引言
InferenceXv2(前身为 InferenceMAX)建立在 InferenceMAXv1 奠定的基础之上。InferenceMAXv1 是我们开源的持续更新推理基准测试,已为 AI 推理性能和经济性评估树立了新的行业标准。InferenceMAXv1 超越了传统静态、时间点式的基准测试,在数百块芯片和主流开源框架上持续运行测试。免费仪表板在此。
我们的基准测试已被广泛复现、验证和/或获得几乎所有主要算力采购方的支持,包括 Google Cloud、Microsoft Azure、Oracle、OpenAI 等众多机构。
InferenceXv2 在此基础上进一步拓展,将覆盖范围扩大到包含大规模 DeepSeek MoE 分离式推理(分离预填充,简称"disagg")配合宽专家并行(wideEP)优化的全部 6 款 NVIDIA 过去 4 年发布的西方市场 GPU SKU,以及 AMD 过去 3 年发布的所有西方市场 GPU SKU——InferenceXv2 在一次完整的基准测试运行中总共使用了近 1000 块前沿 GPU。
在今天的发布中,InferenceXv2 成为首个对 Blackwell Ultra GB300 NVL72 和 B300 进行全帕累托前沿曲线基准测试的测试套件,也是首个第三方 disagg+wideEP 多节点 FP4 和 FP8 MI355X 性能基准测试。在未来的 InferenceX 迭代中,我们将继续重点关注分离式服务配合宽专家并行,因为这正是 OpenAI、Anthropic、xAI、Google Deepmind、DeepSeek 等前沿 AI 实验室以及 TogetherAI、Baseten、Fireworks 等高级 API 服务商在生产环境中实际部署的方案。在本文中,我们还将解析围绕最新 Claude Code Fast mode 功能的系统工程原理和经济学分析。
我们的基准测试完全以 Apache 2.0 协议开源——这意味着我们能够以与 AI 软件生态系统同样快速的步伐推进。如果您喜欢我们的工作并希望给予支持,请在 GitHub 上点个星标!我们还为 ML 社区的所有人提供了免费数据可视化工具 https://inferencex.com,供大家自行探索完整数据集。
我们将第一时间添加 DeepSeekv4 及其他热门中国前沿模型的支持,因为在过去 6 个月中,我们已清理了大量技术债务,现在能够以稳定的基础设施快速推进。今年稍后,我们还将把 TPUv7 Ironwood 和 Trainium3 纳入 InferenceX!如果您想在获得有竞争力的薪酬的同时为我们的使命贡献力量,请在此申请。
关键观察与重点结果
在 FP8 MI355X disagg+wideEP SGLang 配置下,AMD 与 FP8 B200 disagg+wideEP SGLang 相比展现出有竞争力的性价比表现(perf per TCO),但与广泛使用的 Dynamo TRTLLM B200 FP8 相比,TRT 继续展现出碾压级优势。AMD SGLang 分离预填充+wideEP FP8 能够匹配 NVIDIA SGLang 的性能,这是令人振奋的好消息。
我们还发现,在单节点聚合服务场景下,AMD 的 SGLang 在 FP8 上提供了比 NVIDIA SGLang 更好的性价比。同样令人欣慰的是,AMD 已弃用其 vLLM 的二等公民分支,转向更靠近上游、更致力于提供一流体验。 敬请期待我们的"AMD 现状"文章,我们将详细讨论 AMD 进步迅速的领域以及进展迟缓的领域。我们建议 NVIDIA 除了 TRTLLM 引擎外,进一步加大对 SGLang 和 vLLM 生态系统的投入。Jensen 需要为 SGLang 和 vLLM 等开源生态系统调配更多资源与工程师。
在前沿大规模推理服务所采用的最新推理技术(如 disagg 预填充+wideEP+FP4)方面,NVIDIA 的 B200、B300 以及 ASU 级别的机架规模 GB200/GB300 NVL72 在 SGLang 和 TRTLLM 上均实现了碾压级领先。NVIDIA GPU 在能效方面同样占据主导地位,在所有工作负载上,每 token 的全口径预分配能耗(皮焦耳)都低得多。
转向 AMD 方面,我们发现其系统和软件在推理上最大的问题是*可组合性*。也就是说,AMD 的许多推理优化实现单独运行时表现良好,但当多种优化组合使用时,结果并不如预期那般有竞争力。具体而言,分离预填充、wideEP 和 FP4 推理优化的可组合性亟需大幅改进。
虽然仅启用部分 SOTA 推理优化时 AMD 的性能具有竞争力,但当同时启用所有三大主流实验室使用的优化时,AMD 的性能目前无法与 NVIDIA 匹敌。我们强烈建议 AMD 将重心放在不同推理优化的可组合性上。据了解,AMD 将开始在整个软件栈中关注 FP4+分布式推理的软件可组合性。这一工作将在春节后展开,因为他们的大部分 disagg 预填充+wideEP 核心工程师都在中国。
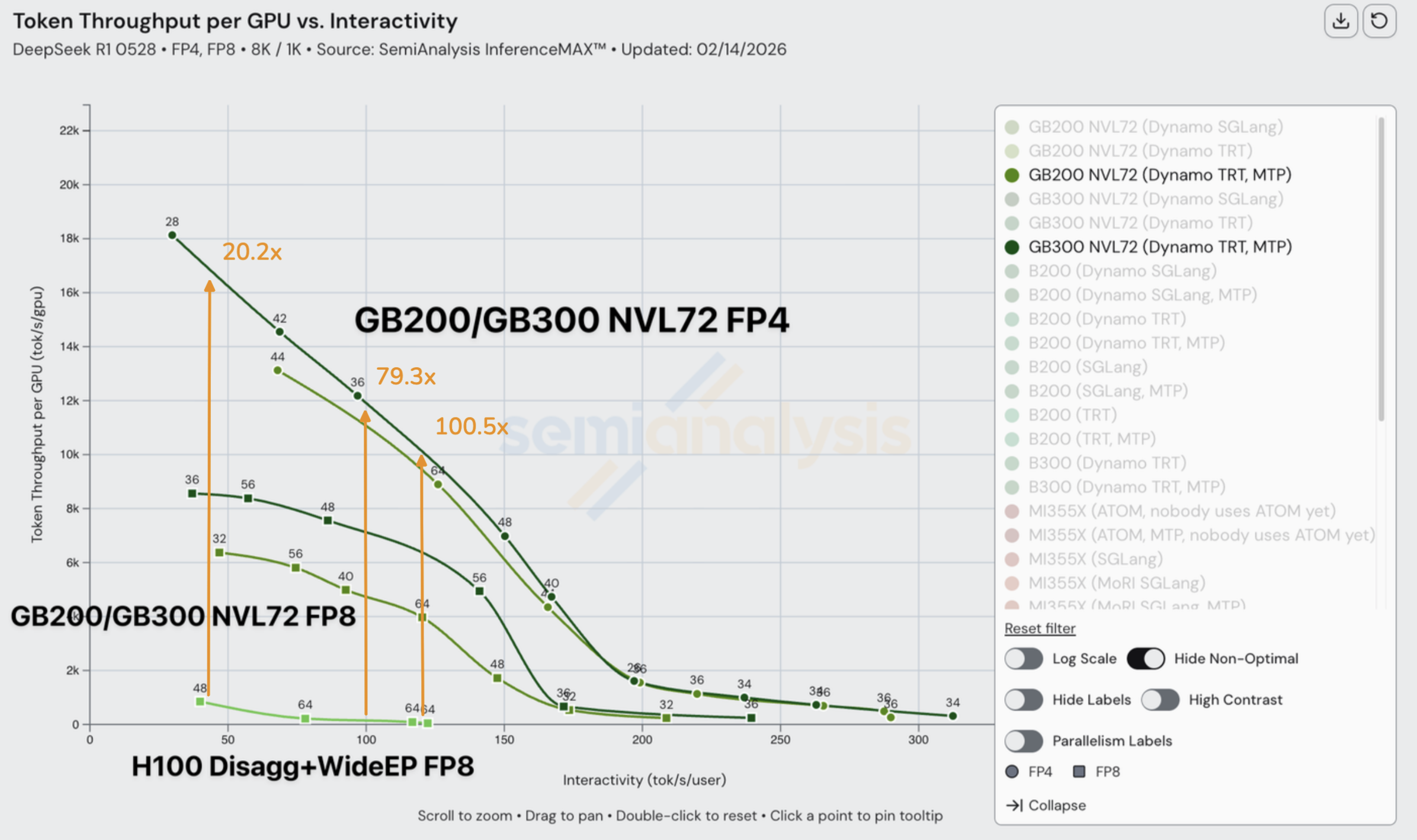
NVIDIA 的 GB300 NVL72 没有令人失望。与强劲的 H100 disagg+wideEP+MTP 基线相比,FP8 vs FP4 最高达到了 100x 的性能提升,FP8 vs FP8 则达到 65x。在 H100 vs GB200 NVL72 的对比中,我们在 75 tok/s/user 下观察到高达 55x 的实际性能差距。机架规模的 Blackwell NVL72 对 Hopper 形成了碾压,让 Hopper 相形见绌。正如 Jensen 在 GTC 2025 上所说的,他是首席营收毁灭者。
在 GTC 2024 上,Jensen 声称 Blackwell 相比 H100 的推理性能将提升高达 30x,Jensen 在 Blackwell 推理性能上做到了低调承诺、超额兑现。这应该能让那些喜欢开"Jensen 数学"玩笑的分析师们暂时消停一段时间。
致谢与 InferenceX™(前身为 InferenceMAX)倡议支持者
我们要感谢 Jensen Huang 和 Ian Buck 对这一开源工作的支持,他们提供了最新的 GB300 NVL72 系统以及代表过去四年所有 GPU SKU 的服务器访问权限。我们要感谢 NVIDIA 团队允许我们在这近 1000 块 GPU 上进行独立基准测试。感谢 Jatin Gangani、Kedar Potdar、Sridhar Ramaswamy、Ishan Dhanani、Sahithi Chigurupati 以及众多其他 NVIDIA 推理工程师帮助验证和优化 Blackwell 与 Hopper 配置。
我们同样感谢 Lisa Su 和 Anush Elangovan 对 InferenceMAX 的支持,感谢他们安排了数十位 AMD 工程师(包括 Chun、Andy、Bill、Ramine、Theresa、Parth 等)为 InferenceMAX 和上游 vLLM/SGLang bug 修复做出贡献,以及在帮助调试和分类 AMD 专有 bug 以优化 AMD 性能方面的积极响应。
我们还要向 SGLang、vLLM 和 TensorRT-LLM 的维护者们致敬,他们构建了世界级的软件栈并将其开源给全世界。您可以在此查看他们关于 InferenceX 的文章:
- SemiAnalysis InferenceMAX: vLLM maintainers & NVIDIA accelerate Blackwell Inference
- GPT-OSS Performance Optimizations: Pushing Pareto Frontier
- SGLang & NVIDIA Accelerating SemiAnalysis InferenceMAX & GB200 Together
InferenceX 倡议还获得了来自 OpenAI、Microsoft、vLLM、Tri Dao、PyTorch Foundation、Oracle 等众多主要算力采购方和 ML 社区知名成员的支持。完整名单请见此处。
重要技术概念入门
在本节中,我们将对一些技术概念进行简要介绍,帮助读者更好地理解后续结果。部分读者可能不需要这些内容,可以直接跳到结果分析部分。我们将在结果分析之后对其中一些主题进行更深入的探讨。
交互性与吞吐量的权衡
LLM 推理的根本权衡在于吞吐量与延迟。交互性(tok/s/user)描述了系统中每个用户接收 token 的速度——它是每输出 token 时间(TPOT)的倒数。吞吐量(tok/s)描述了系统在所有用户之间总共能产出多少 token。可以通过批处理请求来获得更高的总吞吐量,但每个请求分配到的算力会减少,因此完成速度会更慢。这类似于乘坐公交车与跑车的选择。公交车服务众多乘客,但频繁停靠耗费时间,不过成本可以由多位乘客分摊。跑车只能搭载一两位乘客,但几乎不会额外停靠,意味着整体行程更快,只是每位乘客的费用高得多。对于周末去公园的人来说公交车可能更合理,而对于需要快速抵达目的地的名人来说跑车可能更好。没有放之四海而皆准的解决方案。
