Kimi K2.5 和 K2.6 是 xAI Cursor Composer 2 和 Composer 2.5 背后的开源权重模型——Cursor IDE 日活用户超百万,且 K2.6 以 58.6% 的成绩领跑 SWE-Bench Pro。在 8K/1K 工作负载下,vLLM 在 NVIDIA B200 上以 NVFP4 运行 K2.5/K2.6,在整个单节点 Pareto 前沿上均比 H200 INT4 更便宜。在 30–90 tok/s/user 推理区间内,B200 NVFP4 每百万 tokens 成本比 H200 INT4 低 2.71x–2.95x,峰值为 32 tok/s/user 时的 2.95 倍(B200 NVFP4 为 $0.140/M vs H200 INT4 为 $0.413/M——成本降低 66%)。在相同 B200 硬件上,从 INT4 切换到 NVFP4 在等交互性下还可额外带来 2.45x–2.74x 的优势(40 tok/s/user 时 $0.397/M → $0.154/M)。数据来自 SemiAnalysis InferenceX,2026-05-19,GHA run 26118912054。
两款 SKU 均运行相同的 vllm/vllm-openai:v0.21.0 容器。差距来自硬件和精度。B200 的 FP8 dense 吞吐量是 H200 的 2.27 倍(4,500 vs 1,979 TFLOP/s)、HBM 带宽 1.67 倍(8 vs 4.8 TB/s)、NVLink Scale-up 带宽 2.00 倍(900 vs 450 GB/s 单向)。在 FP4 轴上 H200 完全空白——Hopper SM90 没有 FP4 张量核心,官方数据表止步于 FP8。B200 的 NVFP4 核心提供 9,000 TFLOP/s。实测的约 3 倍 token 成本差距,就是这些硅片比值在折算 B200 1.38 倍 TCO 溢价($1.95 vs $1.41/GPU/hr,来源于 SemiAnalysis AI Cloud TCO 模型)之后的呈现。
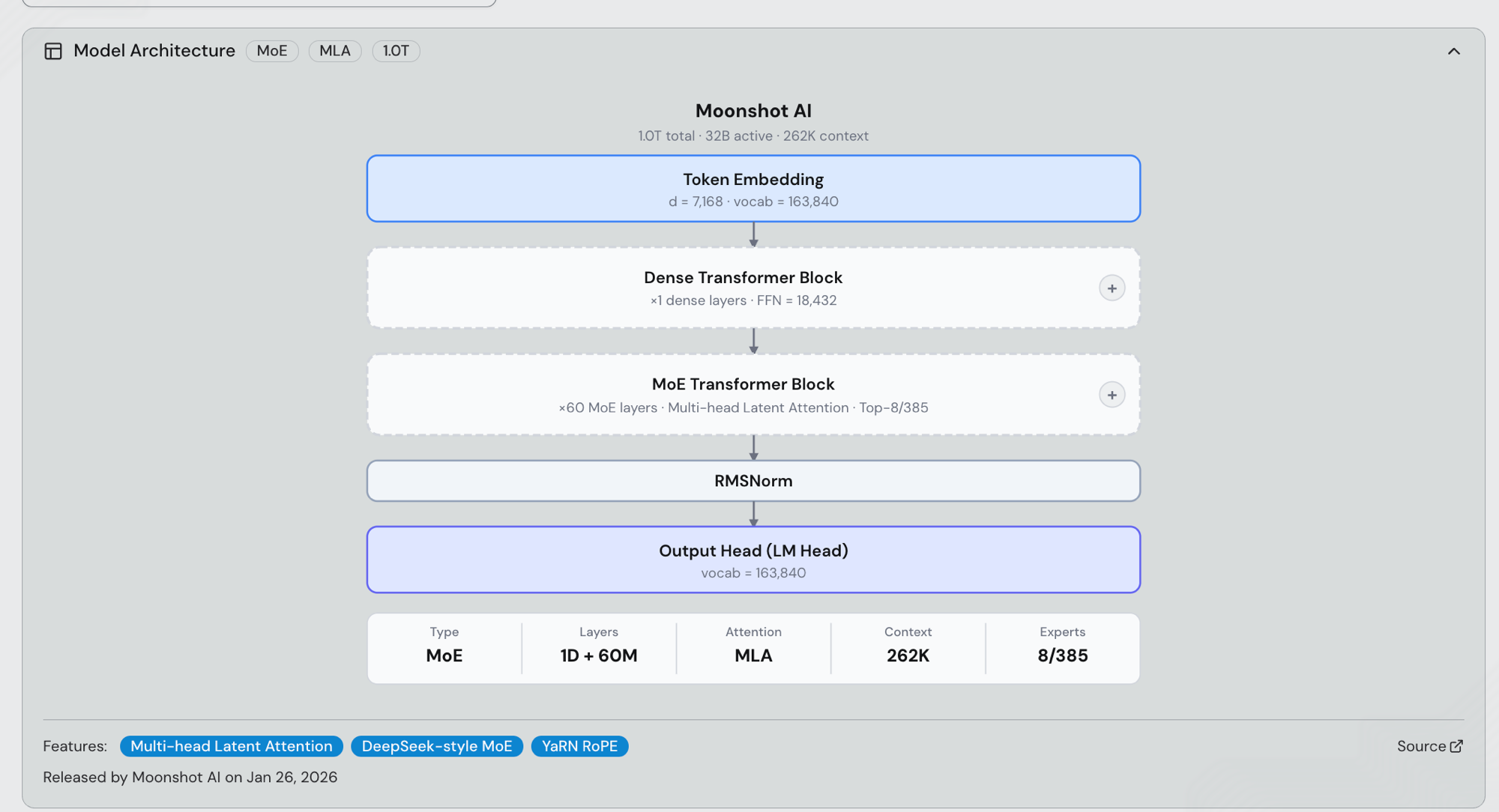
