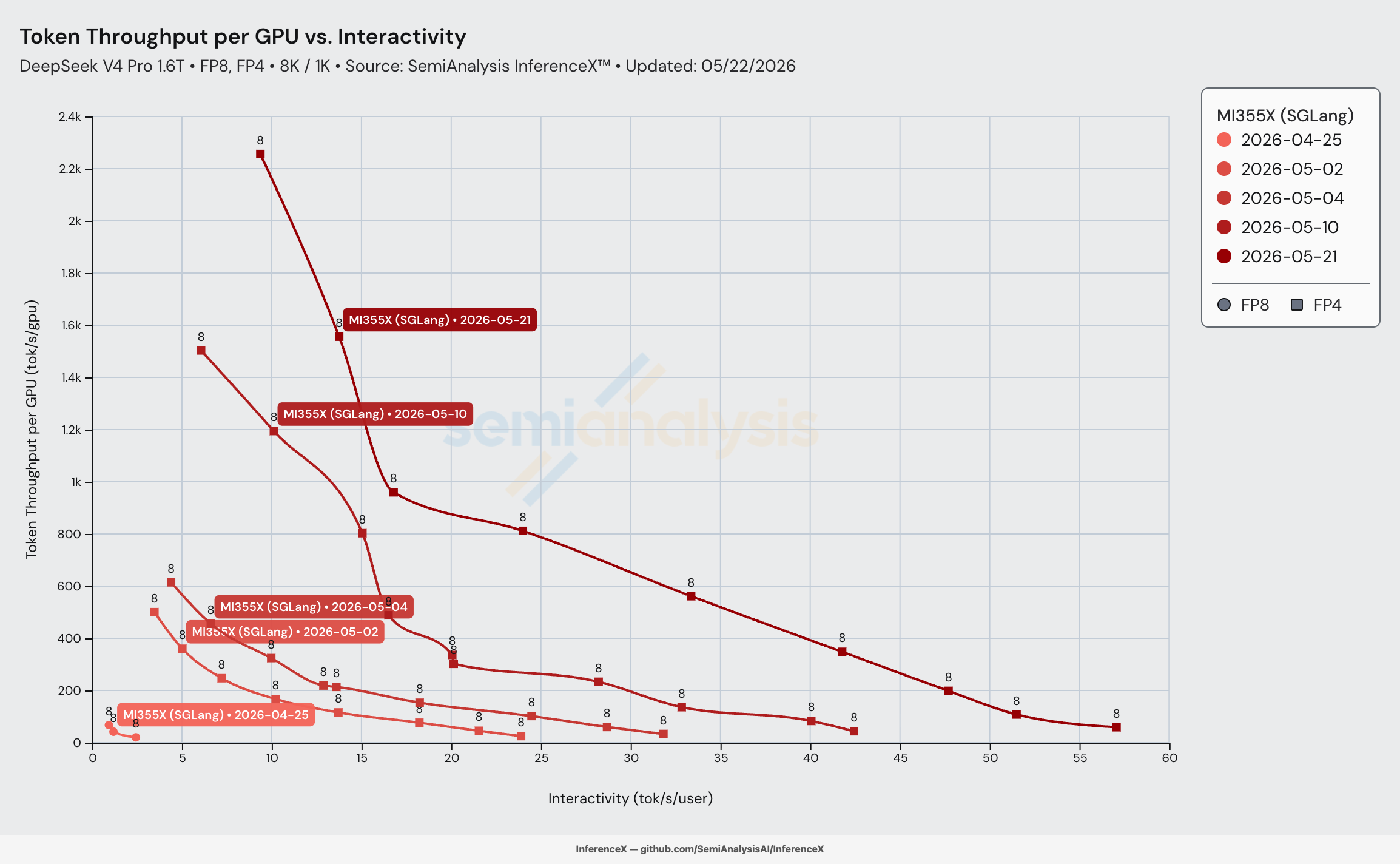
26 days after DeepSeek-V4-Pro's release on 2026-04-24, AMD MI355X SGLang on the sgl-project/sglang amd/deepseek_v4 side branch hits 2,256 tok/s/GPU at 9.4 tok/s/user on the 8K/1K workload — 110.5x the 20.4 tok/s/GPU at 2.4 tok/s/user first-light point from 2026-04-25, and the rare result where both axes climb together: throughput per GPU up 110.5x and interactivity up 3.85x at the same time. SemiAnalysis called the 14-day stretch ~75x at the kernel level; the dashboard now captures another 12 days of optimization on top.