本文将展示的大多数基准测试结果都是一条曲线。在不同的交互性/延迟水平下分析吞吐量非常重要,而不是仅仅看最大吞吐量(通常只能在单一低交互性水平下达到)。在推理领域,没有万能的用例方案。所需的交互性和吞吐量水平取决于具体用例。例如,实时语音模型需要极低的延迟,以便终端用户能与 LLM 维持自然的"对话",而基础问答聊天机器人则允许更高的延迟。我们将这一判断留给读者,请根据曲线并应用此原则来定位自己的用例落在吞吐量-交互性曲线的哪个位置。
成本/TCO 性能比 vs 交互性/端到端延迟曲线大致与吞吐量 vs 交互性/端到端延迟曲线一致:更多的 token/小时意味着更低的每 token 成本,因为固定的 $/小时成本被分摊到更多产出的 token 上。
预填充和解码阶段
推理包含两个主要阶段:预填充和解码。预填充发生在请求生命周期的第一次前向传播中。由于请求中的所有 token 被并行处理,这一阶段计算密集。该阶段负责为序列"填充" KV 缓存。预填充之后,响应逐 token 生成(即解码)。每次前向传播都从 HBM 加载序列的整个 KV 缓存,而仅为单个 token 执行计算,因此解码是内存(带宽)密集型操作。
当预填充和解码在同一引擎上执行时,预填充会不断打断解码批次,导致整体性能下降。
分离预填充
分离预填充(又称 PD 分离或简称"disagg")是将预填充和解码阶段分离到不同 GPU 池或集群上的做法。这些独立的预填充和解码池可以分别调优和扩展,以匹配工作负载需求。
张量并行、专家并行、数据并行(TP、EP、DP)
TP 允许在小批次下最大化交互性,但必须在每一层执行一次 all-reduce。EP 对专家进行分片,利用 MoE 的稀疏性,缺点是 MoE 层需要执行 all-to-all 集合通信(比 all-reduce 等简单集合通信代价更高),并且在小批次下可能出现负载不均衡。DP 将整个模型(或模型的一部分,如注意力机制)复制到多组 GPU(rank)上,然后在各 rank 之间进行请求负载均衡。DP 最易于扩展,但重复了权重加载,在大规模部署下可能造成浪费。
跟踪随时间的改进
InferenceX 的核心目标之一是可视化性能随时间的改进。虽然新芯片的发布频率约为每年一次(O(年)级别),但软件版本的更新频率约为每周一次(O(周)级别)。我们的目标是持续使用最新最先进的软件改进来更新配方,并对各种配置进行基准测试。
DeepSeek R1
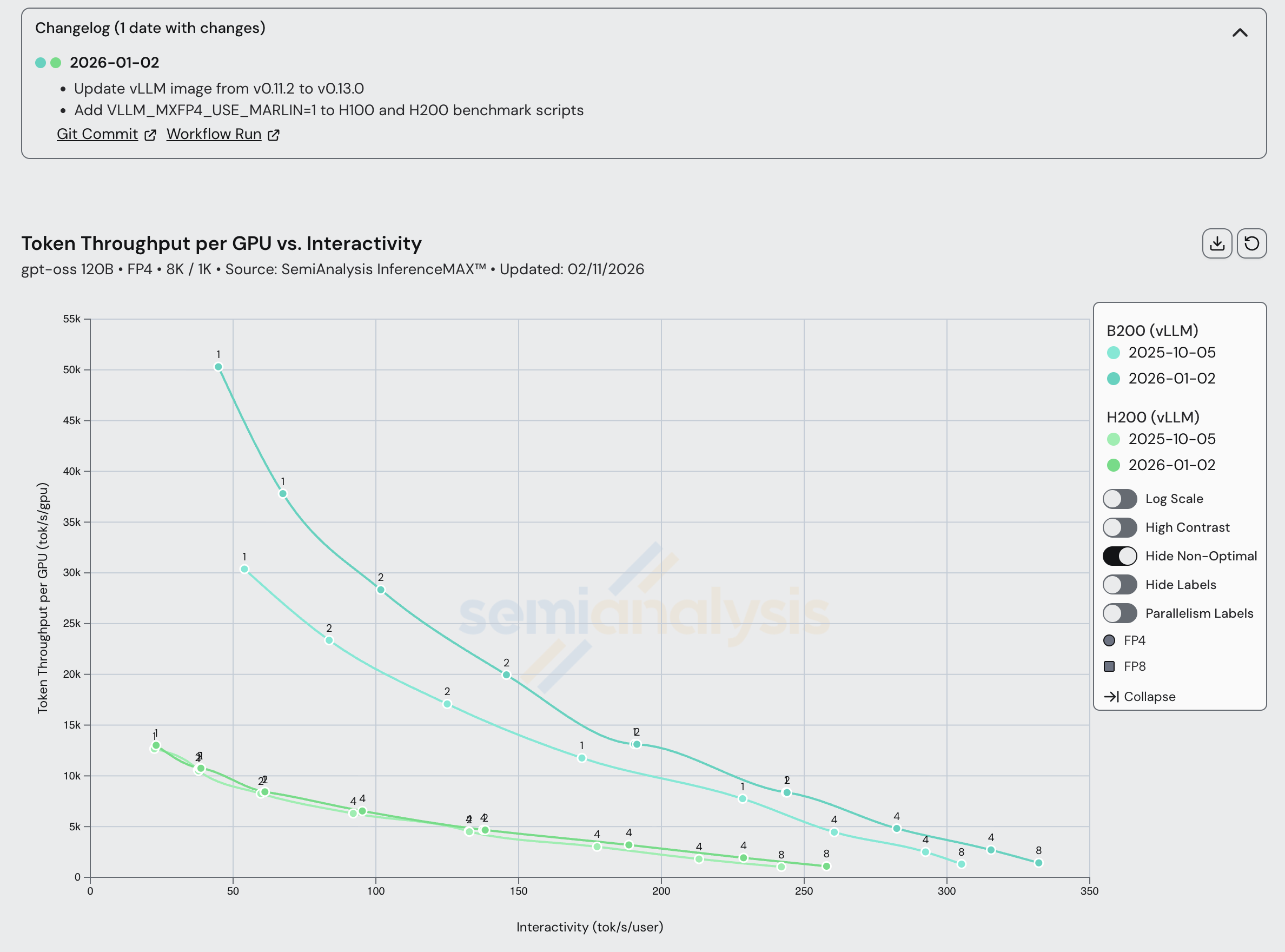
AMD 团队已为所有 SGLang DeepSeek R1 FP4 配置显著提升了性能。在相同的交互性水平下,AMD 在不到 2 个月的时间内几乎将吞吐量翻了一番。此外,我们已推动 AMD 将其分支 SGLang 镜像中的性能优化上推至官方 SGLang 镜像。从 2025 年 12 月到 2026 年 1 月,AMD 的软件性能提升了多达 2x。
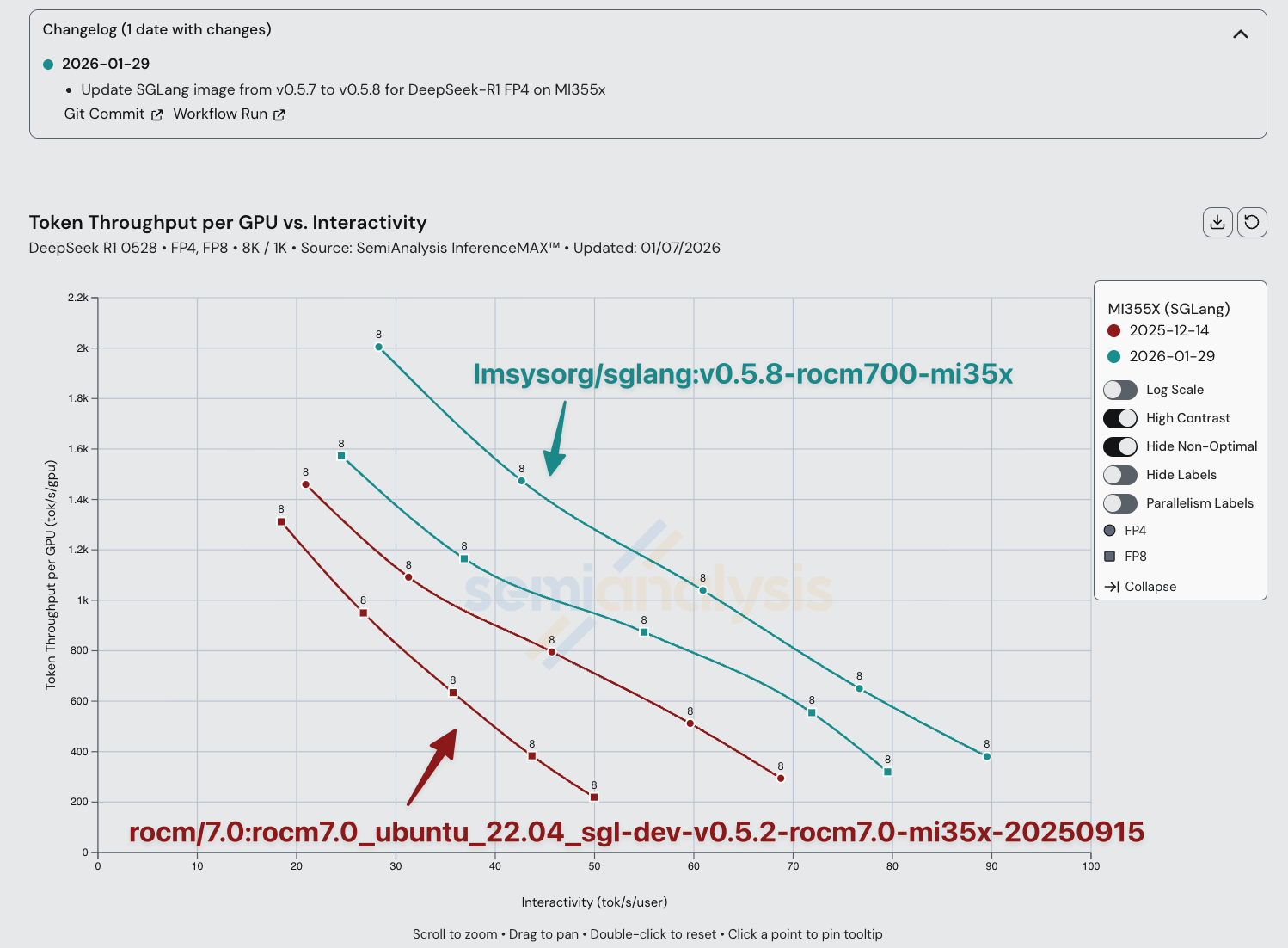
为了更接近一流体验,AMD 需要通过计算资源贡献和代码贡献来增强对 vLLM 和 SGLang 维护者的支持,并安排更多 AMD 审稿人来加速 AMD PR 合入上游的审核流程。

另一方面,NVIDIA 的结果更为稳定,B200 SGLang 在类似时间段内仅有小幅改进。
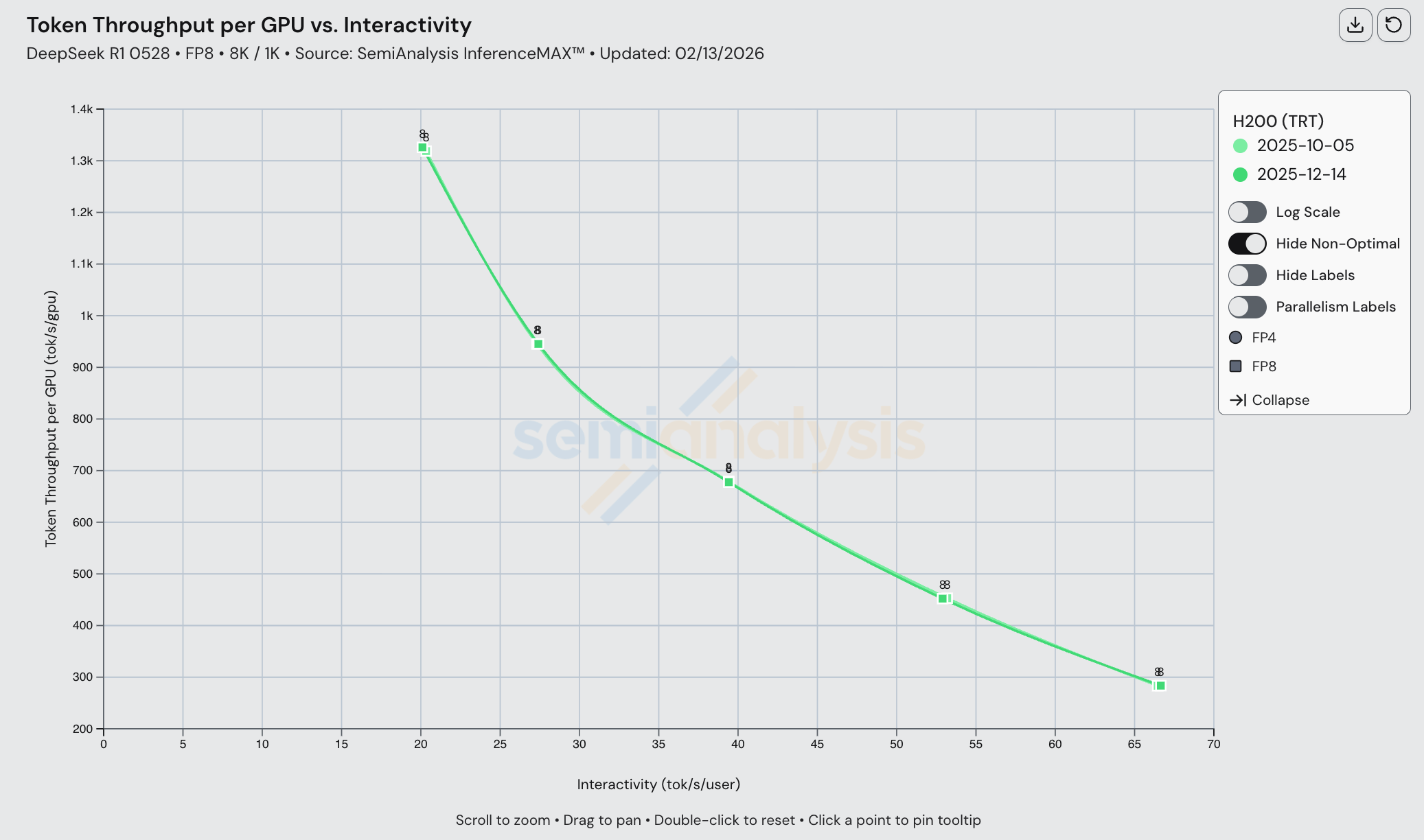
许多成熟 SKU 的改进幅度很小。例如,H200 TRT 单节点在自 10 月以来的 4 个月间性能没有变化,但这是因为 Hopper 的支持从第一天起就很出色,性能自始至终都接近该工作负载的理论峰值,使得交付增量性能提升变得困难。
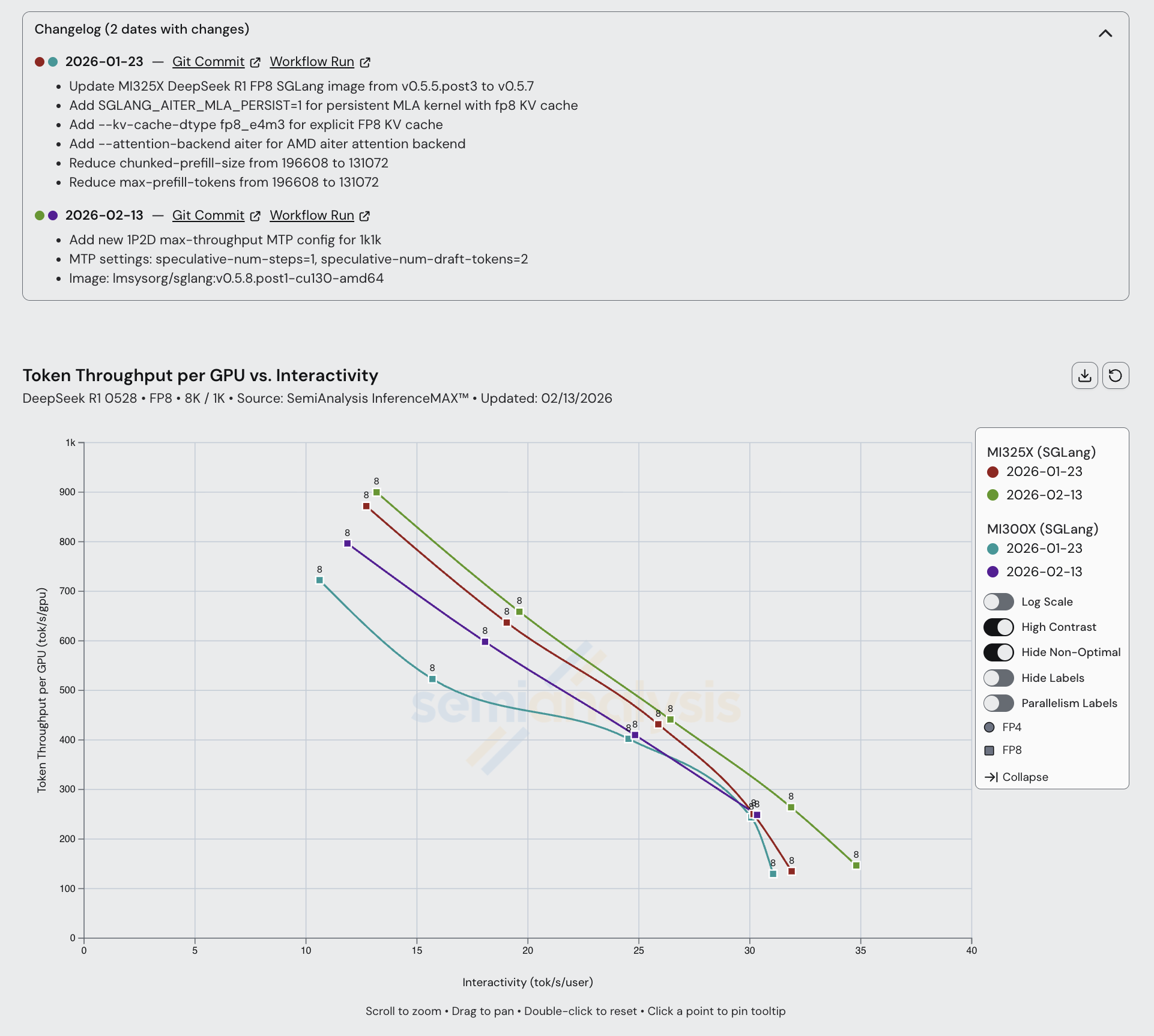
MI300X 和 MI325X 有了一些改进,主要来自最新的 SGLang 版本。请注意,在 InferenceX 的大部分历史中,AMD 使用的是未上推到上游的"私有" ROCm 镜像,因此约 2026 年 1 月之前的运行结果不能与更新的结果直接比较。
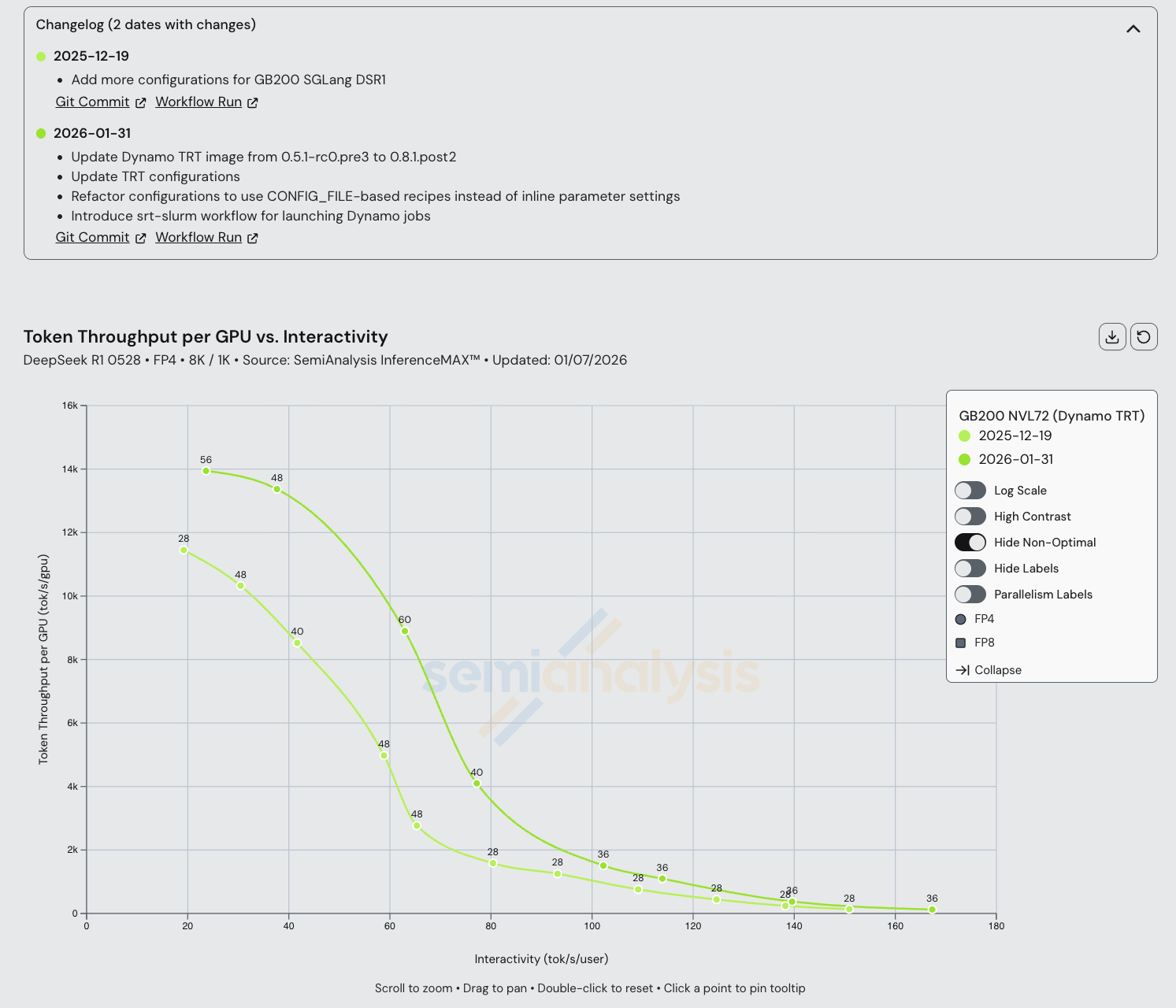
GB200 Dynamo TRT-LLM disagg 也有了显著改进,最大吞吐量在一个多月内提升了 20%。我们还看到中等交互性水平的改进,这部分采用了宽 EP。这可能归因于 GB200 上日趋成熟的宽 EP 内核。
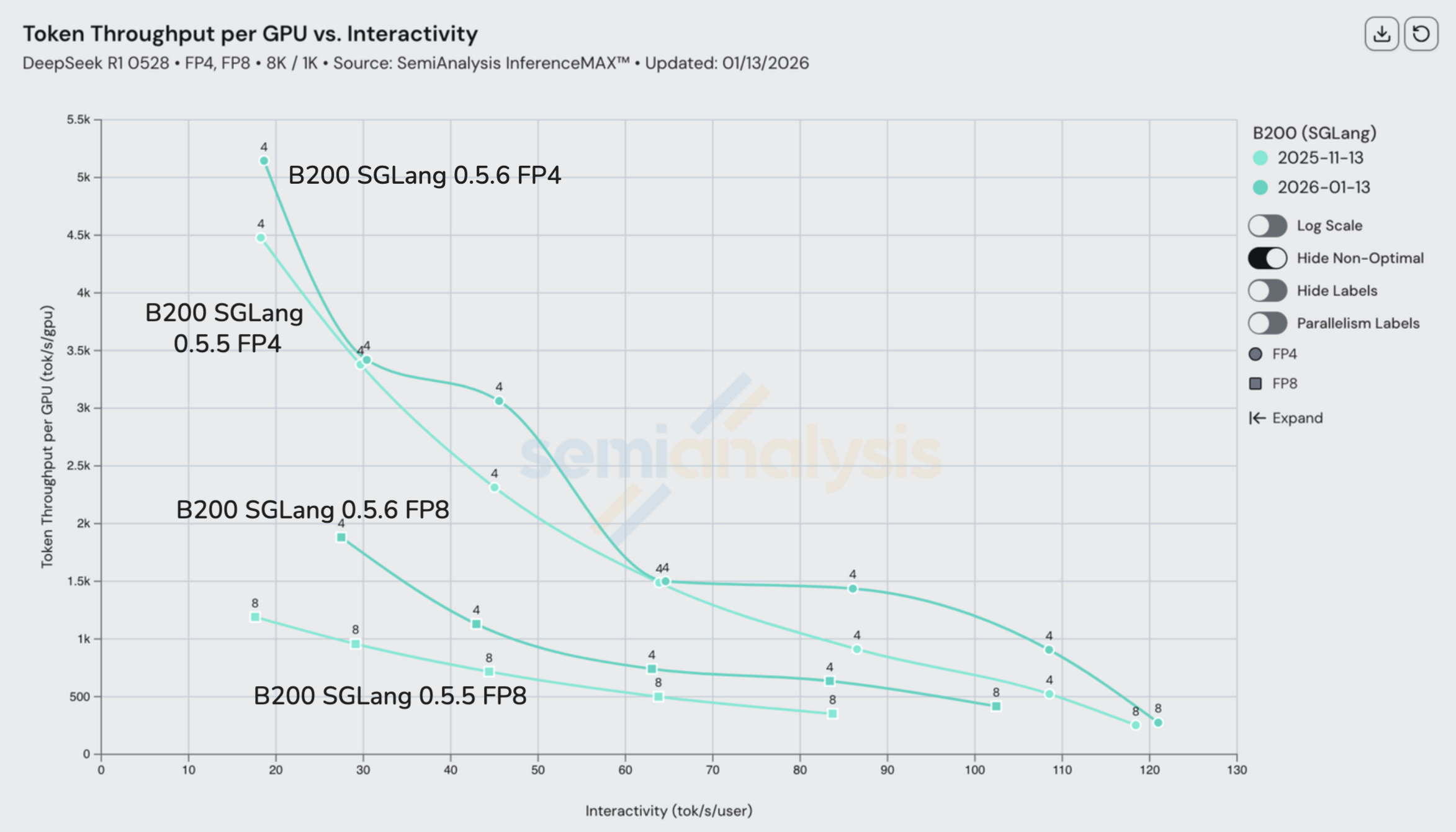
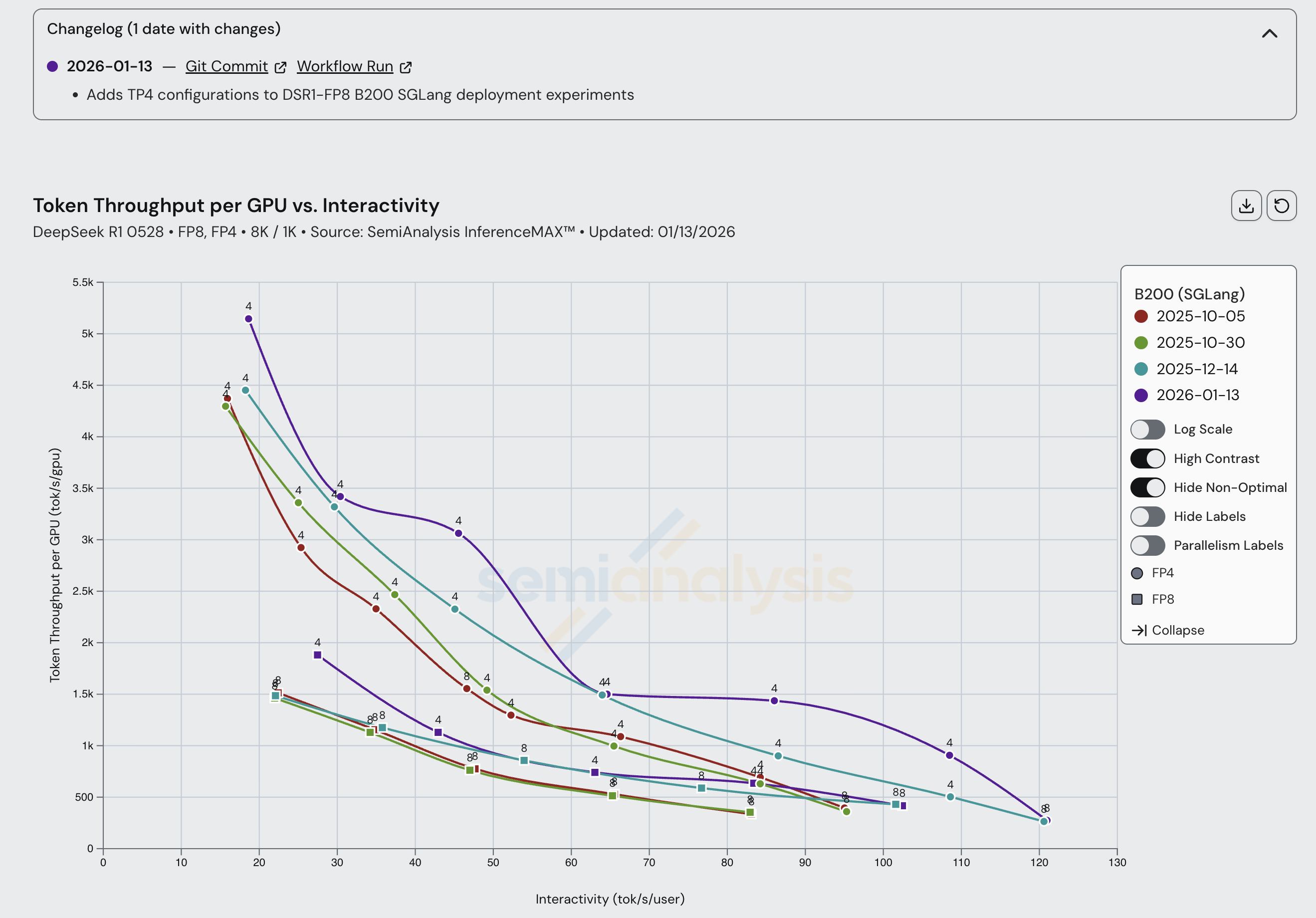
B200 SGLang 自我们去年 10 月首次发布以来,FP4 和 FP8 场景均呈现稳步持续改进,在某些交互性水平下每 GPU 吞吐量翻了一番。
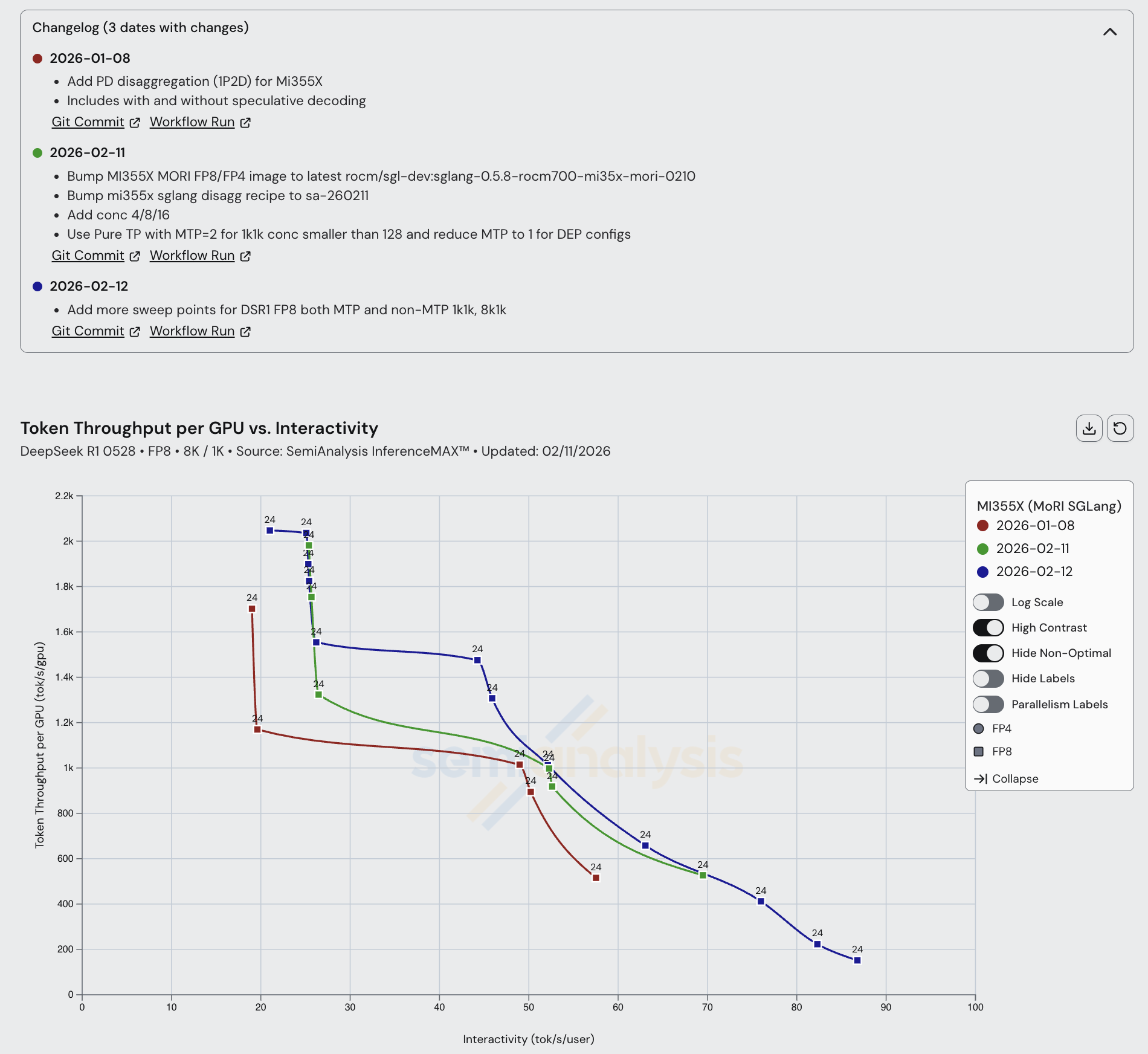
对于 MI355X 分离式推理服务,AMD 推荐使用 SGLang 配合 MoRI。MoRI 是 AMD 的 MoE 分发/聚合集合通信与 KV 缓存传输库,由 AMD 精锐的中国工程团队从第一性原理出发构建。虽然 MoRI 在开放 CI 和测试方面仍需大量工作,但我们坚定支持 MoRI 的发展方向。这是因为 MoRI 没有采用 AMD 历史上的做法(即将 NVIDIA 的 NCCL 分支为 RCCL),而是汲取了 RCCL/NCCL 的经验教训,从零开始构建了一个全新的包。MoRI 的使用也在一个多月的时间内带来了良好的加速效果,在 20-45 tok/s/user 交互性范围内,每 GPU 吞吐量提升了 20% 以上。
GPT-OSS 120B
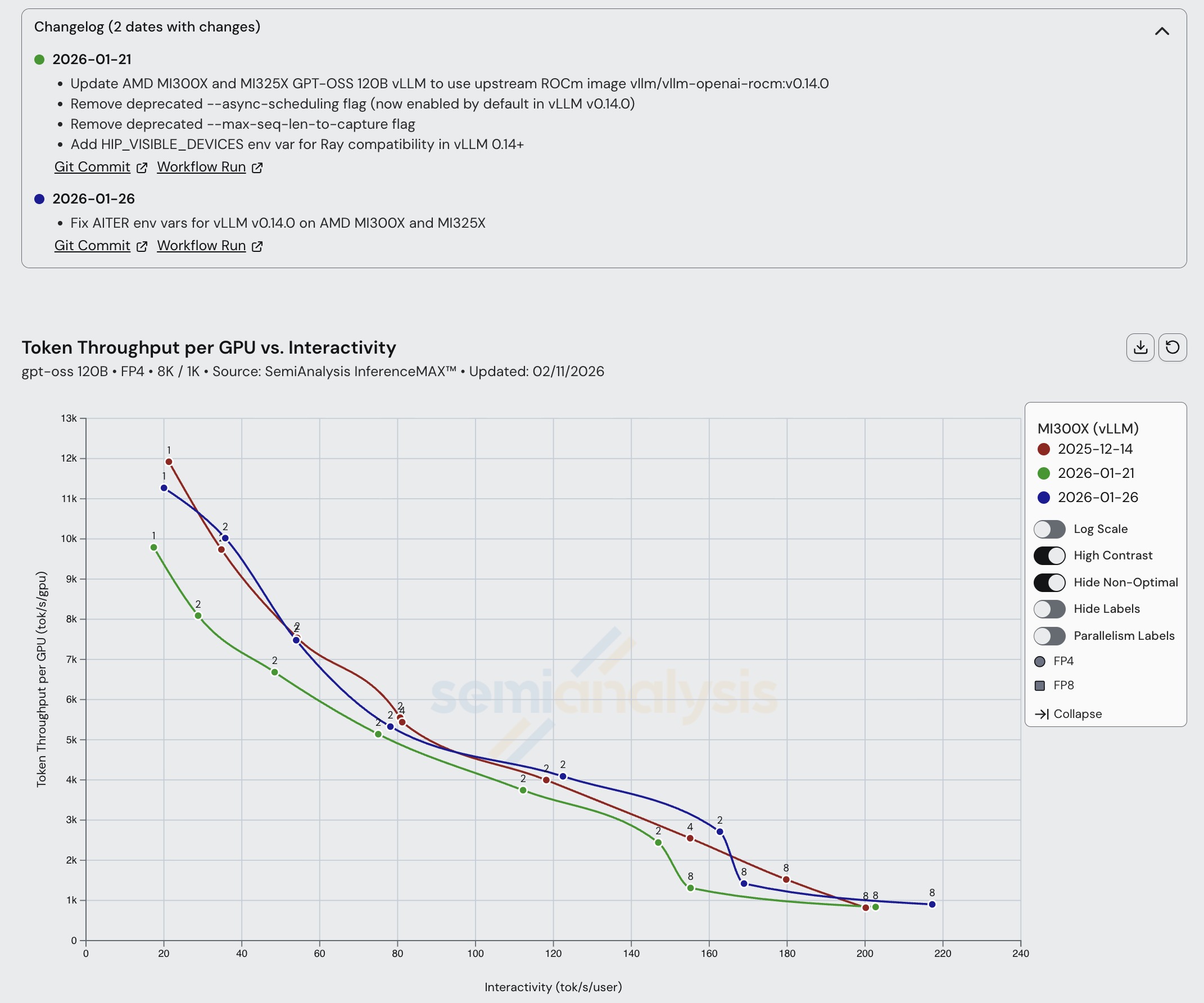
对于 MI300X 和 MI325X,我们在各方面看到了微小的改进。一些 AITER 优化帮助提升了 MI300X 在所有交互性水平下的性能,切换到上游 vLLM ROCm 镜像也带来了改进。
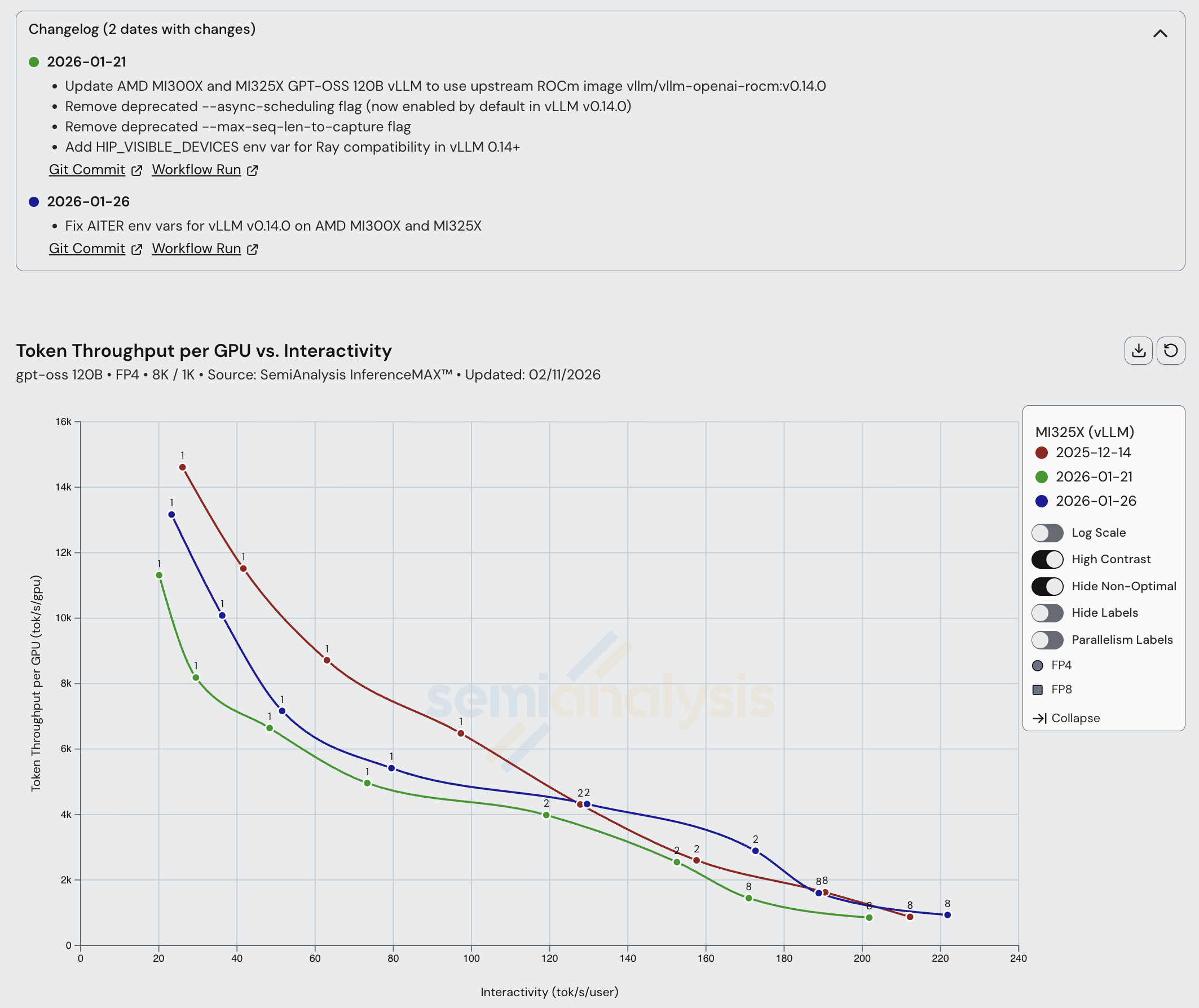
就 MI325X 而言,下游 ROCm 分支镜像(2025 年 10 月 5 日运行时使用)中存在的性能优化似乎并非全部都已合入官方 vLLM ROCm 镜像。
遗憾的是,MI355X 目前仍在使用 vLLM 0.10.1 版本的分支构建 rocm/7.0:rocm7.0_ubuntu_22.04_vllm_0.10.1_instinct_20250927_rc1。我们本希望现在已经更新了,但不幸的是,当前的官方镜像(撰写本文时为 0.15.1)尚未针对 MI355X 进行优化,并且会遇到硬错误。我们在 MI355X 上运行 vLLM 0.14 时也曾遇到硬错误崩溃。业界消息是 vLLM 0.16.0 将最终提供 MI355X 所需的全部改进。
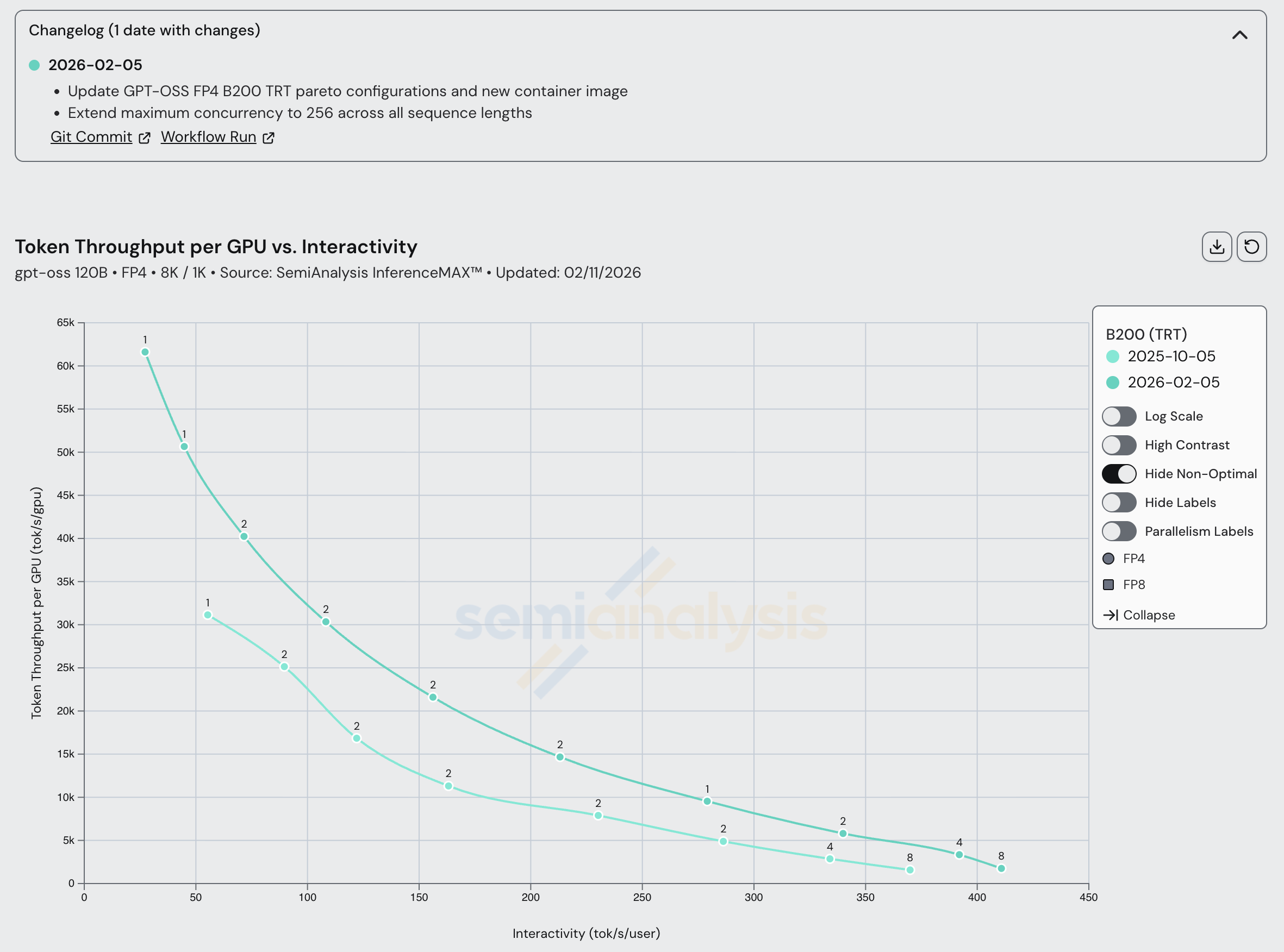
回到 NVIDIA 的系统,Hopper 和 Blackwell 在 vLLM 0.11.2 和 0.13.0 之间都实现了稳步性能提升。我们即将把 NVIDIA GPU 的配方更新到最新 vLLM 版本,预计切换后将获得更大的性能提升。我们还观察到最新的 TRT-LLM 1.2.0 版本带来了性能提升。
分离式推理框架
NVIDIA 使用 Dynamo 作为其分离式推理方案。Dynamo 是一个专为多节点分布式推理设计的推理框架,具备预填充-解码分离、请求路由和 KV 缓存卸载等技术。它与推理引擎无关,允许我们在基准测试中使用 SGLang 和 TRT-LLM 作为后端。对于 AMD,我们使用 SGLang 配合两种不同的 KV 缓存传输框架:MoRI 和 Mooncake。MoRI 是一个高性能通信接口,专注于 RDMA 和 GPU 集成,提供网络集合操作和专家并行内核等应用。Mooncake 最近加入了 PyTorch 生态系统,支持预填充-解码分离以及多种容错多节点功能。
DeepSeek Disagg + WideEP 结果深入分析
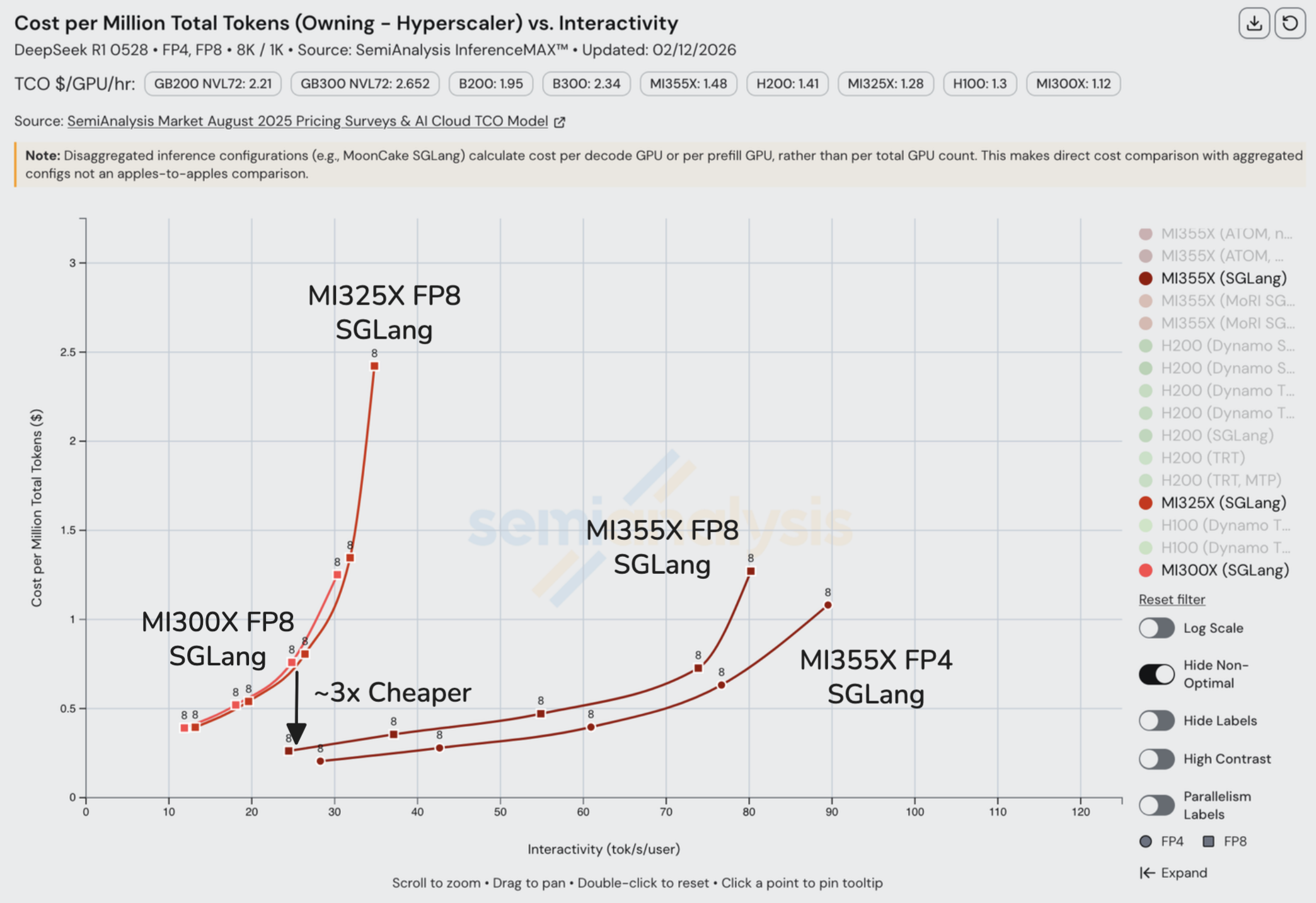
在几乎所有交互性水平下,disagg 在每 GPU 总 token 吞吐量方面都优于聚合推理(灰色线条)。多节点分离式预填充相比单节点聚合服务有着碾压级的优势。
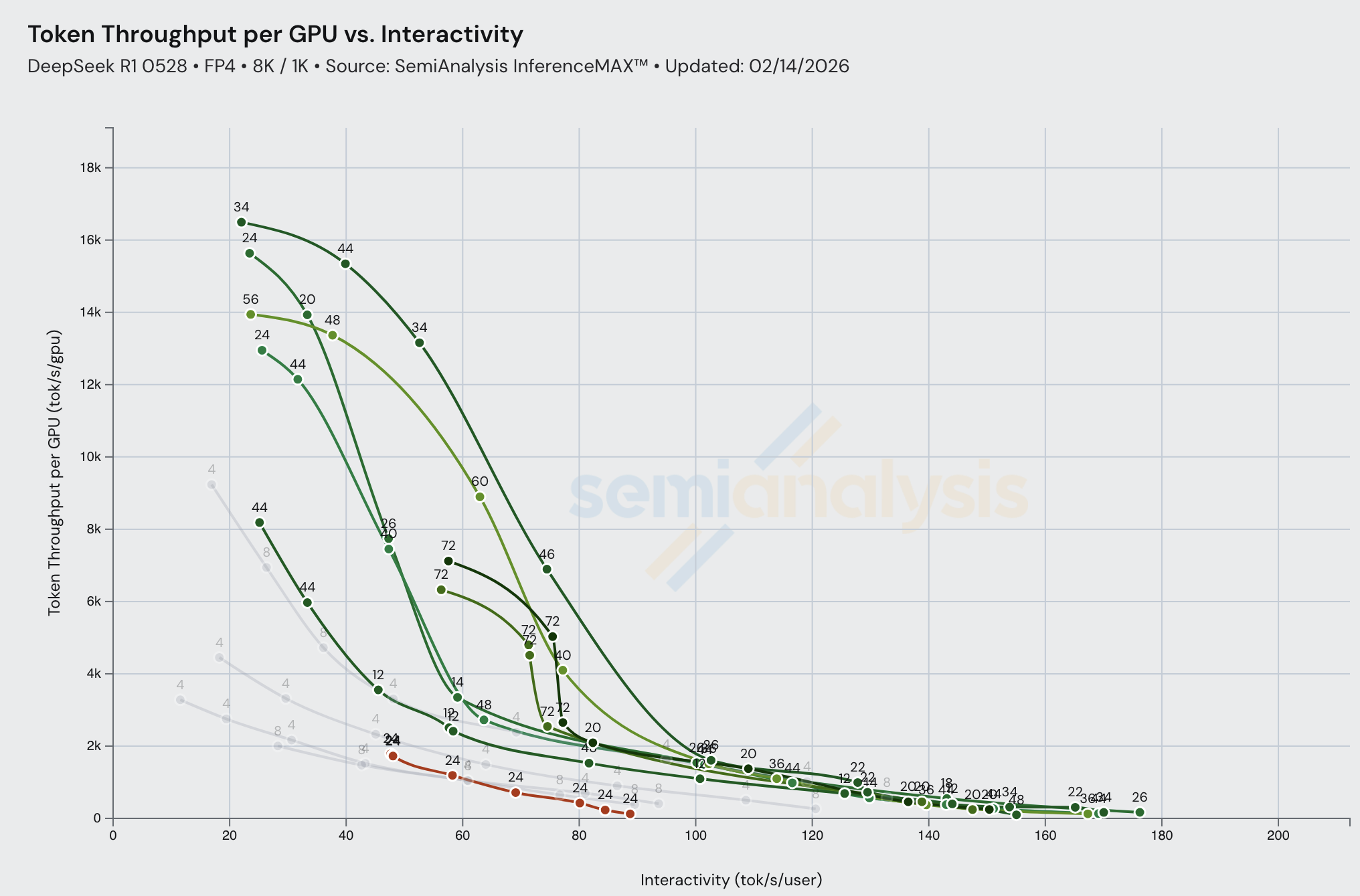
NVIDIA 持续为 B200/GB200 FP8 推送新更新。最新数据展示了 DeepSeek FP8 B200 TRT 单节点(MTP 启用/禁用)vs GB200 Dynamo+TRT disagg(MTP 启用/禁用)的对比。这表明在改进机架规模推理软件和 wideEP 内核方面持续投入了工程力量。
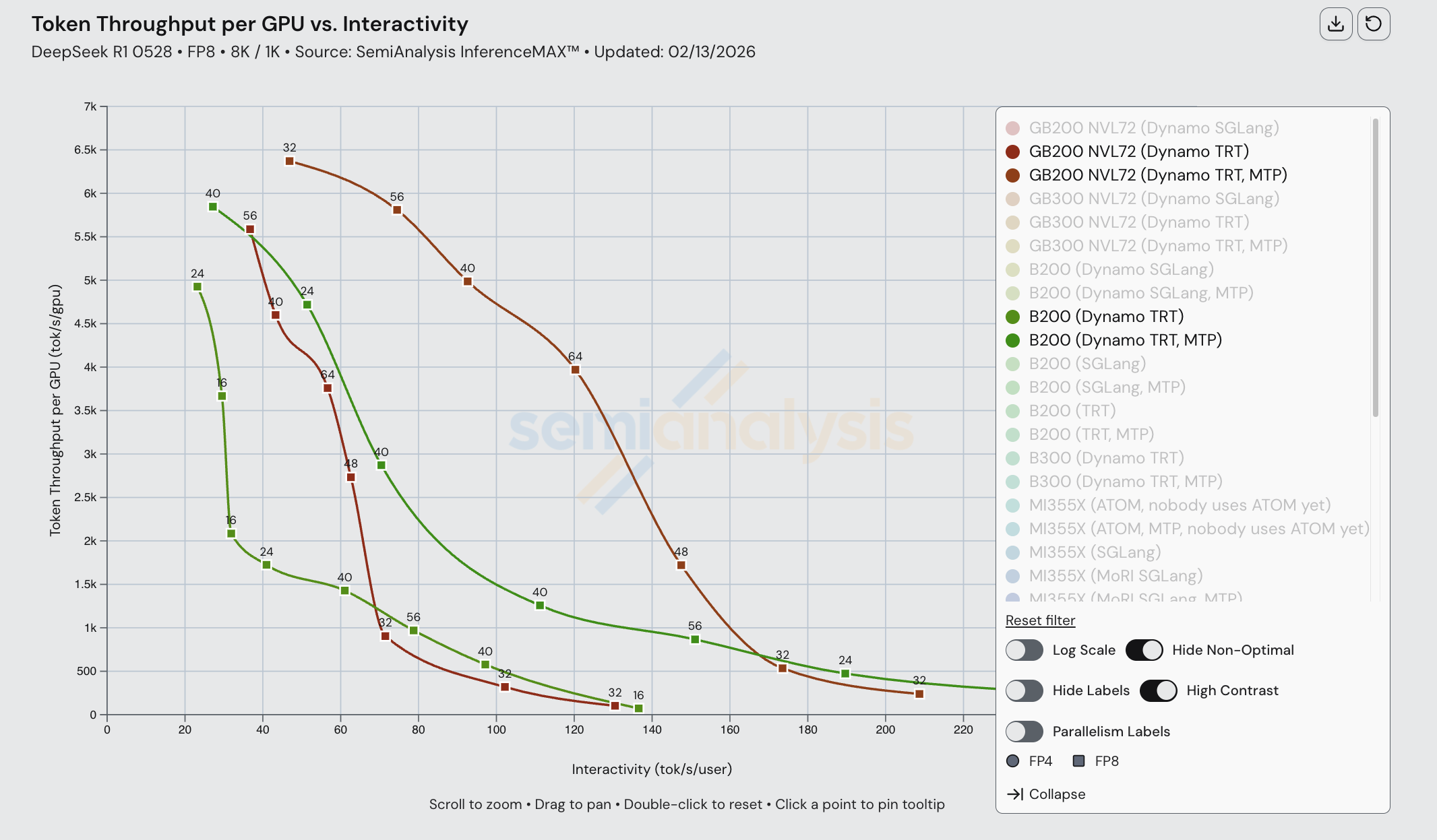
在比较 MI355X 分离式推理与聚合推理时,我们注意到了类似的模式。分离式推理仅在低交互性、高批次的情况下超过聚合推理。这在 FP4 下尤为明显,可能源于优化不够充分的内核。