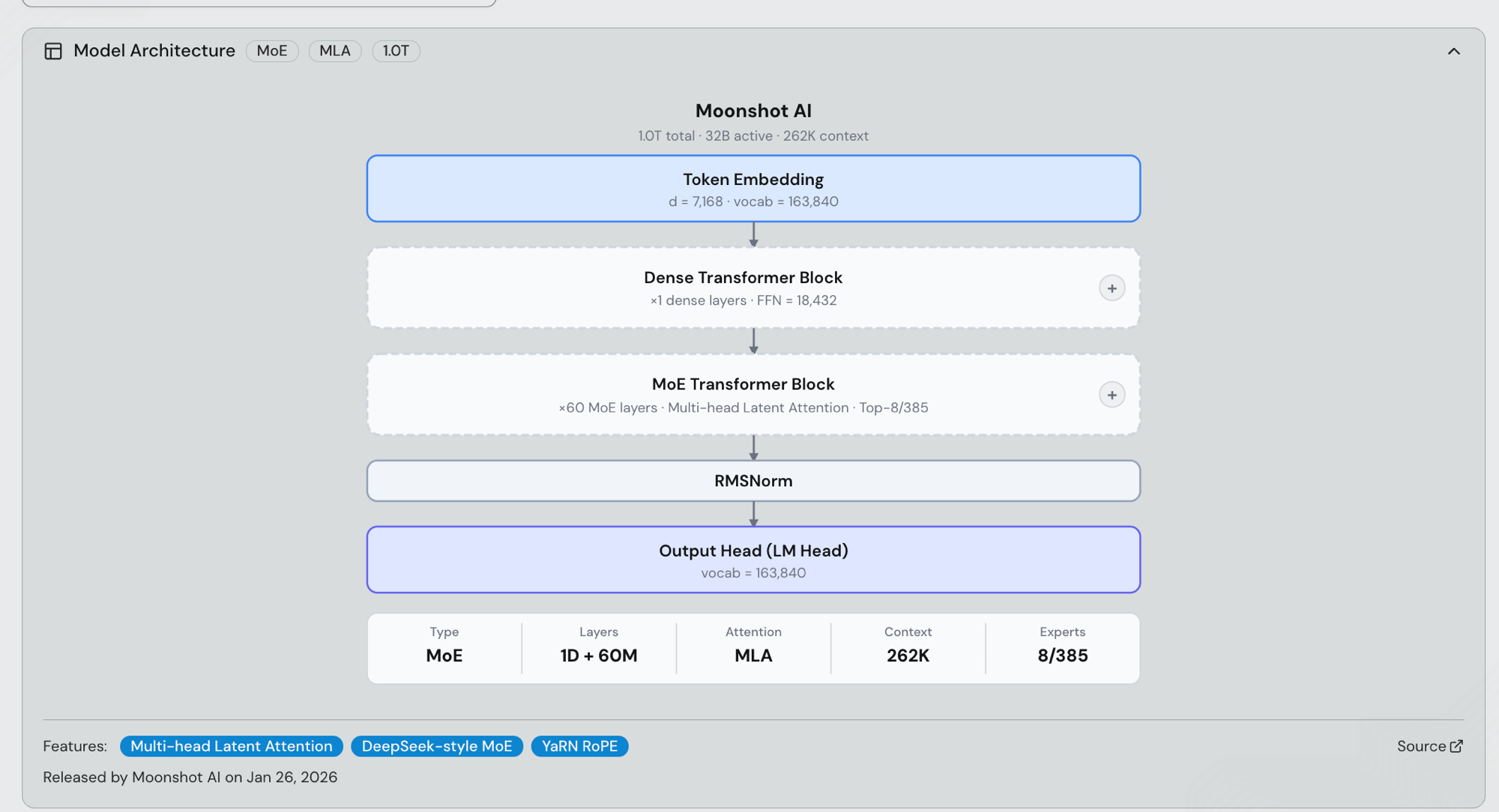
Kimi K2.5 / K2.6 模型架构及下游 Cursor Composer 2.5 模型
Kimi K2.5(发布于 2026-01-27)和 Kimi K2.6(发布于 2026-04-20)共享原始 Kimi K2 骨干网络:1.0T 参数的 MoE,每个 token 激活 32B 参数,DeepSeek 风格的 top-8-of-385 专家路由,跨 61 个 Transformer 层(1 个 dense 块 + 60 个 MoE 块),Multi-head Latent Attention(MLA)、SwiGLU、YaRN RoPE,163,840 词汇量,以及 256K 上下文窗口(262,144 tokens)。HF 检查点为 moonshotai/Kimi-K2.5 和 moonshotai/Kimi-K2.6——两者是在同一预训练架构上的后训练优化,因此本文中的每一个推理结果都同样适用于这两个版本。
K2.5 和 K2.6 是 xAI Cursor Composer 2 和 Composer 2.5 背后的开源权重模型,服务于 Cursor IDE 超过百万的日活用户。K2.6 还在公开 agentic 编程基准测试中领先前沿模型:SWE-Bench Pro 得分 58.6%——领先 GPT-5.4(57.7%)、Claude Opus 4.6(53.4%)和 Gemini 3.1 Pro(54.2%)——SWE-Bench Verified 得分 80.2%(Moonshot K2.6 模型卡)。Cline 的生产部署数据显示其在复杂 diff 编辑任务上的失败率为 3.3%,与 Claude 4 Sonnet 持平。K2.6 的 Agent Swarm 原语可扇出至 300 个并行子 agent,跨 4,000 个协调步骤,从 K2.5 的 100 / 1,500 提升。如果你今天在托管开源 agentic 编程栈,K2.5 或 K2.6 就是你在服务的模型。