31 performance optimization PRs on the AMD side branch did the heavy lifting in a tight relay: FP4 weight enablement (#24031), TileLang attention indexer for DeepSeek Sparse Attention (#24033, #24050), Triton sparse MLA kernel and its later fused-dispatch optimization (#24930, #25878, #25977), fused multi-head compress / RoPE / Hadamard (#24355, #24727, #26014), FlyDSL MoE (#24971), fused hash topk (#24728), AITER MHC pre/post, and a half-dozen compressor element-wise kernel fusions. Speed is the moat.
DeepSeek-V4-Pro Model Architecture
DeepSeek-V4-Pro is DeepSeek's flagship MoE: 1.6T total parameters with 49B activated per token (per the DeepSeek V4 preview announcement). The architecture pairs a novel token-wise compression path with DSA (DeepSeek Sparse Attention) — the same sparse-attention pattern DeepSeek introduced in V3.2 but extended to a longer context (the official services run DSv4 at 1M context by default). The vendor framing for V4-Pro is "peak efficiency: world-leading long context with drastically reduced compute & memory costs"; the open-weights checkpoint is deepseek-ai/DeepSeek-V4-Pro.
The attention mechanism is the central reason the SGLang AMD fork has so many kernels to write. Token-wise compression introduces a multi-head compress (mHC) pre/post pair around the attention block — runtime fuses these with RoPE and Hadamard transforms below — and DSA on the decode path needs a separate attention indexer plus a sparse MLA kernel that walks only the routed positions. The whole stack is new enough that the upstream main branch couldn't run DeepSeek-V4-Pro on Blackwell or ROCm at launch; the AMD fork is what closes that gap on MI355X.
FP4 weight support on MI355X wasn't there at launch either. The 2026-04-25 first-light measurement is FP8 — and required SGLANG_HACK_FLASHMLA_BACKEND=torch plus a --time=300 SLURM bump just to get past the ~30 min MoE JIT compile without hitting the 3 h CI cap — because PR #24031 (kk, 2026-04-29) hadn't yet enabled the FP4 model path on ROCm. Once that landed (plus the matching InferenceX recipe on 2026-05-02 that flipped SGLANG_DSV4_FP4_EXPERTS=True and pulled the FP4 weights of deepseek-ai/DeepSeek-V4-Pro), the curve moved into a measurable serving regime. Every date in this post from 2026-05-02 onward is FP4; only 2026-04-25 is FP8.
DeepSeek-V4-Pro vs Claude Opus 4.6 vs GPT-5.4 vs Gemini 3.1 Pro
DeepSeek published the V4-Pro-Max evaluation at preview against Claude Opus 4.6, GPT-5.4-xHigh, and Gemini 3.1-Pro-High across knowledge/reasoning and agentic benchmarks. Quality-wise this is an open-source frontier coding model:
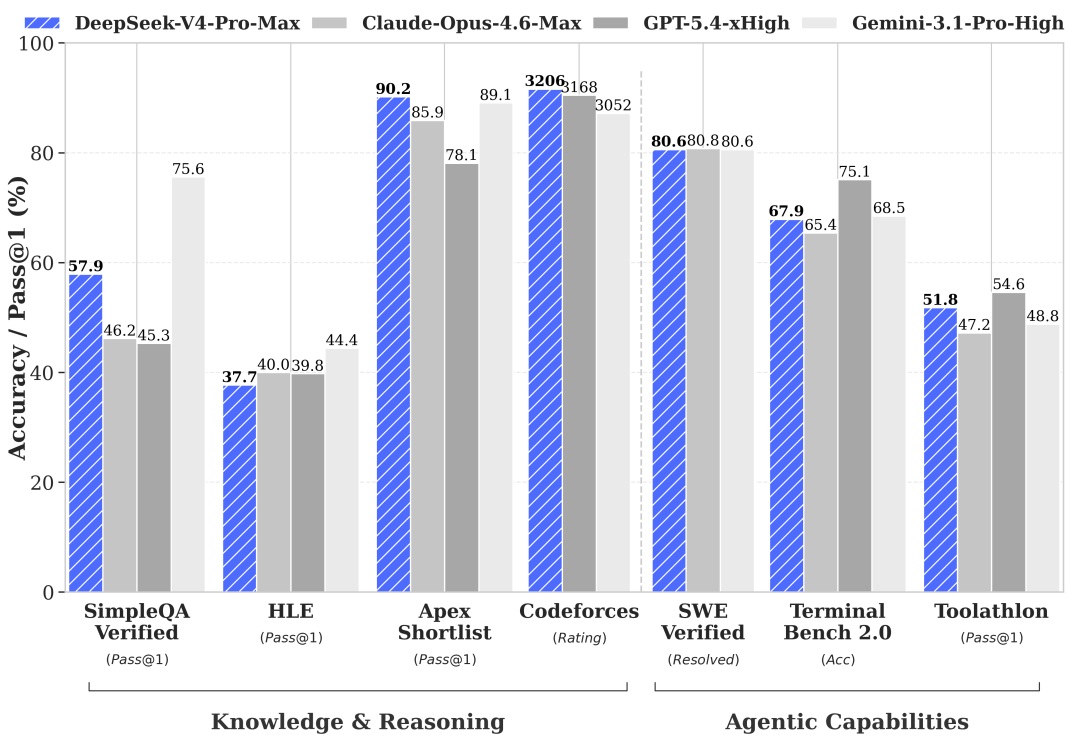