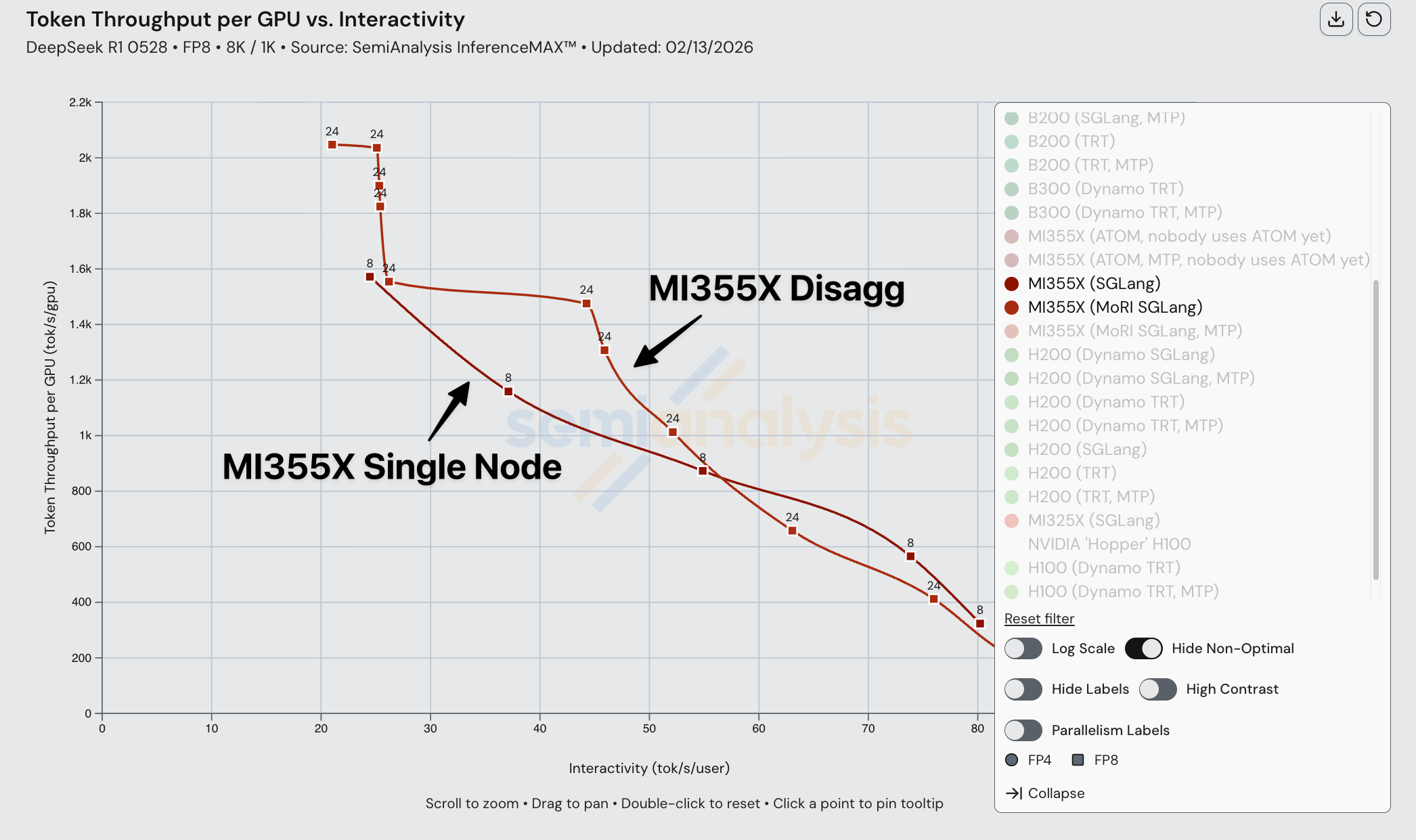
在 MI355X 上将 disagg 预填充+wideEP 与 FP4 组合使用时,我们观察到性能表现不佳。
虽然理论建模显示 MI355X 上的 disagg 推理应该远优于单节点,但由于 ROCm 软件栈在组合多种 SOTA 推理优化时缺乏内核和集合通信优化,disagg 在较高交互性水平下的实际表现反而更差。
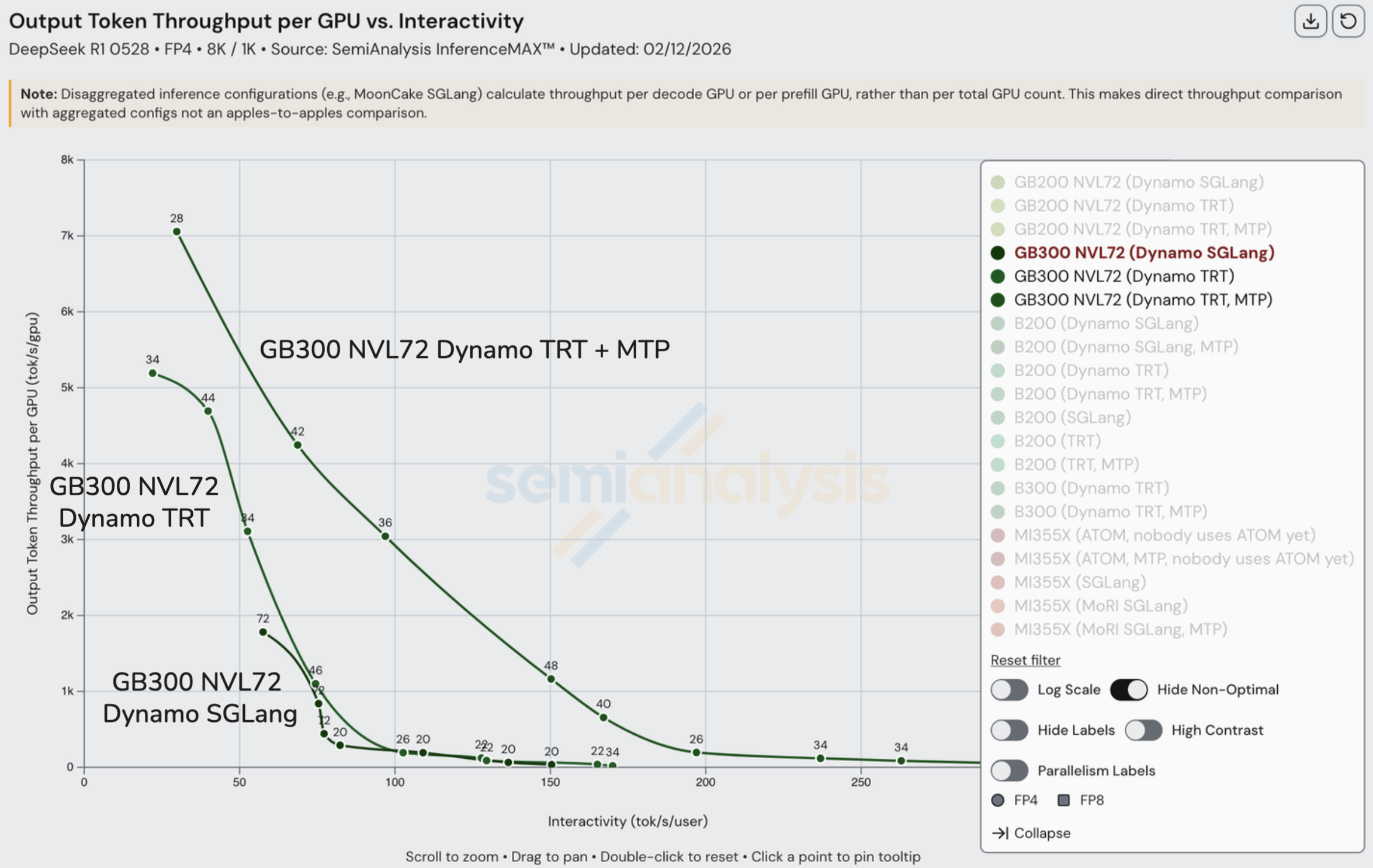
NVIDIA TensorRT-LLM 与 NVL72
TensorRT-LLM 已在全球范围内为 TogetherAI 等服务商每小时处理数十亿 token,它真正让 GB200 NVL72 和 GB300 NVL72 大放异彩,在高吞吐量下性能提升超过一倍。MTP 进一步增强了这些结果,充分释放了芯片的全部潜力。
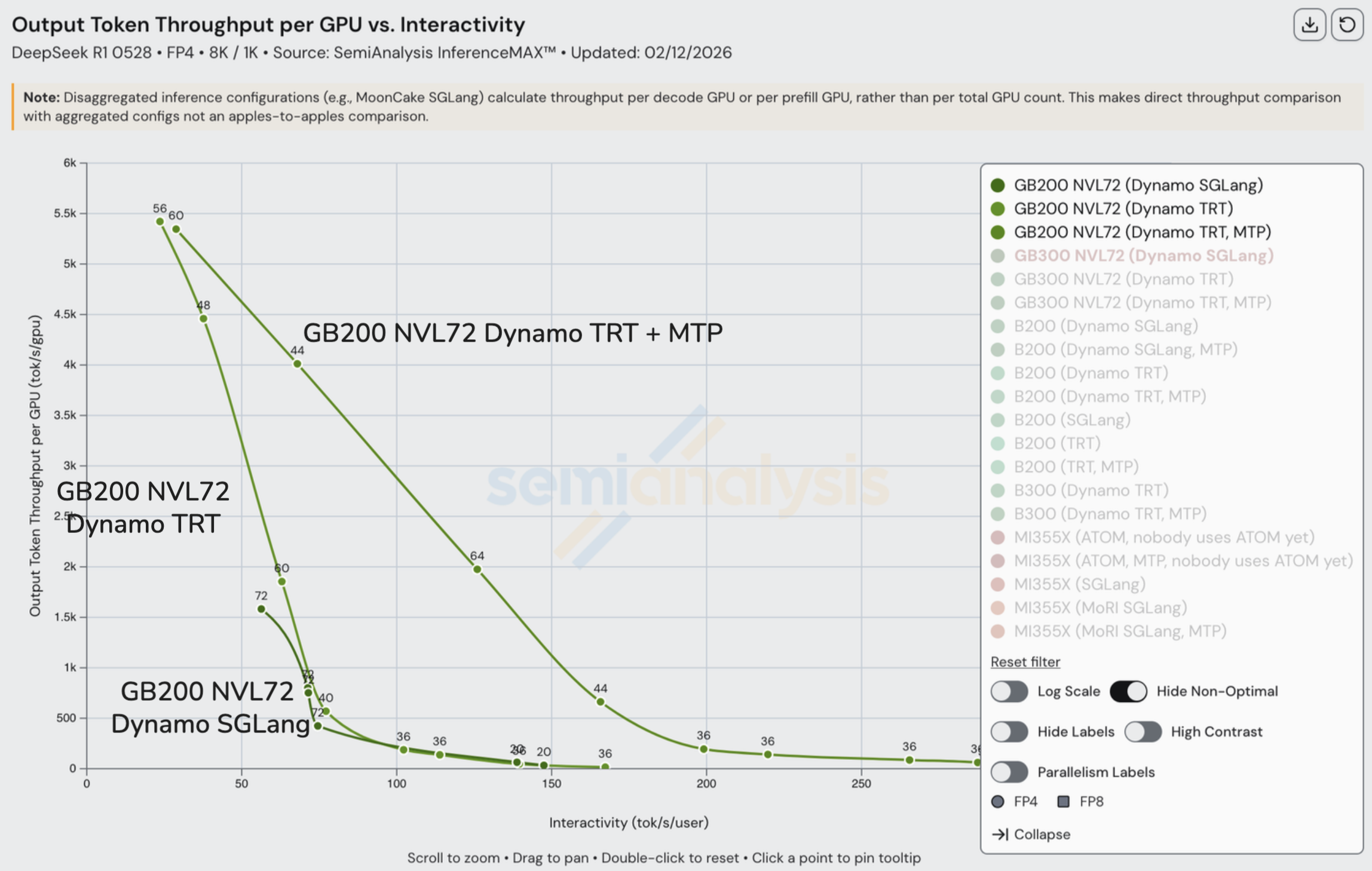
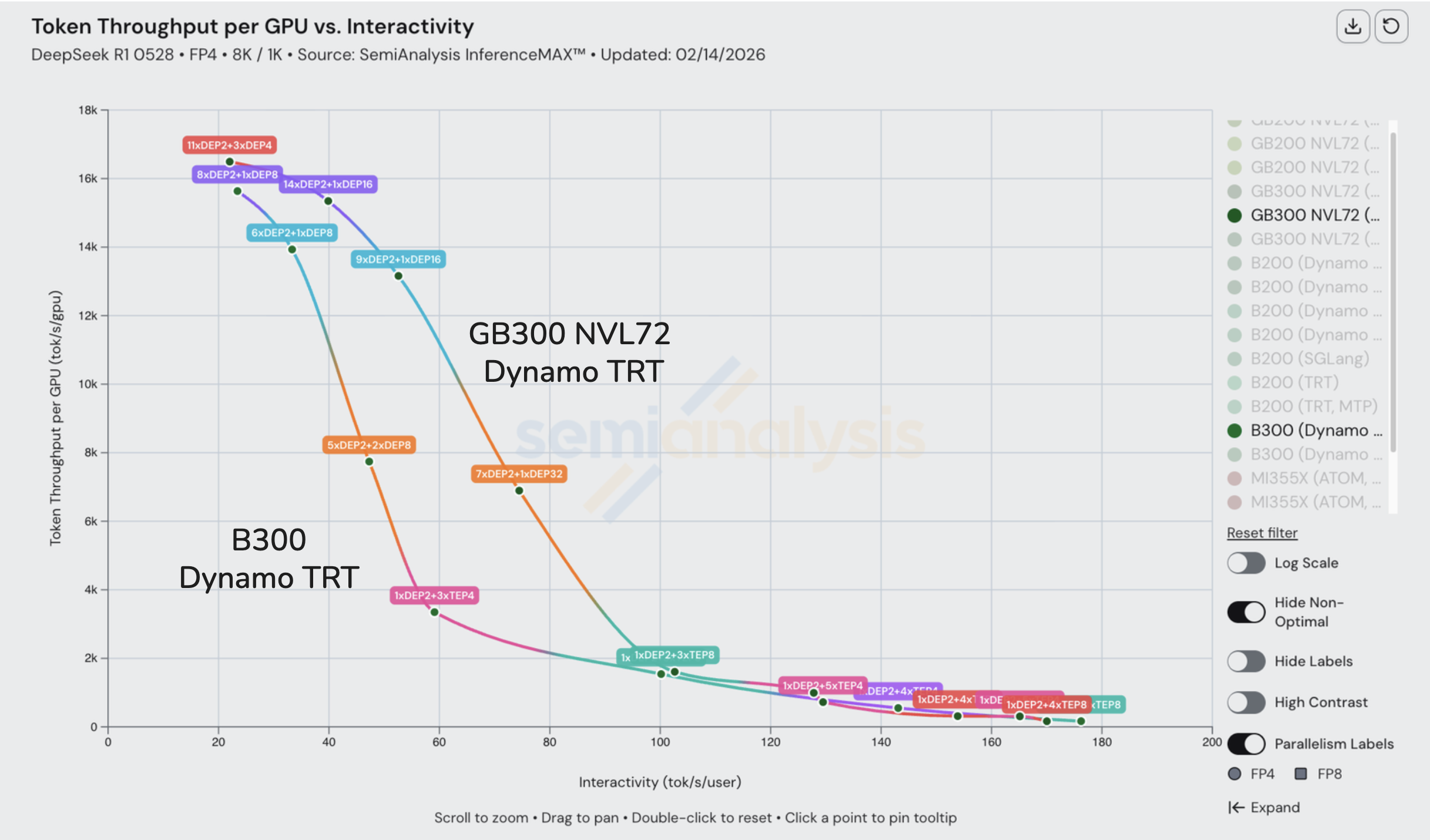
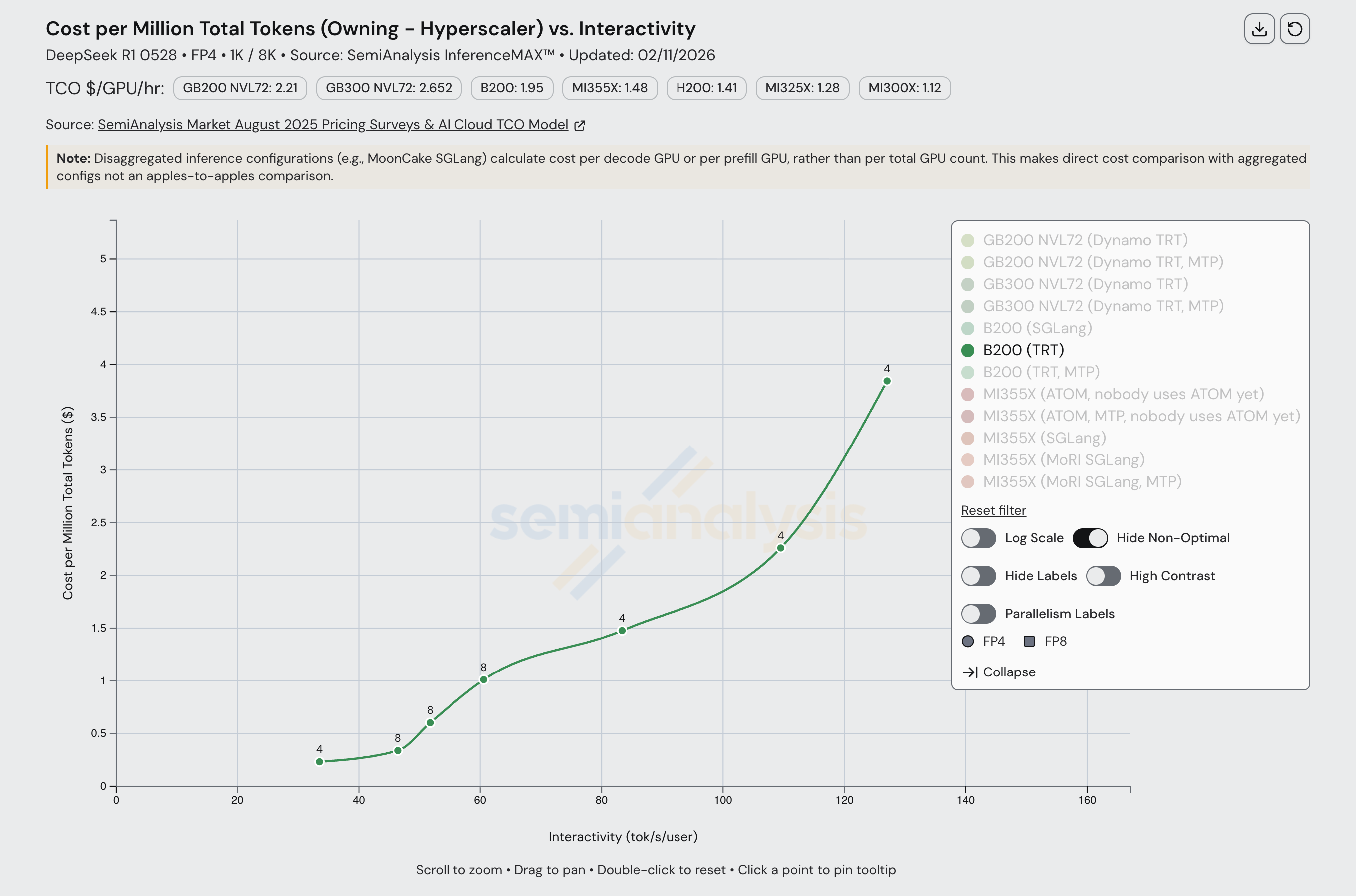
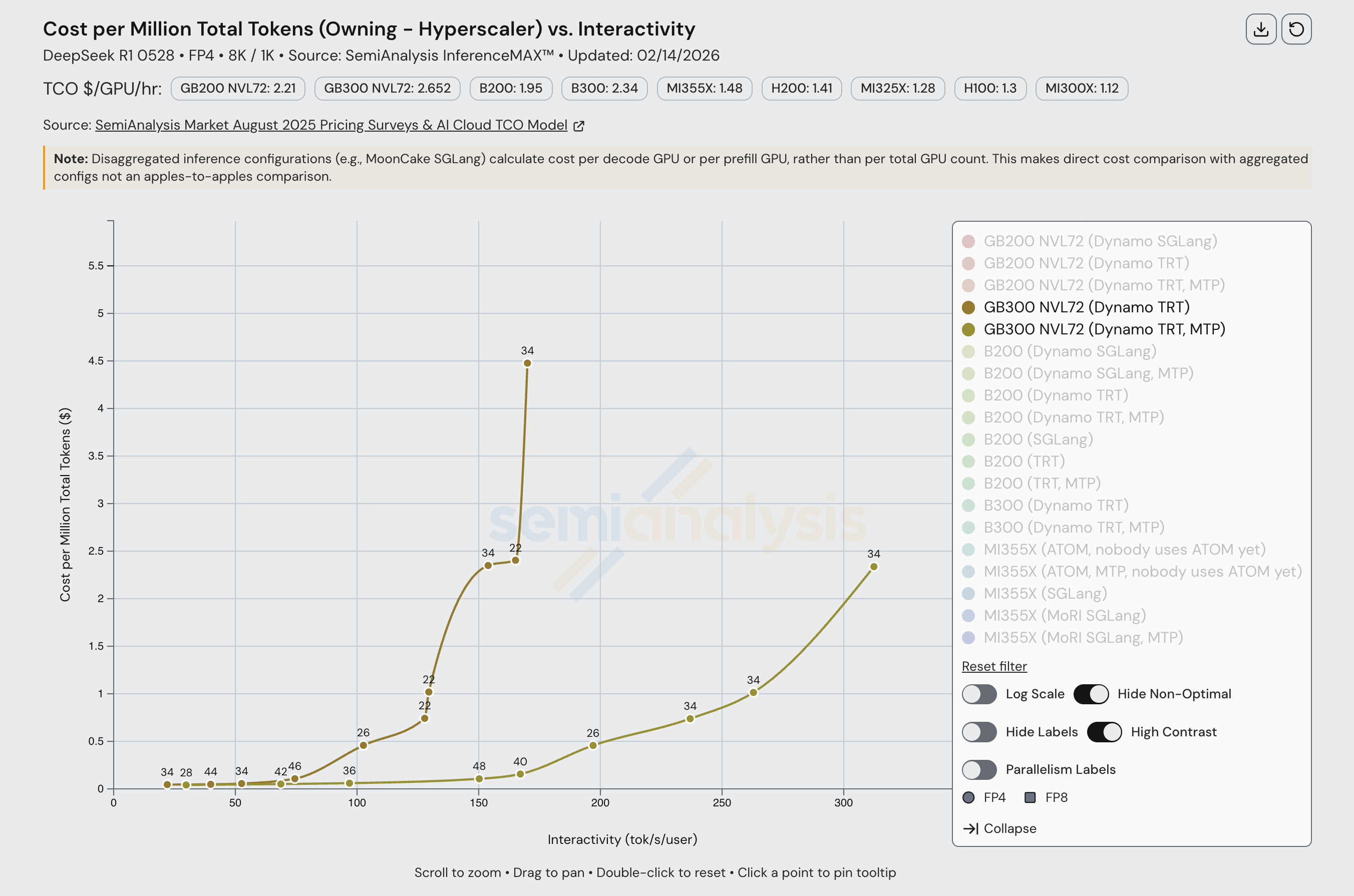
NVL72 系列更大世界规模带来的优势也体现在成本图表上。在固定 60 tok/s/user 交互性水平下,每块 GB200 NVL GPU 产出的 token/s 略低于 B200 的三倍。
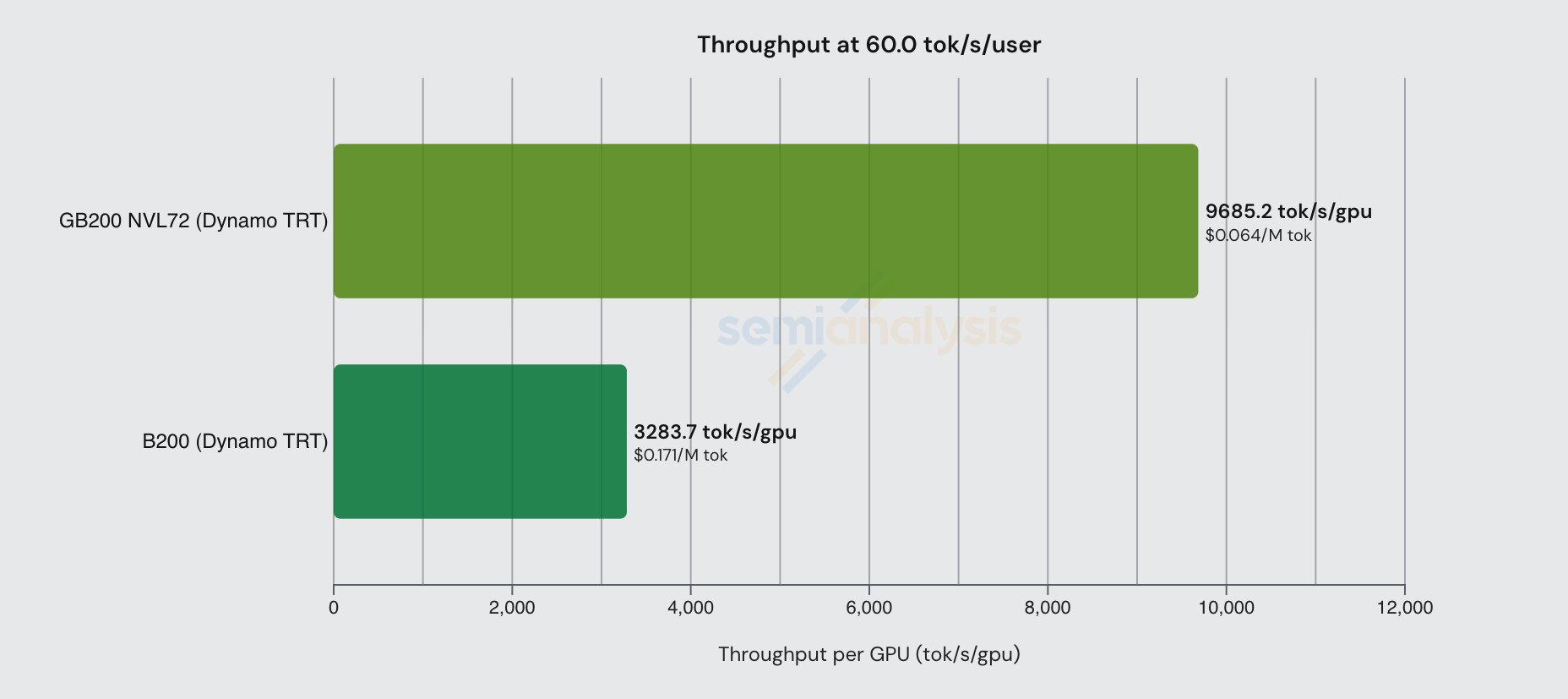
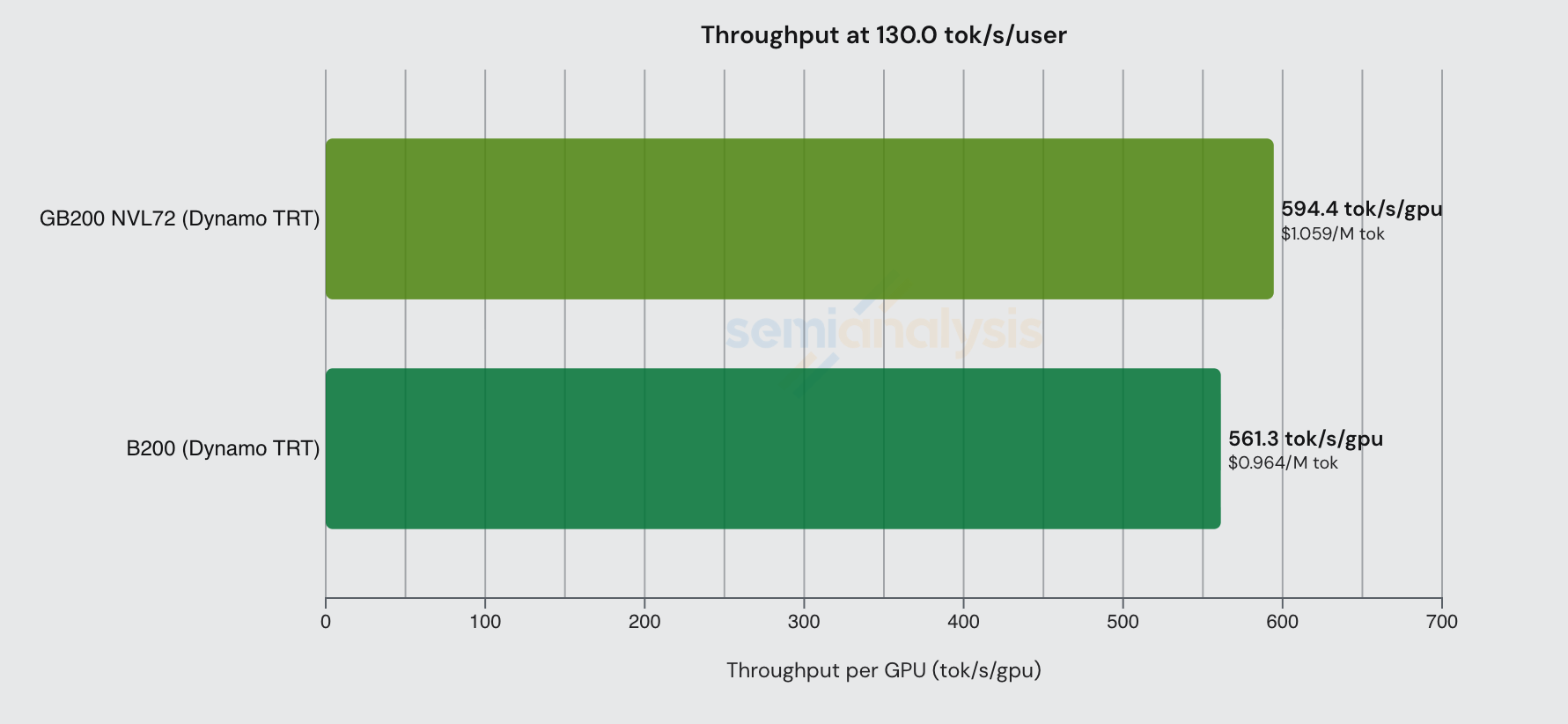
随着交互性提高,这一差距缩小。在 130 tok/s/user 时,GB200 NVL72 几乎没有优势,在 $/百万 token 的基准上甚至更贵。在低批次下,推理工作负载足够小,可以在单个 HGX 节点的 NVLink 域内(即 8 块 GPU)运行,GB200 NVL72 的大规模扩展优势开始消失。
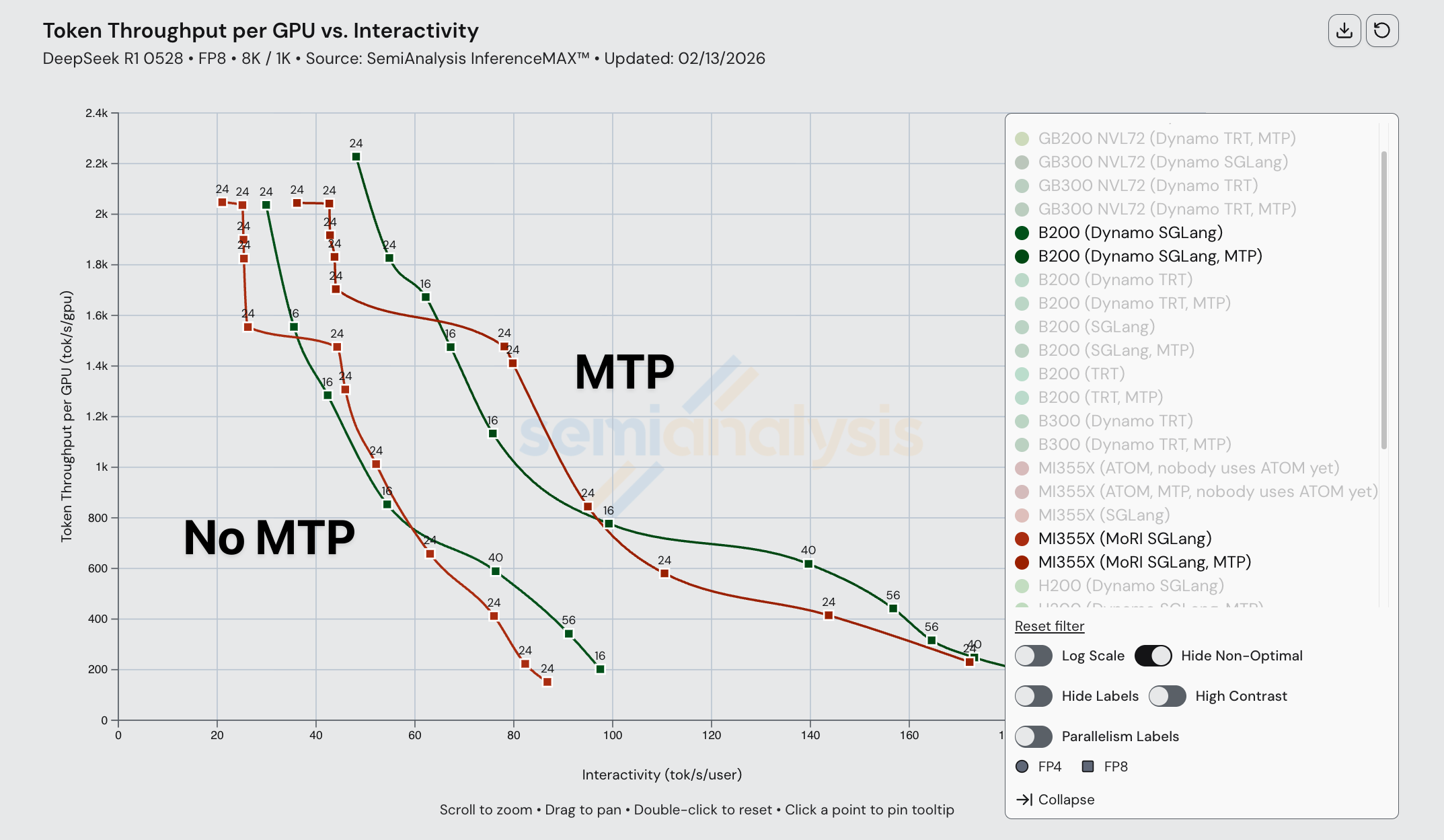
NVIDIA 与 AMD 分离预填充对比
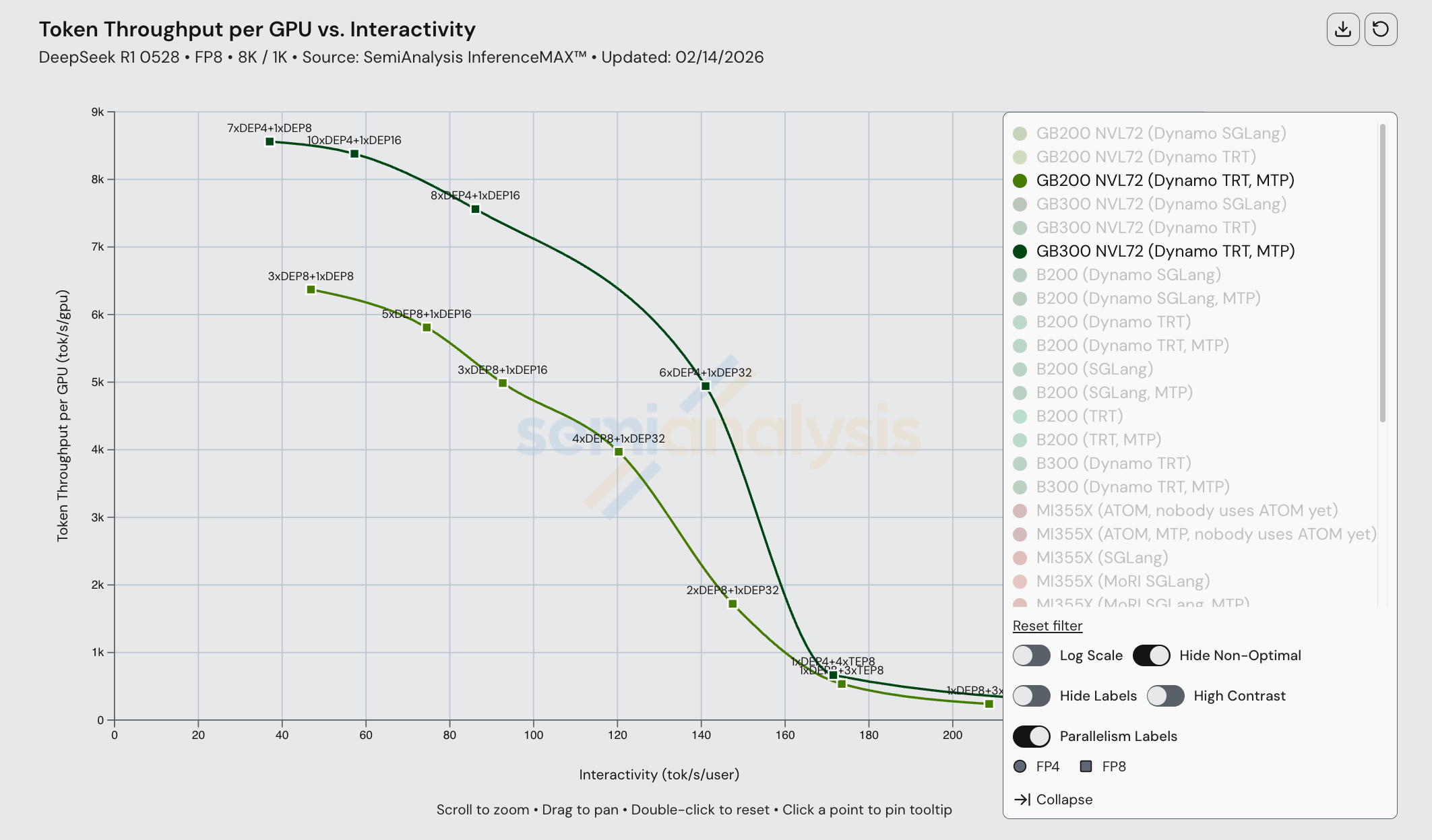
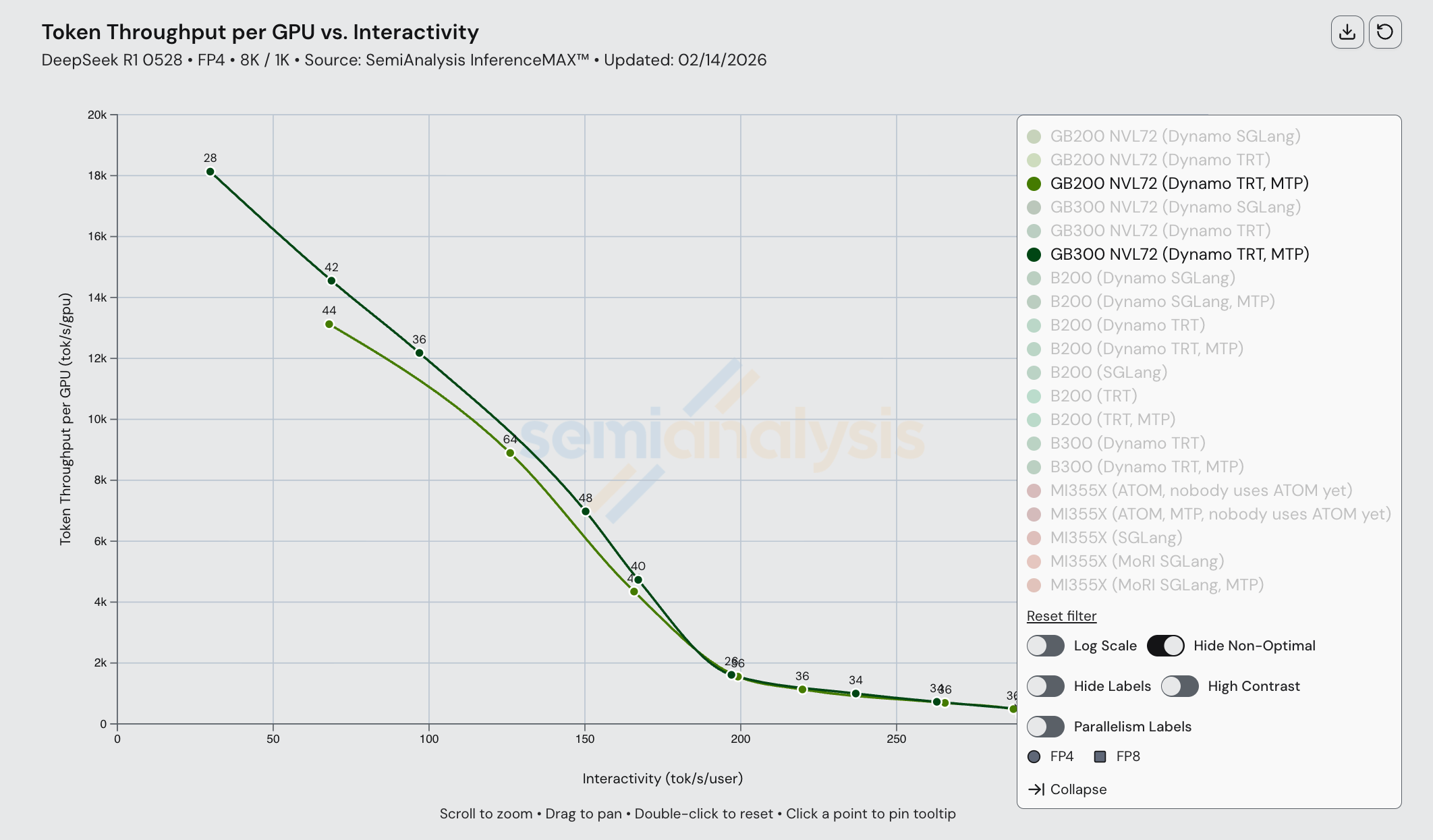
在今天发布的 InferenceXv2 中,ML 社区首次能够看到开源 MI355X 分布式推理的完整帕累托前沿。我们展示了 B200 和 MI355X 在启用和未启用 MTP 的情况下的帕累托曲线。
对于 FP8 分离预填充,MI355X(MoRI SGLang)与 B200(Dynamo SGLang)具有相当的竞争力。这两种配置均未使用宽 EP,所有预填充/解码实例最多使用 EP8。在吞吐量 vs 交互性帕累托前沿的两端,MI355X 略落后于 B200。然而,MI355X disagg 在曲线中段的某些交互性水平上有轻微优势。B200 和 MI355X 都受益于 MTP 的使用,且我们观察到两款芯片使用 MTP 时的相对性能提升幅度相同。
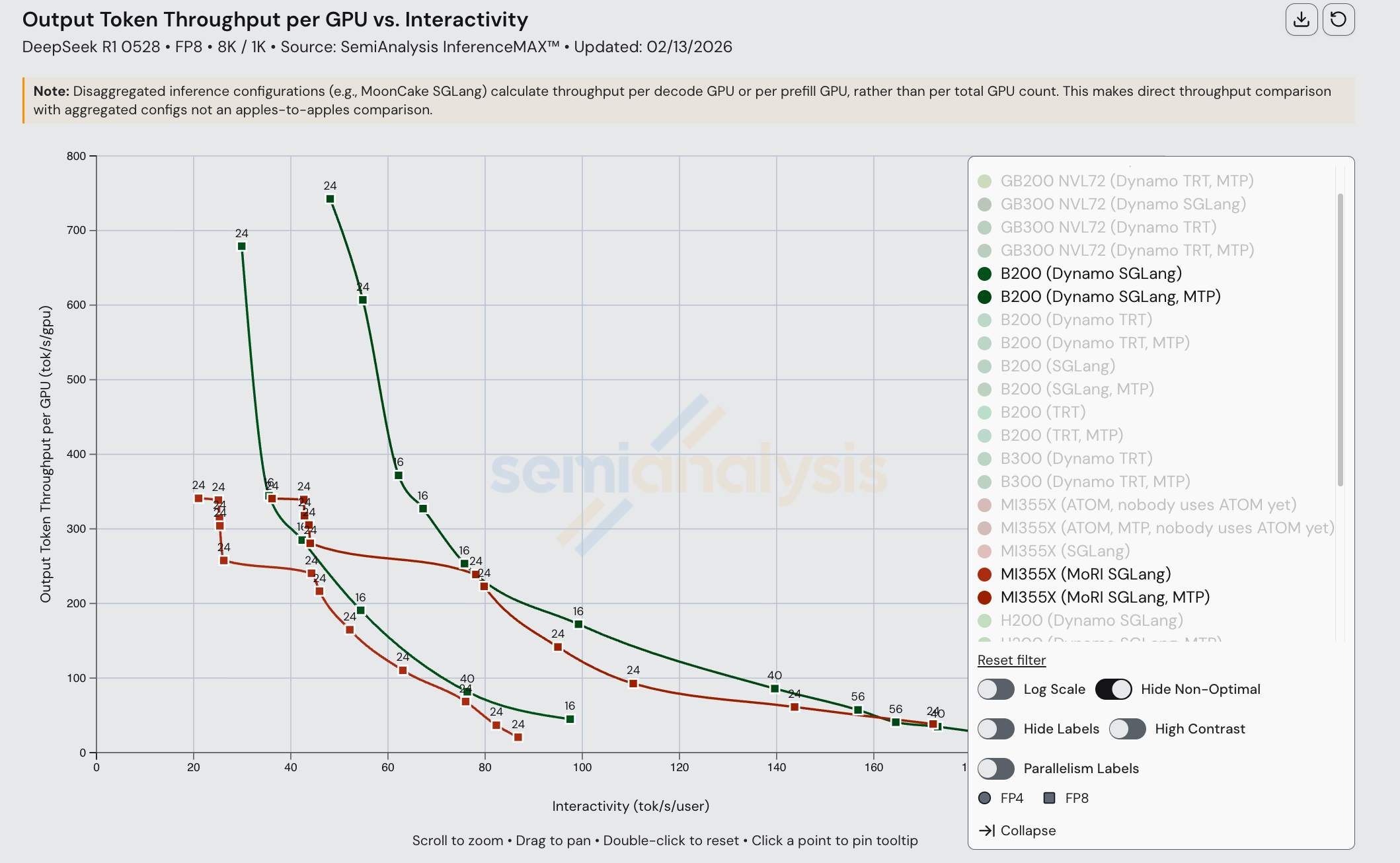
然而,如果我们仅衡量输出(解码)token 吞吐量,可以看到在较低交互性水平下 B200 的输出 token 吞吐量远高于 MI355X。请注意,在查看分离式推理配置的仅输出 token 吞吐量时,我们按解码 GPU 数量而非总 GPU 数量进行归一化。B200 和 MI355X 运行推理任务时可能使用了不同数量的输出 GPU,但关键是无论解码在什么配置上运行,B200 都能更快地完成解码任务。
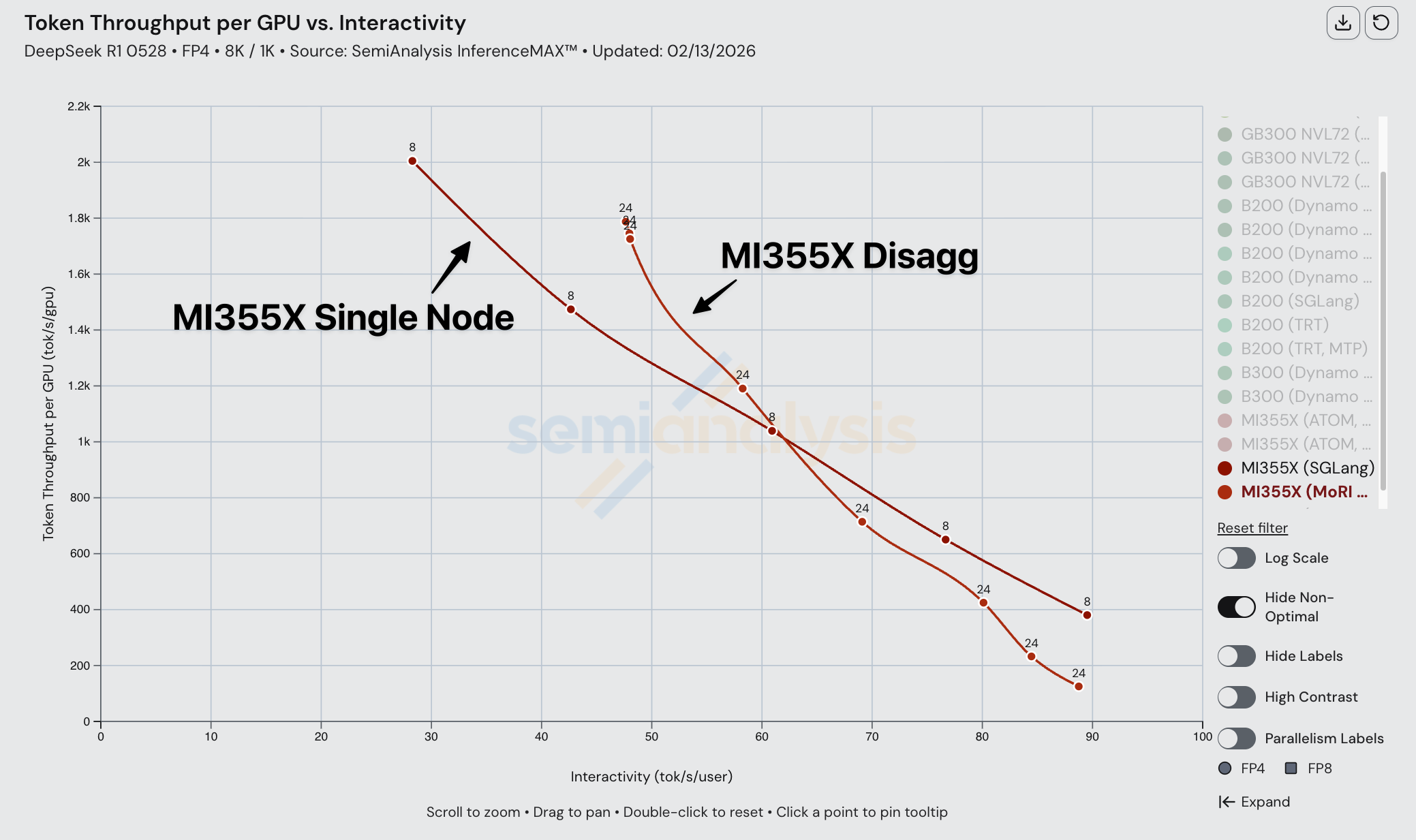
尽管 MI355X 在 FP8 disagg 上具有竞争力,但其 FP4 性能受到可组合性问题的影响。AMD 单节点 FP4 性能尚可,但当我们将 AMD FP4 分离预填充与 NVIDIA 进行比较时,性能表现不佳,MI355X 被 NVIDIA 的 B200 全面碾压。在 1k1k 场景下,MI355X(MoRI SGLang)启用 MTP 也仅勉强胜过未启用 MTP 的 B200(Dynamo SGLang)。
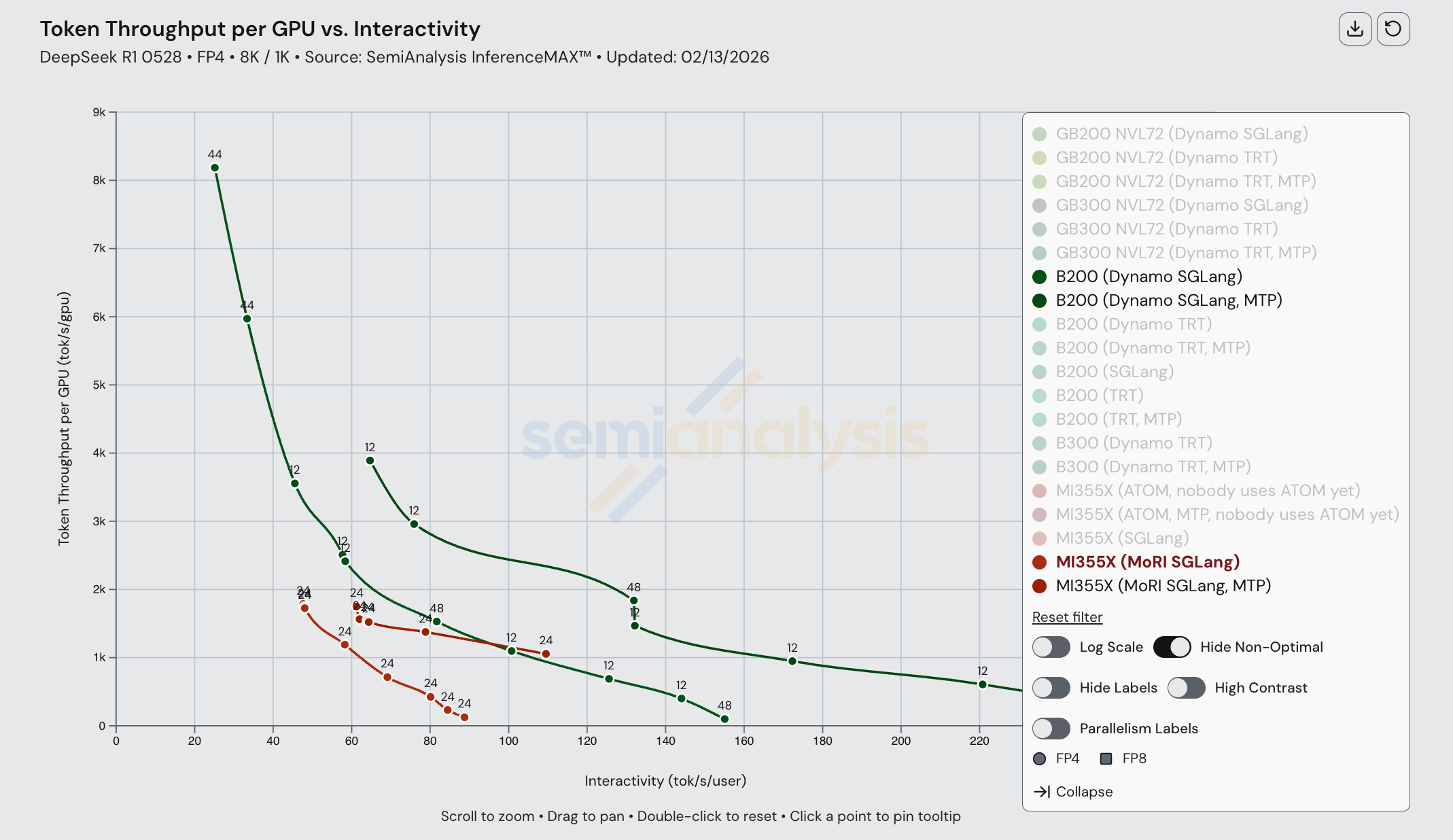
一旦引入 Dynamo TRT-LLM,B200 的性能进一步提升,以至于即使启用 MTP 的 MI355X 也无法匹配 B200 配合 Dynamo TRT-LLM 和 MTP 的性能。MI355X 只有在使用 MTP 时才能匹配 B200(未启用 MTP)的性能,且仅限于约 60 tok/s/user 到约 120 tok/s/user 的交互性范围。
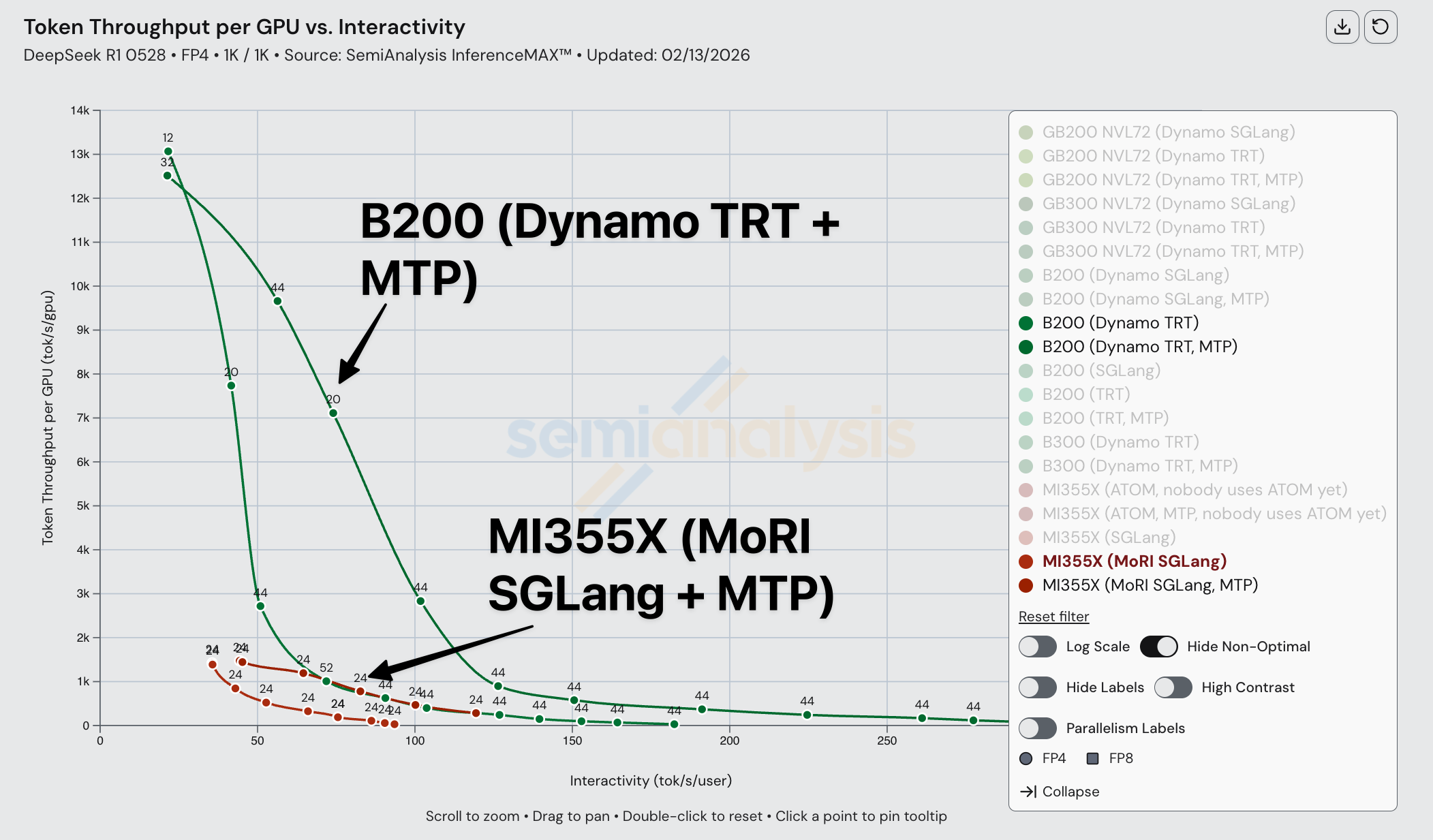
在比较 Dynamo TRTLLM B200 分离预填充与 SGLang MoRI MI355 分离预填充时,由于 TRTLLM 上分离预填充实现更为成熟,AMD 被全面碾压。
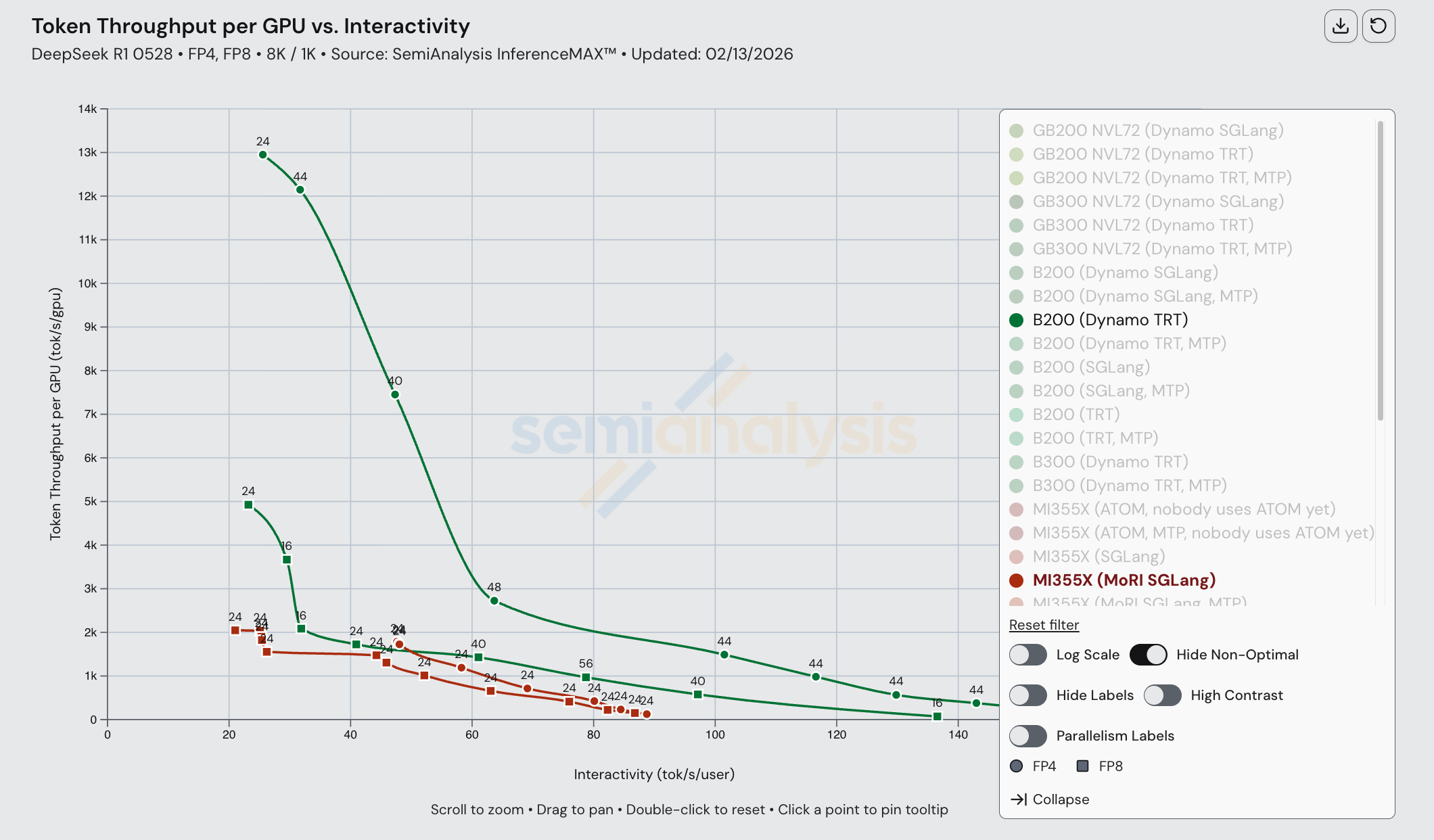

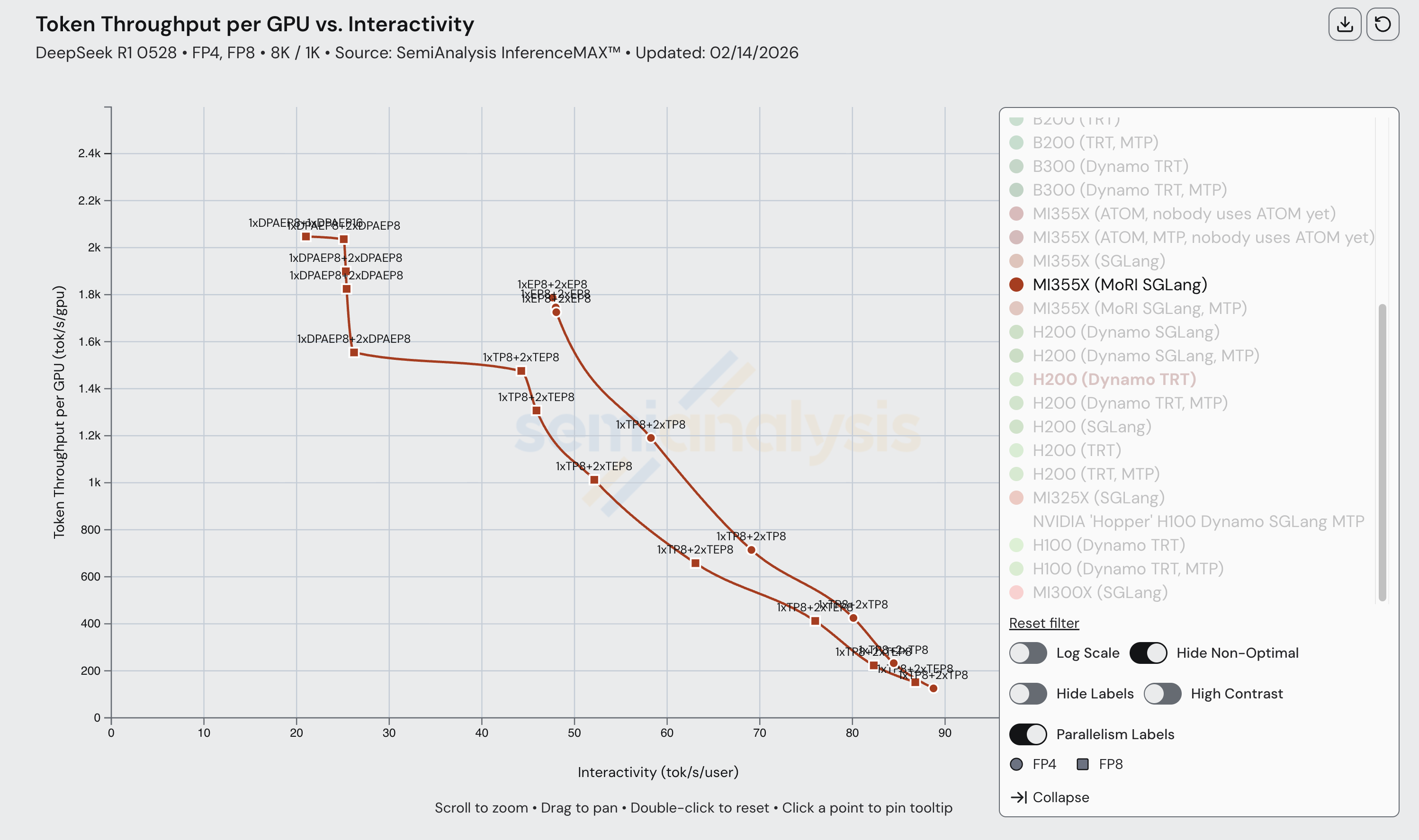
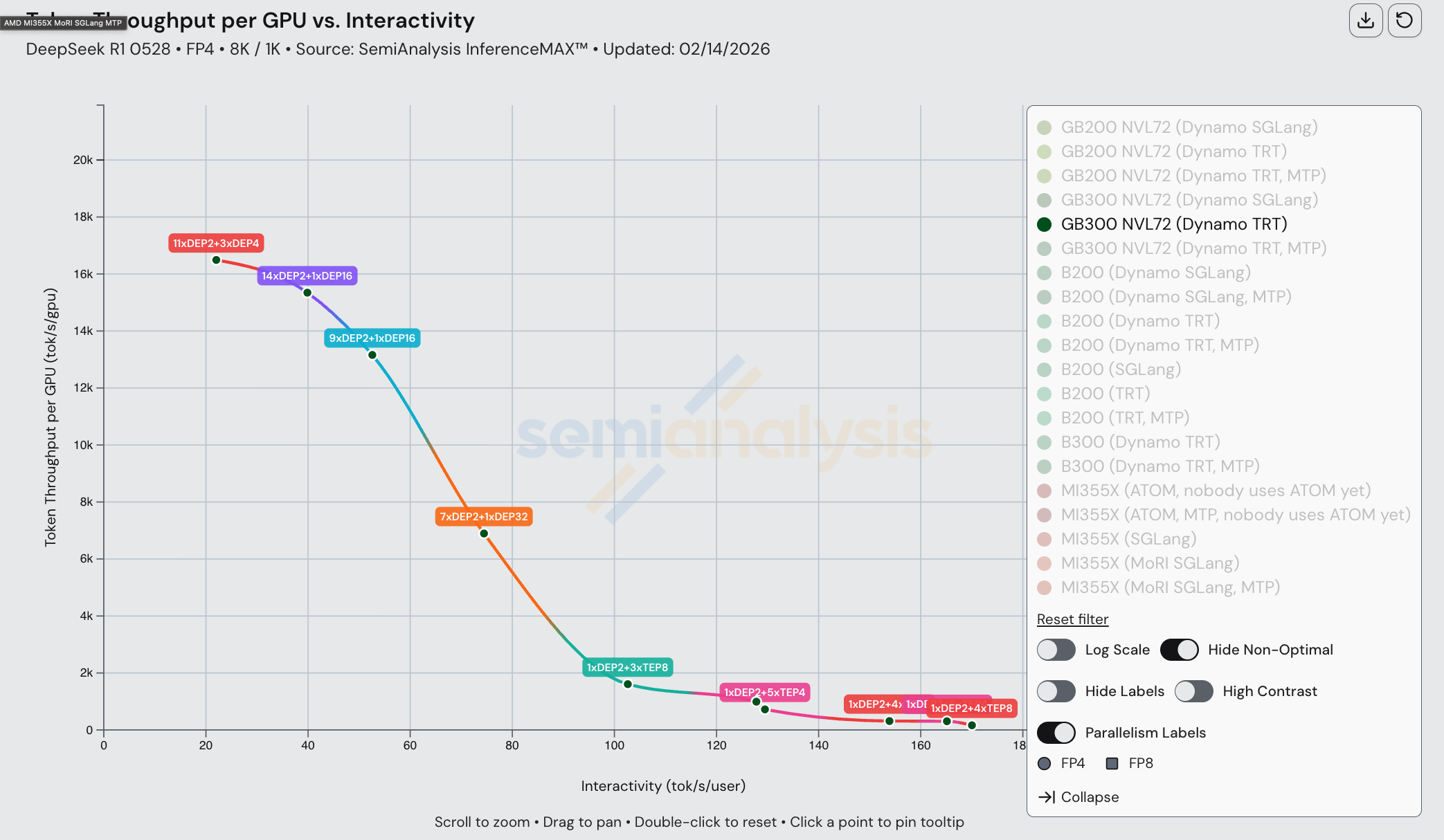
下图展示了构成 MI355X(MoRI SGLang)帕累托前沿的各种并行配置。请注意,目前宽 EP 尚未用于任何数据点(即没有 EP 16、32 等配置)。
解析推理服务商的单元经济学
以下是 OpenRouter 上所有服务 DeepSeek R1 0528 FP8 的推理服务商列表,包含其每百万输入/输出 token 的成本和平均交互性。排除 Chutes 后,中档服务商的交互性约为 35 tok/s/user。
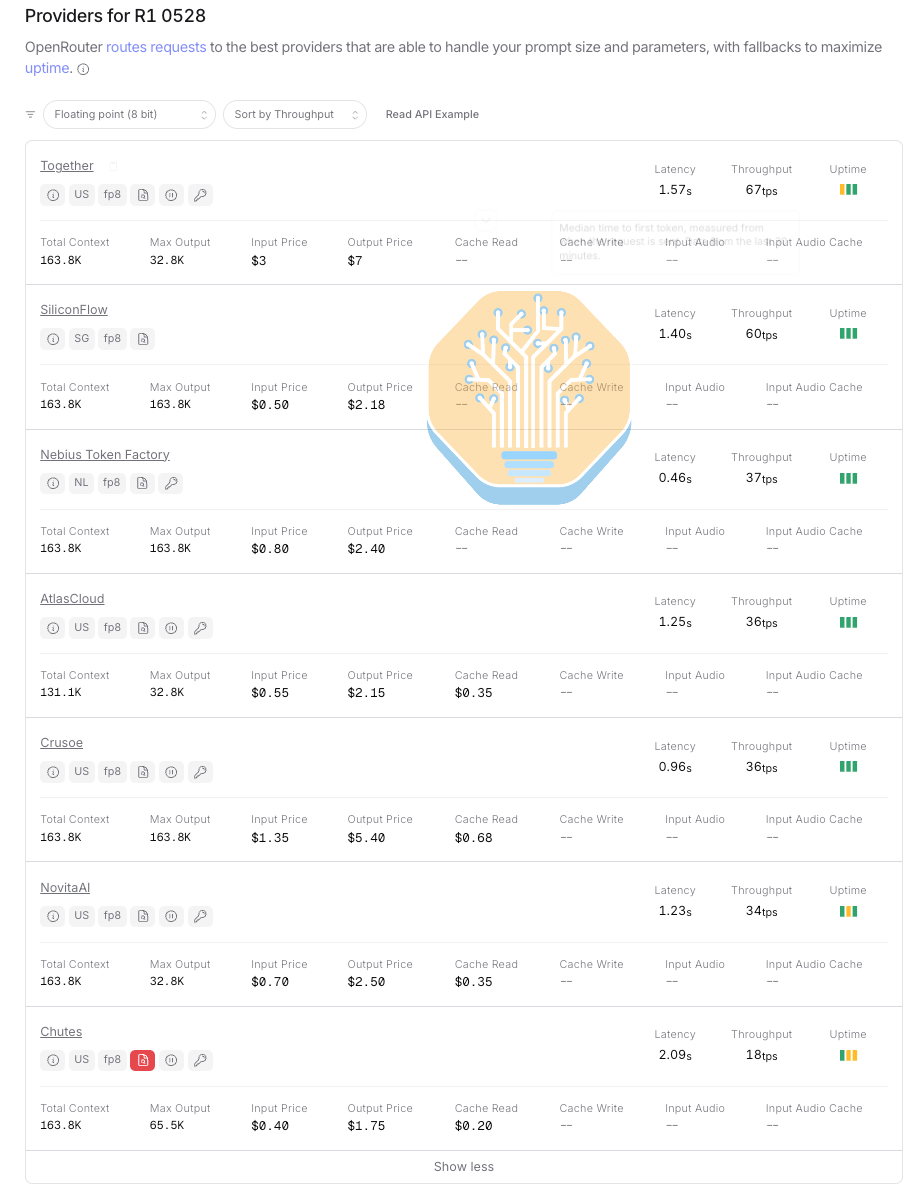
接下来,我们可以使用真实的 InferenceX 数据来插值计算 35 tok/sec/user 交互性水平下每百万输入/输出 token 的成本,鉴于上述数据,这是一个合理的交互性水平。
正如我们在文章后面提到的,这最好被理解为基线数据,并不完全代表真实世界的推理场景,主要因为 InferenceX 使用随机数据进行基准测试并禁用了前缀缓存。换句话说,实际的性能/成本至少能达到这个水平。同样值得注意的是,并非每个 GPU 在每个交互性水平都有数据点。因此,我们无法在每个交互性级别进行精确比较。尽管如此,我们认为下面呈现的柱状图比较是(非常)合理的插值替代精确数据点的方式。
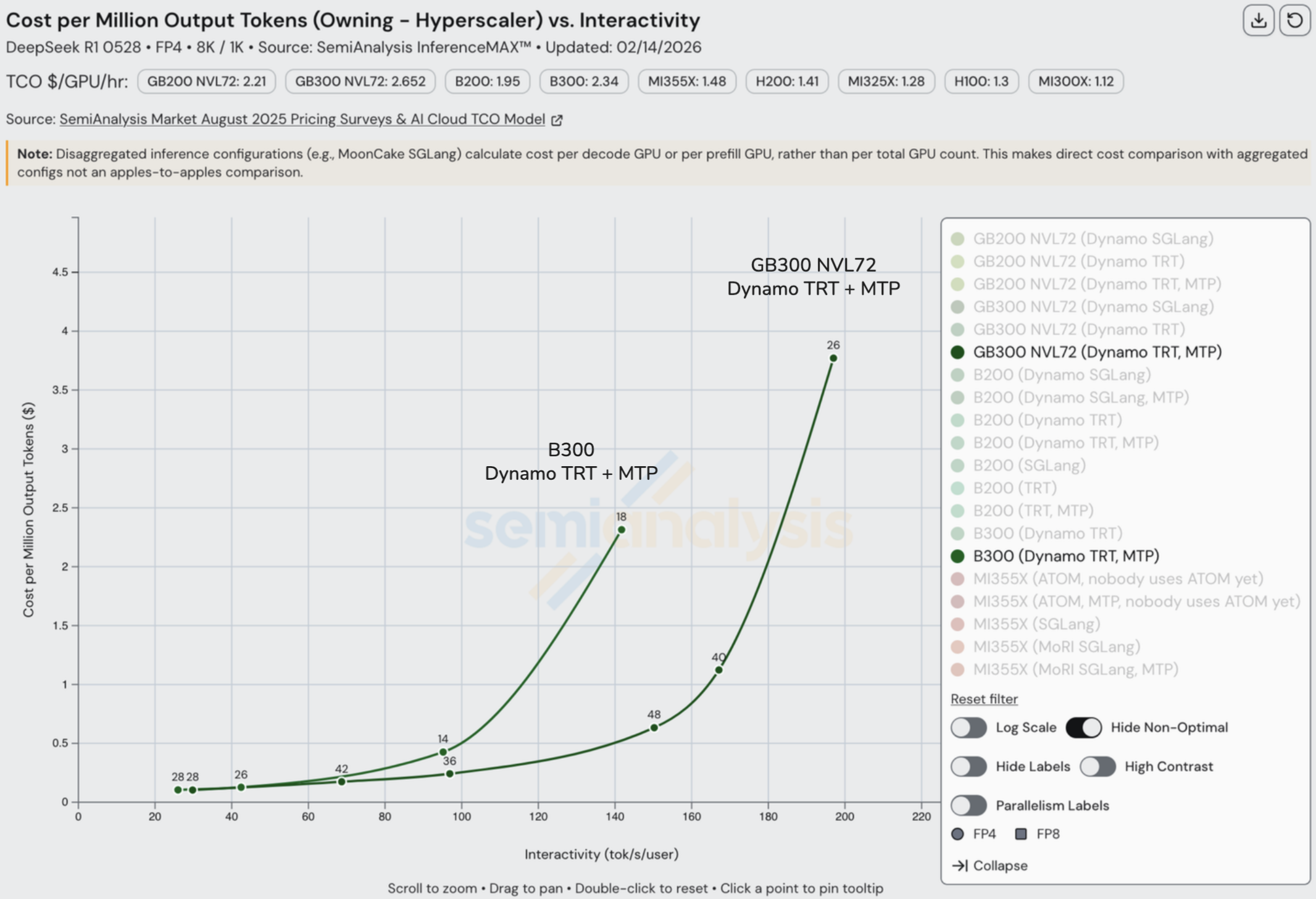
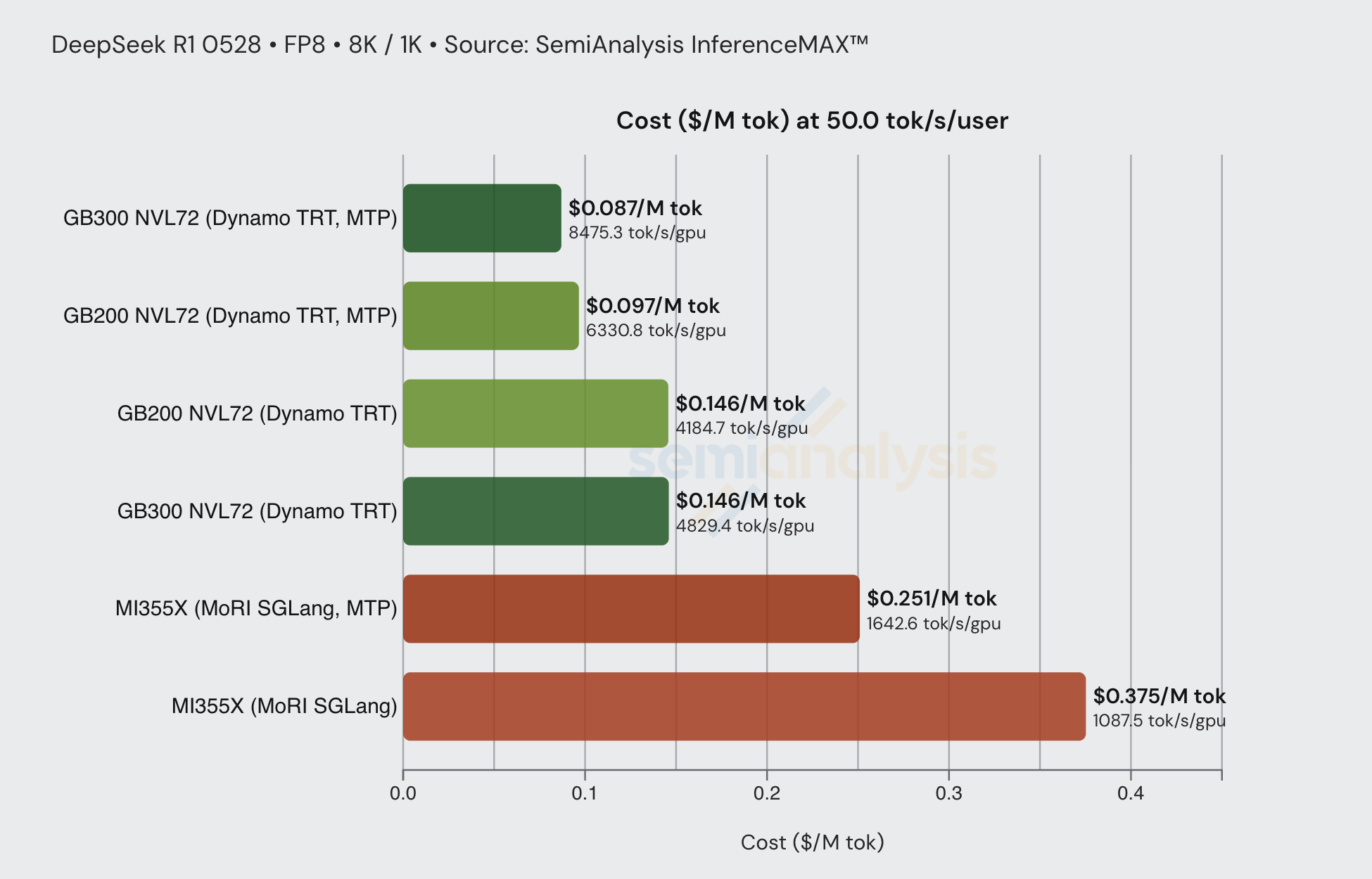
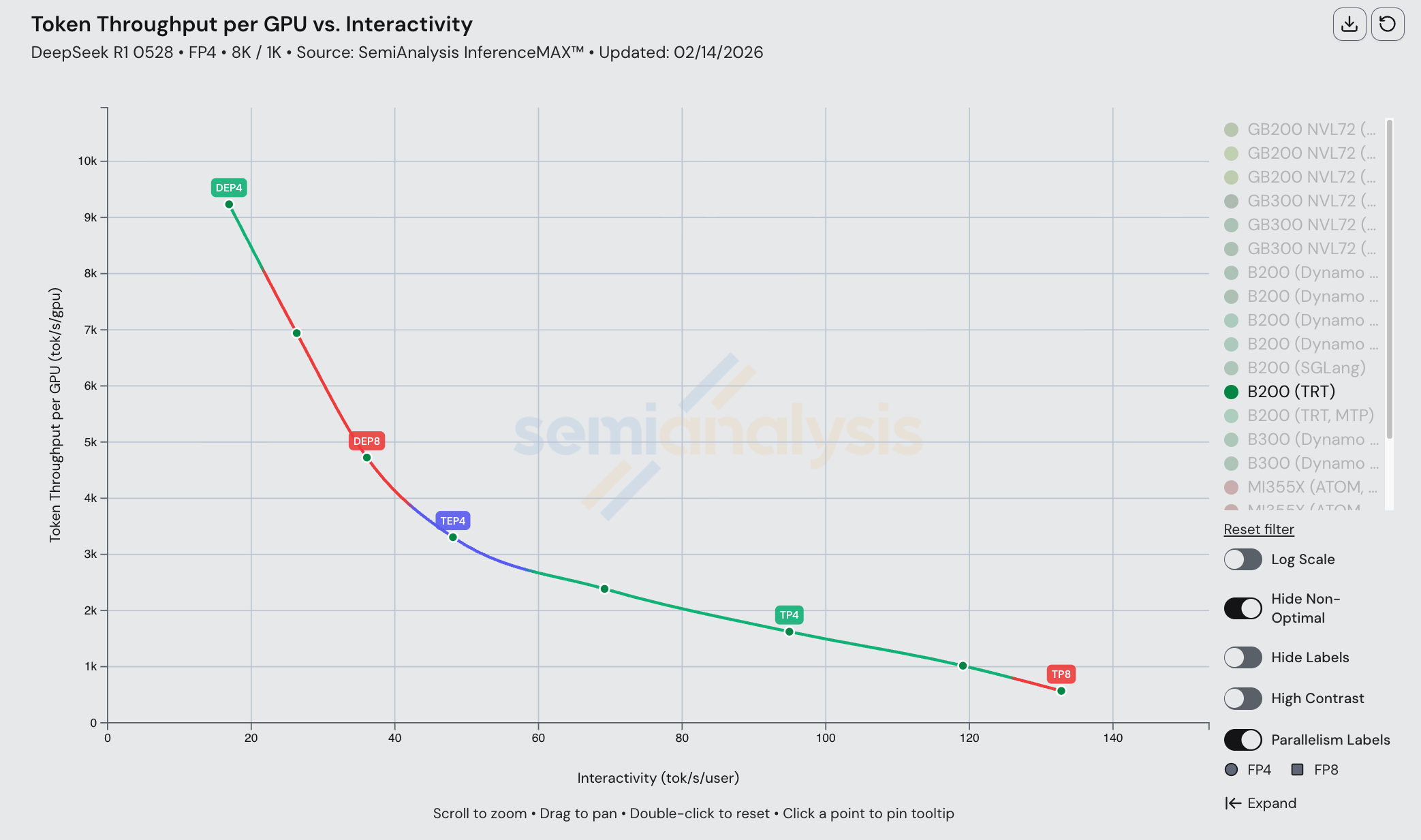
比较该交互性水平下的 disagg+wideEP 配置,我们可以看到分布式推理技术在性价比和整体吞吐量方面的显著效果。我们还看到大规模扩展域(如 GB300 和 GB200 NVL72)在每 GPU 总吞吐量上的绝对主导地位。
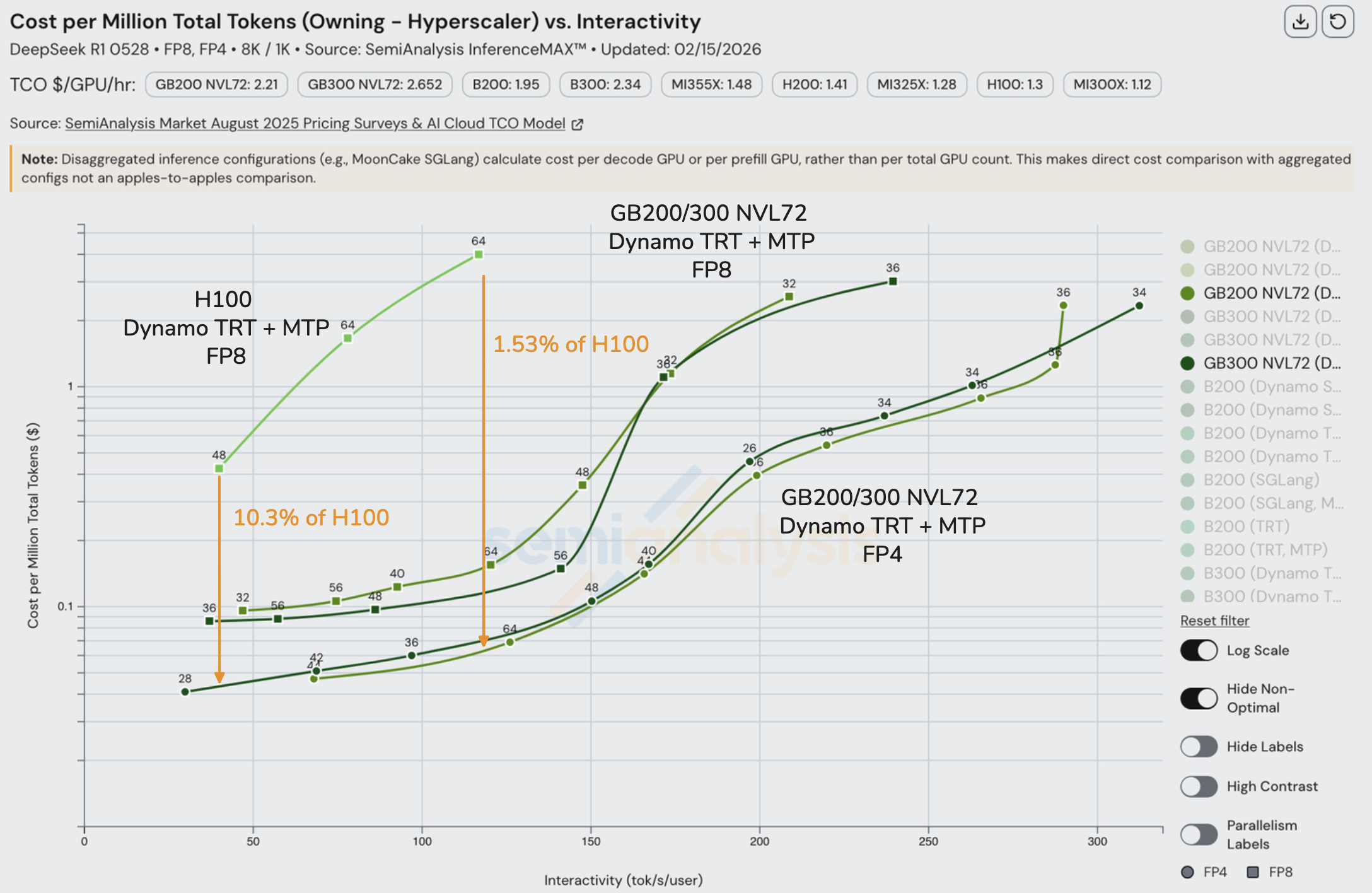
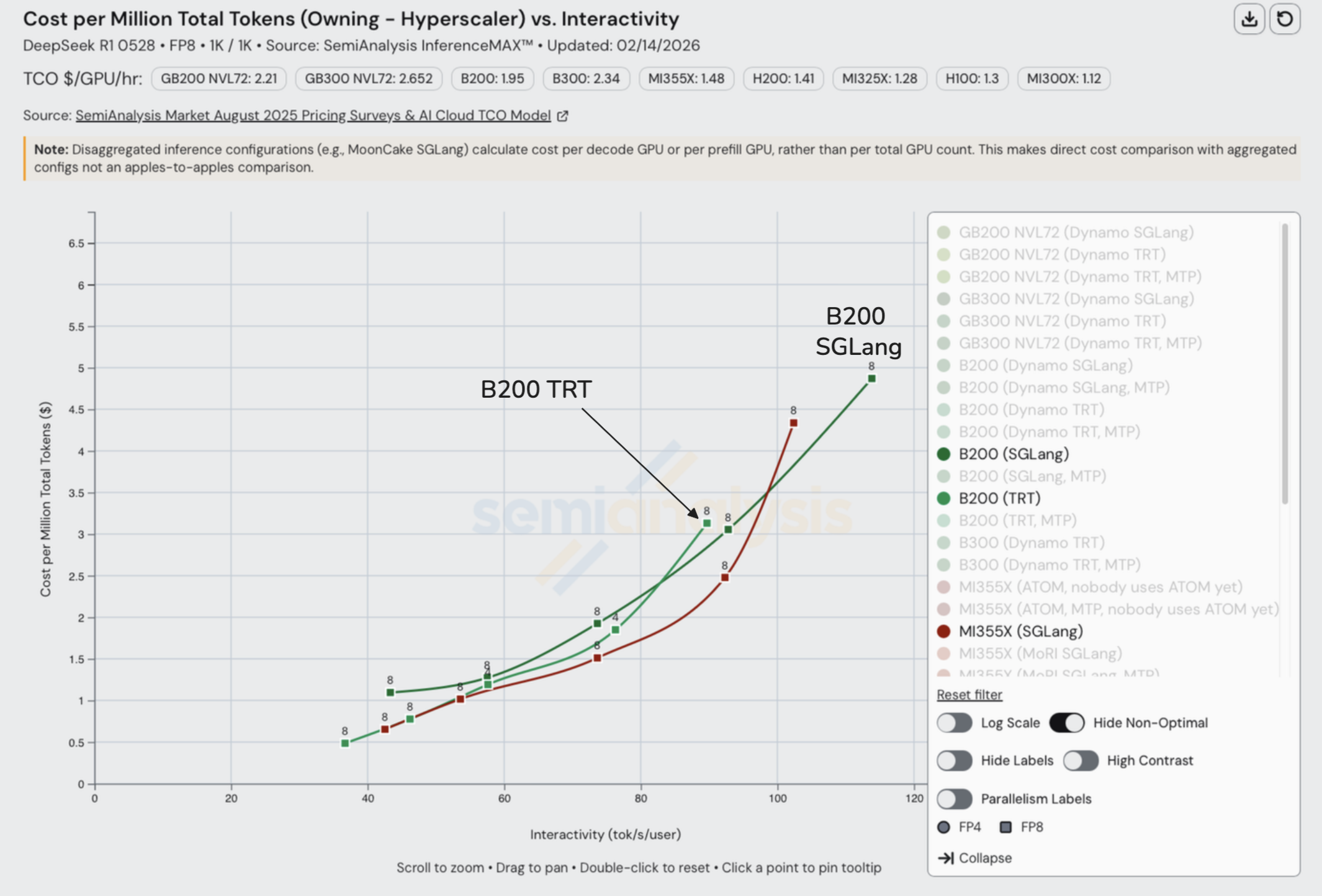
值得注意的是,在该交互性水平下(8k1k 工作负载类型),启用 MTP 的 B200 能够实现最佳性价比。以下我们还列出了每种 GPU 的总拥有成本(TCO)(自有 - 云服务商):

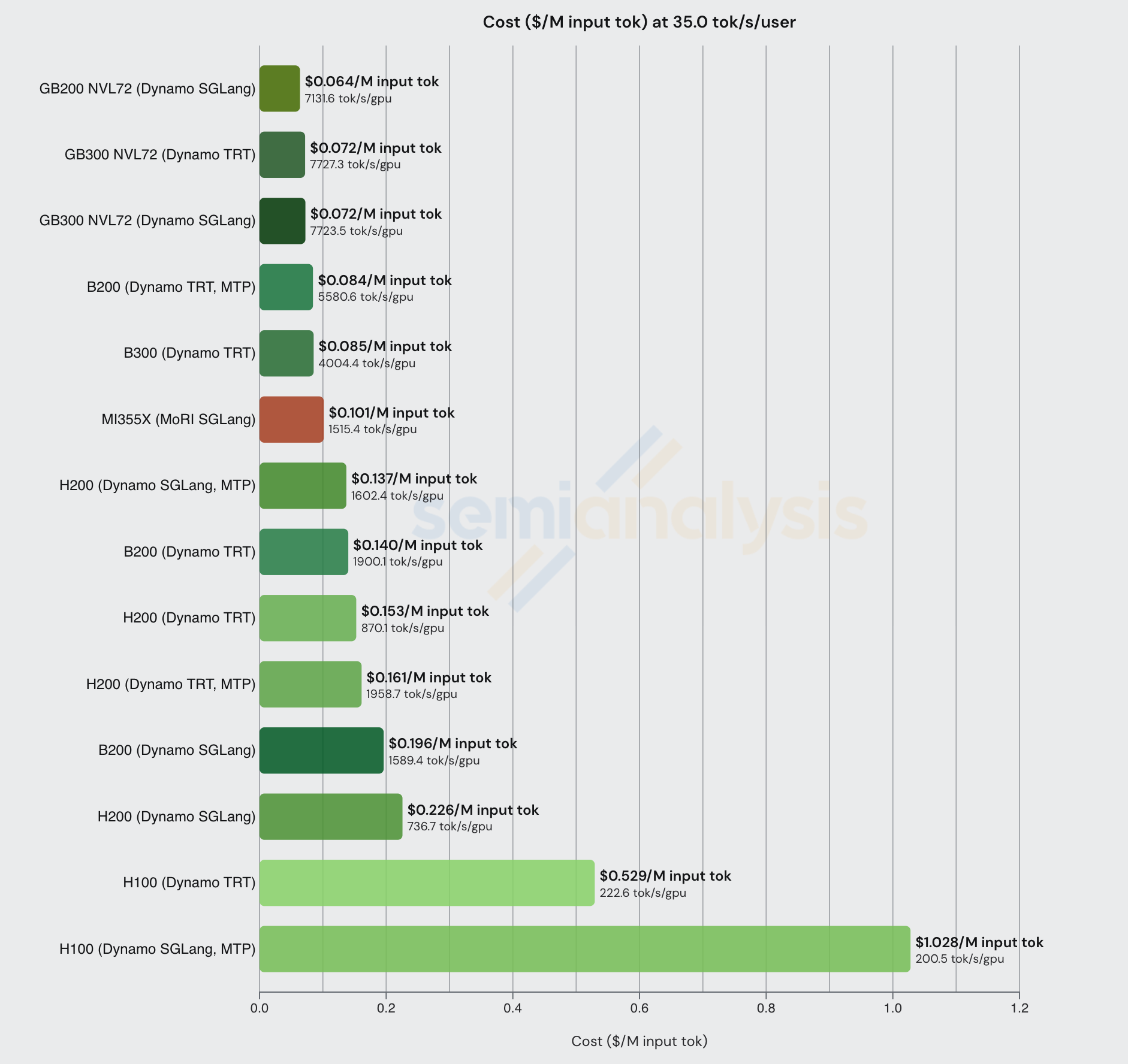
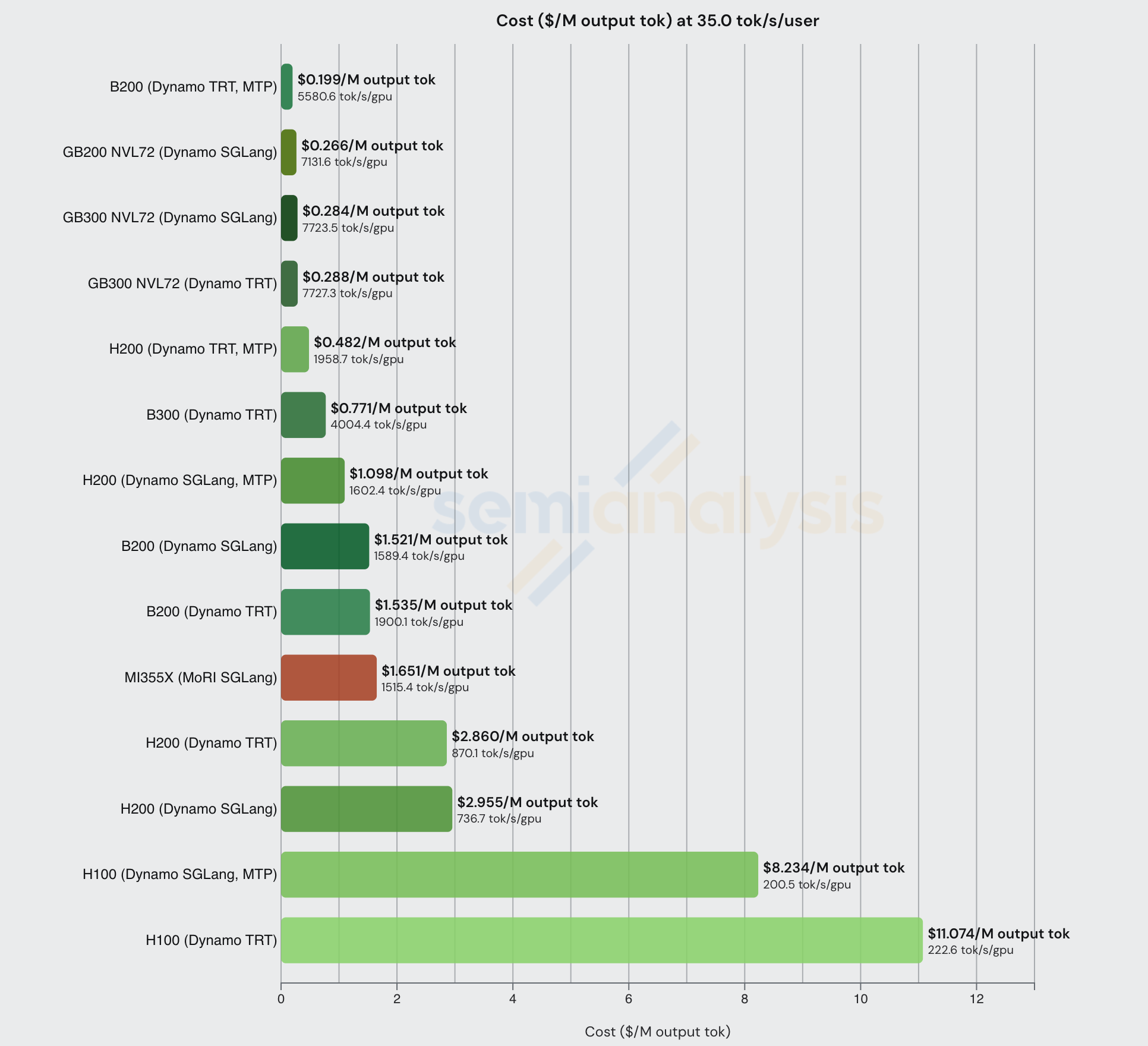
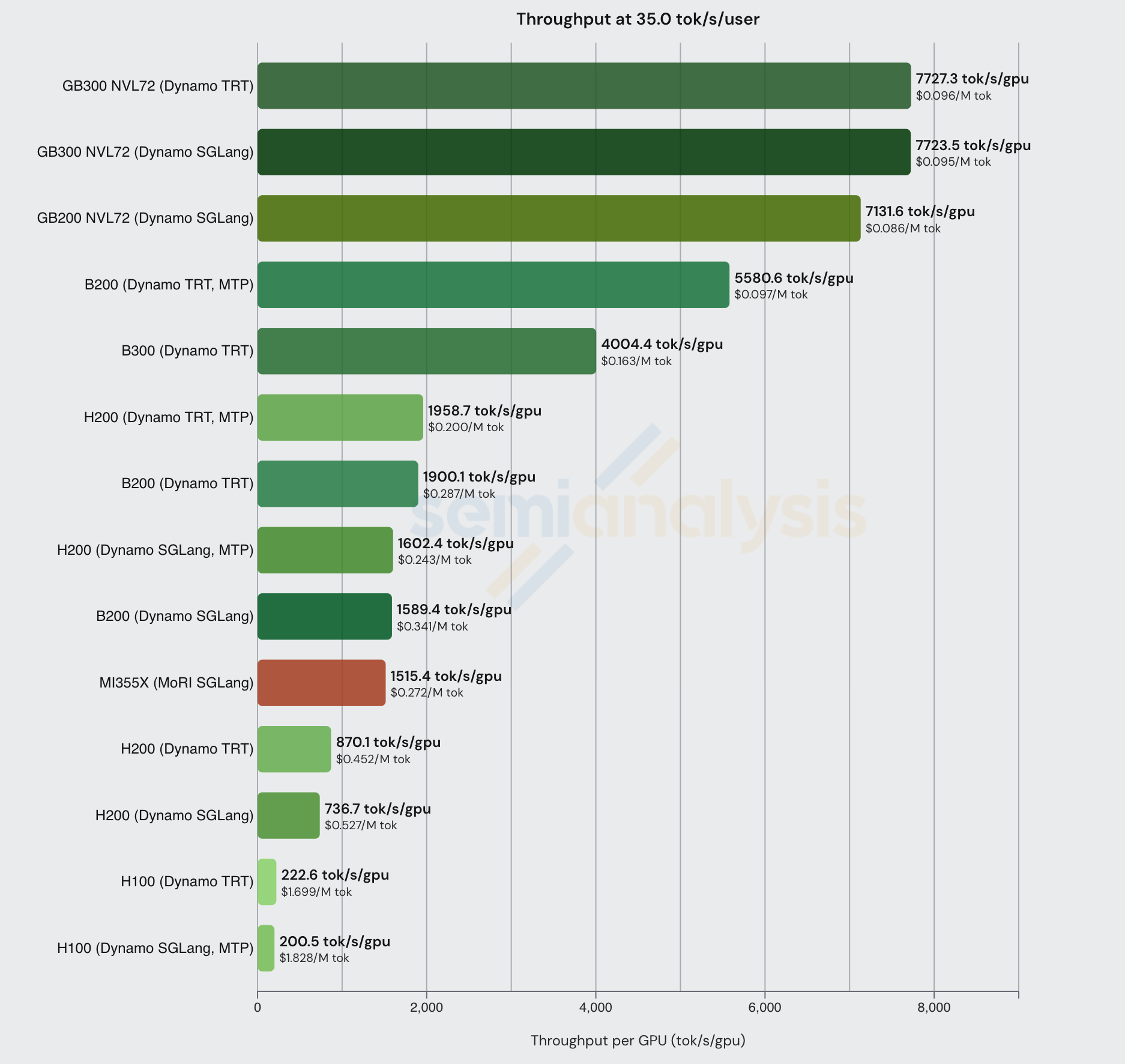
让我们利用上述发现深入分析大规模 LLM 服务的单元经济学。从上面的 OpenRouter 数据可以看到,Crusoe 以 36 tok/sec/user 的交互性提供服务,输入 token 价格为 $1.35/M,输出 token 价格为 $5.40/M。如果我们假设没有缓存命中,并且 Crusoe 至少使用了配备 MTP、disagg 和宽 EP 等 SOTA 推理技术的 H200,上述数据表明他们的成本不超过 $0.226/M 输入 token 和 $2.955/M 输出 token,输入 token 的利润率高达 83% 毛利率(折旧计入销售成本),输出 token 的毛利率为 45%。
当然,这些假设可能不完全正确,且这些计算没有考虑停机时间或利用率不足的情况,但这展示了使用 InferenceX 数据可以进行的一些有趣分析。更多关于推理经济学的分析可以在 SemiAnalysis Tokenomics Model 中找到。