关于量化的说明:Moonshot 发布 K2.5/K2.6 时,原生 INT4 权重是默认的开源权重检查点——本文中 H200 INT4 和 B200 INT4 曲线直接使用该检查点。B200 NVFP4 曲线使用的是相同权重的 NVFP4 再量化版本,以便 B200 的 FP4 张量核心能以全速率执行 MoE GEMM。H200 无法运行此路径——Hopper SM90 没有 FP4 张量核心。
纸面规格
NVIDIA B200 SXM(Blackwell,2025)vs NVIDIA H200 SXM(Hopper,2024)——两者均为 NVIDIA,均运行 vLLM,均部署在 8-GPU NVLink 域中。下方雷达图(chart)将每个轴归一化到 /gpu-specs 中的跨厂商最大值,因此可见多边形在 GB200 NVL72 / GB300 NVL72 设定上限的轴上被压缩(Scale Up Domain Memory + 带宽在 72-GPU 节点规模下),FP4 轴由 GB300 NVL72 的 15,000 TFLOP/s 主导——B200 的 9,000 TFLOP/s 在该轴上约为 60%。
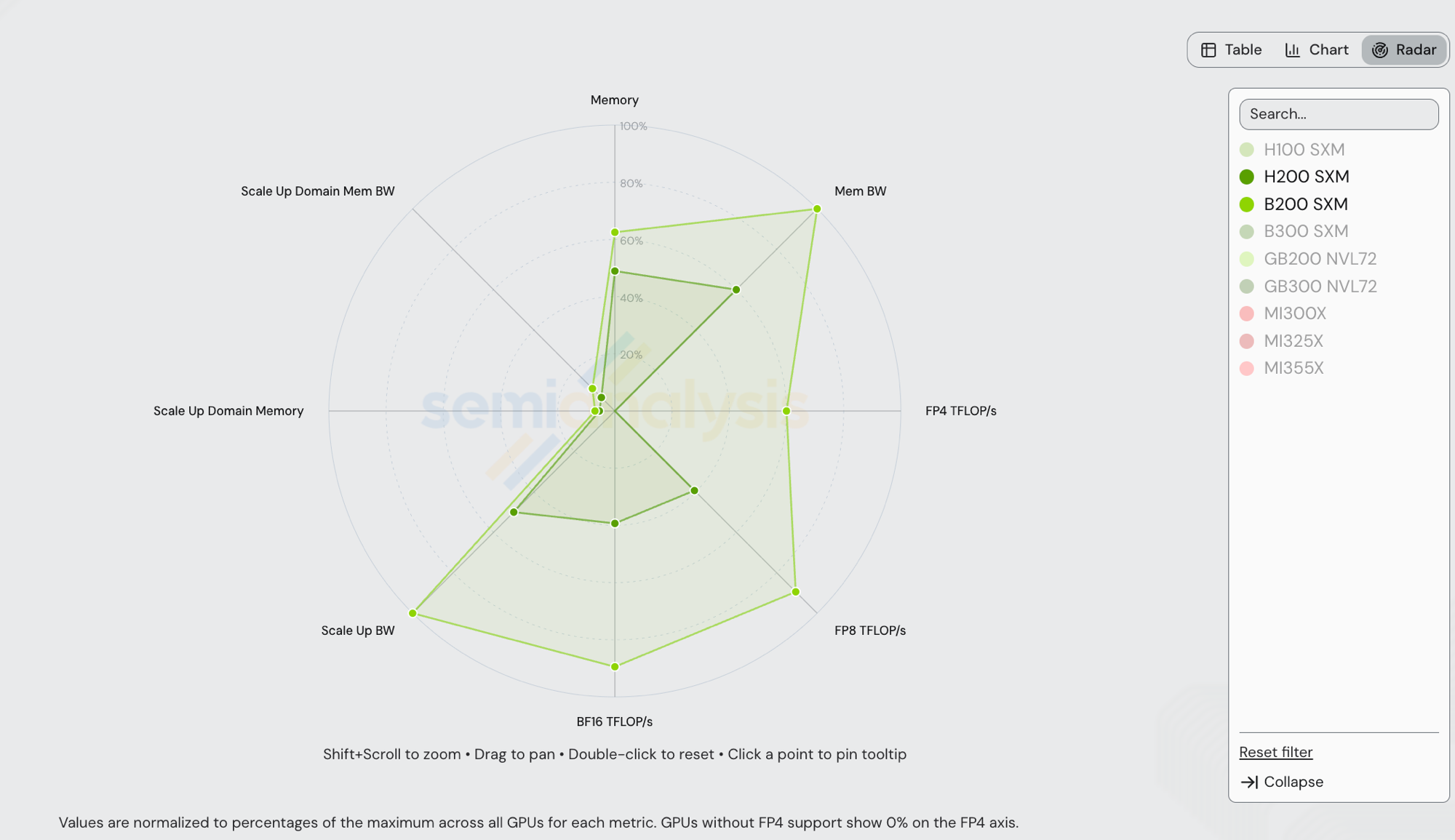
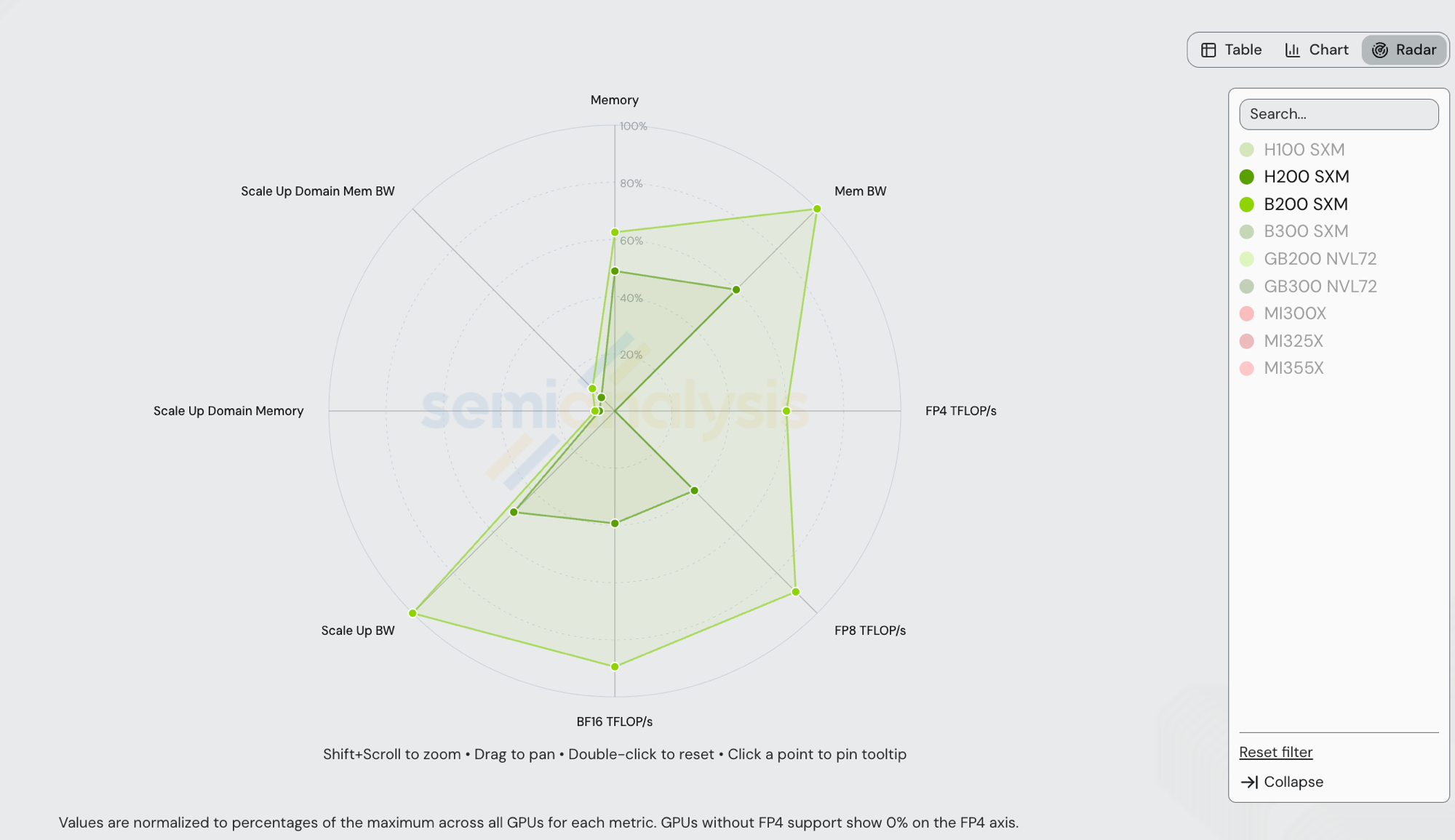
| 规格 | H200 SXM | B200 SXM | B200 / H200 |
|---|---|---|---|
| HBM 容量 | 141 GB | 180 GB | 1.28x |
| HBM 带宽 | 4.8 TB/s | 8 TB/s | 1.67x |
| Dense FP4 (TFLOP/s) | —(无 FP4 核心) | 9,000 | ∞ |
| Dense FP8 (TFLOP/s) | 1,979 | 4,500 | 2.27x |
| Dense BF16 (TFLOP/s) | 989 | 2,250 | 2.27x |
| Scale-up 每 GPU 带宽(单向) | 450 GB/s (NVLink 4) | 900 GB/s (NVLink 5) | 2.00x |