That quality bar is the reason the AMD SGLang team under the leadership of HaiShaw treated MI355X serving as a 14-day sprint: a frontier open-weights coding model is worth the engineering investment, and once a usable curve exists on AMD silicon every percentage point of perf/$ on the serving stack moves real workloads.
What Shipped to Make This Happen
Upstream stack: the amd/deepseek_v4 SGLang side branch. sgl-project/sglang amd/deepseek_v4 is an actively rebased side branch landing AMD-specific DeepSeek-V4-Pro kernels in numbered performance optimization PRs. 31 PRs through 2026-05-22, four primary contributors. Every measurement in this post was taken against side-branch images, not SGLang main (see What's Next for the upstreaming story). The optimizations that moved the curve, grouped by mechanism:
- DSA attention (TileLang indexer + Triton sparse MLA). #24033 (Thomas Wang, 04-29) ports the TileLang attention path to ROCm; #24050 (Thomas Wang, 04-29) adds the attention indexer in TileLang; #24930 (amd-danli103, 05-11) introduces the Triton sparse MLA kernel; #25878 (05-20) and #25977 (jacky.cheng, 05-22) fuse the gather + attention path into single dispatches for prefill and extend respectively.
- mHC fusion (multi-head compress, token-wise compression path). #24355 (kk, 05-04) "optimize mhc performance"; #24424 (Thomas Wang, 05-05) compressor element-wise kernel fusion; #25020 (Xinyi Song, 05-12) compressor optimization; #25245 (jacky.cheng, 05-15) fused softmax pool Triton kernel for compressor; #25353 (Xinyi Song, 05-15) "enable new compressor path"; #26014 (Xinyi Song, 05-22) Triton fused mhc_post_pre for low concurrency.
- RoPE + Hadamard fusion. #24727 (Xinyi Song, 05-09) fuses RoPE Hadamard using
rope_rotate_activation— eliminates a CPU-side launch and improves HBM utilization on the per-step decode loop. #24249 (Xinyi Song, 05-02) does the analogous fused compress-decode kernel. - MoE: FlyDSL + FP4 + fused hash topk. #24031 (kk, 04-29) enables the FP4 model path; #24728 (Xinyi Song, 05-09) fuses the hash topk routing step; #24971 (Thomas Wang, 05-11) lands the FlyDSL MoE backend for ROCm; #25070 (Thomas Wang, 05-12) adds the swiglu-limit dense MoE / shared expert path.
- AITER kernels + misc fusions. Cherry-picked AITER MHC pre/post fix on 05-07 (commit b639cb6); #25043 (jacky.cheng, 05-12) fuses input_layernorm with FP8 per-128 group quant on the attention path; #25251 (jacky.cheng, 05-19) uses AITER
greedy_samplefor all-greedy sampling; #25097 (Raiden Makoto, 05-13) Triton fused store cache for ROCm; #25375 (Thomas Wang, 05-18) rmsnorm_quant fusion for the wqb input.