OpenRouter 数据还显示 Nebius AI Studio (Fast) 以 167 tok/sec/user 的交互性提供 DeepSeek FP4 服务,输入 token $2/M,输出 token $6/M。相应调整 InferenceX 中的交互性水平,我们可以看到以下数据。
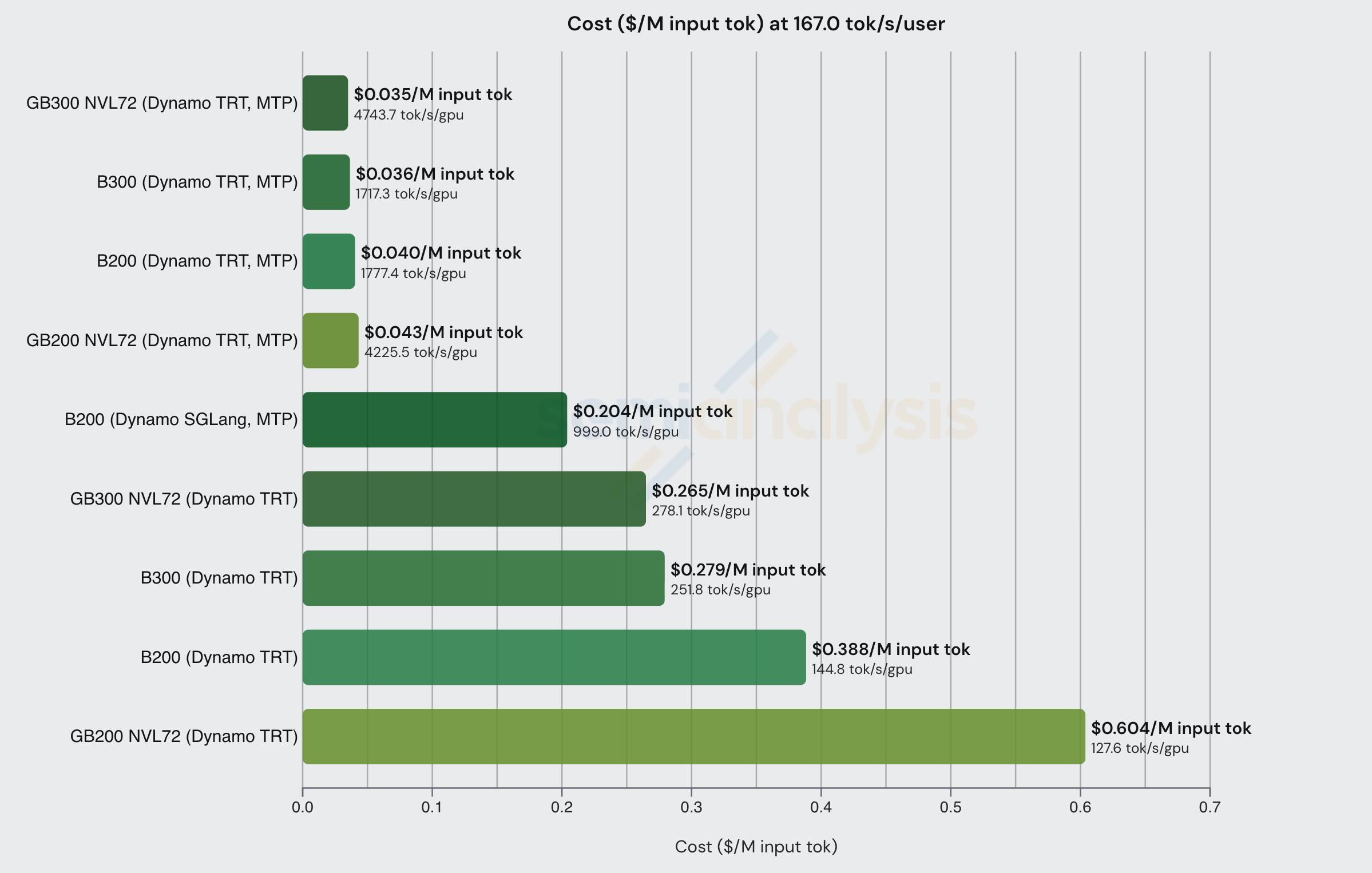
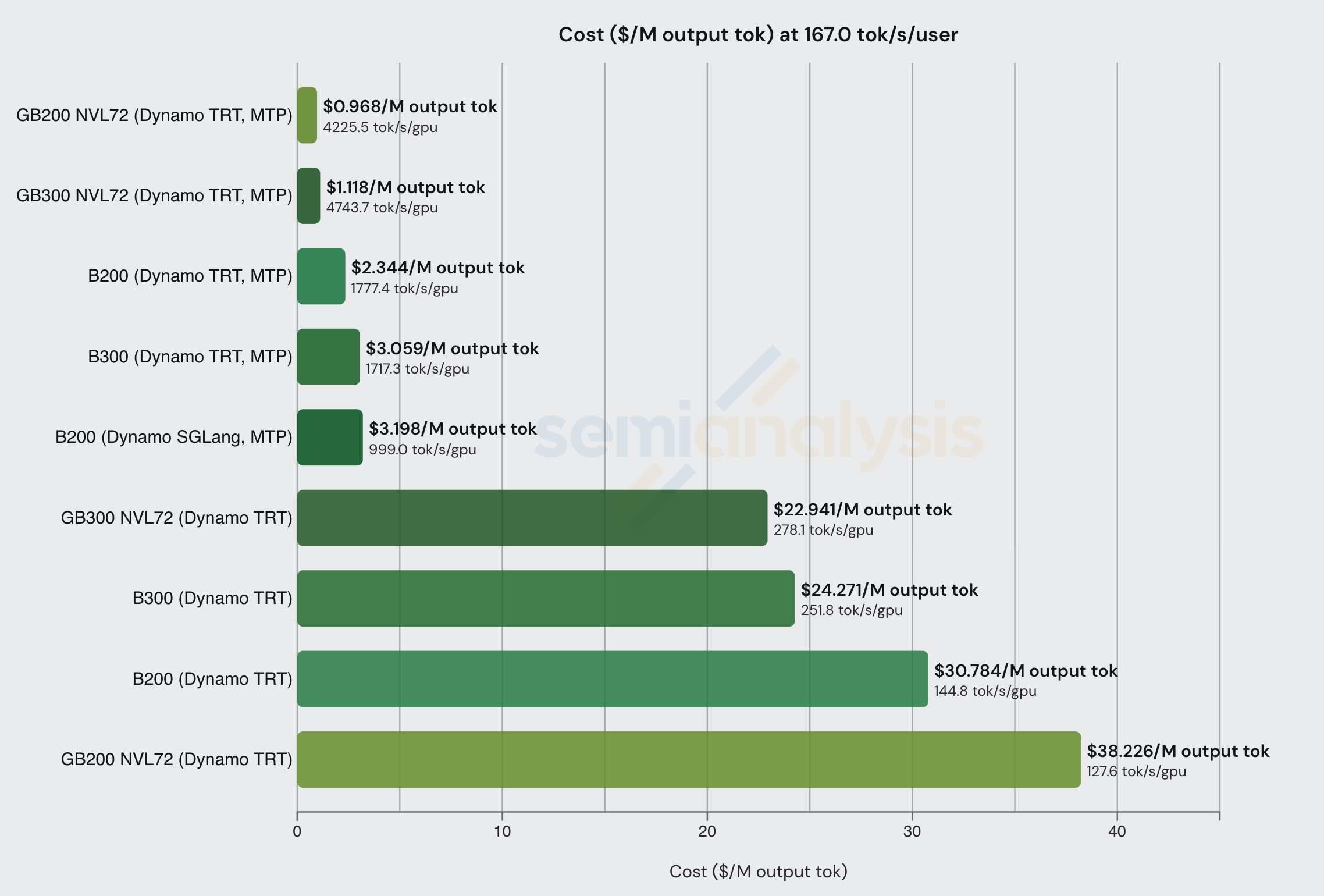
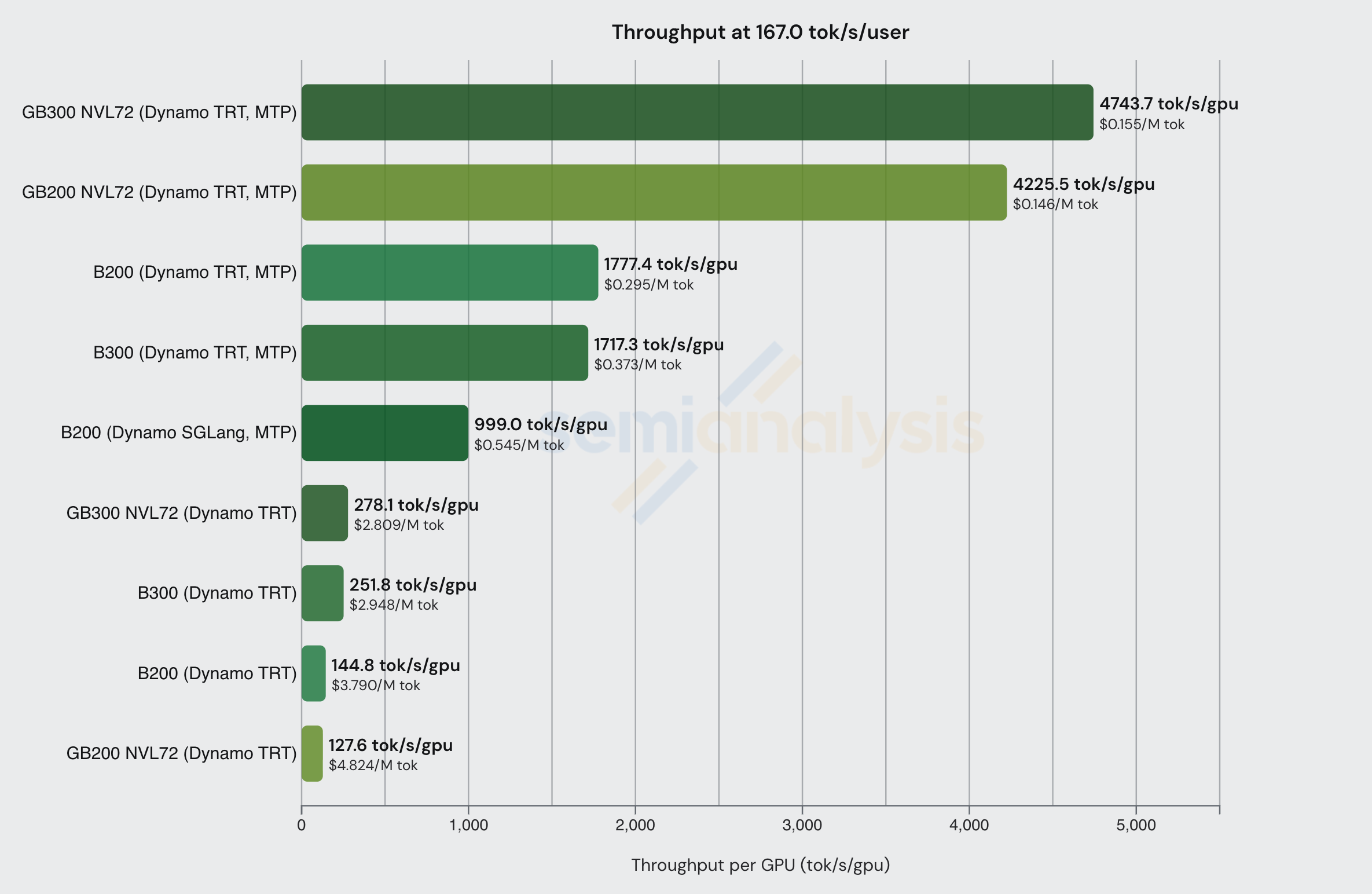
在如此高的交互性下,有必要采用 MTP 等推测解码技术来实现足够高的吞吐量,使推理具有经济可行性。幸运的是,MTP 能够在对模型精度影响极小的情况下提升吞吐量。我们将在文章后续部分进一步讨论 MTP 及其如何用于提升吞吐量/降低成本。
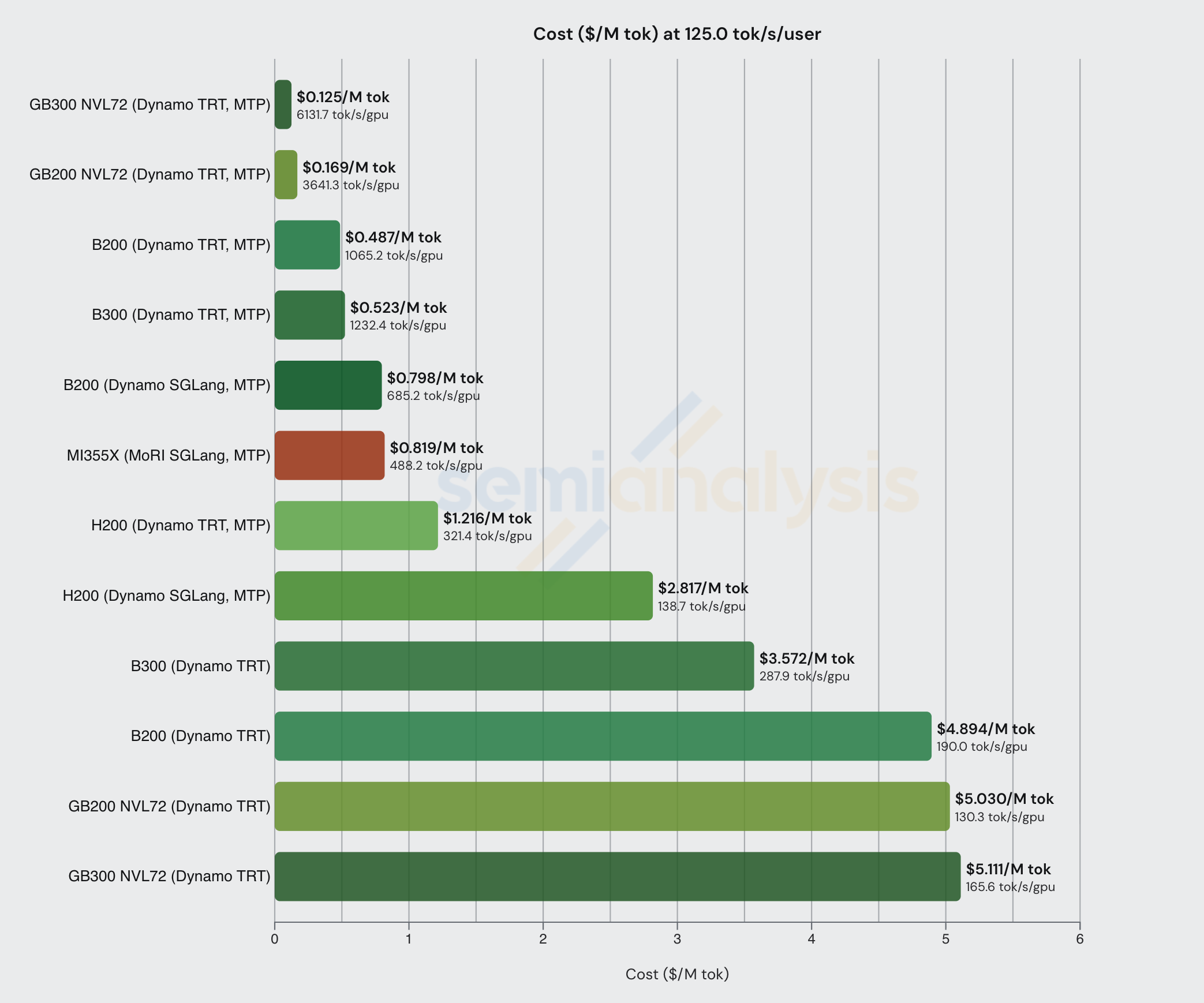
最后,我们再展示一张 FP8 DeepSeek 工作负载在 125 tok/s/user 下的图表。这是另一个低延迟工作负载,MTP 在其中显著改善了经济可行性。与前面的例子一样,我们注意到在这些较高交互性范围内,最便宜的配置都使用了 MTP。
NVIDIA 分离预填充与 WideEP
EP 需要 all-to-all 通信,每块 GPU 都需要向其他所有 GPU 发送 token。这对带宽需求极高。请回忆,NVIDIA 的服务器有两个独立的网络域——NVLink 扩展域(scale-up)和 Scale-out 域,后者通常使用 InfiniBand 或以太网作为网络协议。
- NVLink 域(NVL72 机架内):72 块 GPU 通过 NVLink 连接,每 GPU 单向带宽 900 GB/s。这大约是基于 InfiniBand/以太网的 Scale-out 网络带宽的 7-10 倍。
- InfiniBand/RoCEv2 以太网(NVL72 机架外):通常每 GPU 单向 400-800 Gbit/s(50-100 GB/s)。请注意,我们对 NVIDIA 的所有测试都在基于 InfiniBand 的集群上进行。
TP 将每一层的权重矩阵分片到各 GPU 上。这意味着每一层的每个 token 最多需要两次 all-reduce 通信(列并行 GEMM 后一次,行并行 GEMM 后一次)。对于 EP,all-to-all 仅在 MoE 层执行。每块 GPU 只发送被路由到相应专家的 token。这意味着与 TP 相比,EP 在所有层的通信成本更低。
由于 EP 的 all-to-all 通信带宽需求随参与者数量增长,在跨越较慢的 IB/以太网网络之前尽量保持在高带宽 NVLink 域内是更好的选择。使用 NVL72,72 块 GPU 的 EP 可以在不离开 NVLink 的情况下完成,而前代产品(仅 8 块 GPU NVLink 域)只能在 8 块 GPU 之间以 NVLink 速度执行 EP,超出后就要使用较慢的 IB/以太网网络。
宽 EP 在权重加载效率方面也有重大优势。对于 DeepSeek R1 这样的模型,解码是内存带宽受限的:瓶颈在于 GPU 从 HBM 加载权重的速度。使用宽 EP(例如 DEP32),32 块 GPU 共同持有并加载一次 670B 权重,每块仅加载其分片(约 21B)。所有 32 块芯片的总 HBM 带宽被用于加载模型的单个副本。相比之下,使用更窄的 EP 配合更多 DP 副本(例如 5xDEP8),5 个副本中的每一个都需要完整的 670B 权重副本——系统中总共有 5×670B = 3.35T 的冗余权重加载。EP 将权重在芯片间分摊;DP 则复制它们。这就是为什么更宽的 EP(在 NVLink 等高带宽互连的支持下)能带来显著更好的每 GPU 吞吐量。
通常,在低并发度下 TP 更为合适,这主要是出于负载均衡的考虑。在小批次下,EP 会因 token 到专家的路由不均匀而导致部分 GPU 利用率不足、另一些则过载。TP 避免了这一问题,因为每块 GPU 持有每个专家的一个切片,始终获得等量的工作。在低并发度下,这种负载不均衡的代价超过了 TP 额外通信开销的成本。
在更高并发度下,这种权衡发生变化。较大的批次使专家激活分布更加均匀,EP 的通信和权重加载优势开始主导 TP 昂贵的逐层 all-reduce。在曲线中段,混合 TP+EP 配置在两方面取得平衡——在每个专家内使用小规模 TP 组实现负载均衡,同时在更大范围的 GPU 上使用 EP 来分摊权重并减少通信。
对于更高的交互性水平(小批次),大规模扩展世界往往不能带来更强的性能。B300 通过 IB 的 disagg 与 GB300 NVL72 的性能相同,因为工作负载受延迟限制而非带宽限制。NVL72 巨大的 NVLink 带宽优势并不重要,因为即使是慢得多的 IB 链路也不会被微小的 token 批次流量所饱和。
预填充/解码分离也发挥了重要作用。预填充是计算密集且突发的;解码是内存带宽受限且稳态的。当它们共享同一 GPU 时,会相互干扰,导致延迟抖动和容量浪费。将它们分离到专用 GPU 池,使每个阶段运行与其特性匹配的工作负载,从而提高有效利用率。这就是为什么分离式 B200 配置在吞吐量-交互性曲线中段优于单节点 B200。PD 分离结合跨更多 GPU 通过 IB 的更宽 EP 能比将两个阶段塞入单个 8-GPU 节点更高效地分摊权重。
附注:TogetherAI 的优秀推理工程师注意到多轮对话流量中一个模式,即首轮预填充的需求与后续轮次的预填充需求差异很大,通过对此进行分离实现了更好的首 token 延迟(TTFT)表现。
Jensen 低调承诺、超额兑现——Hopper vs Blackwell vs 机架规模 NVL72
在 GTC 2024 上,Jensen 在台上承诺从 H100 到 GB200 NVL72 将实现高达 30x 的性能提升,所有人都认为这是典型的营销包装,在现实世界中不可能实现。 许多人试图为这种"现实扭曲力场"贴上标签,以便开更多 Jensen 数学的玩笑。确实——我们曾指出 30x 性能差异的比较是将 H200 FP8 的最差情况与 GB200 FP4 的合理情况进行对比。
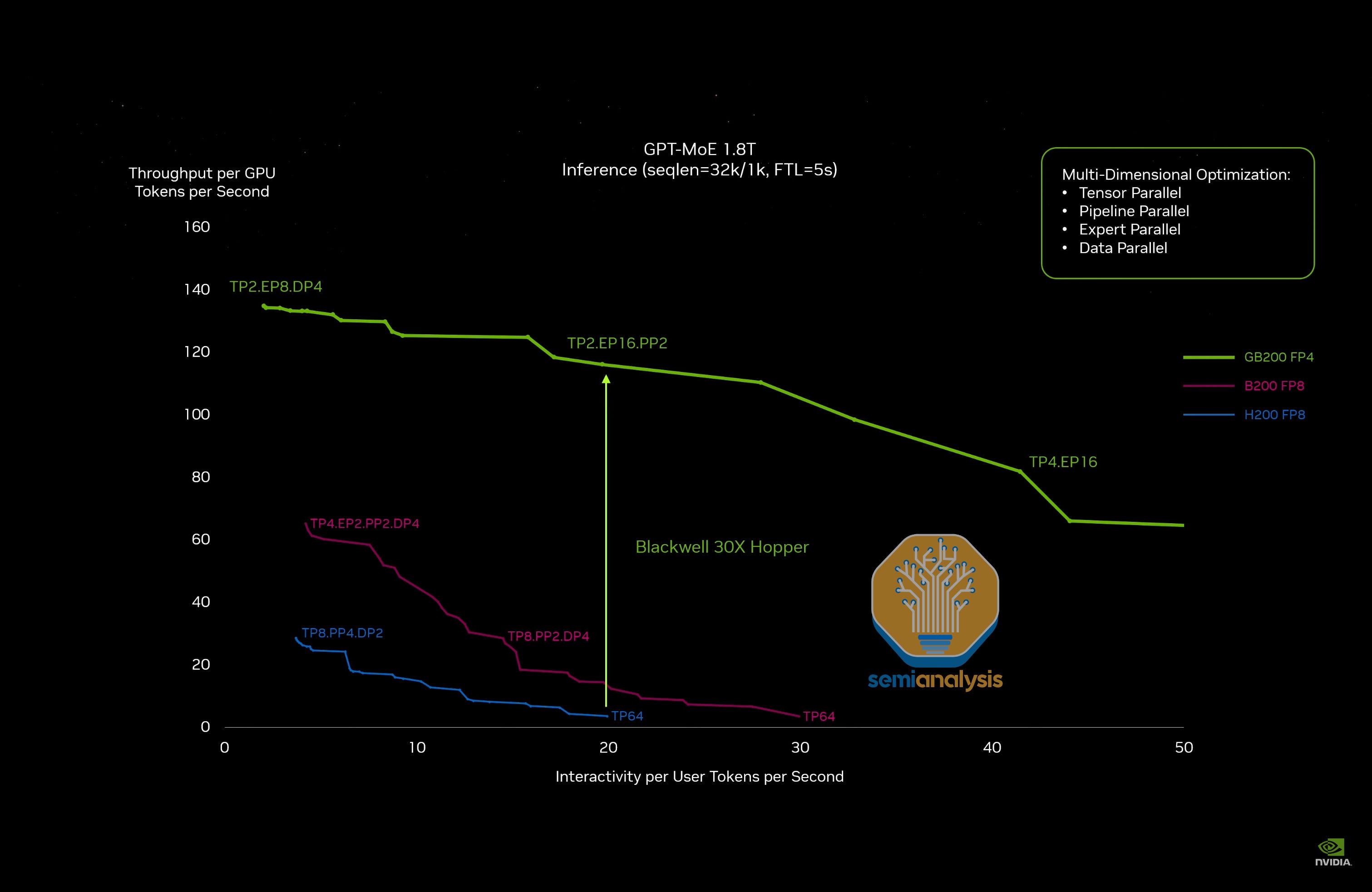
但事实证明,笑话在他们自己身上。快进将近两年后,我们现在可以看到这并非营销炒作,Jensen 实际上一直在低调承诺 Blackwell 的性能。根据我们的测试,相比强劲的 H100 disagg+wideEP FP8 基线,Blackwell 在大规模 MoE 推理上表现出色,在 116 toks/s/user 下,GB200 NVL72 FP4 达到了高达 98x 的性能提升,GB300 NVL72 FP4 更是达到了高达 100x!也许新的 Jensen 数学法则就是:在 token 吞吐量方面,他兑现的是承诺值的两倍。买得越多,省得越多!
即使考虑到 Blackwell 和 Blackwell Ultra 更高的总拥有成本,我们仍看到与 Hopper 相比 9.7x(40 tok/s/user)至 65x(116 tok/s/user)的每美元 token 提升。您可以在我们的免费网站上详细探索 Hopper vs Blackwell 的性能对比。Blackwell 相对 Hopper 的性能优势如此之大,以至于我们不得不在仪表板中添加对数刻度来进行可视化展示。
如前文所述,B300 服务器最多通过 900 GB/s/GPU 的 NVLink 扩展网络连接 8 块 GPU,而 GB300 NVL72 服务器通过 NVLink 扩展网络连接 72 块 GPU。因此,当我们的推理部署需要超过 8 块 GPU(但少于 72 块)时,需要引入多节点 B300 服务器来组成推理系统,这意味着通信退回到带宽较低的 InfiniBand XDR Scale-out 网络,每 GPU 提供 800 Gbit/s(单向)带宽。相比之下,机架规模的 GB300 NVL72 通过 NVLink 连接 72 块 GPU,提供每 GPU 900 GB/s(单向)带宽,我们可以看到机架规模服务器使推理系统中的 GPU 之间通信带宽比多节点 B300 服务器高出 9 倍以上。
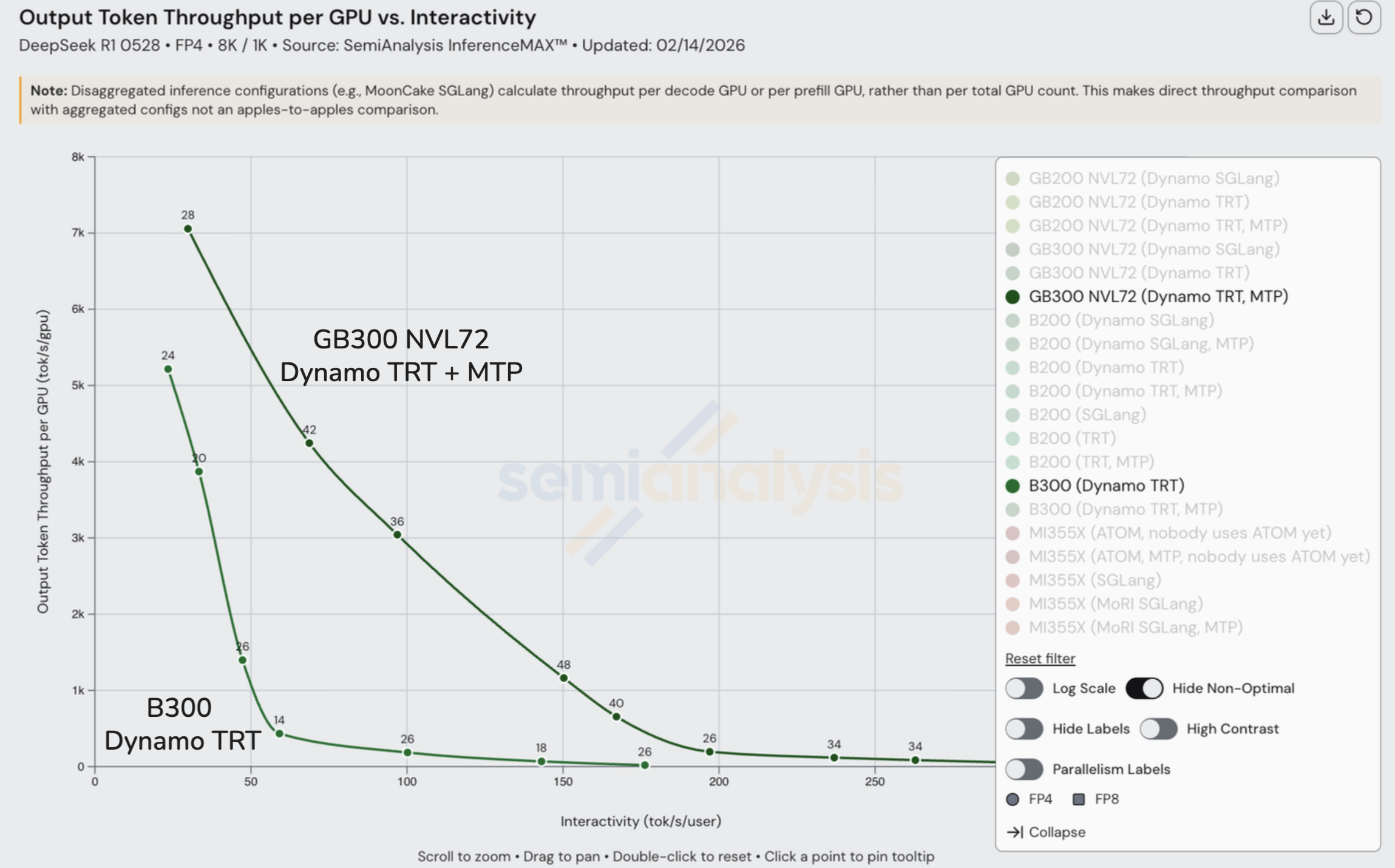
诚然 GB300 NVL72 的全口径每 GPU 成本更高,但这仅将带宽/TCO 优势降低到 8x 更快的水平。机架规模架构的带宽优势直接推动了更低的每 token 成本。Google TPU、AWS Trainium 和 NVIDIA 是目前仅有的部署了机架规模系统设计的 AI 芯片厂商。AMD 的首款机架规模 MI455X UALoE72 系统的工程样品和小批量生产将在 2026 年下半年完成,而由于制造延迟,大规模量产和首批生产 token 要到 2027 年 Q2 才能在 MI455X UALoE72 上产生。
Blackwell vs Blackwell Ultra