| Scale-up 节点规模 | 8 | 8 | 1.00x |
| Scale-up Domain HBM 容量 | 1.13 TB | 1.44 TB | 1.28x |
| Scale-up Domain HBM 带宽(聚合) | 38.4 TB/s | 64 TB/s | 1.67x |
| TCO(SemiAnalysis AI Cloud 模型) | $1.41/GPU/hr | $1.95/GPU/hr | 1.38x |
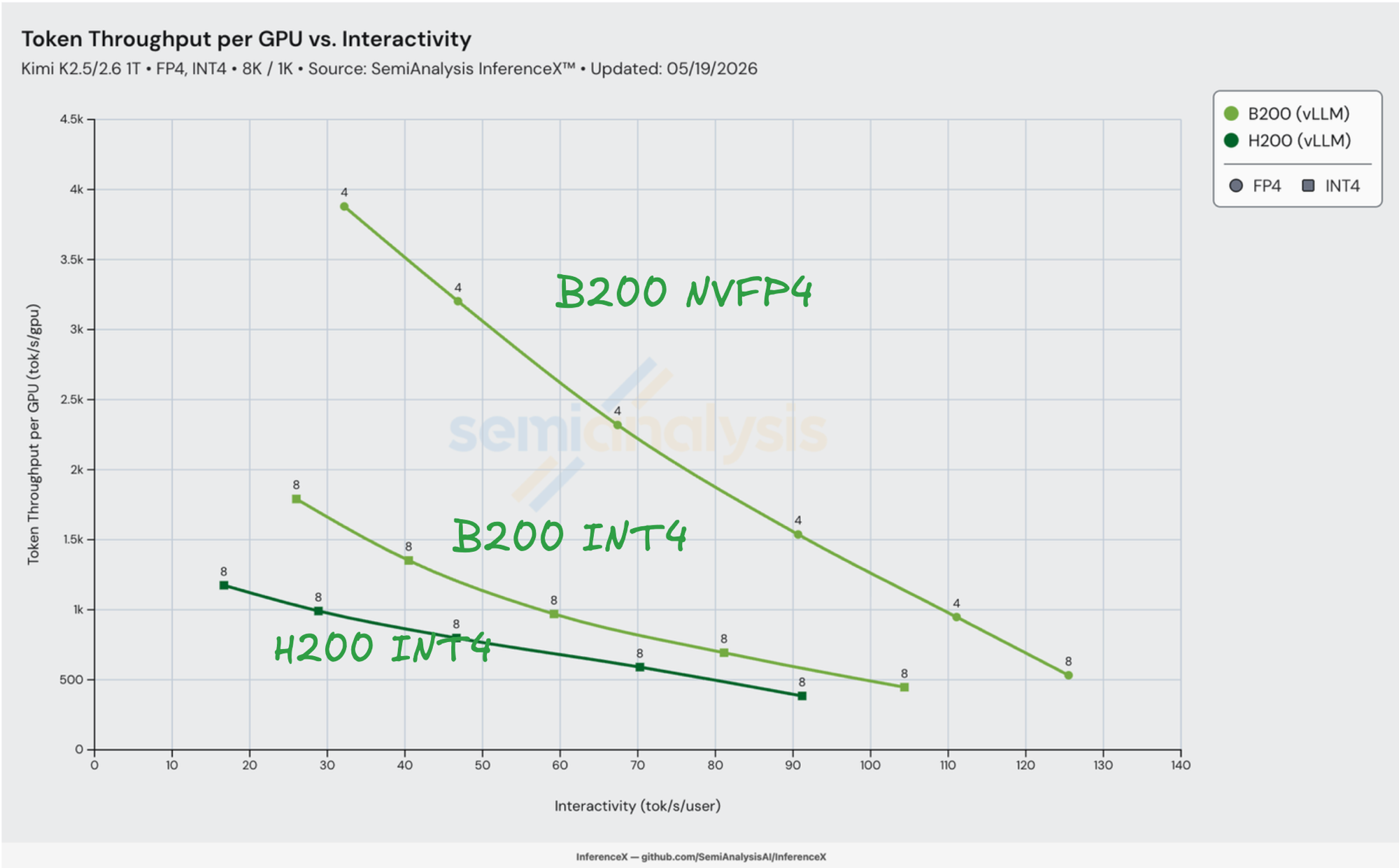
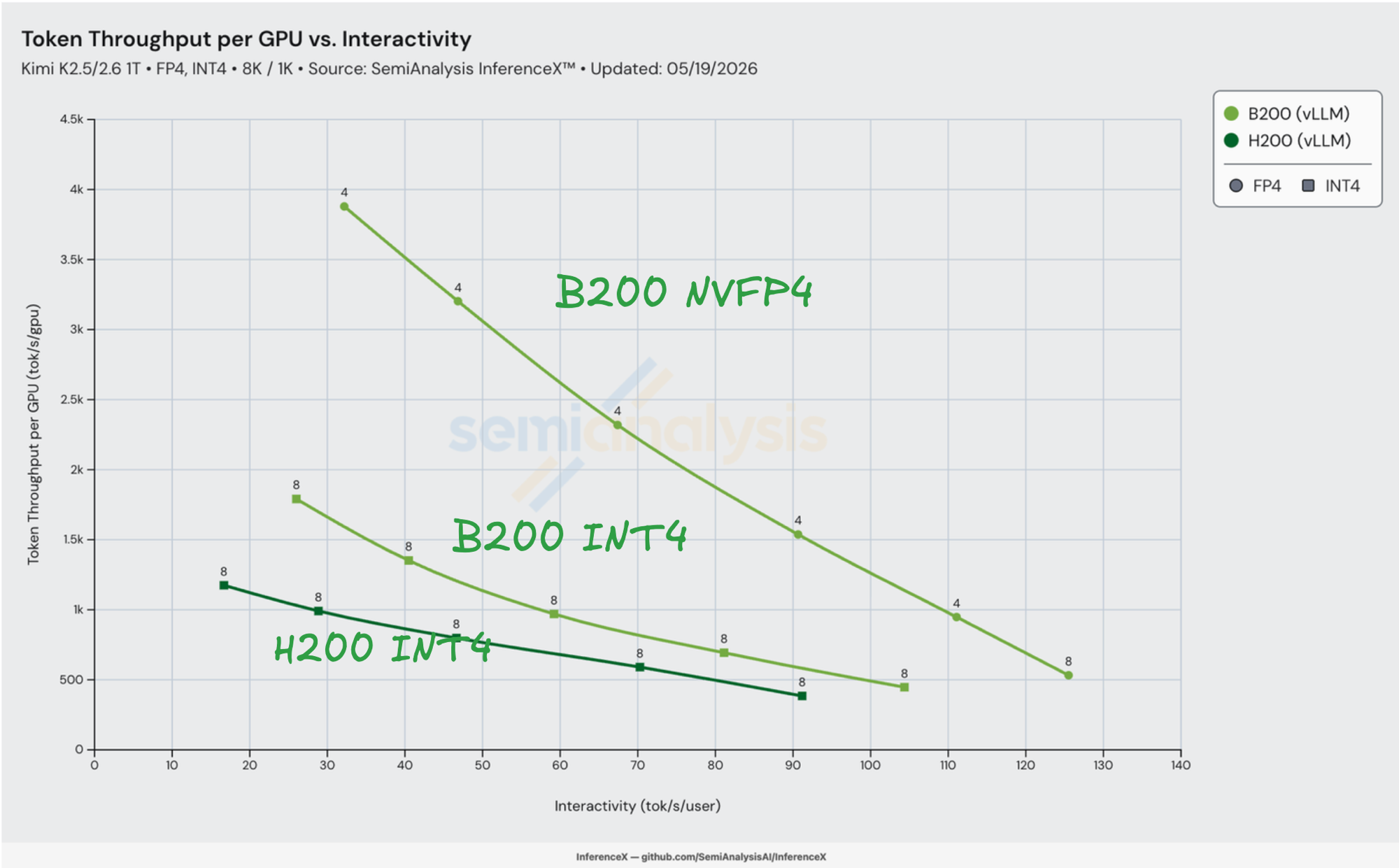
从硅片规格到实测性能的映射。 当两款 SKU 在同一模型上都运行 vLLM INT4 时,工作负载在 decode 路径上受 HBM 带宽瓶颈限制——每一步通过 HBM 流式读取活跃专家权重,在并发用户间分批执行。B200 1.67 倍的 HBM 带宽优势直接体现在吞吐量上:在 iv = 26 tok/s/user 时,B200 INT4 达到 1,791 tok/s/GPU vs H200 INT4 的插值 1,055——比值为 1.70x,正好位于硅片极限。扣除 1.38 倍 TCO 溢价后,B200 INT4 相对 H200 INT4 获得 1.22 倍的 token 成本优势。
HBM 容量带来了雷达图上看不到的第二个硅片优势:更低的 TP,每个 token 更少的集合通信开销。 Kimi K2.5/K2.6 INT4 的模型活跃状态约占 500 GB(1T 总参数 × 约 4 bit + 激活值 + KV 缓存 + paged attention 暂存空间)。在 B200 的 180 GB/GPU 上,可以放入 4 GPU(720 GB 聚合,约 30% 空间留给 KV 缓存和激活值)→ TP=4 可行。在 H200 的 141 GB/GPU 上,同样的模型需要 至少 8 GPU(1,128 GB 聚合)才能留出足够的 KV 缓存空间 → 必须使用 TP=8。本文中每一个 Pareto 最优的 B200 NVFP4 数据点都是 TP=4;每一个 H200 INT4 数据点都是 TP=8。