InferenceX recipe loop. The InferenceX benchmark recipe absorbed each upstream wave with image bumps roughly every 2–3 days through the optimization phase: container images progressed from rocm/sgl-dev:v0.5.10rc0-rocm720-mi35x-20260414 (04-25, FP8 only, recipe needed SGLANG_HACK_FLASHMLA_BACKEND=torch to even compile) → rocm/sgl-dev:rocm720-mi35x-583b1b6-20260501-DSv4 (05-02, FP4 enabled via SGLANG_DSV4_FP4_EXPERTS=True) → a8410de6-20260502 (05-03, fused-compress-decode) → bfd32b6-20260507 (05-08, AITER MHC pre/post + Triton SWA prepare) → 0363e6c-20260509 → b19052c-20260518 (05-19, stable lmsysorg/sglang:v0.5.12-rocm720-mi35x repo with Triton attention backend, FlyDSL MoE, fused hash topk) → 8c3b5aa-20260521 (05-21 final). Recipe tuning between image bumps tightened --num-continuous-decode-steps (4 → 8, +4.7%), drove --max-running-requests and --cuda-graph-max-bs from the matrix concurrency value, and enabled --enable-prefill-delayer on the DP-attention configurations.
The Numbers
All rows are DeepSeek-V4-Pro at ISL 8192 / OSL 1024 on a single MI355X 8-GPU node, measured on InferenceX between 2026-04-25 and 2026-05-21. Throughput is per-GPU. Precision: 2026-04-25 is FP8 (the only path that worked at launch); 2026-05-02 onward is FP4 on deepseek-ai/DeepSeek-V4-Pro with SGLANG_DSV4_FP4_EXPERTS=True. DP attention engaged at high concurrency in the later runs.
2026-04-25 (FP8, baseline first-light):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 8 | 20.4 | 2.43 | 411 |
| 32 | 42.0 | 1.19 | 843 |
| 64 | 67.4 | 0.93 | 1,074 |
2026-05-02 (FP4 first light, +TileLang attention, FP4 enablement):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 25.2 | 23.89 | 41.86 |
| 2 | 45.4 | 21.65 | 46.41 |
| 4 | 76.5 | 18.38 | 54.87 |
| 8 | 115.8 | 13.87 | 72.92 |
| 16 | 167.2 | 10.07 | 97.87 |
| 32 | 247.0 | 7.33 | 138.64 |
| 64 | 359.9 | 5.23 | 199.14 |
| 128 | 500.2 | 3.61 | 288.50 |
2026-05-04 (+fused compress-decode, +TileLang MHC post, dropped Torch fallback):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 33.3 | 31.82 | 31.43 |
| 4 | 102.1 | 24.65 | 40.86 |
| 8 | 153.0 | 18.43 | 54.82 |
| 16 | 218.9 | 13.04 | 77.62 |
| 32 | 324.2 | 10.10 | 100.26 |
| 64 | 455.7 | 6.86 | 151.33 |
| 128 | 614.6 | 4.54 | 227.59 |
2026-05-10 (+AITER MHC pre/post, +Triton SWA prepare, +FlyDSL MoE preview):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 43.9 | 42.44 | 23.56 |
| 4 | 136.0 | 33.11 | 30.45 |
| 8 | 233.4 | 28.63 | 35.44 |
| 16 | 336.1 | 20.33 | 49.86 |
| 32 | 488.3 | 16.80 | 60.58 |
| 64 | 802.9 | 14.81 | 66.43 |
| 128 | 1,194.3 | 10.17 | 98.80 |
| 256 | 1,503.2 | 6.14 | 164.86 |
2026-05-21 (latest: SGLang v0.5.12 + Triton attention backend + fused hash topk + FlyDSL MoE):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) |
|---|---|---|---|
| 1 | 59.2 | 57.06 | 17.52 |
| 4 | 198.5 | 47.71 | 20.96 |
| 8 | 348.2 | 41.78 | 23.94 |
| 16 | 561.3 | 33.37 | 29.97 |
| 32 | 811.7 | 23.99 | 41.68 |
| 64 | 959.6 | 16.79 | 59.56 |
| 128 | 1,556.0 | 13.76 | 72.69 |
| 256 | 2,256.1 | 9.37 | 106.75 |
| 512 | 1,814.4 | 5.59 | 178.90 |
The bolded row is the headline: 2,256 tok/s/GPU at 9.4 tok/s/user on conc 256 with DP attention — 110.5x the 20.4 tok/s/GPU at 2.4 tok/s/user first-light point on 04-25 (and 33.5x even the 67.4 tok/s/GPU 04-25 peak at 0.9 tok/s/user, which wasn't a serving operating point). New ceiling for MI355X DSv4-Pro single-node aggregated serving.
