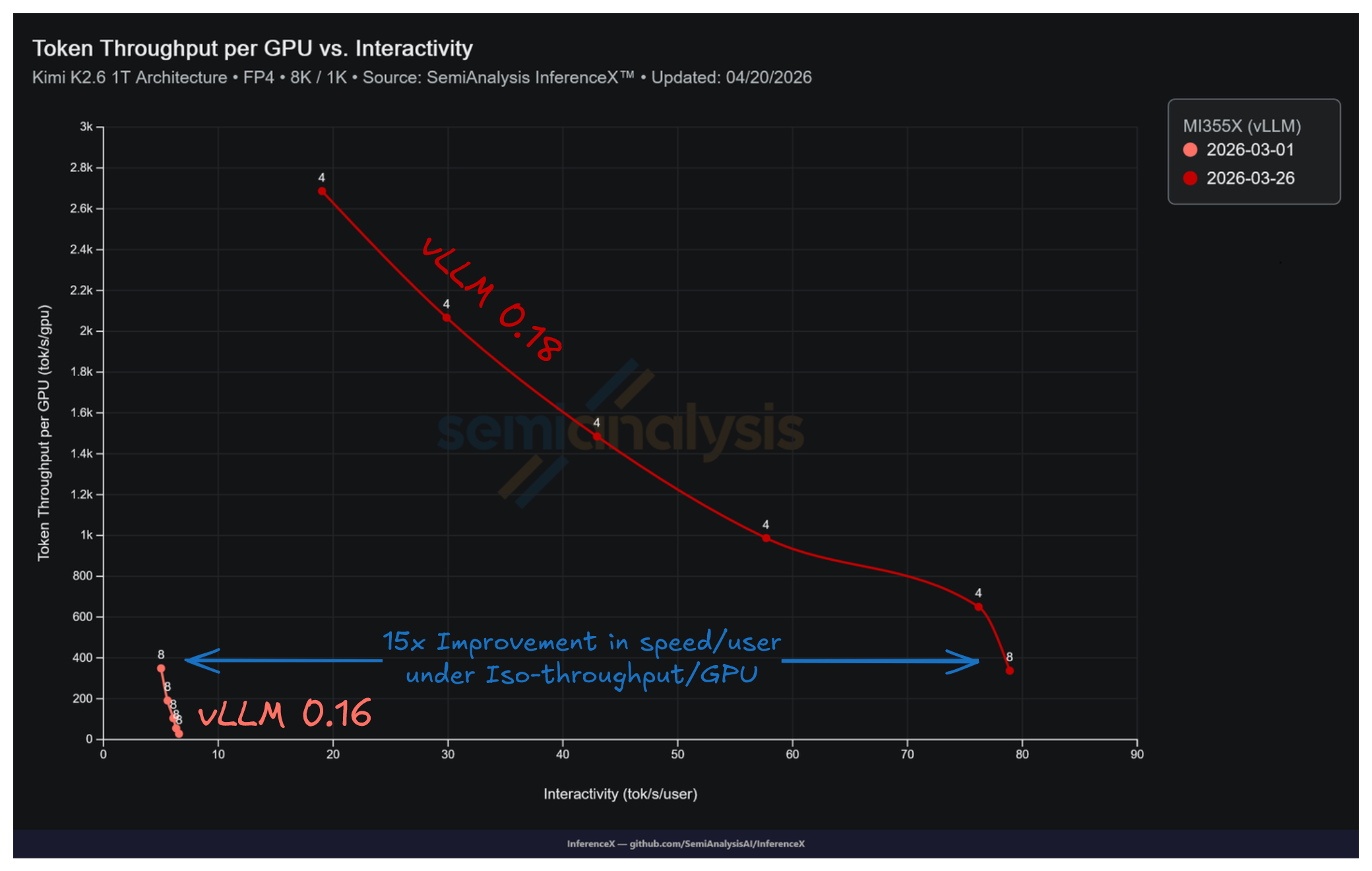
仅凭一个 vLLM PR,AMD MI355X 上 Kimi K2.5 MXFP4 在 8k/1k 工作负载上同等并发下的性能就从 6.6 tok/s/user 跃升至 78.9 tok/s/user。同一个 PR 还带来了其他惊人的性能增益,包括低批次下交互性提升 12.0 倍、峰值吞吐量提升 7.7 倍,以及等吞吐量下最高 15 倍的交互性提升。
然而,他们最令人印象深刻的成就在于推动曲线改变的速度。vLLM PR #35850 于 3 月 6 日合入并随 vLLM 0.18 发布,到 3 月 26 日 InferenceX 的基准测试流水线就通过 InferenceX PR #936(该 PR 启用了 MI355X Kimi K2.5 配方上的 AITER、专家并行及 vLLM 0.18.0 升级)捕获了完整效果——距离我们 3 月 1 日的 vLLM 0.16.0 基线仅 25 天。MI355X Kimi K2.5 MXFP4 上的每一个工作点都从一个几乎不可用、只有单点延迟下限的状态,被重写为一条可达 78.9 tok/s/user 低批次交互性和 2,687 tok/s/GPU 峰值吞吐量的完整 Pareto 前沿。这正是我们构建 InferenceX 自动化基准测试的原因——高效地捕获并报告此类变化。
我们在 InferenceXv2 中对 AMD Kimi K2.5 推理提出的最持续的批评之一是可组合性。MI355X 在 CDNA4 上的硅片能力在 tensor-core 层面与 B200 有竞争力,但 AMD 的 ROCm 和 vLLM 路径并不总能释放该能力。这在推理配方仍在成熟中的新一代前沿 MoE 模型上尤为明显。
PR #35850 修复了什么
Kimi K2.5 是一个 1T 参数的 MoE 模型,使用多头潜在注意力(MLA,Multi-head Latent Attention),这是 DeepSeek 在 V2 中引入的注意力变体。MLA 通过将 key 和 value 投影到共享潜空间来减少 KV 缓存占用。由此产生的每 rank 注意力头数取决于 tensor-parallel rank 数:TP=4 时 Kimi K2.5 为 16 头/rank,TP=8 时为 8 头/rank。
AITER(AMD 面向 ROCm 的手动调优 AI Tensor Engine)在 CDNA4 上有优化的 MLA 内核路径,但 vLLM 的集成代码在 TP=8 时未能正确分发到该路径。AITER 的 MLA 解码内核围绕 gqa_ratio=16 的 ASM 路径构建,原生接受 16 头/rank(TP=4)和 128 头/rank,并拒绝中间值。在 Kimi K2.5 TP=8 的 8 头/rank 下,分发因头数断言失败而回退到 vLLM 的参考 TritonMLA 路径,该路径在 MXFP4 下比 AITER 慢很多。