在纸面参数上,新发布的 Blackwell Ultra 与 Blackwell 拥有相同的内存带宽和 FP8 性能,FP4 性能仅高 1.5x,但在实际测量中,我们发现 Blackwell Ultra 的 FP8 性能比 Blackwell 好了多达 1.5x,不过 FP4 仅好了 1.1x。这可能是因为 Blackwell Ultra 作为新发布的 GPU,软件尚未完全优化。
MI355X vs MI325X vs MI300X
在 AMD SKU 上,我们看到 MI355X 相比 MI300X 性能提升高达 10x。AMD 目前仅在 MI355X 上成功运行了 DeepSeek SGLang 分离式推理,尚未提交 MI300X 或 MI325X 的分离式推理结果,可能是由于旧 SKU 上的软件问题仍在解决中。
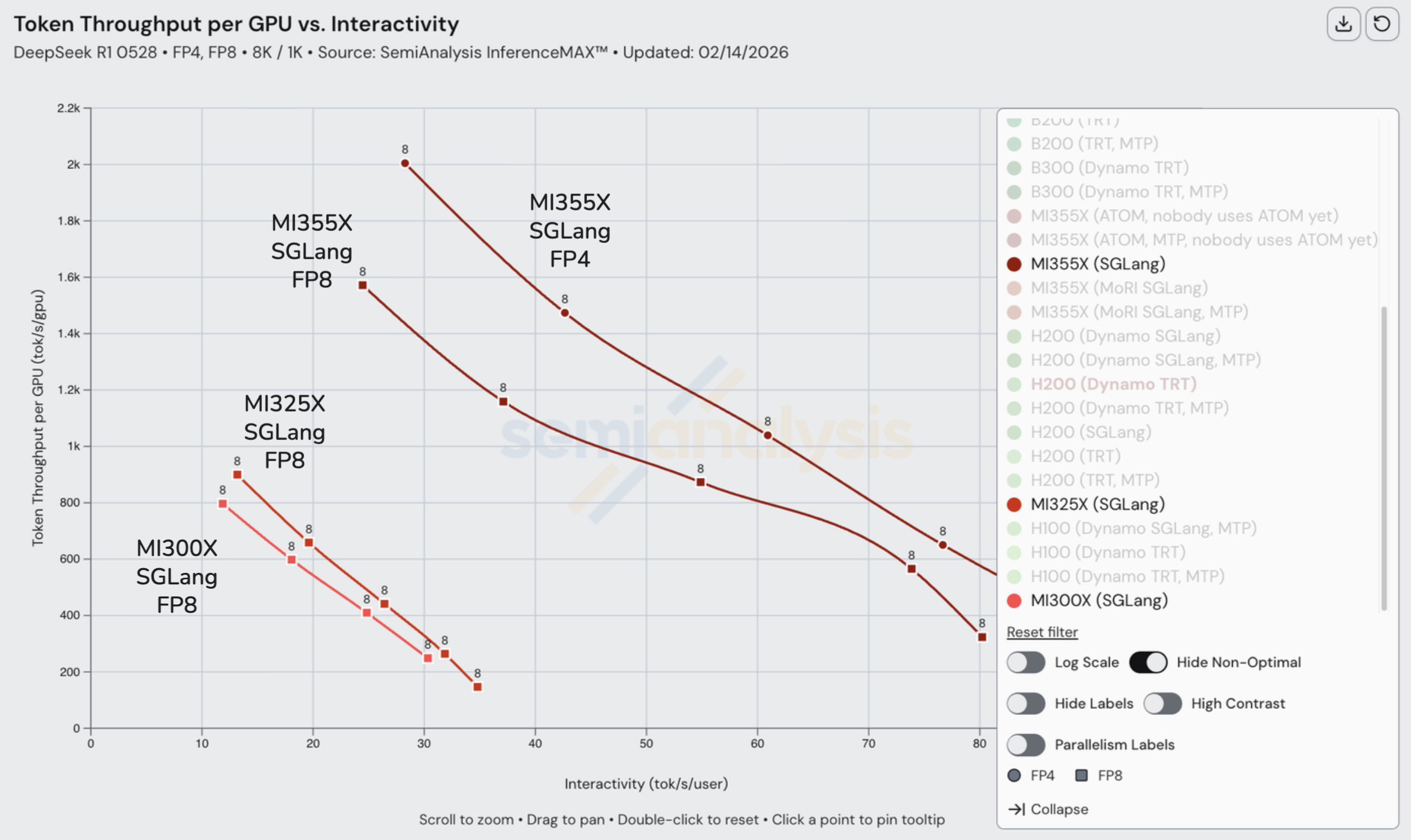
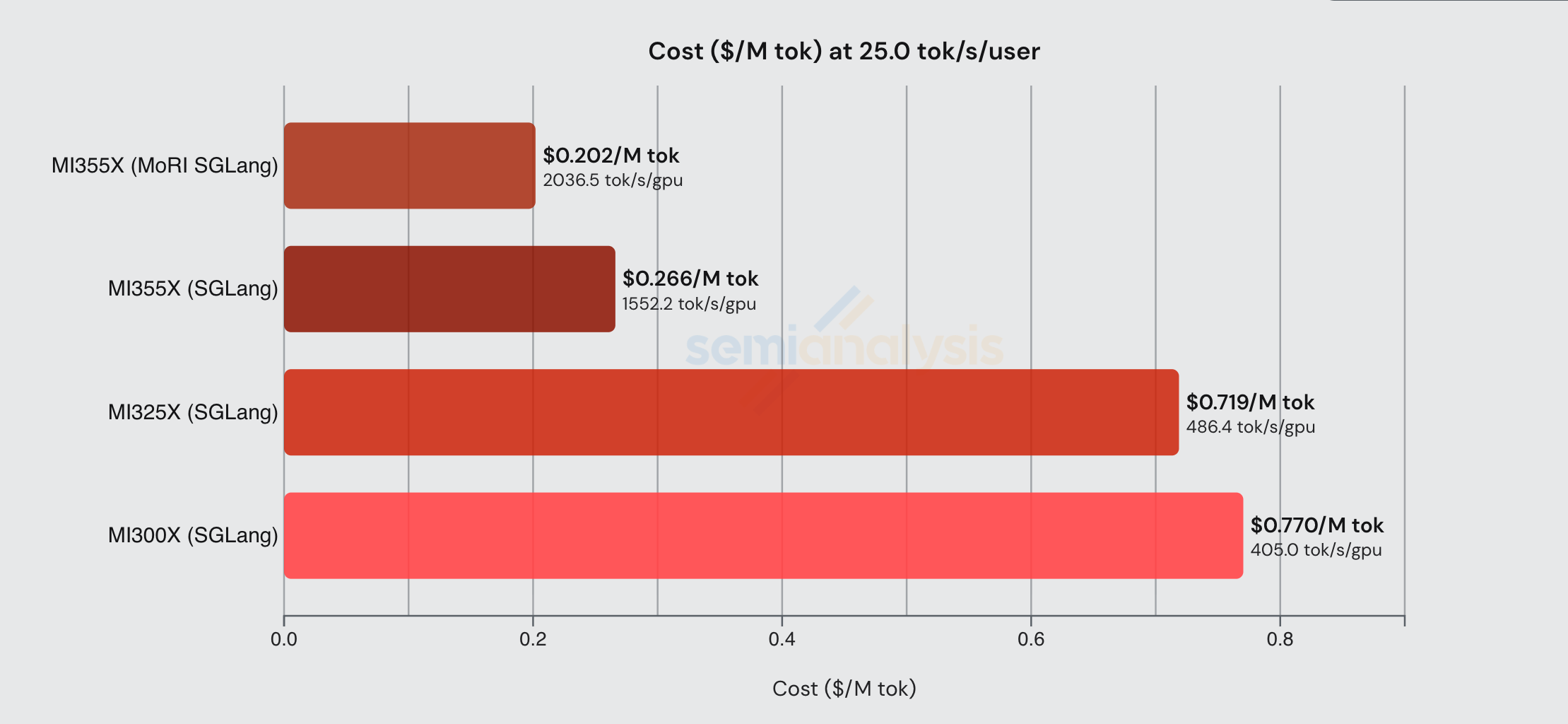
从成本角度来看,对于 FP8 的 DeepSeekR1,在 24 tok/s/user 的交互性水平下,MI355X 的推理成本比 MI325X 便宜略低于 3 倍。每 GPU 的吞吐量略低于 MI325X 的 4 倍。
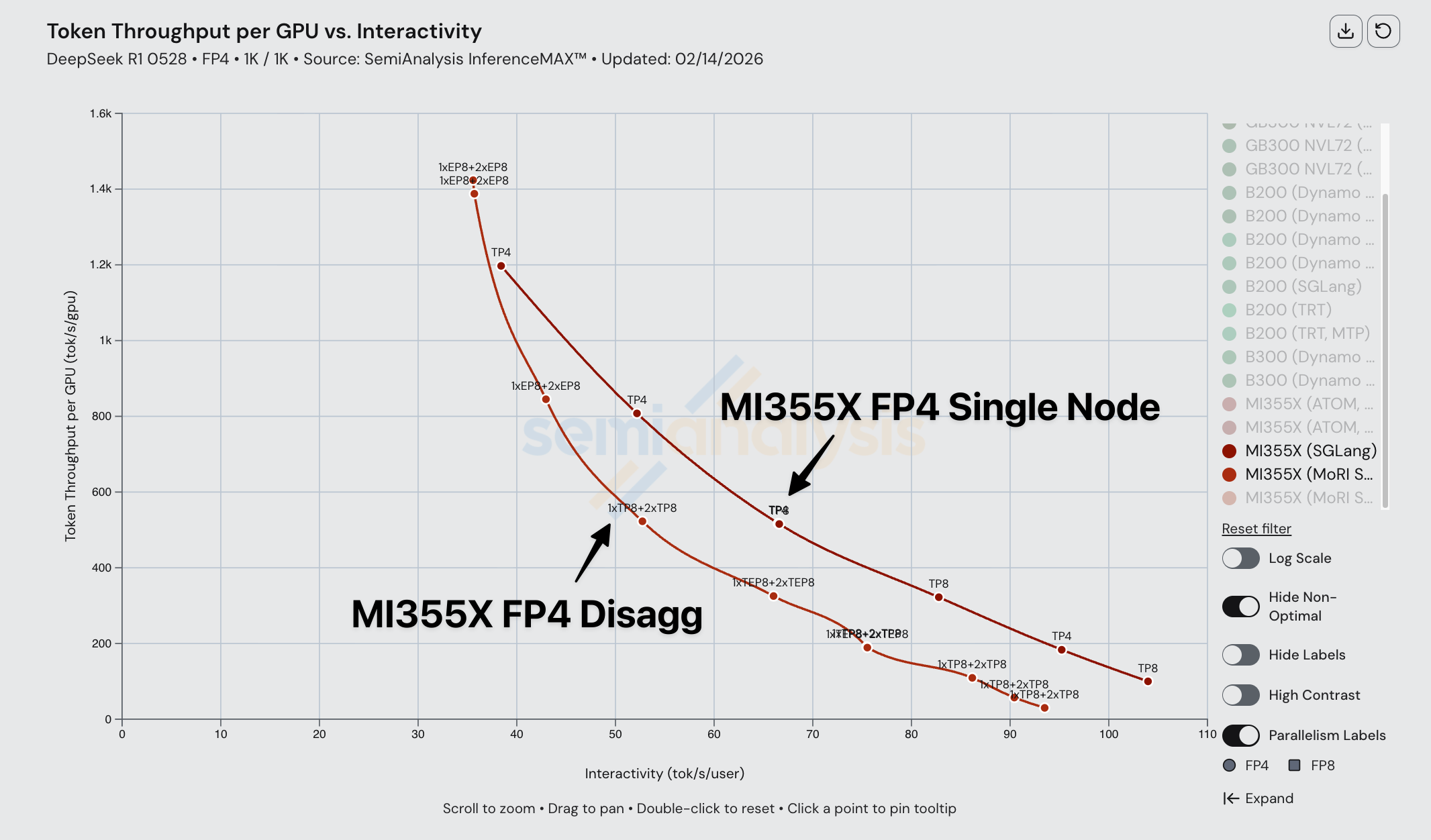
AMD 在 FP4、分布式推理与宽专家并行上的可组合性问题
虽然 AMD 在单节点 FP4 上表现尚可,在 FP8 分布式推理上与 B200 SGLang 具有竞争力,但当前 AMD 开源推理栈的问题在于:虽然各个推理优化单独表现良好,但实际客户部署时会将多种优化组合使用。顶级 AI 实验室都同时启用 FP4 配合分离式推理配合宽专家并行,问题正出在这里。
AMD 软件仍未达标,SemiAnalysis 和 AMD 内部的理论极限建模都表明,对于 FP4,分离式推理配合宽专家并行应该优于 MI355X 单节点推理。遗憾的是,软件仍然是 AMD GPU 的巨大瓶颈。AMD 管理层需要继续优化工程人才的资源配置——例如,将工程资源从无人使用的单节点宠物项目(如 ATOM)转移到修复上述推理优化可组合性问题上。当前不佳的软件表现源于缺乏聚焦和优先级设置不当。所有顶级实验室已在使用分离式推理和宽专家并行;AMD 需要停止专注于单节点,大力投入多节点推理的开源方案。
AMD 在开源分布式推理、宽专家并行和 FP4 可组合性方面落后超过六个月,NVIDIA 和 SGLang 团队六个月前就已展示了他们在 DeepSeek 上的 NVFP4 性能。
AMD ATOM 引擎
AMD 推出了名为 ATOM 的新推理引擎。ATOM 能提供略好的单节点性能,但在许多关键功能上完全缺失,导致无法用于真实工作负载。例如,它不支持 NVMe 或 CPU KVCache 卸载、工具解析、宽专家并行或分离式服务。这导致生产环境中没有任何客户使用它。与 NVIDIA 的 TRTLLM 不同——后者在 TogetherAI 等公司全球范围内每小时生成数十亿 token,并且支持工具解析和其他功能——由于上述功能缺失,目前没有任何 token 工厂在使用 ATOM。
此外,vLLM 等开源推理引擎的维护者对 AMD 感到失望,原因是 AMD 提供的工程和 GPU 资源不足。例如,vLLM 首席维护者 Simon Mo 在 GitHub RFC 中表示,他仍然没有可用的 MI355X 来添加到 vLLM CI 中,因此用户体验不佳。vLLM 上目前没有任何 MI355X 测试,而 NVIDIA 的 B200 在 vLLM 上有大量测试。同样,vLLM 上的 MI300X CI 机器数量仍然不够。上游 vLLM 至少还需要 20 台 MI300 机器、20 台 MI325 机器和 20 台 MI355X 机器才能达到与 CUDA 相同的可用性水平。
在 SemiAnalysis,我们一直在推动 AMD 为 vLLM 贡献更多计算资源,并在最近几周取得了一些成果。vLLM 将开始获得几台 MI355X 机器,使其 CI 测试覆盖率从 0% 提升到非零水平。我们将在即将发布的"AMD 现状"文章中详细讨论 AMD 此前对 vLLM、SGLang、PyTorch CI 机器贡献不足的情况,以及 Anush 如何开始着手解决这一问题。在 SemiAnalysis,我们将建立内部仪表板来跟踪 AMD 和 NVIDIA 在 vLLM、SGLang、PyTorch 和 JAX 上运行的测试数量和质量。
此外,vLLM 维护者表示,由于机器资源不足,他们无法为 ROCm 提供首日 vLLM 支持。这一巨大的上市时间差距导致 ROCm 持续落后,给 NVIDIA 留下了继续收取高达 75% 毛利率(4 倍成本加价)的巨大空间。
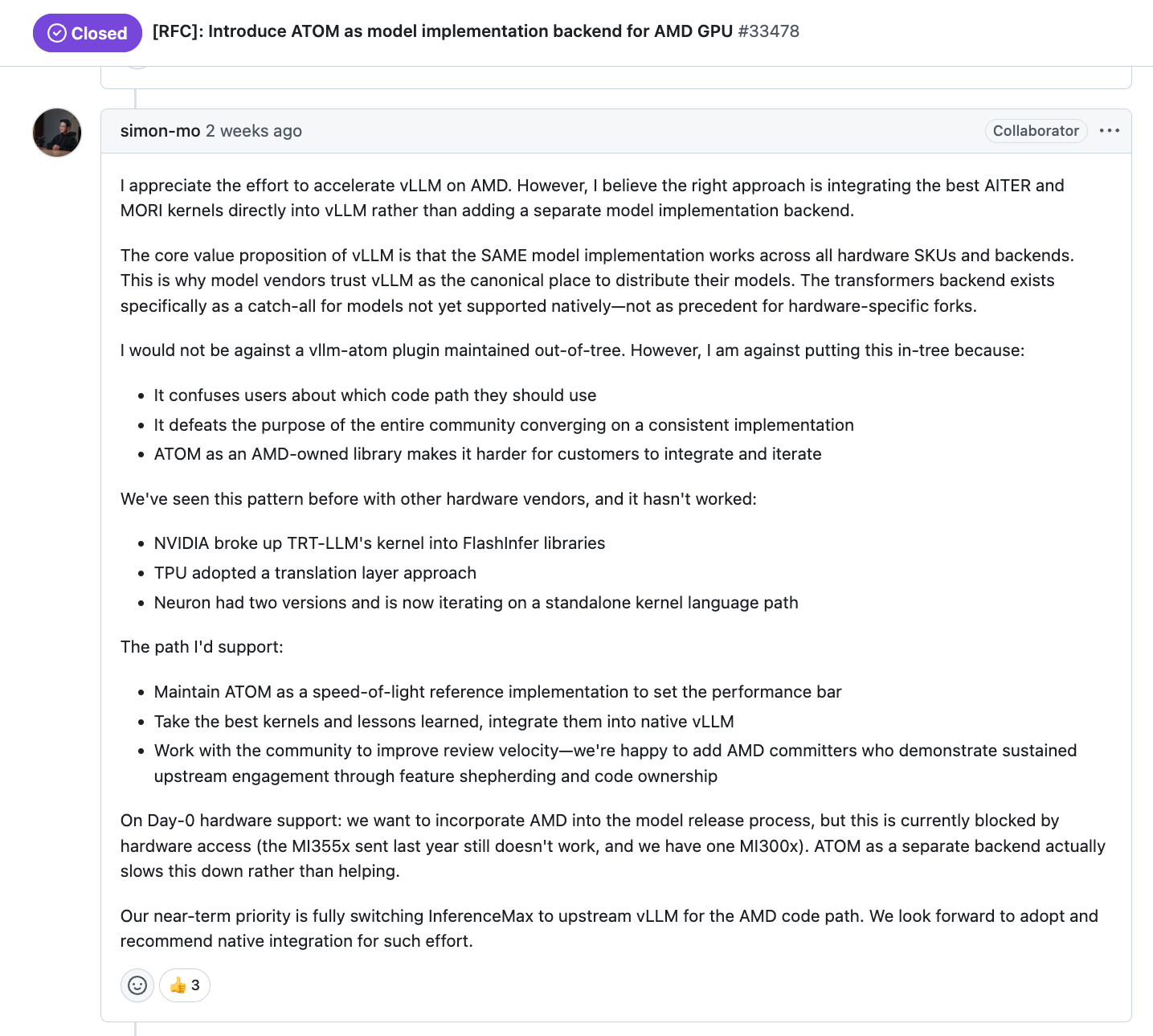
最后,AMD 没有足够的提交者"通过功能引导和代码所有权展示持续的上游参与",并且缺乏能审核自身代码的审稿人。这就是为什么 ROCm vLLM 的开发速度远慢于 CUDA vLLM。
AMD 有许多才华横溢的优秀工程师在 ATOM 上工作,我们鼓励 AMD 管理层考虑将这些优秀工程师重新部署到人们实际使用的库和框架上,如 vLLM 和 SGLang。
如前所述,AMD 还需要优先解决 FP4、wideEP 和分离式服务的可组合性问题,而不是过度专注于单节点的 FP4 优化。
多 Token 预测(MTP)
推测解码通过使用一个小型、低成本的草稿模型提前提议多个 token 来降低自回归生成的成本。大模型然后在一次类似预填充计算的前向传播中验证所提议的 token。对于给定的输入序列长度,当输入多出 N 个 token 时,单次前向传播的耗时大致相同。推测解码利用这一特性,在小模型上运行推理生成多个 token 供主模型在一次前向传播中验证,在相似的时间预算内最多额外产出 N 个 token。
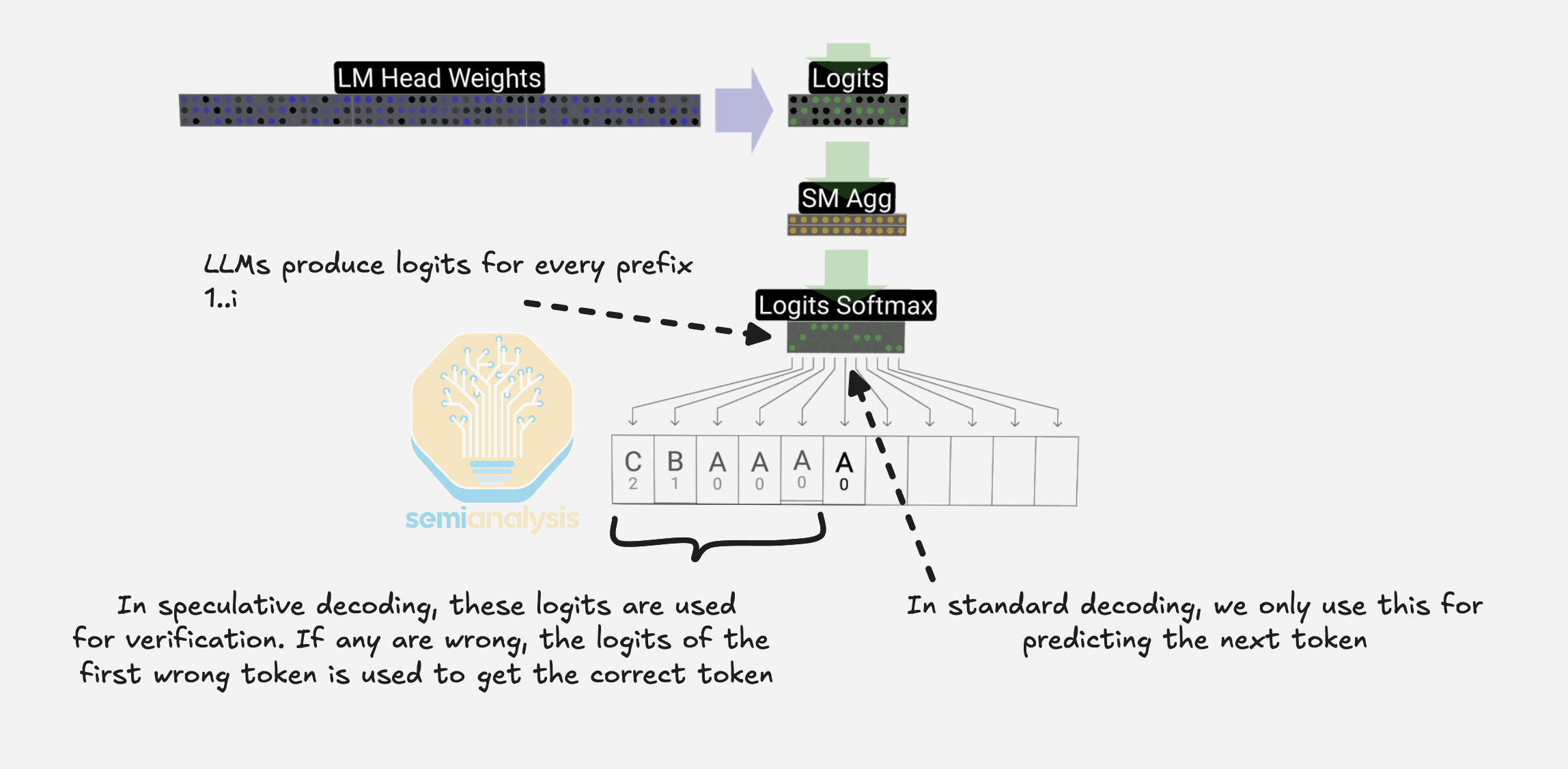
这一关于在相同时间预算内额外产出 token 的假设对于稠密模型最为成立,因为批量验证可以在多个位置复用相同的权重流。对于混合专家模型,不同的 token 可能路由到不同的专家,因此验证多个草稿 token 可能激活更多专家,迫使从内存获取额外的专家权重。正如 EAGLE 论文中 Mixtral 8x7B Instruct 模型的结果所示,这些额外的内存访问会削弱带宽节省,使验证与标准解码步骤的成本相当。
多 Token 预测在无需单独草稿模型的情况下追求类似的效益。模型架构中添加了辅助预测头,使单个模型能从同一底层表示中提议多个未来 token。这改善了分布对齐,因为提议来自最终进行评分的同一模型。多 Token 预测还避免了服务额外模型的运维复杂性,同时仍然支持多 token 生成策略,但要求 MTP 头与主模型一起预训练。
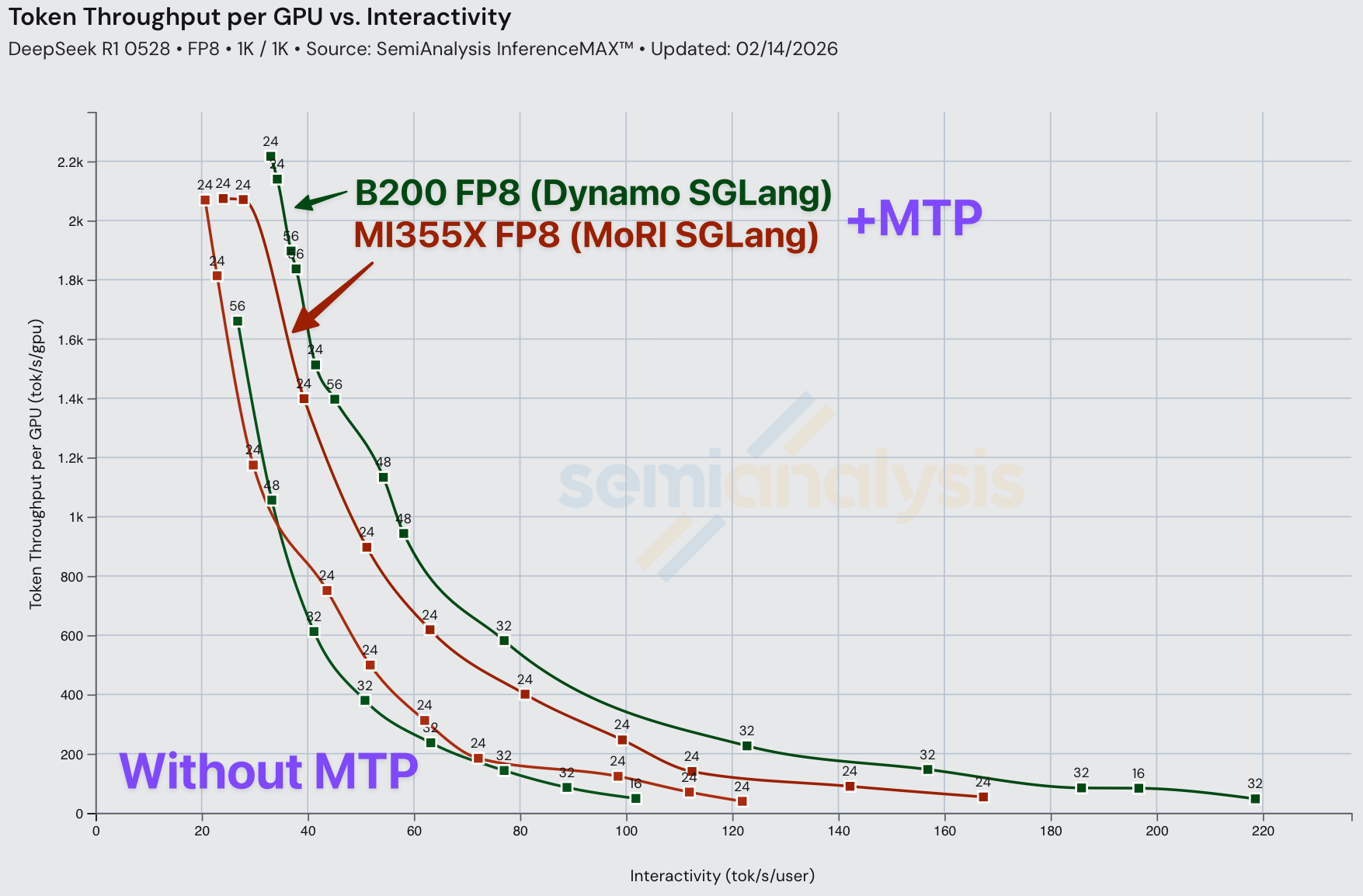
在所有 SKU 上,启用 MTP 都带来了性能提升。通过利用通常未使用的 logits 来验证额外 token,仅增加了极少的计算开销,节省了解码过程中昂贵的权重加载。
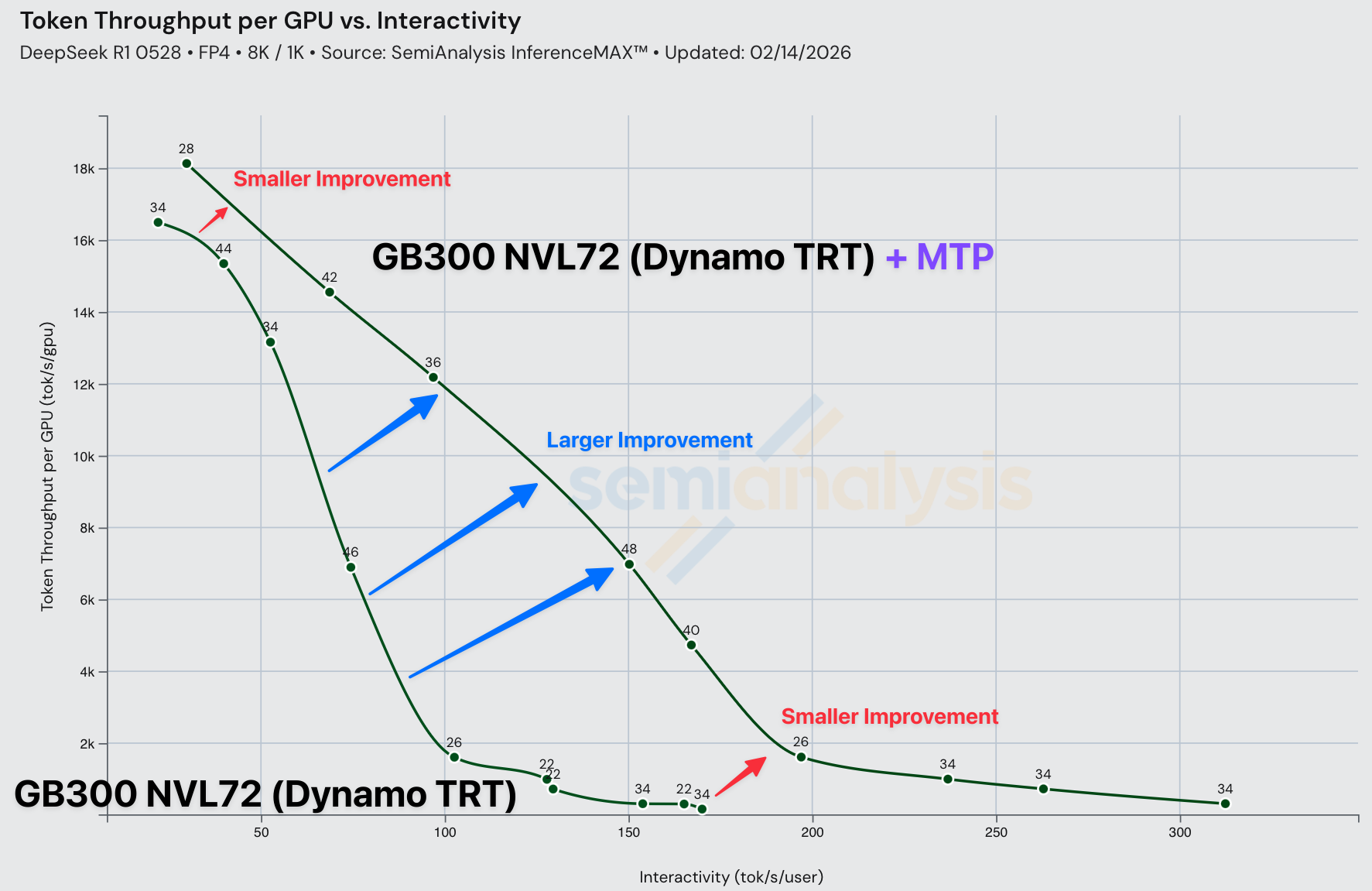
在大批次下,推理机制相比小批次受内存带宽限制更少。由于推测解码(包括 MTP)的工作原理是用多余的计算换取更少的内存受限解码步骤,推测 token 带来的额外验证工作可能无法恰好利用空闲算力,导致在大批次下的改进幅度较小。
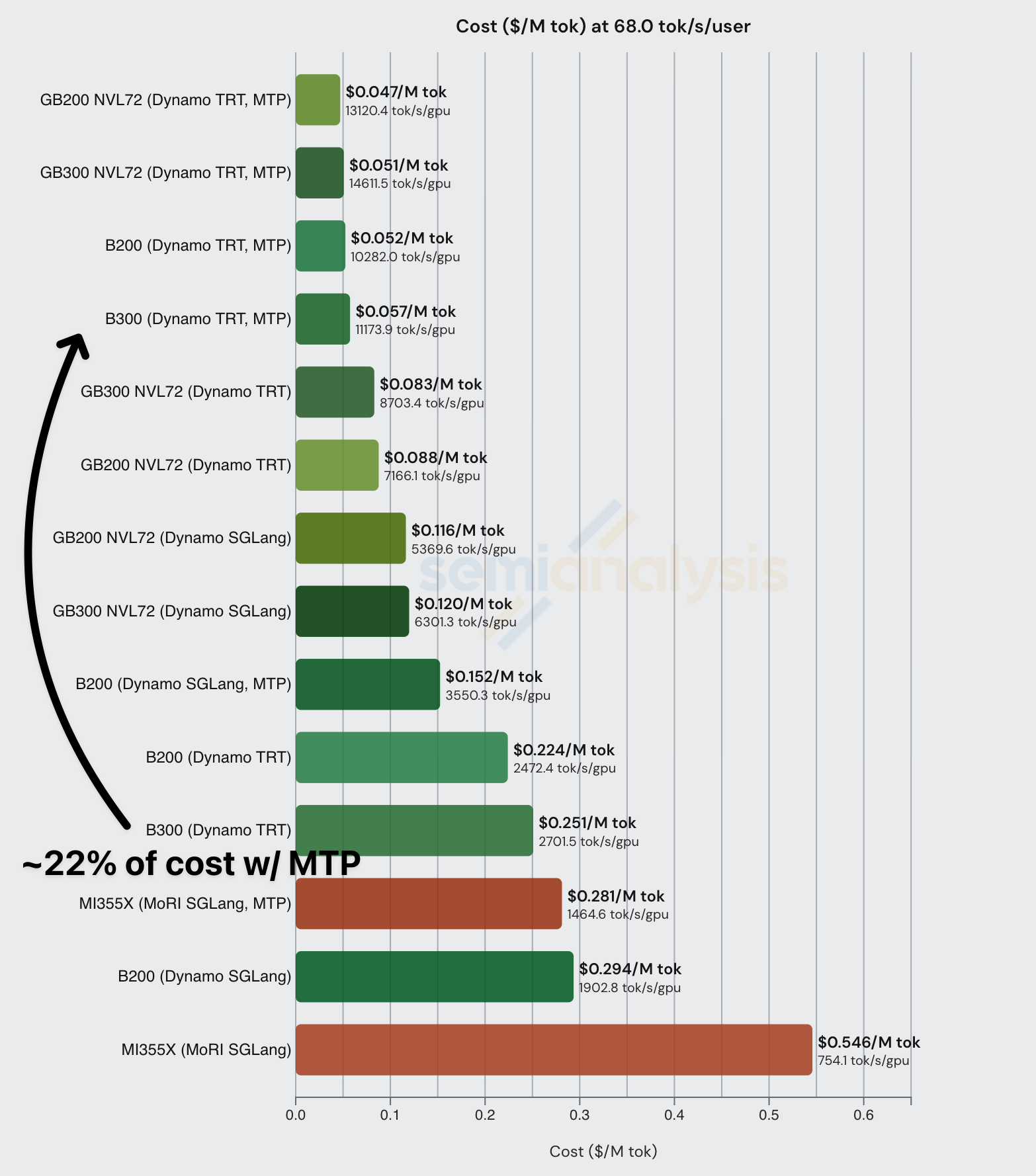
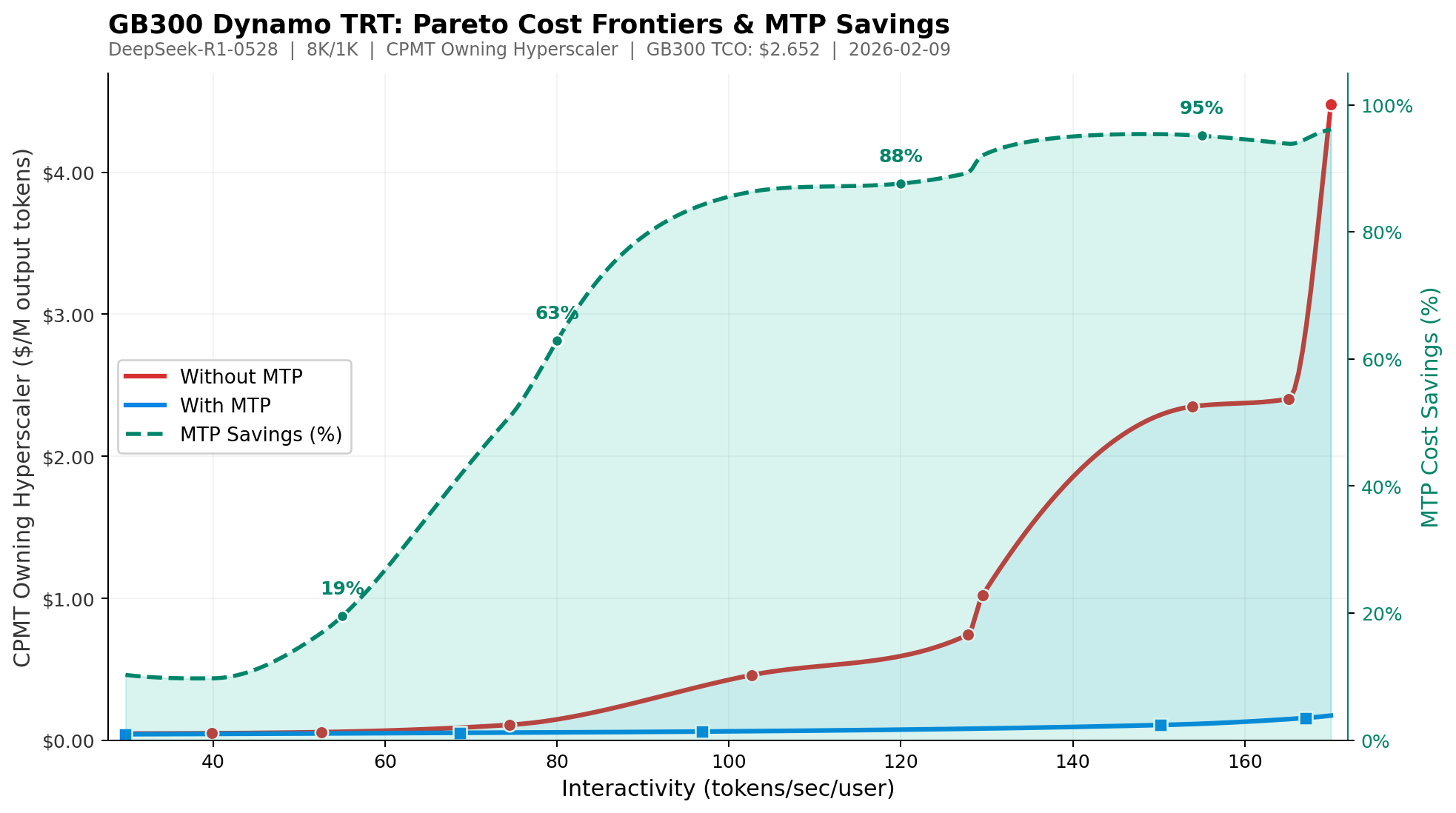
从成本角度来看,MTP 能带来巨大的成本节省。在下表中,我们看到使用 Dynamo TRT 运行 FP4 的 DeepSeek-R1-0528 每百万总 token 成本为 $0.251,但启用 MTP 可将成本大幅降低至每百万总 token 仅 $0.057。
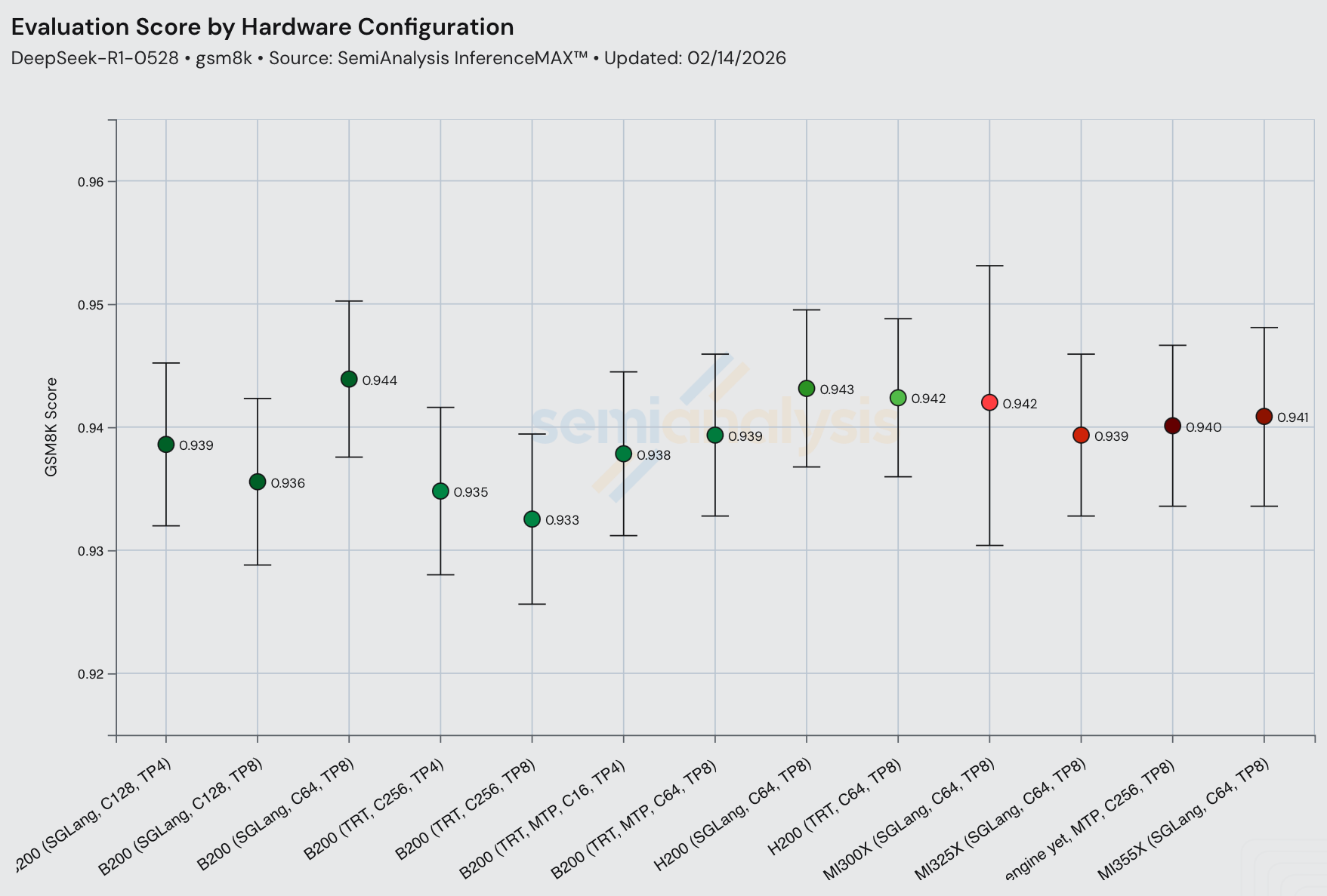
在所有配置中,当其他条件不变时,在 DeepSeek R1 上使用 MTP 可以提高交互性,且对模型精度没有显著影响。这与 DeepSeek V3 技术报告的结论一致。
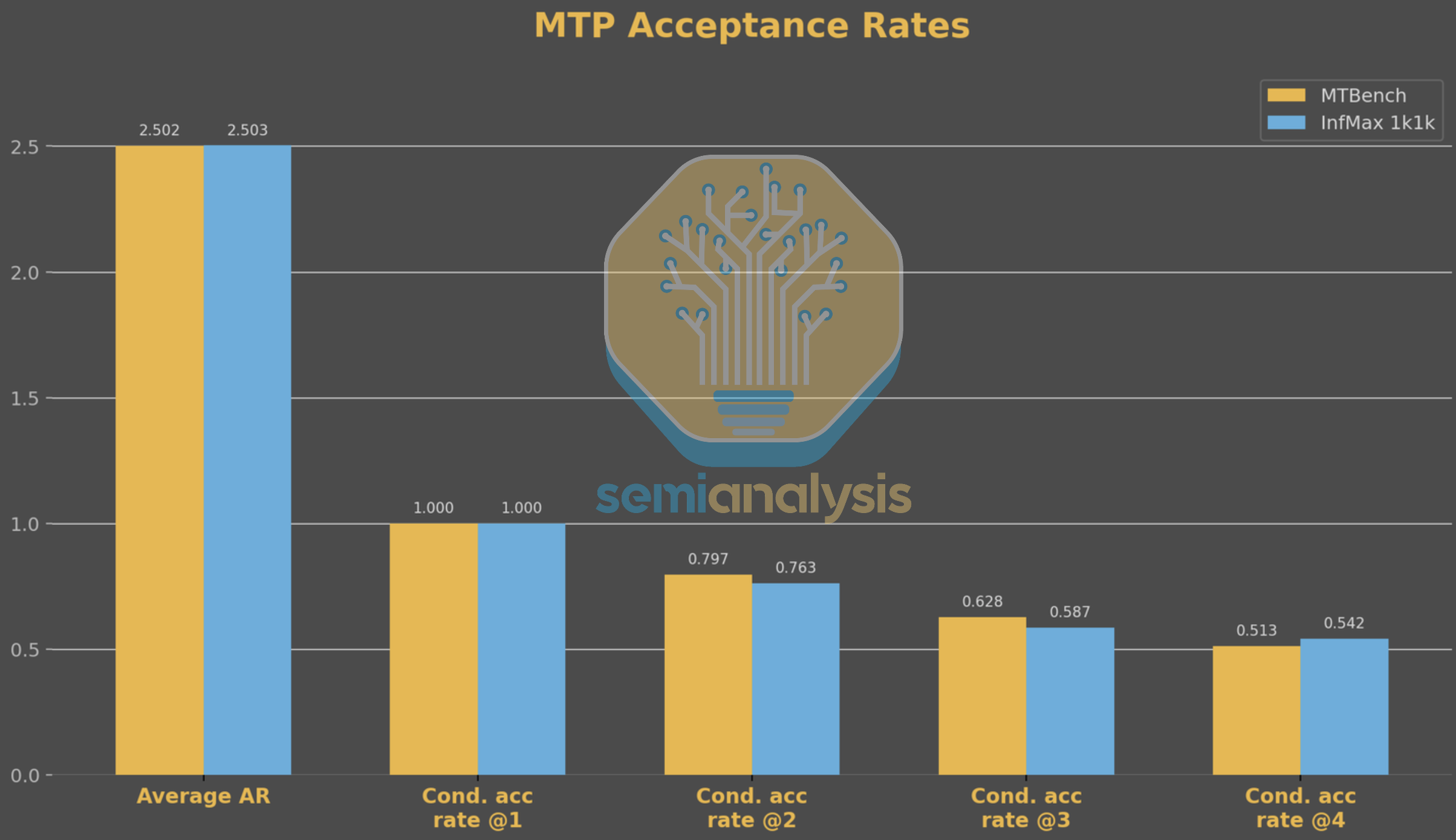
关于 MTP 性能数据的有效性,有人可能会认为合成数据集的分布不能代表真实数据。然而,比较 MTBench 和我们的 1k1k 基准测试之间的 MTP 接受行为,我们发现分布非常相似,这证实了我们的 InferenceX 基准测试是真实世界生产性能的良好代理。话虽如此,InferenceX 并非完美,我们始终在寻求改进。如果您想加入我们的使命,请在此申请加入我们的特别项目团队。
精度评估
吞吐量优化有时会悄然牺牲精度(例如通过过于激进的接受率放松、解码调整、数值不稳定的内核或端点配置错误)。如果没有评估,一个配置错误的服务器(截断、错误的解码、错误的端点参数)仍然可以产生很好的吞吐量数字,但输出的答案却是垃圾。例如,这一额外的检查层帮助我们发现了 GPT-OSS 的某些 DP 注意力实现的问题。