Iso-Interactivity Throughput Comparison
Throughput per GPU at matched interactivity, interpolated along each date's Pareto frontier. 2026-04-25 doesn't reach any interactivity above 2.5 tok/s/user, so every row reads _unreachable_ for that date — the model wasn't yet operating in a serving regime. Cells outside a frontier's measured range render as _unreachable_.
| Interactivity (tok/s/user) | 04-25 | 05-02 | 05-04 | 05-10 | 05-21 | 05-02 → 05-21 |
|---|---|---|---|---|---|---|
| 8 | unreachable | 221 | 401 | 1,363 | unreachable | ∞ |
| 10 | unreachable | 169 | 328 | 1,208 | 2,162 | 12.8x |
| 12 | unreachable | 136 | 247 | 1,065 | 1,855 | 13.6x |
| 15 | unreachable | 104 | 194 | 775 | 1,272 | 12.2x |
| 17 | unreachable | 88 | 169 | 473 | 951 | 10.8x |
| 20 | unreachable | 61 | 139 | 361 | 876 | 14.3x |
| 25 | unreachable | unreachable | 99 | 266 | 788 | ∞ |
| 30 | unreachable | unreachable | 50 | 205 | 653 | ∞ |
| 40 | unreachable | unreachable | unreachable | 89 | 393 | ∞ |
| 50 | unreachable | unreachable | unreachable | unreachable | 140 | ∞ |
The headline is 12–14x throughput-per-GPU at iso-interactivity from 2026-05-02 to 2026-05-21 in the 10–20 tok/s/user serving band. The lift cascades date-over-date — every image bump moved the curve another 1.6–4.4x. The high-interactivity arm (25+ tok/s/user) opened up entirely after 05-04, and 50 tok/s/user only became measurable on 05-21 with the latest FlyDSL MoE + fused hash topk kernels in lmsysorg/sglang:v0.5.12-rocm720-mi35x.
Live chart, pre-filtered to MI355X SGLang DSv4-Pro across the 5 measured dates.
What's Next for MI355X DeepSeek-V4-Pro
The remaining gap to NVIDIA on DSv4-Pro is not silicon — it is software. On paper, the MI355X die has more HBM (288 GB vs B200's 180 GB — 1.60x capacity), the same 8 TB/s HBM bandwidth, and slightly more dense per-GPU compute across the board (FP4 / FP8 / BF16 all at 1.12x B200). The one silicon axis where B200 leads is intra-node scale-up bandwidth — NVLink 5 at 900 GB/s uni-directional vs 5th Gen Infinity Fabric at 576 GB/s, a 1.56x edge — and at single-node TP=8 on a 1.6T-active-49B MoE that delta is a smaller lever than the kernel-stack maturity gap the AMD fork is still closing.


