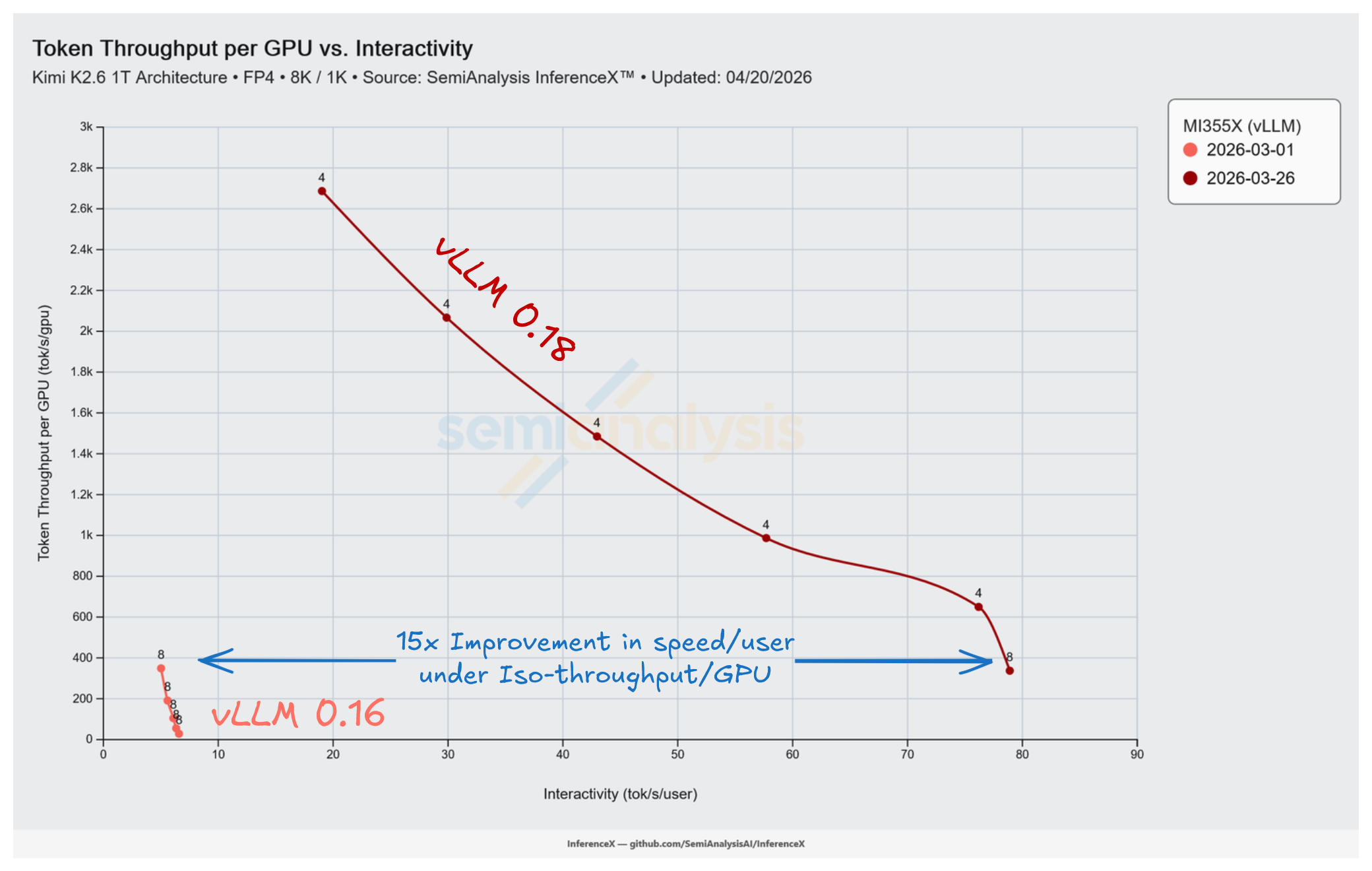
It took a single vLLM PR to move AMD MI355X Kimi K2.5 MXFP4's performance from 6.6 to 78.9 tok/s/user at matched concurrency on the 8k/1k workload. That same PR also provided other incredible performance gains including 12.0x interactivity at low batch, 7.7x peak throughput, and up to 15x at iso-throughput.
However, their most impressive achievement was how fast they were able to move the curve. vLLM PR #35850 merged on March 6 and shipped in vLLM 0.18, and by March 26 the InferenceX benchmark loop had caught the full effect via InferenceX PR #936 (which enabled AITER, expert parallel, and the vLLM 0.18.0 upgrade on the MI355X Kimi K2.5 recipe), 25 days after our vLLM 0.16.0 Mar 1 baseline. Every operating point on MI355X Kimi K2.5 MXFP4 was rewritten from a barely usable option with a single-point latency floor to a proper Pareto frontier reaching 78.9 tok/s/user at low batch and 2,687 tok/s/GPU at peak throughput. This is the exact reason we built the InferenceX automated benchmark. To efficiently catch and report on changes like this as soon as they land.
One of the most consistent criticisms we've leveled at AMD Kimi K2.5 inference through InferenceXv2 is composability. MI355X silicon on CDNA4 is competitive with B200 at the tensor-core level, but AMD's ROCm and vLLM path does not always expose that capability. This is particularly visible on newer frontier MoE models where the inference performance recipes are still maturing.
What PR #35850 Fixed
Kimi K2.5 is a 1T-parameter MoE that uses Multi-head Latent Attention (MLA), the attention variant DeepSeek introduced in V2. MLA reduces KV-cache memory by projecting keys and values into a shared latent space. The resulting attention heads-per-rank depends on tensor-parallel rank: at TP=4, Kimi K2.5 hits 16 heads/rank, and at TP=8 it hits 8 heads/rank.