张量并行度减半意味着每个 decode 步骤的集合通信流量减半——注意力输出投影、MoE gather 和 post-MLP reduce 上各少一个 log₂N AllReduce 跳。Amdahl 定律在串行集合通信瓶颈上拉低了每步延迟下限。B200 NVFP4 曲线不仅因精度比值而位于 B200 INT4 之上;它还因每个 decode 步骤完成更快而在交互性轴上向左偏移。
精度解锁叠加在以上两个因素之上。 将 B200 的路径从 INT4 切换为 NVFP4,使其 dense 张量核心吞吐量翻倍——这条路径承担了 K2 中 MoE GEMM 的大部分计算——且无需额外的 HBM 开销。B200 NVFP4 在 32 tok/s/user 时达到 3,879 tok/s/GPU,是 B200 INT4 峰值(26 tok/s/user)的 2.17 倍。将三个因素相乘——1.67x HBM 带宽(decode 瓶颈下的吞吐量下限)× 约 2x NVFP4(精度解锁)× TP=4 vs TP=8 的集合通信优势——再除以 1.38x TCO 溢价。最终得到实测的 2.95 倍每百万 tokens 成本优势。
详细数据
所有行均为 Kimi K2.5 / K2.6 在 ISL 8192 / OSL 1024 下的单 8-GPU 节点结果,数据来自 2026-05-19 的 InferenceX 基准测试,GHA run 26118912054。吞吐量为每 GPU 数值。每百万 tokens 成本使用 SemiAnalysis AI Cloud TCO 模型:H200 $1.41/GPU/hr,B200 $1.95/GPU/hr。公式:$/M tok = TCO\_$/GPU/hr × 1e6 / (3600 × tput_per_gpu)。
H200 vLLM INT4 (TP=8)——参考基准:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 384.4 | 91.18 | 10.97 | $1.019 |