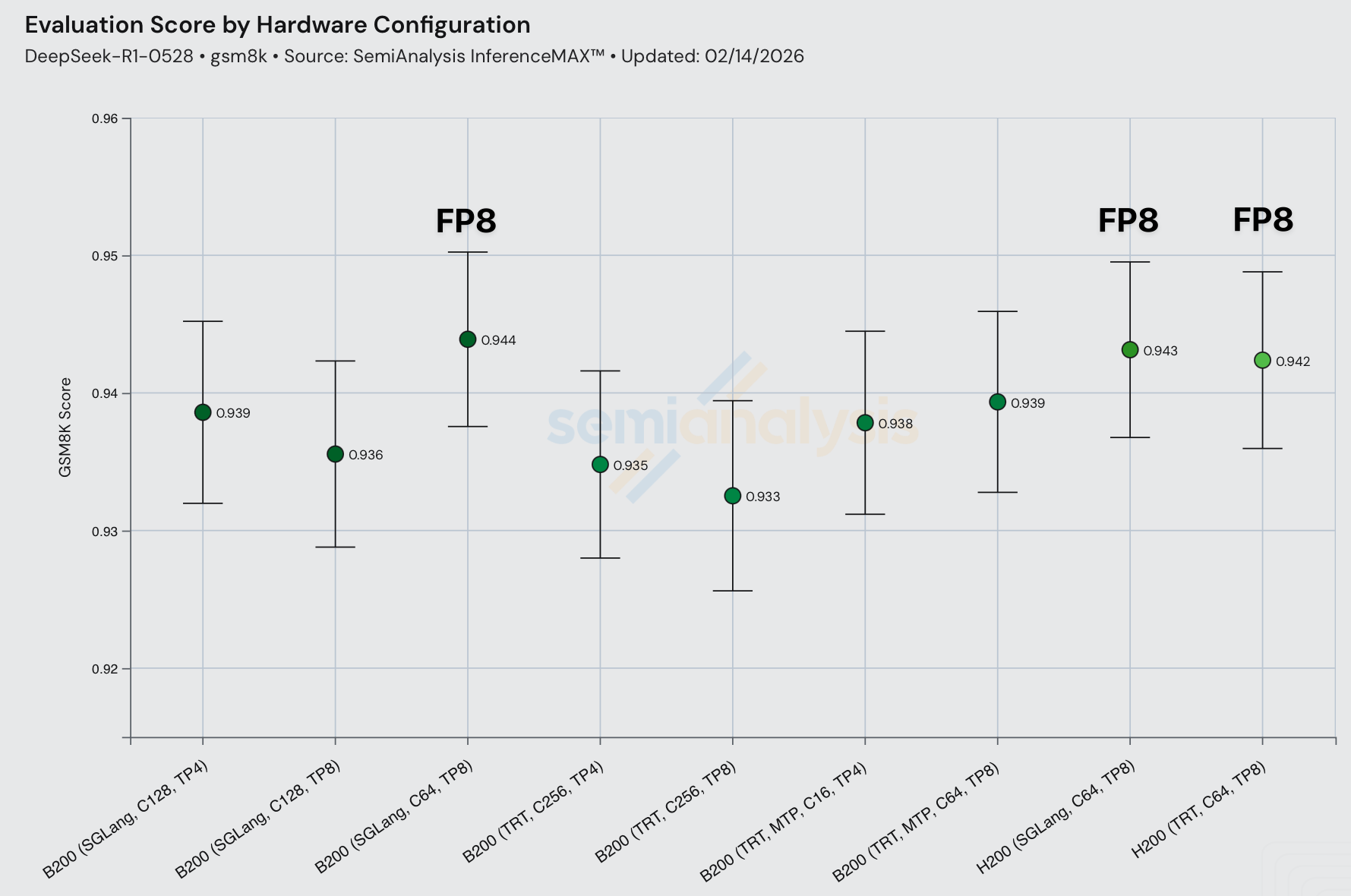
现在,每个代表性吞吐量配置都附带了数值精度检查。目前我们仅使用 GSM8k,但由于这是一个非常简单的基准测试,评估分数可能不会因数值计算差异而有太大变化,更难的基准测试可能会在数值精度方面产生更大的差异。因此,我们计划在未来扩展到更难的测试,如 GPQA、HLE、MATH-500、SWE-Bench verified。
另一种性能-精度权衡体现在量化上。以更低精度服务模型可能导致模型输出变差。对于 DeepSeek R1,FP8 运行的评估分数略高于 FP4。请注意,GSM8k 评估已经饱和,且在 QAT/PAT 过程中通常会针对常见的 GSM8k、MATH-500 等进行校准,导致有时评估结果优异而真实世界终端用户评估表现不佳。如果您想加入团队研究如何正确评估推理引擎精度,请在此申请加入使命。
Anthropic Fast Mode 推理解析
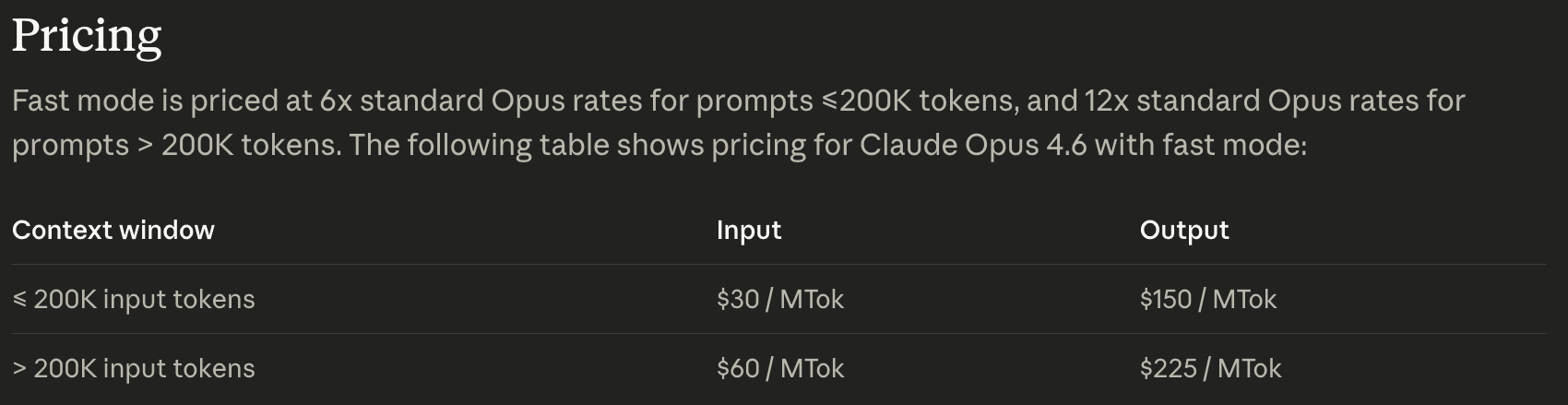
Anthropic 最近伴随 Opus 4.6 发布了"fast mode"。其价值主张是:相同的模型质量,约 2.5 倍的速度提升,约 6-12 倍的价格。这两个数字可能都令人意外,一些用户推测这一定需要新硬件。实际上并不需要。这本质上就是那个根本性权衡在起作用。任何模型都可以在广泛的交互性水平(每用户 token/s)范围内提供服务,每百万 token 的成本(CPMT)会相应变化。用我们的类比来说,梅赛德斯既造公交车也造跑车。
精打细算的人可能认为 fast mode 更贵,但如果从总拥有成本的角度来看,fast mode 在某些情况下实际上要便宜得多。例如,一个 GB200 NVL72 机架可以花费 330 万美元,因此,如果 Claude Code 的智能体循环(在生产中运行在 Trainium 上)通过工具调用使用 NVL72 机架,而这些机架的推理速度慢了 2.5x,您就需要 2.5x 更多的机架来提供推理服务,这意味着不启用 fast mode 将额外花费近 500 万美元。

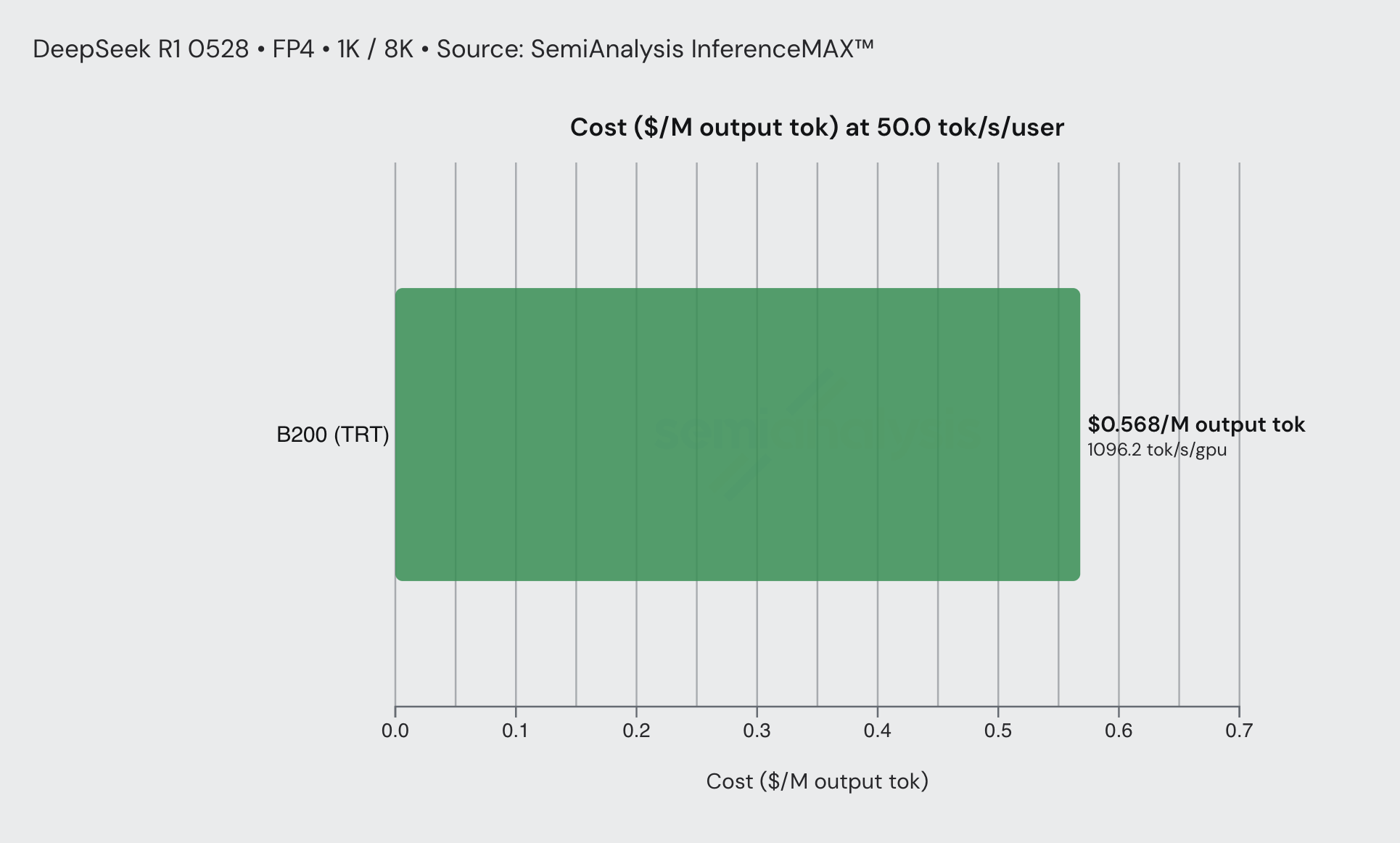
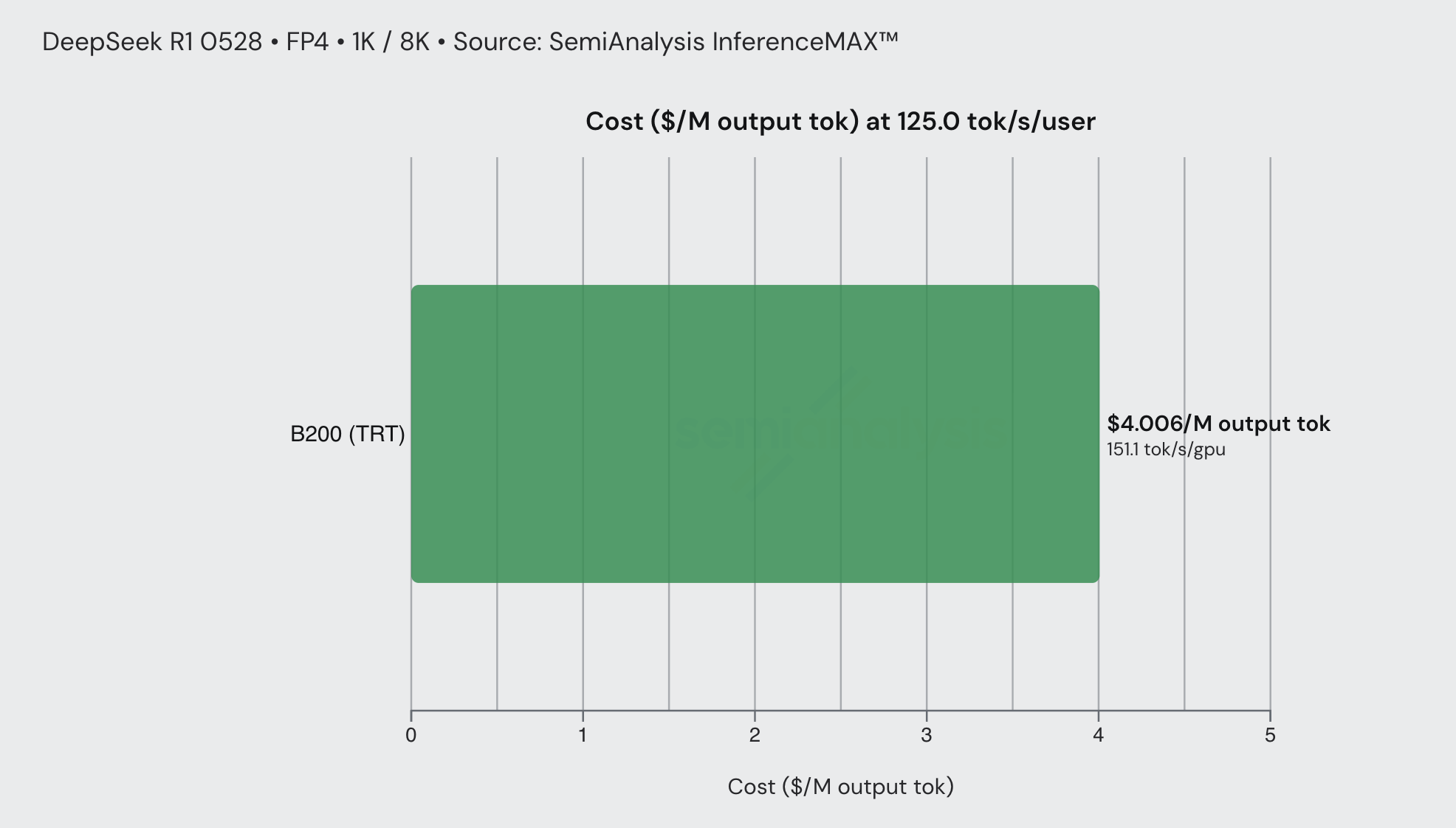
以在 B200 上使用 TRT-LLM 运行的 DeepSeek R1 0528 FP4 编码工作流为例。在 50 tok/sec/user 的交互性下,推理成本约为 $0.56/M 输出 token。在 125 tok/sec/user 的交互性下,成本上升至约 $4/M 输出 token——速度提升 2.5 倍,价格增加约 7 倍,与我们在 Anthropic fast mode 中看到的情况非常接近。请注意,这假设 DeepSeek R1 与 Opus 4.6 相似,实际并非如此。但总体原理仍然成立。
这直接源于 LLM 推理中延迟与吞吐量的根本权衡。在大批次下,GPU 实现了更好的利用率和更高的总 token 吞吐量,即同时服务更多用户、更低的每 token 成本。在小批次下,每个请求有更大的并行度,每个用户获得更快的响应,但总 token 吞吐量下降。由于加速器的每小时成本无论如何使用都是固定的,更低的吞吐量意味着更少的 token 来分摊该成本,因此每 token 价格更高。
简言之,fast mode 不一定是硬件层面的故事,只是在相同 GPU 上用吞吐量换延迟的自然结果。
此外,我们观察到推测解码等推理优化技术可以直接降低推理成本,无需新芯片。
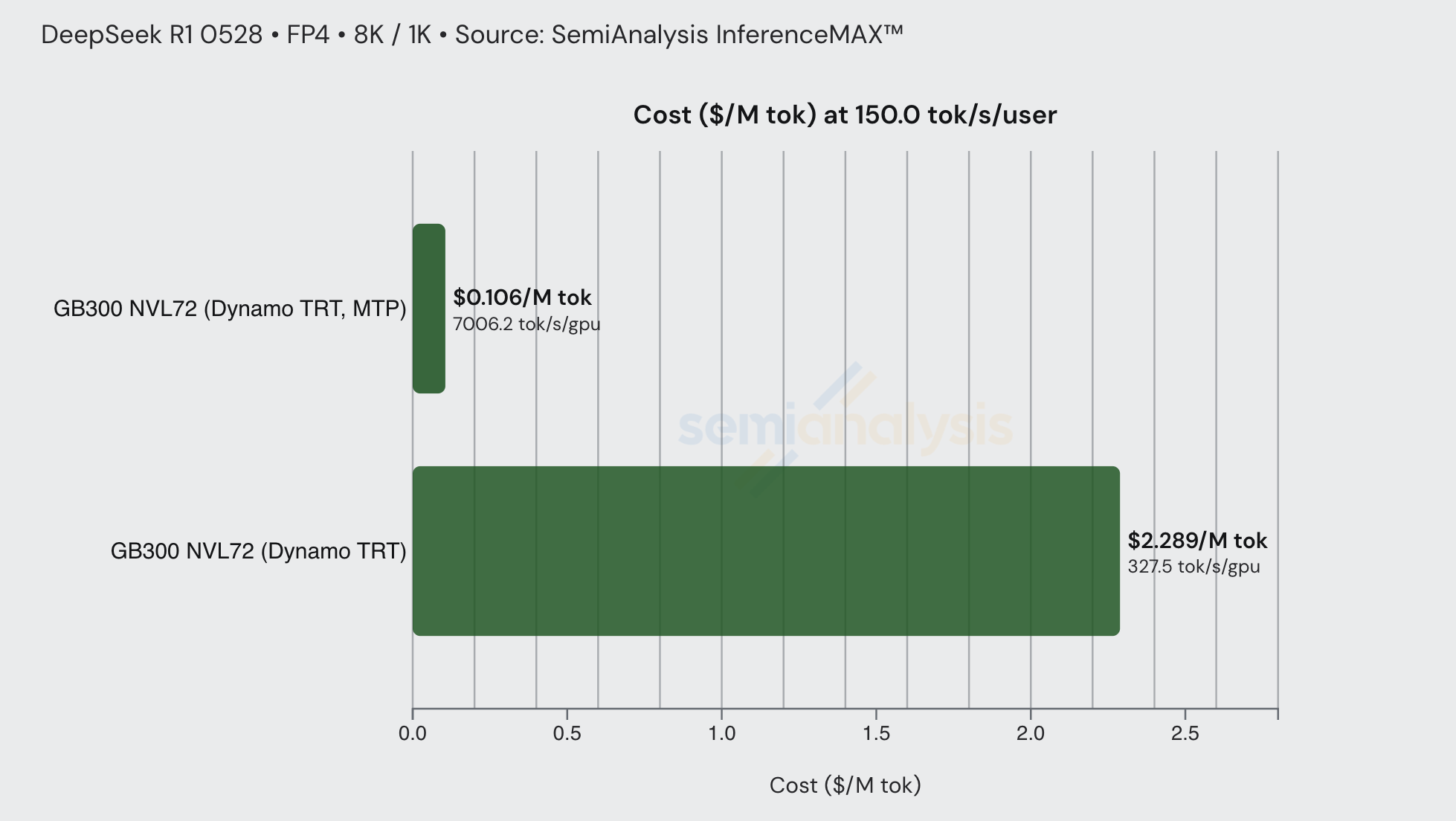
以下面的例子为例,DeepSeek R1 FP4 在 8k/1k 工作负载上。在 150 tok/sec/user 的交互性水平下,基线 GB300 Dynamo TRT 的每百万 token 成本约为 $2.35,而启用 MTP 将价格降至约 $0.11。仅通过采用一种推理优化技术,就实现了该交互性水平下约 21 倍的价格降低。
固定 50 tok/sec/user 的交互性水平,我们进一步看到 MTP 如何在各种芯片上有效降低每百万 token 成本(CPMT)。
宽专家并行(WideEP)与分离预填充
在本节中,我们将深入探讨专家并行,并解释什么是宽专家并行。然后我们将解释分离预填充的概念、它与 WideEP 的区别,以及 WideEP 和分离预填充如何协同使用以实现 SOTA 性能。
WideEP
目前,大多数前沿 AI 实验室采用的是混合专家(MoE)模型架构而非稠密架构。在 MoE 架构中,每个 token 只激活一部分"专家"。例如,DeepSeek R1 总共有 671B 参数,但仅有 37B 活跃参数。具体来说,DeepSeek R1 有 256 个路由专家(和 1 个共享专家),每个 token 被路由到 8 个不同的专家。这种架构天然适合专家并行(EP),即将专家权重均匀分布到一定数量的 GPU 上。
考虑在单个 8-GPU 服务器上服务 DeepSeek R1。在 671B 参数的规模下,需要某种形式的并行才能将模型放入可用的 HBM 中。最简单的方法是张量并行(TP),它将每个权重矩阵分片到所有 GPU 上。这对稠密模型效果很好,但忽略了 MoE 的稀疏激活模式。使用 TP=8 时,每个专家的权重都分片到所有 8 块 GPU 上,意味着每次专家激活都需要在所有 GPU 之间执行 all-reduce——即使 256 个专家中每个 token 仅激活 8 个,且归约维度的 GEMM 更小导致算术强度更低。TP 将每个专家当作稠密层对待,在模型稀疏性未被利用的情况下承担了全部跨 GPU 通信成本。
专家并行采用了更合适的方法,将完整的专家分配给各个 GPU。使用 EP=8 时,我们将每层的 256 个专家分配到 8 块 GPU 上,每块 GPU 每层 32 个专家。每块 GPU 持有约 1/8 的专家权重加上非专家权重的完整副本(注意力投影、嵌入层、归一化层和共享专家)。由于 DeepSeek R1 约 90% 以上的参数是路由专家权重,EP 捕获了大部分内存节省,而将剩余不到 30B 的非专家参数在所有 8 块 GPU 上复制是可以承受的。
前向传播在每一层分两个阶段进行。在注意力阶段,每块 GPU 充当独立的数据并行 rank,使用其复制的非专家权重处理自己的请求子集——无需 GPU 间通信。在 MoE 阶段,轻量级路由器确定每个 token 需要哪些专家,token 通过 all-to-all 通信被分发到相应的 GPU。每块 GPU 仅对路由到它的 token 执行其本地专家计算,结果通过第二次 all-to-all 返回。
最直接的扩展方式是复制:在 N 个节点上部署 N 个独立的 EP8 实例。每个实例独立服务请求,无跨节点通信。这使吞吐量线性扩展,但每块 GPU 仍然持有每层 32 个专家,每个 token 最多激活其中 8 个。75% 的专家权重闲置在 HBM 中。
宽专家并行(WideEP)采用了不同的方法,将 EP 跨节点扩展而非复制独立实例。在 64-GPU 集群(8 个节点)上,DP64/EP64 将每层每块 GPU 仅放置 256/64 = 4 个专家,同时每块 GPU 仍持有非专家权重的完整副本。在 MoE 阶段,所有 64 个 DP rank 的 token 通过 all-to-all 分发到托管其路由专家的 GPU。
与单节点 EP8 基线相比,这带来了三重叠加效益。首先,将专家占用从每 GPU 32 个减少到 4 个,释放了大量 HBM 用于 KV 缓存,直接增加了每 GPU 批次容量。其次,64 个 DP rank 的 token 汇聚到更少的每 GPU 专家上,增加了每专家 token 数,提高了算术强度(每字节权重加载的 FLOPS 更多),改善了计算利用率。相同的专家权重在每步服务 8 倍的 token。第三,聚合 HBM 带宽随 GPU 数量线性扩展;64 块 GPU 同时加载专家权重提供了单节点 8 倍的内存带宽,减少了内存瓶颈。
上述配置仅使用 DP+EP(也称为 DEP),其中每块 GPU 持有所有非专家权重的完整副本。随着 GPU 数量增加,这种复制变得越来越浪费。在 64-GPU 的 DP64/EP64 部署中,每块 GPU 都存储着约 40B 非专家参数的相同副本。
在 GPU 组内添加张量并行可以解决这个问题。在 EP64/DP8/TP8 配置中,64 块 GPU 被组织成 8 个 DP 组,每组 8 块 GPU。在每个 TP 组内,注意力投影、共享专家、归一化层和 LM head 被 8 路分片,因此每块 GPU 仅持有 1/8 的非专家权重。在整个集群中,256 个专家仍然像之前一样分布——每 4 块 GPU 一个。
纯 DEP 只有一种通信模式:用于专家路由的 all-to-all。添加 TP 在每个 TP 组内为注意力和非专家计算引入了第二种 all-reduce。关键设计原则是将 TP 组放置在单个节点内(NVLink 或 MNNVL 提供高带宽互连),而将 EP/DP 跨节点运行(all-to-all 通信模式可以容忍更高的延迟)。