PR #35850 在单次提交中完成了三项修改:通过头重复技巧(将 8 头填充到 16 头以使用现有的 gqa_ratio=16 ASM 内核)支持 num_heads < 16 的 AITER MLA——这为 Kimi K2.5 TP=8 和 Kimi-Linear TP=16 解锁了性能;放宽了头数断言以接受 4、8 或 [16, 128] 内任意 16 的倍数;以及当使用 FP8 KV 缓存时自动从 TritonMLA 回退到 AITER MLA(TritonMLA 对 FP8 KV 抛出 NotImplementedError)。三项修改均随 vLLM 0.18 发布。此外,AMD 对 MoE 专家形态的 MXFP4 GEMM 自动调优也与该 PR 一起贡献了观测到的吞吐量提升。
解读曲线
InferenceX 的基准测试结果在变化一落地就捕获到了:
| 日期 | Conc | Decode TP | tok/s/GPU | TPOT | tok/s/user | 同并发增益 |
|---|---|---|---|---|---|---|
| 3 月 1 日 | 4 | 8 | 28.7 | 152 ms | 6.6 | (基线) |
| 3 月 1 日 | 8 | 8 | 55.0 | 158 ms | 6.3 | (基线) |
| 3 月 1 日 | 16 | 8 | 104.8 | 164 ms | 6.1 | (基线) |
| 3 月 1 日 | 32 | 8 | 191.2 | 179 ms | 5.6 | (基线) |
| 3 月 1 日 | 64 | 8 | 348.5 | 199 ms | 5.0 | (基线) |
| 3 月 26 日 | 4 | 8 | 337 | 13 ms | 78.9 | 12.0x |
| 3 月 26 日 | 8 | 8 | 521 | 16 ms | 60.8 | 9.7x |
| 3 月 26 日 | 16 | 8 | 870 | 20 ms | 50.5 | 8.3x |
| 3 月 26 日 | 32 | 8 | 1,255 | 27 ms | 36.4 | 6.5x |
| 3 月 26 日 | 64 | 8 | 1,647 | 43 ms | 23.3 | 4.7x |
两个日期均使用 TP=8 以进行等条件对比。延迟下限从 152–199 ms 崩塌至 13–43 ms,覆盖整个批次曲线。
对于峰值吞吐量,修复后的最优配方切换到 TP=4,以少量低批次交互性为代价换取更高的每 GPU token 数:
| 日期 | Conc | TP | tok/s/GPU | TPOT | tok/s/user |
|---|---|---|---|---|---|
| 3 月 26 日 | 4 | 4 | 650 | 13 ms | 76.2 |