| 8 | 590.2 | 70.28 | 14.23 | $0.664 |
| 16 | 797.9 | 46.64 | 21.44 | $0.491 |
| 32 | 990.9 | 28.86 | 34.65 | $0.395 |
| 64 | 1,174.5 | 16.67 | 59.98 | $0.334 |
B200 vLLM INT4 (TP=8)——相同精度下的 Blackwell 硬件,隔离纯硬件差异:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 446.7 | 104.36 | 9.58 | $1.213 |
| 8 | 692.8 | 81.12 | 12.33 | $0.782 |
| 16 | 969.4 | 59.21 | 16.89 | $0.559 |
| 32 | 1,351.4 | 40.48 | 24.70 | $0.401 |
| 64 | 1,790.7 | 26.01 | 38.45 | $0.303 |
B200 vLLM NVFP4 (TP=4 + TP=8)——标题中的最优方案;dense Pareto 最优段在所有并发度下均为 TP=4,外加一个 TP=8 conc=4 数据点延伸高交互性端:
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens | TP |
|---|---|---|---|---|---|
| 4 | 532.0 | 125.51 | 7.97 | $1.018 | TP=8 |
| 4 | 947.4 | 111.08 | 9.00 | $0.572 | TP=4 |
| 8 | 1,537.2 | 90.66 | 11.03 | $0.352 | TP=4 |
| 16 | 2,318.7 | 67.40 | 14.84 | $0.234 | TP=4 |
| 32 | 3,202.7 | 46.83 | 21.35 | $0.169 | TP=4 |
| 64 | 3,879.3 | 32.19 | 31.07 | $0.140 | TP=4 |