一如既往,这里的权衡是吞吐量与延迟的取舍。一个组内的 TP=8 意味着这 8 块 GPU 共享一个批次并且必须在每个解码步同步,将有效 DP 度从 64 降低到 8。注意力侧的每 GPU 批处理独立性丧失了。但每个 DP 组现在每步处理注意力的速度提高了 8 倍,因为矩阵乘法在 TP 组内被 8 路分割。每 token 延迟下降,同时峰值并发度也下降——相对于纯 DEP,该配置沿延迟-吞吐量帕累托前沿滑动。
分离预填充
分离预填充,有时也称为预填充-解码(PD)分离,是将 LLM 推理的预填充和解码阶段在不同节点上执行的过程。预填充发生在请求首次处理时,对所有 token 执行一次前向传播,从而"预填充"该请求的 KV 缓存。这是一个计算密集型操作,因为所有 token 同时通过前向传播。随后,token 逐个生成或"解码",每个解码步都从 HBM 加载 KV 缓存。这是一个内存密集型过程,因为不断增长的 KV 缓存持续被加载。
在传统的单节点推理中,引擎在同一 GPU 上交替执行预填充和解码。到来的预填充请求会阻塞正在进行的解码批次,增加首 token 延迟(TTFT)和 token 间延迟。分块预填充通过将长预填充拆分为更小的片段来缓解这一问题,但资源竞争的根本问题仍然存在。分离预填充彻底消除了这一问题!
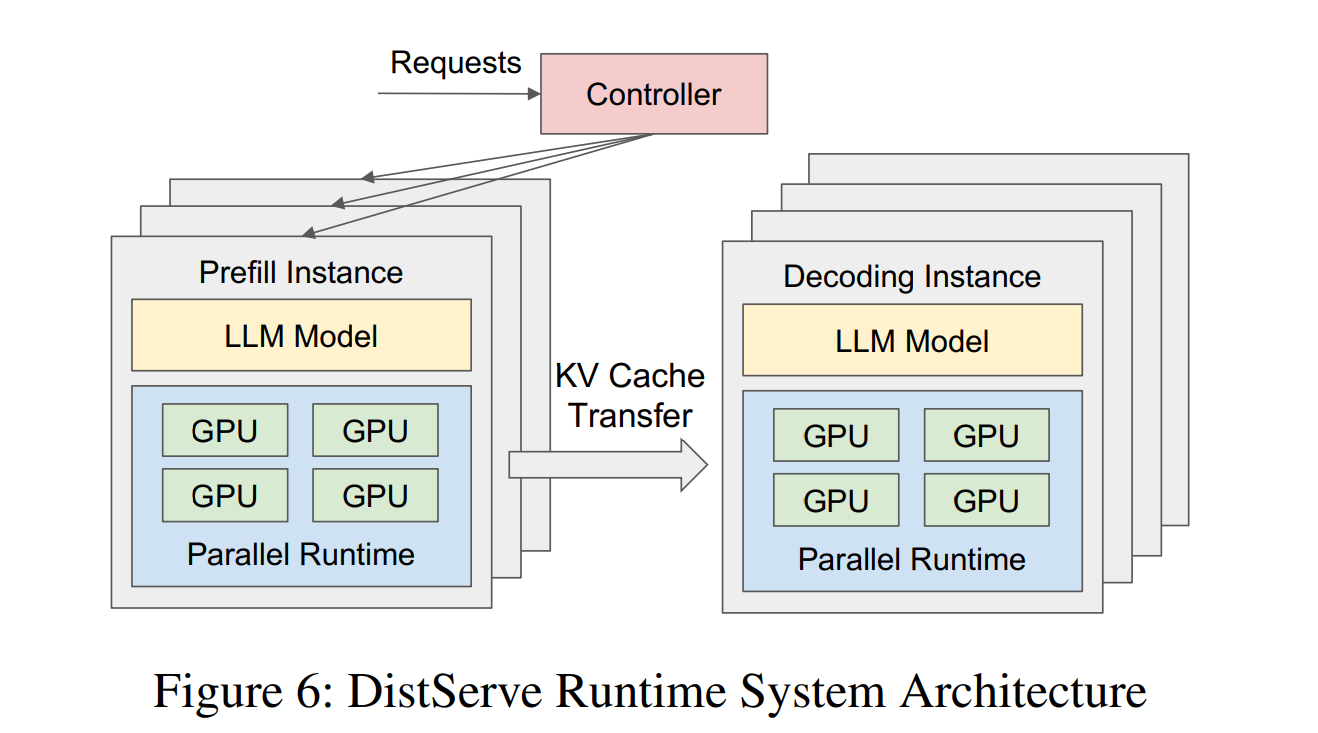
分离还支持对每个阶段进行独立扩展和优化。有了独立的节点,每个阶段可以分别调优:不同的并行策略、不同的批次大小和不同的内存分配比例。预填充与解码节点的比例也可以根据工作负载的输入-输出长度比进行匹配。例如,预填充主导的工作负载(长输入、短输出,如摘要生成、RAG、大上下文窗口的智能体编码)分配更多预填充实例。解码主导的工作负载(短输入、长输出,如思维链推理、长文本生成)分配更多解码实例。缓存命中率高的工作负载也倾向于使用更多解码,因为来自共享系统提示或多轮对话历史的复用 KV 缓存条目完全跳过了预填充。
分离的关键代价是 KV 缓存传输。预填充完成后,该请求的完整 KV 缓存必须从预填充节点传输到解码节点,然后才能生成第一个解码 token。对于像 DeepSeek R1 这样具有 61 层和 FP8 KV 缓存的模型,8192 个 token 的预填充产生大约 500MB 的 KV 数据需要通过网络传输,这直接增加了 TTFT。这种传输通过 RDMA(通常是 RoCE 或 InfiniBand)进行,使用零拷贝 GPU 到 GPU 的数据移动,无需 CPU 参与。NIXL(NVIDIA Inference Transfer Library)等库将数据移动层抽象在统一的异步 API 后面,具有可插拔的 UCX、GPUDirect Storage 等传输后端。这将推理引擎与任何特定传输协议解耦,并支持跨异构硬件的分离,其中预填充和解码实例可能跨越不同的设备类型或互连。
使用宽 EP + 分离式服务优化推理
宽 EP 和分离预填充是两种独立的技术,通常一起使用以实现帕累托最优性能。在本节中,我们将逐步分析 InferenceX 的真实结果,帮助建立对在不同交互性水平下何种并行策略、宽 EP 和分离预填充组合更合适的直觉。
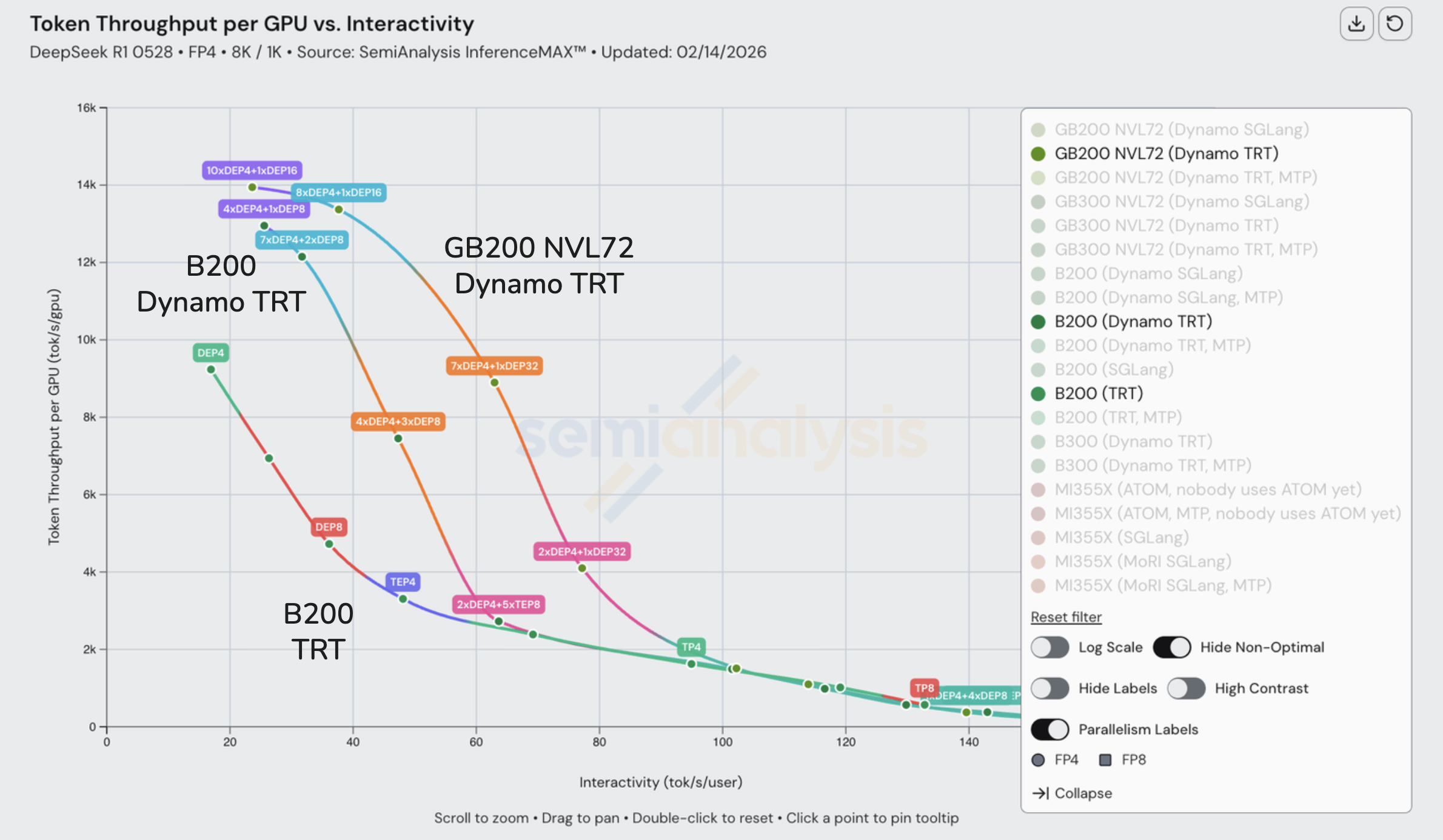
首先了解对于单节点配置,哪些并行策略落在帕累托前沿的哪些部分会有所帮助。以在单个 8-GPU B200 节点上使用 TRT-LLM 运行 DeepSeek R1 FP4 8k/1k 为例。最优策略随着在前沿上的移动而变化,主要由批次大小及其对专家激活密度的影响驱动。
在最高交互性水平(批次 1-16)下,纯 TP 优于任何涉及 EP 的配置。在小批次下,每步仅有少量专家被激活。使用 EP 时,这些激活在 GPU 之间分布不均:在批次 4 时,256 个专家中仅有 32 个被触发,任何给定 GPU 在给定层中接收零路由 token 的概率约为两位数百分比。TP 通过将每个专家分片到所有 GPU 来避免这一问题,因此无论路由器选择哪些专家,所有 8 块 GPU 都平等参与每个专家的计算。我们在分析 DeepSeek R1 时收集了专家激活比例与批次大小的数据,确认在批次 16 及以下时,每层的专家激活率非常低。
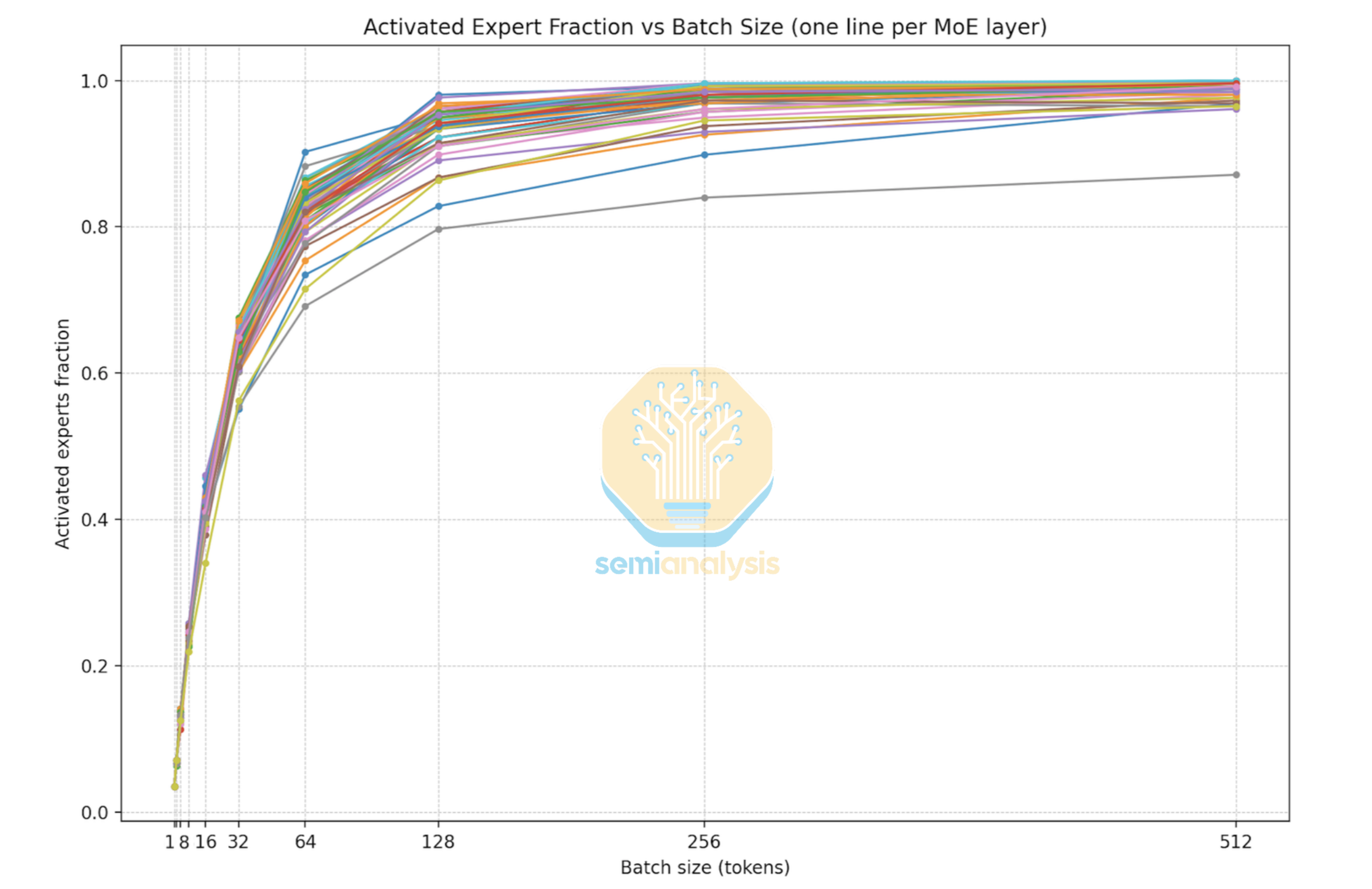
随着我们移至稍低的交互性水平,批次大小仍然足够小,专家权重仍然通过 TP 而非 EP 进行分片。交叉点出现在大约批次 32 处,此时约 50-60% 的专家在每层被激活。在这个密度下,EP 的负载不均衡变得可以容忍,其 token 路由开销比 TP 所需的逐专家 all-reduce 更低。该范围内的配置使用 TEP:注意力使用张量并行(所有 GPU 协作完成每个注意力计算),MoE 层使用专家并行(专家分配到特定 GPU 并通过 all-to-all 路由)。在最高吞吐量、最低交互性区域,批次很大(128+),配置转向完全 DEP:注意力权重在所有 GPU 上作为独立数据并行 rank 完全复制,专家通过 EP 分布,批次容量最大化但牺牲了每 token 延迟。
在扩展到宽 EP 配合分离预填充时,我们观察到了相同的一般模式。预填充和解码使用独立的并行策略和节点数量,两者都根据工作负载和目标交互性水平进行调优。以 8k/1k 工作负载(预填充密集型)在高吞吐量、低交互性区域为例。预填充是瓶颈,因为每个请求需要对 8192 个输入 token 执行一次计算密集的前向传播。该区域的配方分配更多预填充节点而非解码(4P1D、7P2D、4P3D)以维持高预填充吞吐量。这些预填充节点运行 DEP 配置,在独立的数据并行 rank 上复制注意力权重,以便同时处理多个长上下文预填充。解码节点数量较少但以同样的原则运行宽 DEP 配合大批次。
在低交互性端,同时进行的请求较少,因此单个预填充实例就能跟上传入需求的节奏。但每个请求仍需 1024 个解码步骤,且在高交互性下这些步骤必须很快。该区域的配方转向更多解码节点而非预填充(1P3D、1P4D),每个解码实例在小批次下运行 TEP。注意力的张量并行通过将计算分片到实例内的所有 GPU 来最小化每步延迟,而专家并行在中等批次(EP 负载均衡足够好的情况下)处理 MoE 路由。多个小批次解码实例(而非较少的大批次实例)保持了低每 token 延迟,同时仍提供足够的并发服务能力。
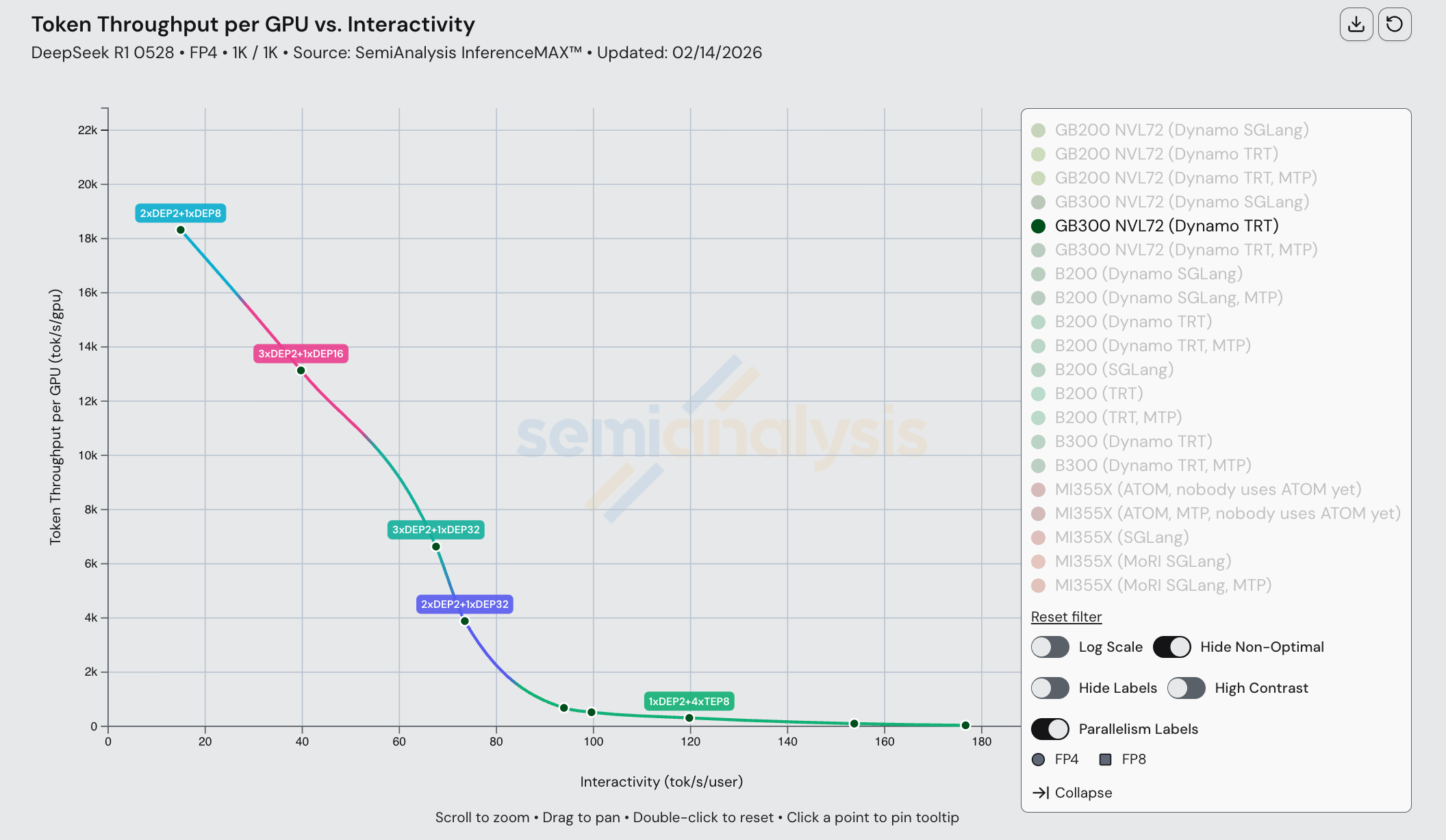
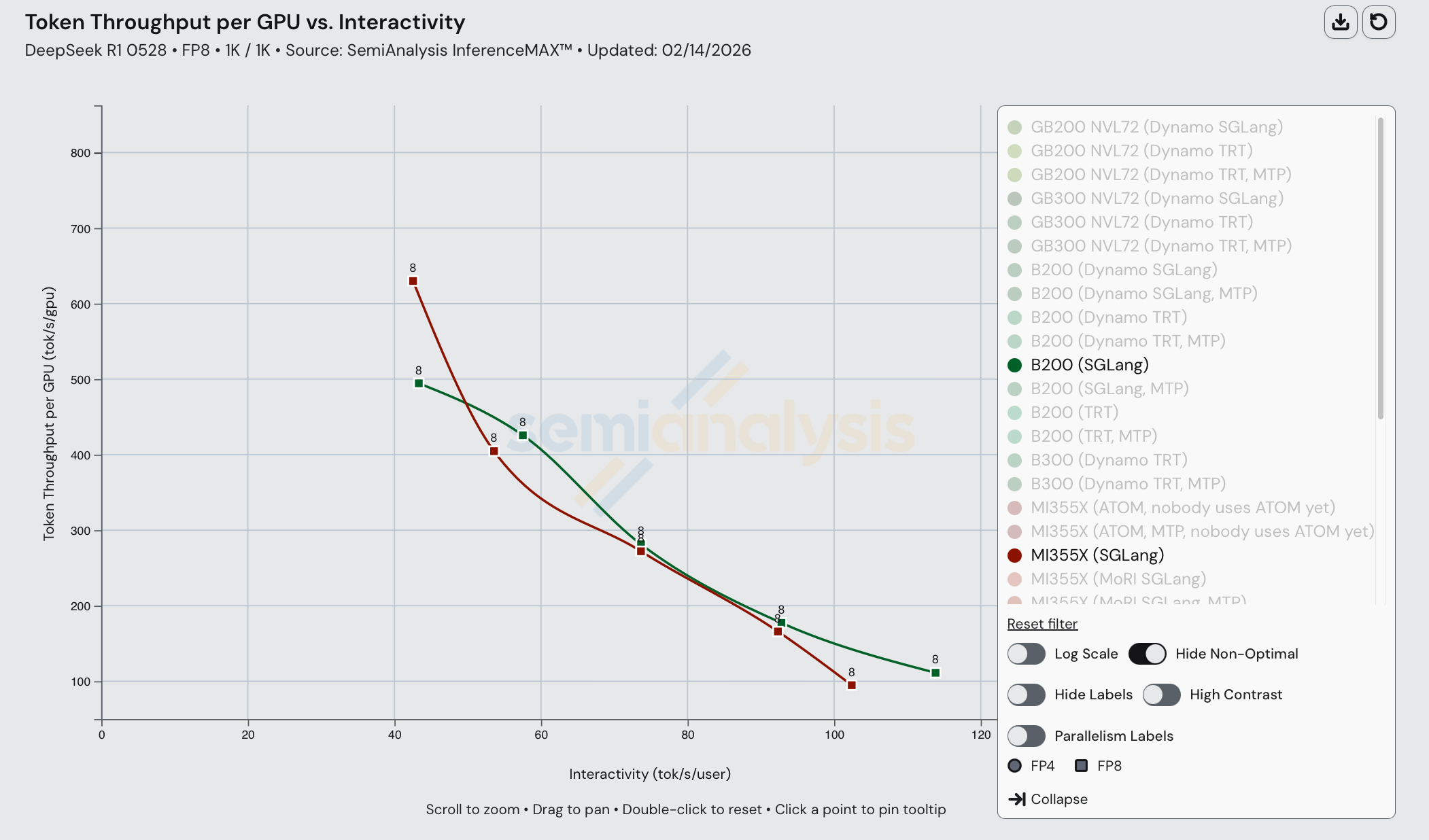
深入分析 DeepSeek R1 单节点结果
在 DeepSeek R1 FP8 1k1k 上,我们看到 MI355X 在单节点场景下与对标的 B200 具有竞争力——尽管在 FP4 多节点场景下被碾压。MI355X(SGLang)在较低交互性水平的吞吐量性能上甚至超过了 B200(SGLang)。此外,MI355X(SGLang)在大多数场景下从性价比角度优于 B200(TRT 和 SGLang)。
遗憾的是,时至 2026 年,大多数前沿实验室和推理服务商既不使用 FP8 也不使用单节点推理。
这一结果表明 AMD 的芯片本身非常出色,如果他们能在软件方面推进得更快,完全可以与 NVIDIA 展开极具竞争力的较量。速度就是护城河。
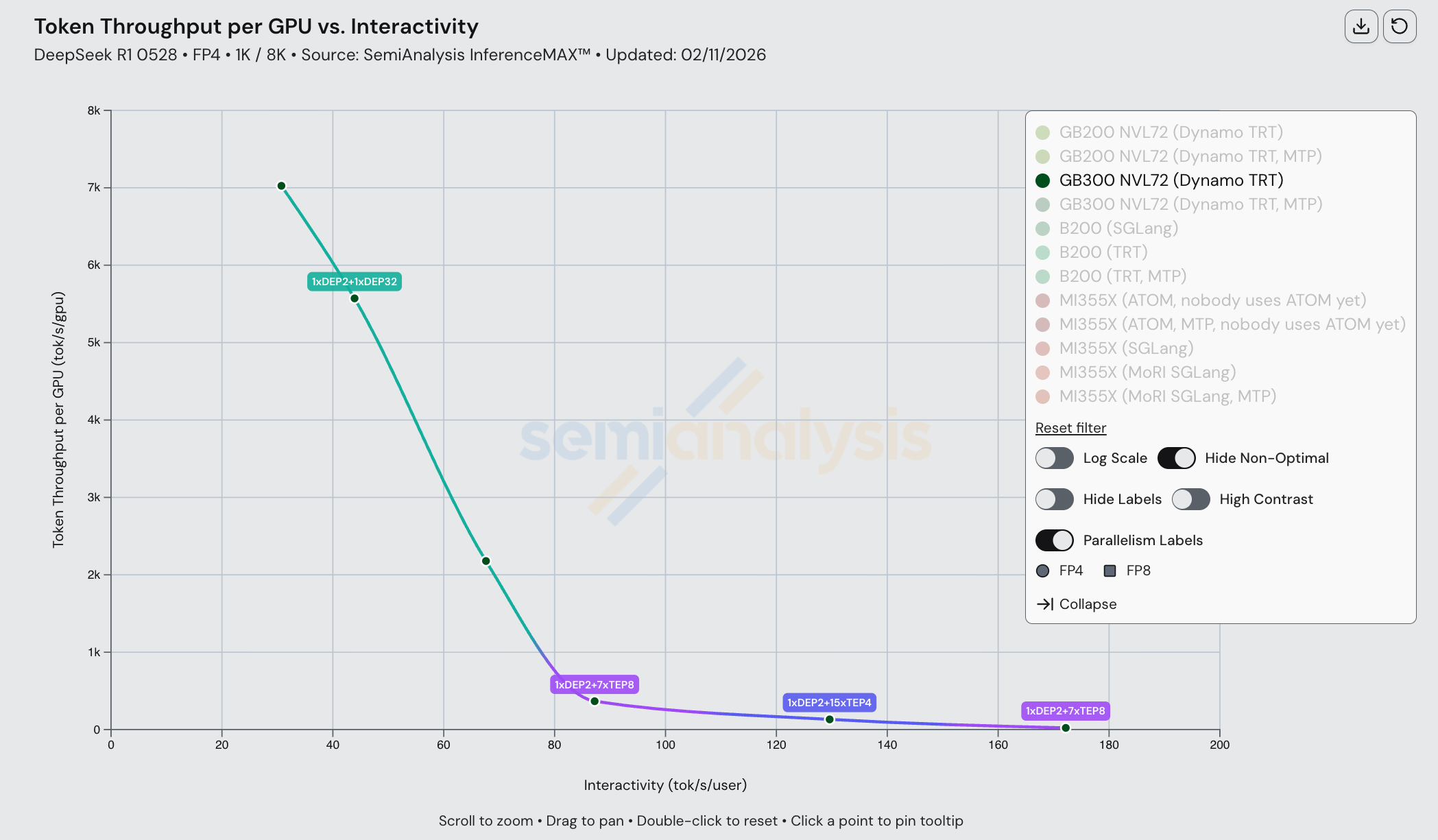
因此,我们看到 MI355X 在 FP4 性能上明显落后于 B200:
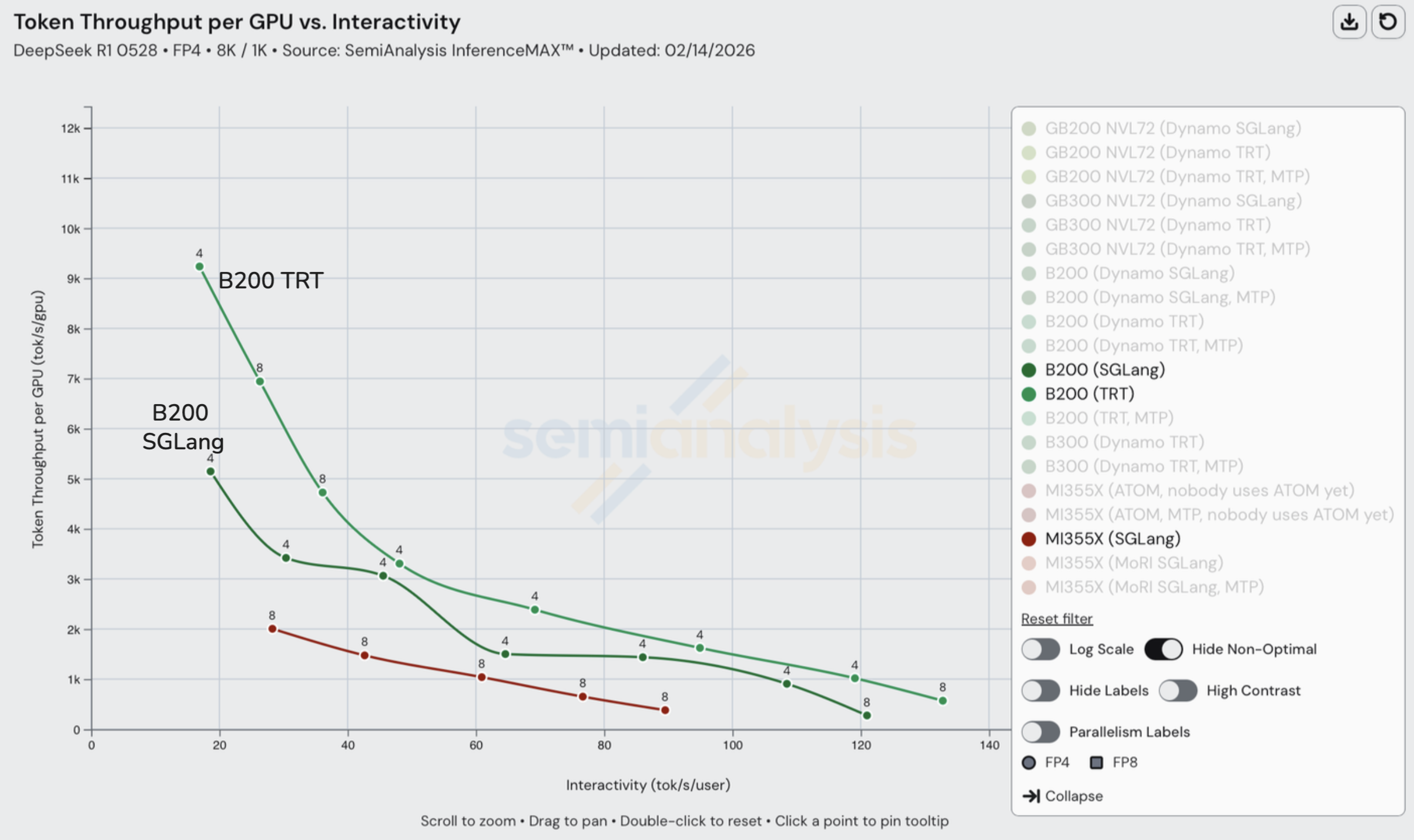
在比较 H200(SGLang)和 MI325X(SGLang)上的 DeepSeek R1 FP8 性能时,自我们去年 10 月首次发布 InferenceXv1 以来变化不大。MI325X 数据采集于 2026 年 2 月 12 日,使用 SGLang 0.5.8,而 B200 数据采集于 2026 年 1 月 23 日,使用 SGLang 0.5.7。
我们注意到一个值得关注的问题是 MI325X 的交互性范围比 H200 小得多,H200 的范围为 30-90 tok/sec/user,而 MI325X 仅为 13-35 tok/sec/user。这对于希望在更广泛交互性范围内服务用户的服务商来说是个问题。
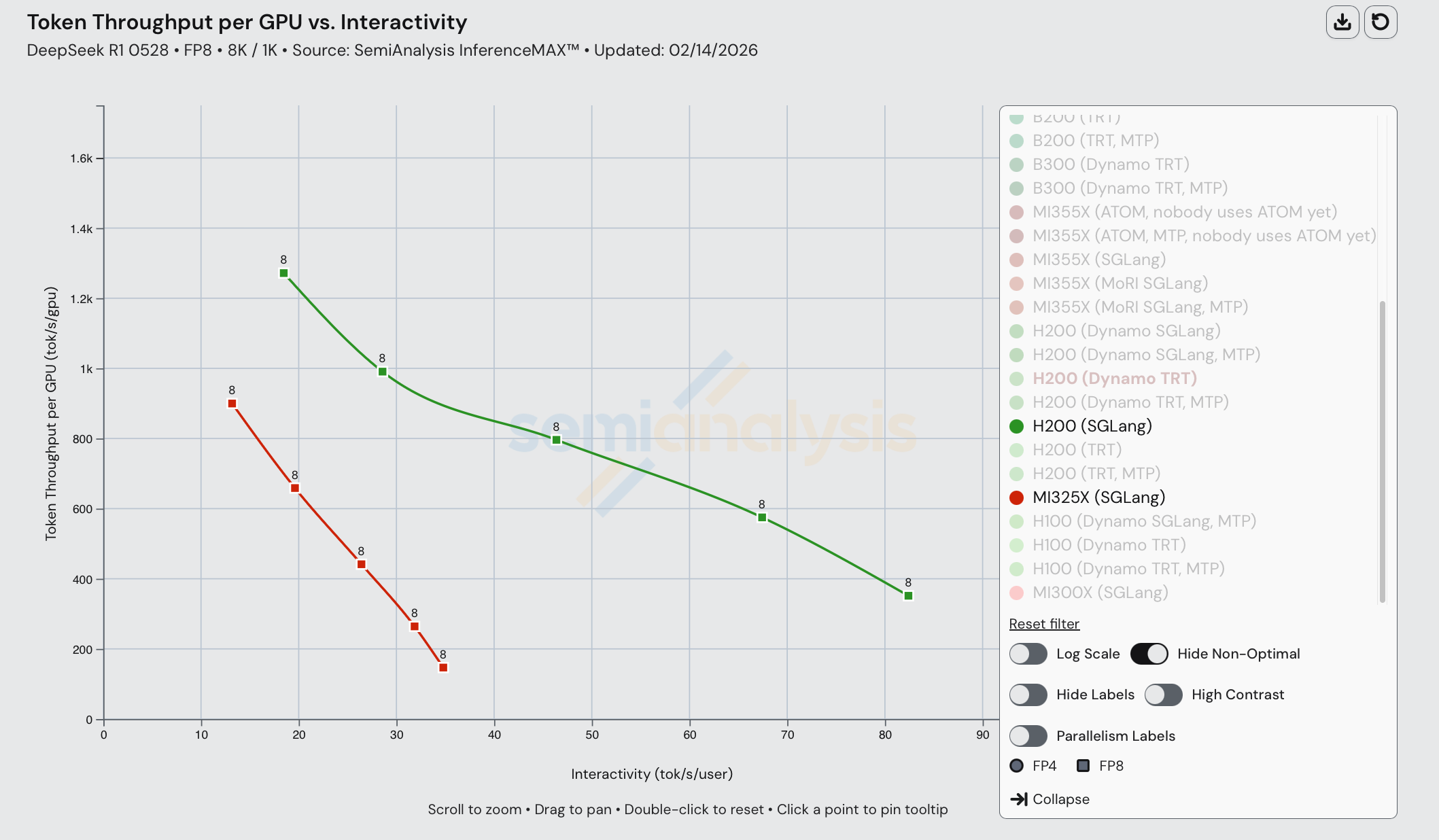
GPT-OSS 120B 单节点
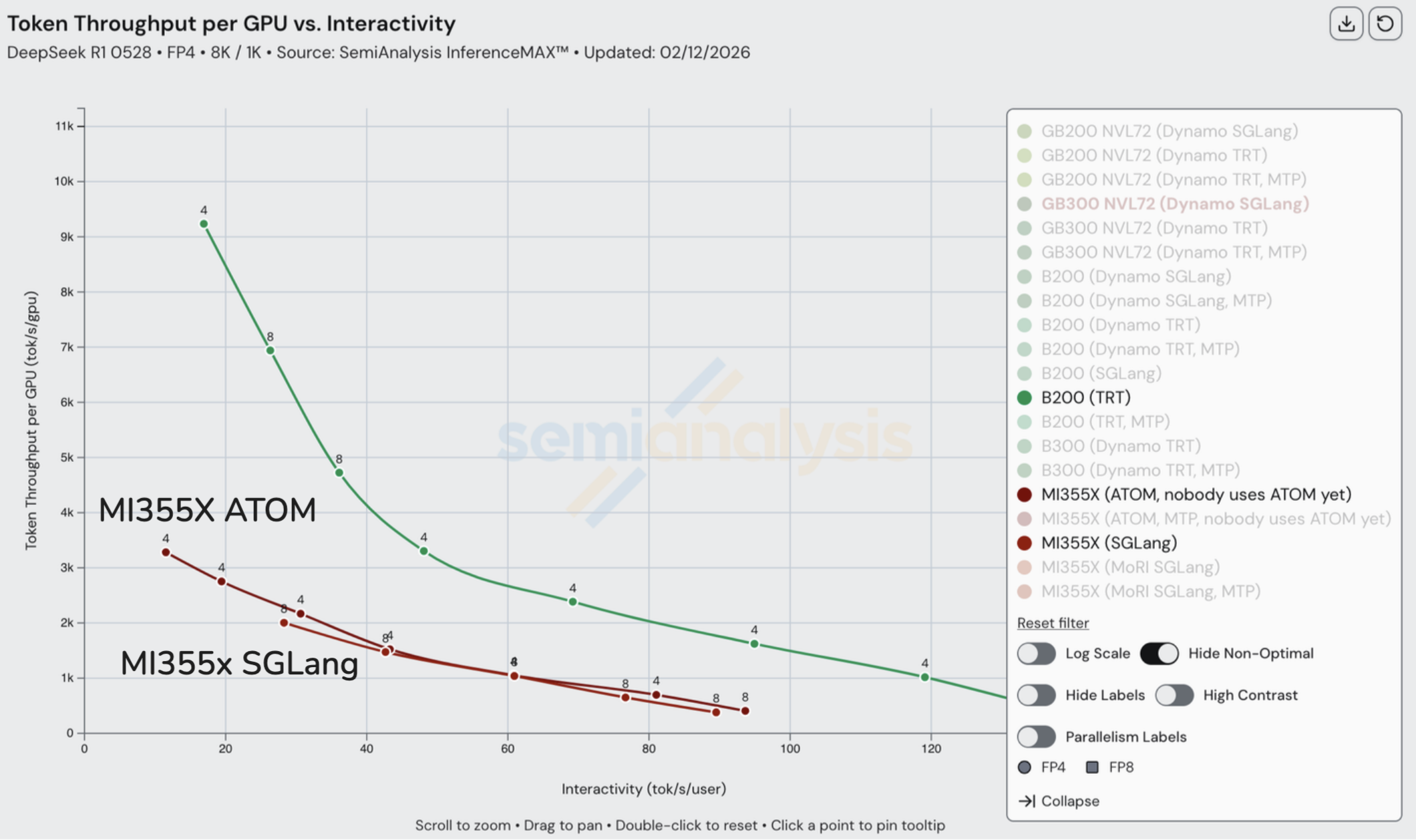
MI300X、MI325X、H200 和 H100 集中在吞吐量 vs 交互性图的左下方,表明它们之间的权衡大致相似,NVIDIA 通常保持适度领先。下一个层级是 MI355X,在给定交互性水平下每 GPU 的 token 吞吐量大约提升 2 倍以上。在 MI355X 中,ATOM 将曲线向低交互性高吞吐量方向移动,表明它优先考虑峰值吞吐量而非每用户响应速度。