| Spec | MI355X | B200 SXM | MI355X / B200 |
|---|---|---|---|
| HBM capacity | 288 GB | 180 GB | 1.60x |
| HBM bandwidth | 8 TB/s | 8 TB/s | 1.00x |
| Dense FP4 (TFLOP/s) | 10,066 | 9,000 | 1.12x |
| Dense FP8 (TFLOP/s) | 5,033 | 4,500 | 1.12x |
| Dense BF16 (TFLOP/s) | 2,516 | 2,250 | 1.12x |
| Scale-up BW per GPU (uni-di) | 576 GB/s (Infinity Fabric) | 900 GB/s (NVLink 5) | 0.64x |
| Scale-up world size | 8 | 8 | 1.00x |
| Scale-up domain HBM capacity | 2.30 TB | 1.44 TB | 1.60x |
| Scale-up domain HBM BW (aggregate) | 64 TB/s | 64 TB/s | 1.00x |
So when the measured B200 SGLang DSv4-Pro curve sits ~5x above MI355X SGLang in the 15–30 tok/s/user serving band on the exact same FP4 / 8K / 1K workload, that gap is not flops, not HBM capacity, not HBM bandwidth, and barely scale-up bandwidth. It is upstream kernel coverage, fusion completeness, and scheduler tuning — exactly the surface the amd/deepseek_v4 fork is rebasing against, exactly the gap that shrank 110.5x in 26 days:
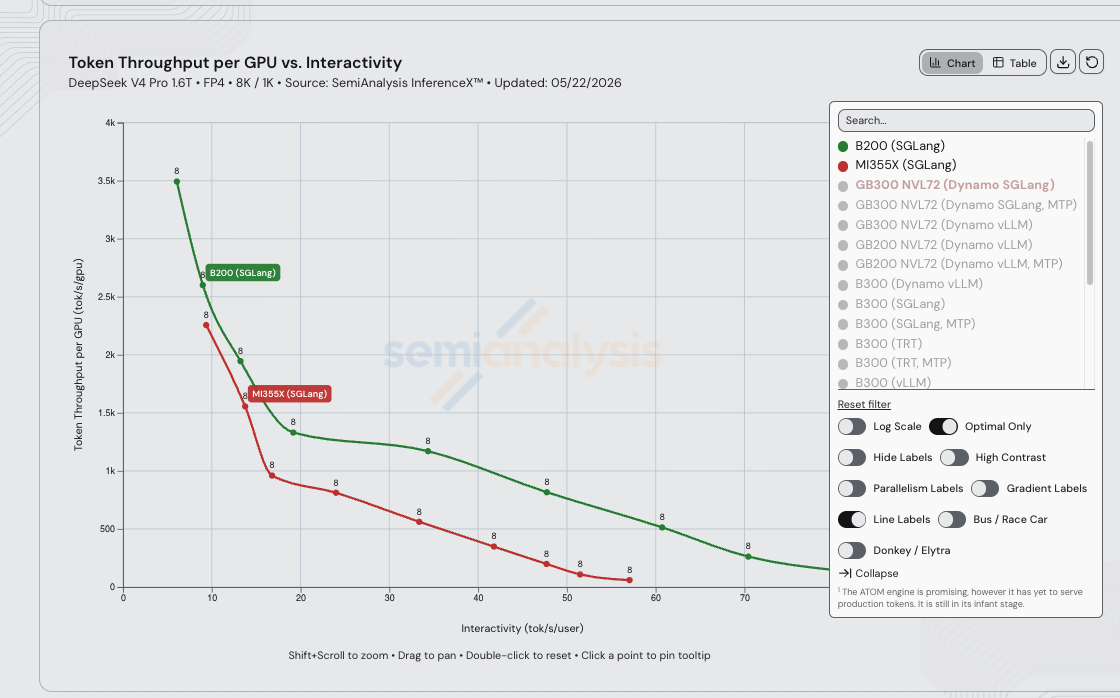
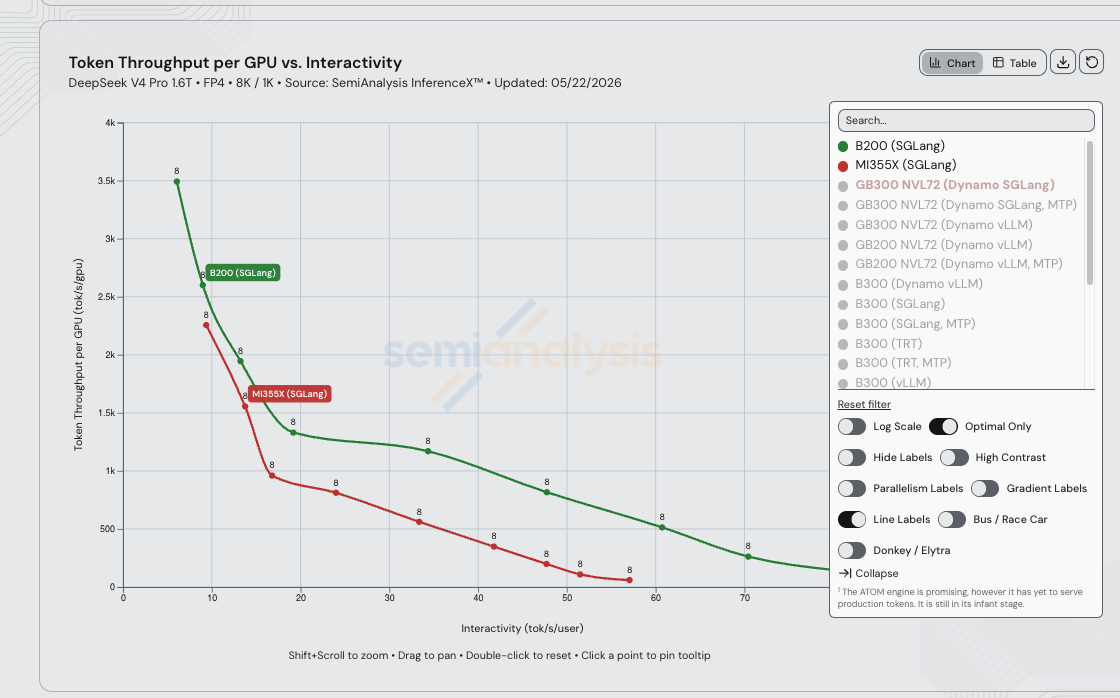
Per the SemiAnalysis assessment, the closing steps:
- ~5x more throughput needed to catch single-node aggregated B200. The B200 SGLang stack on DSv4-Pro already reaches the multi-thousand tok/s/GPU range out to 70+ tok/s/user that MI355X SGLang only touches at the low-interactivity left edge. Closing it is realistic for AMD within the next couple of weeks at the current PR cadence on the
amd/deepseek_v4fork — the silicon supports it, the kernels just need to catch up. - Another ~1.5x for PD-disaggregated B200. No InferenceX disagg recipe for MI355X DSv4-Pro has shipped yet. The
mori-sglangAMD disagg fork has the prefill/decode separation primitives, but they haven't been wired into the DSv4-Pro recipe in the InferenceX loop. - Sustained kernel cadence on the AMD fork. The 31-PR pace is what produced the 110.5x lift; the open compare view is still adding performance optimization PRs every 2–3 days, so the curve in this post will already be stale by next week. The new compressor path (#25353) and the fused nosplitk attention dispatch for extend (#25977) shipped after the 2026-05-21 dataset and are not yet reflected.