加粗行即为标题数字:B200 NVFP4 在 32 tok/s/user 时每百万 tokens 仅需 $0.140,为图表中的最低推理成本。
等交互性成本对比
在匹配的交互性水平下,沿每款 SKU 的 Pareto 前沿插值得出的每百万 tokens 成本。超出前沿测量范围的单元格标记为 _unreachable_(比值列标记为 _∞_)。三条曲线的重叠区间为 30–90 tok/s/user——这是有意义的三方对比所在的区间。
| 交互性 (tok/s/user) | H200 INT4 $/M | B200 INT4 $/M | B200 NVFP4 $/M | H200 / B200 NVFP4 | H200 / B200 INT4 | B200 INT4 / B200 NVFP4 |
|---|---|---|---|---|---|---|
| 32 | $0.413 | $0.343 | $0.140 | 2.95x | 1.20x | 2.45x |
| 35 | $0.427 | $0.362 | $0.145 | 2.95x | 1.18x | 2.50x |
| 40 | $0.453 | $0.397 | $0.154 | 2.94x | 1.14x | 2.58x |
| 50 | $0.511 | $0.477 | $0.177 | 2.88x | 1.07x | 2.69x |
| 60 | $0.569 | $0.566 | $0.206 | 2.75x | 1.00x | 2.74x |
| 70 | $0.660 | $0.655 | $0.244 | 2.71x | 1.01x | 2.69x |
| 80 | $0.811 | $0.766 | $0.286 | 2.84x | 1.06x | 2.68x |
| 90 | $0.996 | $0.927 | $0.347 | 2.87x | 1.07x | 2.67x |
| 100 | unreachable | $1.123 | $0.421 | ∞ | unreachable | 2.67x |
| 110 | unreachable | unreachable | $0.550 | ∞ | ∞ | ∞ |