在这一层级之上是 NVIDIA 的 B200 和 GB200,它们在整个前沿线上都优于 MI355X。虽然 B200 和 GB200 共享相同的 Blackwell 计算核心,但 GB200 实现了更高的吞吐量-交互性曲线,因为该平台和服务栈减少了大规模部署中的非计算瓶颈(互连/拓扑、CPU-GPU 耦合和运行时调度),从而实现了有效的横向扩展和更低的每 token 开销。
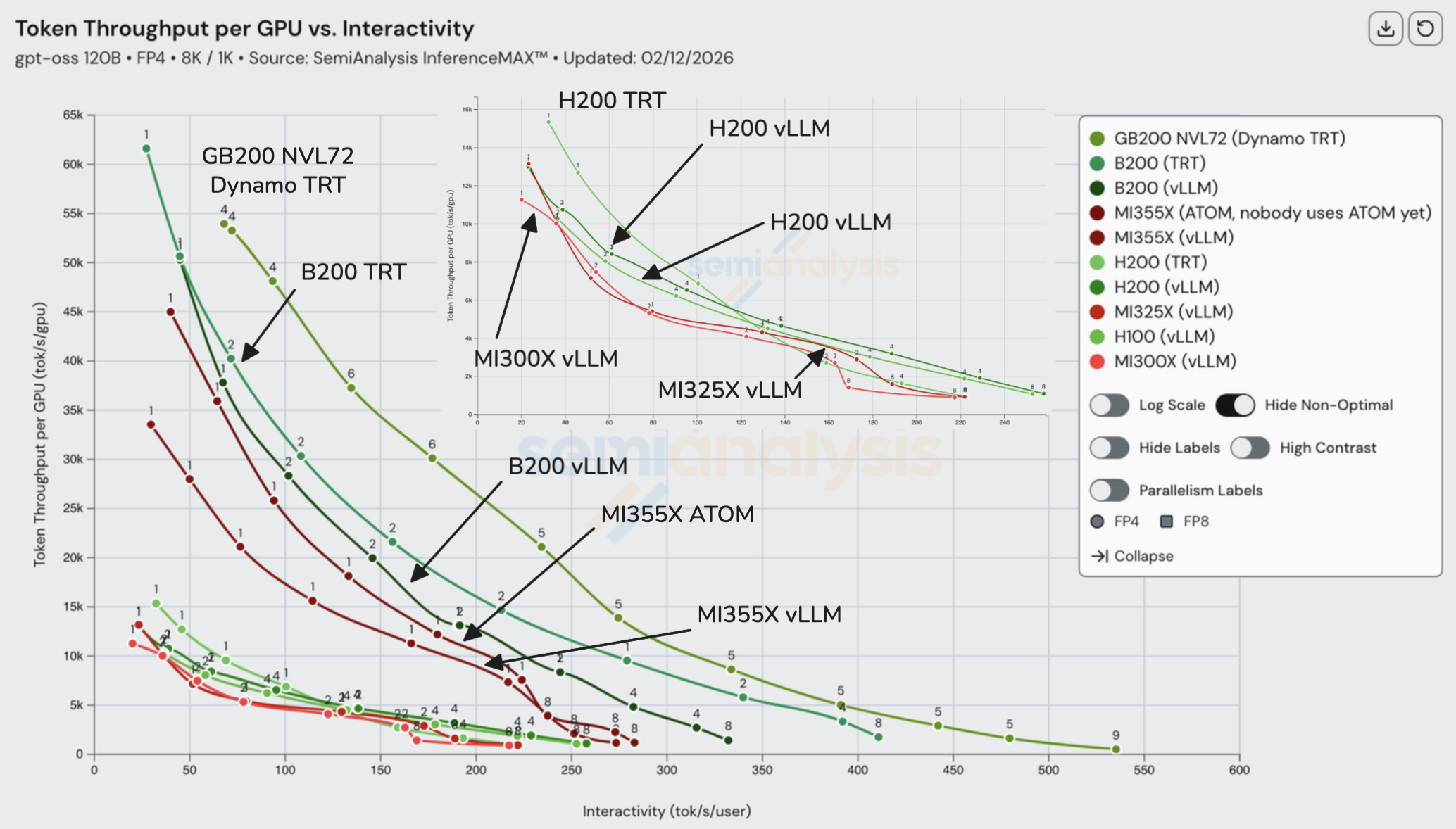
如果我们将成本纳入等式,MI355X 变得更有竞争力:在高吞吐量下优于 B200。然而,GB200 仍然是最便宜的选择。
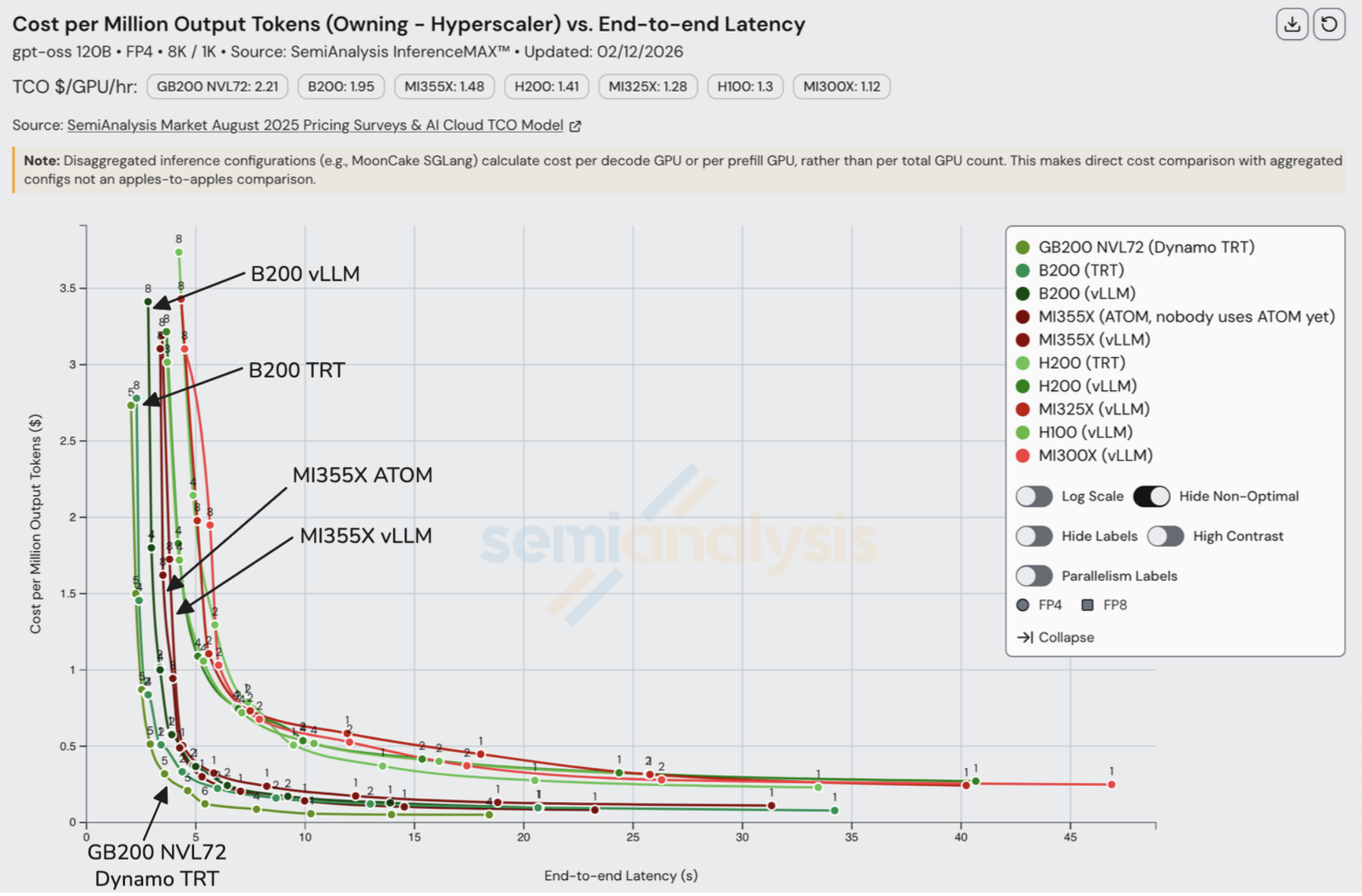
再次回到 B200 与 GB200 NVL72 的比较,NVL72 的影响显而易见。我们在本文前面讨论了 GB200 NVL72 的 72 GPU 扩展世界规模与 B200 的 8 GPU 扩展世界规模的影响。在约 100 tok/s/user 的交互性范围内,每 GPU 的输出 token 吞吐量翻了一倍以上,展示了 NVL72 更大扩展域的影响。
InferenceX 仓库核心更新
我们对 InferenceX 仓库进行了一些核心架构变更,使基准测试更易于理解和复现。此外,我们已全面拥抱 AI 工具以最大化生产力并提高开发效率。
自 InferenceXv1 以来的核心变更
我们自 v1 以来做出的主要改变之一是执行扫描的频率。此前我们每晚对每个配置执行完整扫描。然而,随着我们添加了更多芯片、分离预填充、宽 EP 和其他功能,我们意识到每晚运行既过于耗时又浪费资源。而且,这也没有必要——基准测试只有在配方变更或新软件版本发布时才真正需要重新运行。
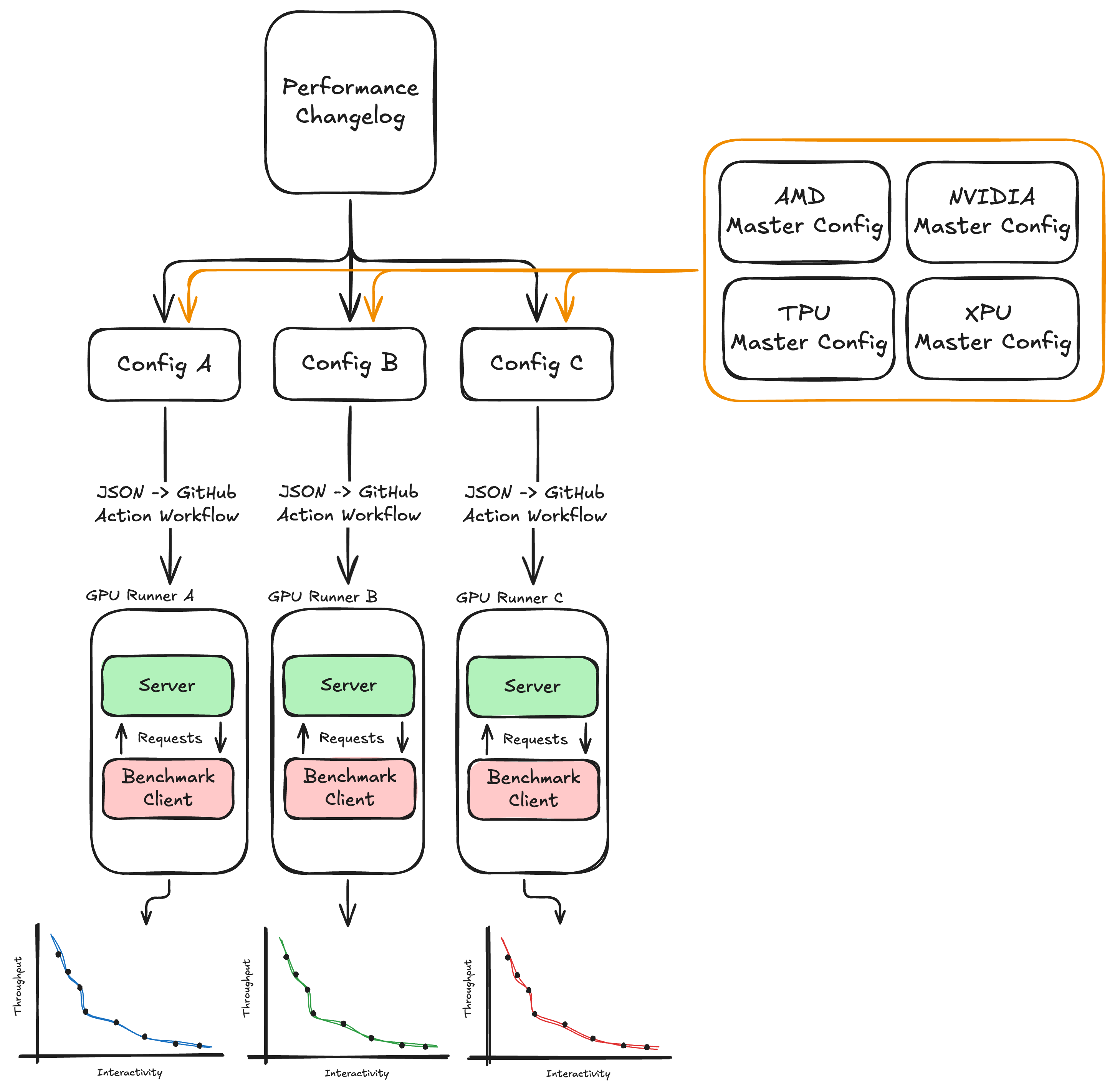
我们现在基于仓库根目录的 changelog 的修改来触发扫描。当开发者对给定配置进行了影响性能的变更时,他们会在 changelog 中添加一个条目,列出受影响的配置和变更的简要描述。所有配置定义在一个主配置 YAML 文件中,它是每个待扫描数据点的完整状态表示,包括 ISL/OSL、EP、TP、DP、MTP 等核心设置。当包含 changelog 添加的 PR 被合并时,一个工作流会解析引用的配置键,从主配置中提取相应的扫描定义,并将它们作为独立的 GitHub Actions 任务分发。这些任务收集完整扫描的所有数据点,并将结果作为产物上传。
以下是 InferenceX 启动任务的高层示意图。
Claude Code 深度 AI 应用
在 InferenceX v1 发布后不久,我们意识到不充分利用 AI 会让多少开发吞吐量白白浪费。因此,我们卷起袖子决定拥抱 Claude Code,开始一次一个 token 地吸收智能,达到了目前每天 $6,000 的消费速率。如果您想为我们年化吸收 300 万美元 Claude 智能的 KPI 做贡献,请在此申请加入使命。 我们的启蒙之旅始于发现 GitHub Copilot agent 是免费的——起初我们简直不敢相信这个功能居然不收费!很快我们意识到 Copilot 很糟糕,也就明白了为什么 GitHub 要免费赠送。要让我们继续用它,恐怕得倒贴钱给我们才行。
自 Claude Code 发布以来,我们一直在本地使用它。但最近,我们将 Claude Code 集成到了 InferenceX 的开发中,除了常规的 PR 审查等任务外,还赋予了它在集群上执行扫描的能力。通过我们搭建的工作流,Claude 可以手动启动运行、查看结果并进行迭代。这使我们能够通过 GitHub 应用轻松地在移动中部署快速修复。
另一个酷炫的用例是使用 Claude 为新的 vLLM/SGLang 镜像寻找配方。当新镜像发布时,配方有时需要更新以实现最佳性能(新环境变量、修改的引擎参数等)。通过我们的 Claude Code 集成,我们只需打开一个 issue 并要求 Claude 搜索镜像 changelog 中的所有提交,以找到需要添加到配方中的必要变更。这效果相当好,虽然不完美,但通常能提供一个良好的起点。
GitHub Actions
秉承开源精神,所有运行都在 GitHub Actions 上进行,因此基准测试结果是可验证、透明且可复现的。然而,GitHub 的故障最近一直是我们目标的持续障碍。最近我们看到的独角兽比任何其他动物都多!但也许是时候出去接触一下大自然了。
Microsoft/GitHub 自己也意识到了这个问题,已停止在其状态页面上更新综合正常运行时间数字,在过去 90 天内只剩下一个 9:97.36%。忽视问题并不会让它消失...
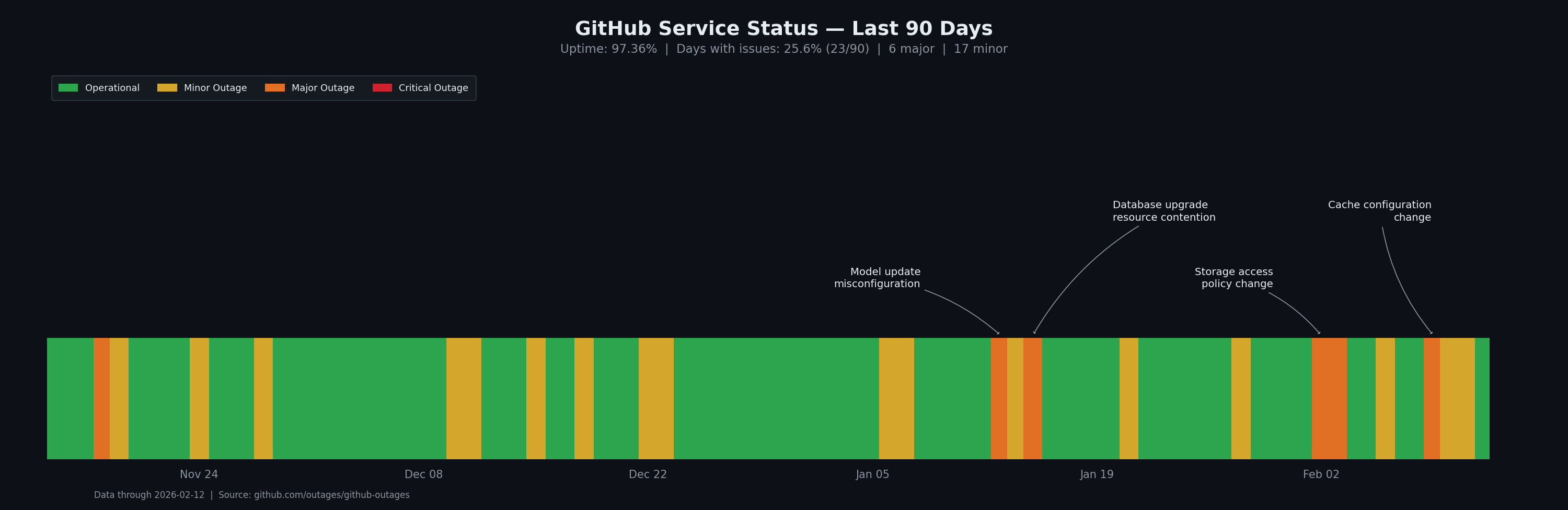
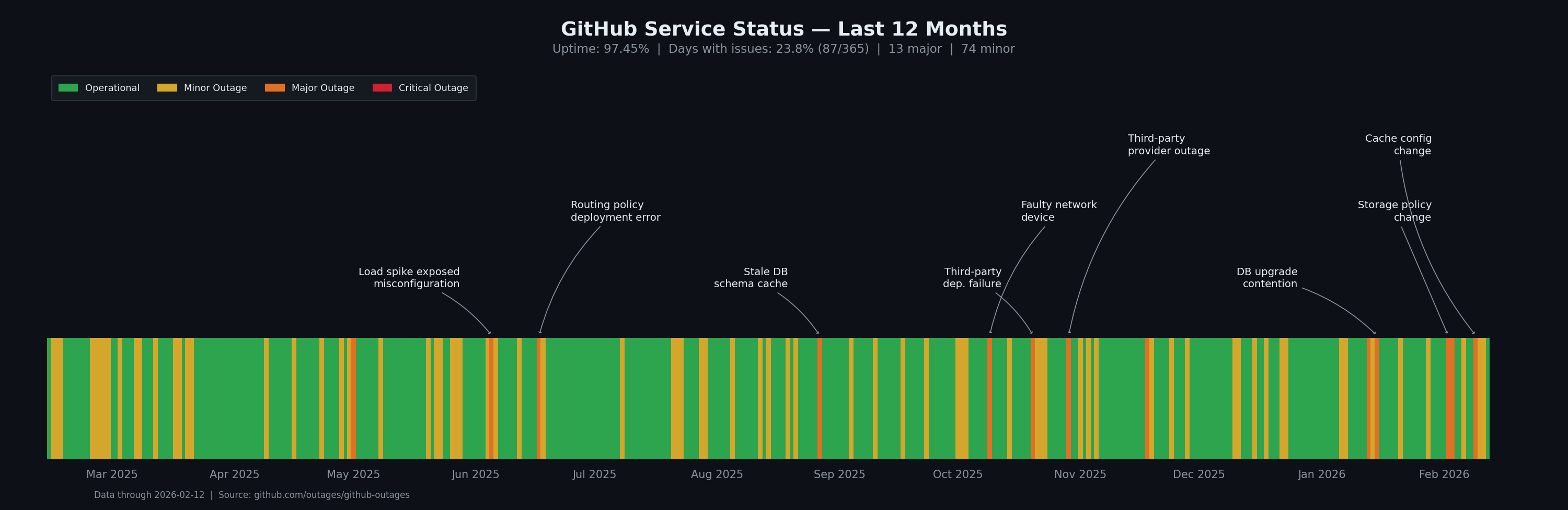
总的来说,GitHub Actions 只是勉强够用。它为开发者提供了一种平庸的体验。它显然不是为在数百块 GPU 的集群上启动数千个任务而设计的。尽管如此,自发布以来我们与一些 GitHub Actions 工程师进行了密切合作以更好地满足 InferenceX 的需求,我们可以自信地说他们非常好合作。此外,我们的一个直接需求是在点击工作流运行时实现任务的懒加载,虽然他们花了一些时间,但最终实现了这一功能。
InferenceX 的未来
自 2025 年 10 月初 InferenceX 首次发布以来,我们一直在努力持续改进。发布后,我们花了一些时间重构代码库使其更具可扩展性,使新模型和推理技术现在可以"即插即用"地添加。这些改变使我们能够无缝集成 H100、H200、B200、B300、GB200、GB300 和 MI355X 的 PD-disagg 基准测试。我们还在默认基准测试管线中添加了精度评估,以确保在所有配置中对模型性能的可见性。
虽然自发布以来我们做了很多改进,但要达到提供最贴近真实世界推理基准测试这一北极星目标,仍有大量工作要做。为此,我们计划在真实数据集上进行基准测试、添加智能体编码性能基准测试、包含更多 SOTA 推理优化、测试更多模型,以及更多。
迁移至多轮真实多轮对话和智能体编码数据集
目前,InferenceX 使用完全随机的 token 作为基准测试的输入。然后我们在 [ISL*0.8, ISL] 分布下均匀变化 ISL/OSL,OSL 类似。由于使用随机数据,我们在所有基准测试中禁用了前缀缓存,因为完全随机数据的前缀缓存命中率期望值为 0%。此外,所有随机数据都是单轮的,意味着每个对话只包含一个提示和一个回答。虽然这提供了良好的基线帕累托前沿,但它不是模拟真实世界生产推理工作负载的实际基准测试方案。
在近期,我们将使用类似 allenai/WildChat-4.8M 这样的数据集创建基础多轮基准测试,该数据集记录了真实用户的多轮对话。除了在所有场景中启用前缀缓存外,我们还将启用 KV 缓存 CPU 卸载,因为这是我们在生产工作负载中看到的做法。这将更准确地评估每款芯片的优缺点。例如,MI355X 拥有 288GB HBM3e 而 B200 仅有 192GB。因此,我们预期 MI355X 在高并发多轮场景中表现更好,因为更多内存可以分配给 KV 缓存。另一方面,在 GPU KV 缓存紧张、块被卸载到 CPU 的场景中,我们预期 GB 系列表现更优,因为这些芯片拥有 900 GB/s 双向 CPU-GPU 带宽,相比之下 HGX 使用 PCIe 5.0 和 6.0 分别只有 128 GB/s 和 256 GB/s。此外,我们目前看到 AMD 的 CPU 卸载软件表现不佳,这可能在相同场景中对性能产生负面影响。
关键是:真实世界的多轮数据集测试了更多 SOTA 推理引擎功能,能够在所有芯片上捕获更细致和可靠的性能数据。
随着 Claude Code、Codex 和 Kimi 的兴起,在智能体编码场景中进行性能基准测试变得越来越重要。与上述类似,这些场景是多轮的,但还包括超长上下文对话以及工具使用。在接下来几个月中,我们计划创建一个基准测试套件,能够在所有芯片上最准确地捕获开放模型在这些智能体编码场景中的性能。
添加 TPU、Trainium 及更多模型
目前,我们持续对 DeepSeek R1 和 GPT OSS 120B(此前还有 Llama 3.1 70B)进行基准测试。为了跟上最新的模型架构,我们计划在接下来几个月内添加 DeepSeek V3.2(含 DSA)、DeepSeek V4 首日支持、Kimi K2.5、Qwen3、GLM5 等众多模型。我们还将最终添加多模态模型,并使用 EPD 和 CFD(由 TogetherAI 发明)优化。
除了新模型外,我们正在积极推进添加 TPU 和 Trainium 的工作。
总拥有成本(NVL72、Blackwell、Blackwell Ultra、MI355、Hopper、MI325、MI300)
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
本文完整版发布在我们的 Substack 上。订阅 SemiAnalysis 阅读完整文章。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。