| 3 月 26 日 | 64 | 4 | 2,687 | 53 ms | 19.0 |
等吞吐量对比:15 倍提升之所在
上表中的 12.0 倍增益是在相同批大小下对比两个版本。更有价值的对比是固定每 GPU 吞吐量,考察每位用户的响应速度提升了多少。在 8k/1k 下沿两条 TP=8 曲线在匹配 tok/s/GPU 水平上进行插值:
| 等吞吐量 (tok/s/GPU) | v0.16 交互性 (tok/s/user) | v0.18 交互性 (tok/s/user) | 交互性增益 |
|---|---|---|---|
| 337 | 5.1(插值,约并发 62) | 78.9(实测,并发 4) | 15.6x |
| 380 | 4.9(外推) | 74.7(插值,约并发 5) | 15.2x |
"最高 15 倍"的标题出现在 337 tok/s/GPU 处,v0.16 破损的延迟下限(152–199 ms TPOT,与批大小无关)与 v0.18 在并发 4 下 13 ms 的正常下限在此交汇。在该工作点上,vLLM v0.18 已能在 Kimi K2.5 推理上实现接近实时语音的延迟。
您可以在此处找到该图表的在线版本,已预筛选为 3 月 1 日到 3 月 26 日间 MI355X vLLM 上的 Kimi K2.5 数据。
速度即护城河
修复后,MI355X Kimi K2.5 推理在 8k/1k MXFP4 上峰值达到 2,687 tok/s/GPU,约为 B200 单节点 vLLM FP4 4,021 tok/s/GPU 的 67%。在超大规模云厂商和新兴云服务商租用 Instinct MI355X 的较低每 GPU TCO 下,确实存在 MI355X 每百万 token 更便宜的工作点。然而,机架级分离式推理方面的差距仍未弥合:在该工作负载上 MI355X 落后 GB200 NVL72 Dynamo vLLM 和 TRT-LLM 4.7x–5.3x。大多数 MI355X 配置仅限单节点,限制在 4 或 8 GPU,没有分离式预填充/解码拆分,没有跨机架级互联的宽专家并行。
AMD 已经展示了其能够在自有技术栈上交付生产级分离式推理的能力。MI355X DeepSeek R1 结果使用了 mori-sglang 配合分离式预填充/解码、MXFP4 和 MXFP8,含和不含 MTP 投机解码两种模式。我们期待尽快在 Kimi K2.5 上看到同样的方案。
而这正是我们基准测试所展示的更新节奏为何如此重要。如果在 3 月 1 日做一次时间点 MI355X vs B200 对比,结论会是 MI355X 落后 10 倍且几乎不可用。然而,仅仅 25 天后的数据证明 MI355X 已进入 B200 单节点的射程之内。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。