- Side branch → SGLang main upstream migration. The first chunk landed in PR #24933 (kk, merged 2026-05-18, +3,678 / -70 across 17 files) — enough to run DSv4-Pro on ROCm in eager mode on SGLang main via
is_hip/use_aitergating, Triton replacements for the JIT-fused kernels that don't compile on ROCm, and a new HIP attention backend for the DSv4 attention path. The PR description explicitly flags the follow-on work: "subsequent PRs to merge remaining DSv4 optimizations fromamd/deepseek_v4branch" — compression flow fusion, multi-stream enablement, the TileLang attention indexer, FlyDSL MoE, and the perf-critical SGLANGOPT* toggles all remain side-branch-only as of 2026-05-22. Until those migrate, MI355X DSv4-Pro serving on SGLangmainwill under-perform what this post measured by an order of magnitude — the side-branch images (lmsysorg/sglang:v0.5.12-rocm720-mi35x-*) remain the only way to reproduce the curves above.
For MI355X DSv4-Pro serving today, the 2026-05-21 recipe on lmsysorg/sglang:v0.5.12-rocm720-mi35x-20260517 is the production frontier — anything earlier than 05-10 should not be benchmarked against.
Acknowledgments
The 31 performance optimization PRs are the work of Thomas Wang (TileLang attention indexer, FlyDSL MoE, compressor element-wise fusion, attn early-exit with CUDA graph, rmsnorm-quant fusion), Xinyi Song (fused compress-decode, fused RoPE Hadamard, fused hash topk, compressor optimization), HaiShaw (integration coordination + ENV setup), amd-danli103 (Triton sparse MLA + fused dispatch), jacky.cheng (input_layernorm + FP8 per-group quant fusion, softmax pool, AITER greedy_sample), kk (FP4 enablement, MHC perf, fuse_wqkv), Raiden Makoto (Triton fused store cache), Xinyu Jiang (radix opt), and the broader AMD AI team. Speed of the upstream-to-benchmark loop is the moat.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.