| 125 | unreachable | unreachable | $1.000 | ∞ | ∞ | ∞ |
B200 NVFP4 vs H200 INT4 的差距在重叠区间内几乎恒定:30 到 90 tok/s/user 范围内为 2.71x–2.95x。 曲线的两端获得相同的优势。在低交互性/高批量端,工作负载受 decode 瓶颈限制,B200 的 HBM 带宽 + NVFP4 张量核心均保持饱和。在高交互性/低批量端,NVFP4 随批量缩小持续降低每 token 计算开销。同精度行(H200 INT4 vs B200 INT4)则呈现不同的趋势:在 60–80 tok/s/user 时收窄至 1.00x–1.07x,B200 的硅片优势仅仅能覆盖其 TCO 溢价。精度解锁才是支撑标题数字的核心。
在 100 tok/s/user 以上,只有 B200 NVFP4 还有可用方案。H200 INT4 的前沿在 91 tok/s/user 终止(并发 4 时单步计算饱和);B200 INT4 在 104 tok/s/user 终止。B200 NVFP4 仍可在 125 tok/s/user 时以 $1.00/M 提供服务——这是任何 Hopper 方案都无法到达的区间。
在线图表,已预筛选为 2026-05-19 测试中 B200 + H200 上的 vLLM Kimi K2.5/K2.6 FP4 和 INT4 对比。
致谢
Kimi K2.5 和 K2.6 是 Moonshot AI 的工作成果,权重发布于 moonshotai/Kimi-K2.5 和 moonshotai/Kimi-K2.6。Blackwell 上的 vLLM NVFP4 路径是 vLLM 项目以及 NVIDIA TensorRT-LLM / AITER 内核团队的工作成果,vLLM 链接了他们的 FP4 MoE 内核。持续基准测试由 SemiAnalysis 在 InferenceX 上执行。速度就是护城河。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。