AITER, AMD's hand-tuned AI Tensor Engine for ROCm, has an optimized MLA kernel path on CDNA4, but the vLLM integration was not dispatching to it at TP=8. AITER's MLA decode kernel is built around a gqa_ratio=16 ASM path that natively accepts 16 heads/rank (TP=4) and 128 heads/rank, and rejects intermediate values. At TP=8 on Kimi K2.5 with 8 heads/rank, the dispatch failed the head-count assertion and fell through to vLLM's reference TritonMLA path, which on MXFP4 runs materially slower than AITER.
PR #35850 landed three changes in a single commit: AITER MLA support for num_heads < 16 via a head-repeat trick (padding 8 heads to 16 so the existing gqa_ratio=16 ASM kernel works, which unlocks TP=8 on Kimi K2.5 and Kimi-Linear at TP=16), a relaxed head-count assertion accepting 4, 8, or any multiple of 16 in [16, 128], and auto-fallback from TritonMLA to AITER MLA when FP8 KV cache is used (TritonMLA raises NotImplementedError on FP8 KV). All three shipped in vLLM 0.18. Separately, AMD's ongoing MXFP4 GEMM autotuning on the MoE expert shapes contributed alongside this PR to the observed throughput delta.
Reading the Curve
The InferenceX's benchmark results caught the change as soon as it landed:
| Date | Conc | Decode TP | tok/s/GPU | TPOT | tok/s/user | Gain at matched conc |
|---|---|---|---|---|---|---|
| Mar 1 | 4 | 8 | 28.7 | 152 ms | 6.6 | (baseline) |
| Mar 1 | 8 | 8 | 55.0 | 158 ms | 6.3 | (baseline) |
| Mar 1 | 16 | 8 | 104.8 | 164 ms | 6.1 | (baseline) |
| Mar 1 | 32 | 8 | 191.2 | 179 ms | 5.6 | (baseline) |
| Mar 1 | 64 | 8 | 348.5 | 199 ms | 5.0 | (baseline) |
| Mar 26 | 4 | 8 | 337 | 13 ms | 78.9 | 12.0x |
| Mar 26 | 8 | 8 | 521 | 16 ms | 60.8 | 9.7x |
| Mar 26 | 16 | 8 | 870 | 20 ms | 50.5 | 8.3x |
| Mar 26 | 32 | 8 | 1,255 | 27 ms | 36.4 | 6.5x |
| Mar 26 | 64 | 8 | 1,647 | 43 ms | 23.3 | 4.7x |
TP=8 at both dates for the apples-to-apples comparison. The latency floor collapsed from 152-199 ms to 13-43 ms across the batch curve.
For peak throughput, the winning post-fix recipe shifted to TP=4, which trades a small amount of low-batch interactivity for much higher tokens per GPU numbers:
| Date | Conc | TP | tok/s/GPU | TPOT | tok/s/user |
|---|---|---|---|---|---|
| Mar 26 | 4 | 4 | 650 | 13 ms | 76.2 |
| Mar 26 | 64 | 4 | 2,687 | 53 ms | 19.0 |
Iso-Throughput: Where the 15x Lives
The 12.0x gain in the table above compares both versions at the same batch size. The more useful comparison holds throughput per GPU fixed instead, and asks how much faster each user's response comes back. Interpolating both TP=8 curves on 8k/1k at matched tok/s/GPU levels:
| Iso-throughput (tok/s/GPU) | v0.16 interactivity (tok/s/user) | v0.18 interactivity (tok/s/user) | Interactivity gain |
|---|---|---|---|
| 337 | 5.1 (interp, conc ~62) | 78.9 (measured, conc 4) | 15.6x |
| 380 | 4.9 (extrap) | 74.7 (interp, conc ~5) | 15.2x |
The "up to 15x" headline sits at 337 tok/s/GPU, where v0.16's broken latency floor (152-199 ms TPOT regardless of batch) meets v0.18's proper floor of 13 ms at conc 4. At this operating point vLLM v0.18 is now able to run at near real-time speech latency on Kimi K2.5 inference.
You can find the live version of this chart here pre-filtered to Kimi K2.5 on MI355X vLLM across Mar 1 to Mar 26.
Speed Is the Moat
Post-fix, MI355X Kimi K2.5 inference peaks at 2,687 tok/s/GPU on 8k/1k MXFP4, roughly 67% of B200 single-node vLLM FP4 at 4,021 tok/s/GPU. At the lower per-GPU TCO that hyperscalers and neoclouds are renting Instinct MI355X at, there are real operating points where MI355X is the cheaper choice per million tokens. However, the gap that has still not closed for rack-scale disagg: MI355X is 4.7x–5.3x behind GB200 NVL72 Dynamo vLLM and TRT-LLM on this workload. Most MI355X configs are single-node, bounded to 4 or 8 GPUs, no disaggregated prefill/decode split, no wide expert parallelism across a rack-scale fabric.
AMD has already shown it can ship production disagg on its own stack. The MI355X DeepSeek R1 results use mori-sglang with disaggregated prefill/decode, MXFP4 and MXFP8, both with and without MTP speculative decoding. We hope to see the same for Kimi K2.5 soon.
And this is why update cadence showcased by our benchmarks matter so much. A point-in-time MI355X vs B200 comparison run on March 1 would have said MI355X was 10x behind and roughly unusable. However, data from a mere 25 days later proves that MI355X is within striking distance of B200 single-node.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.