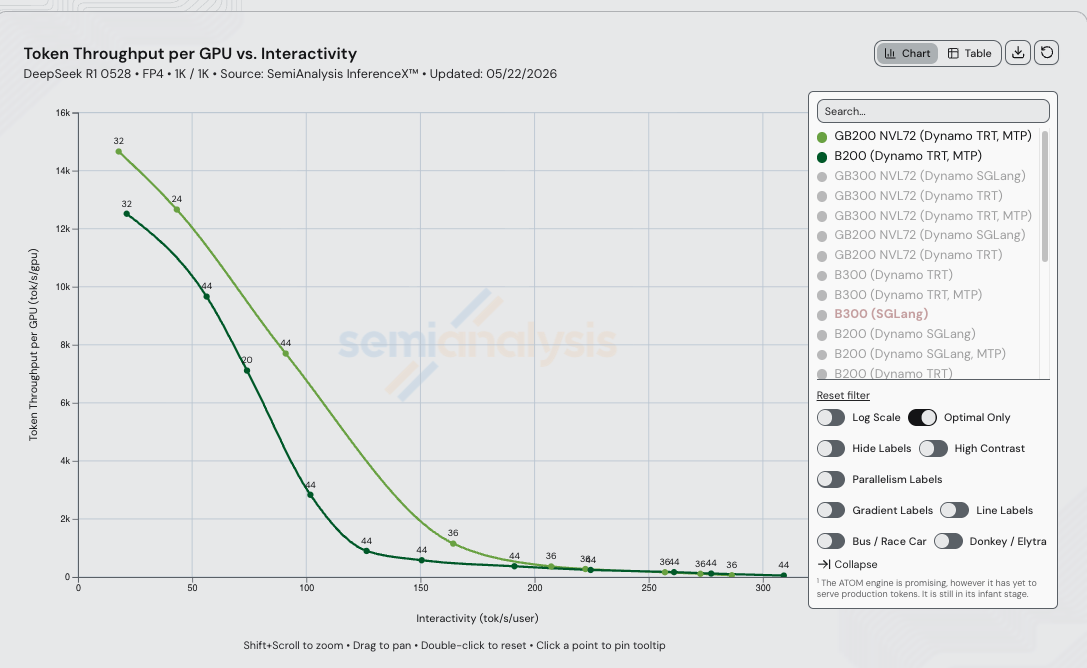
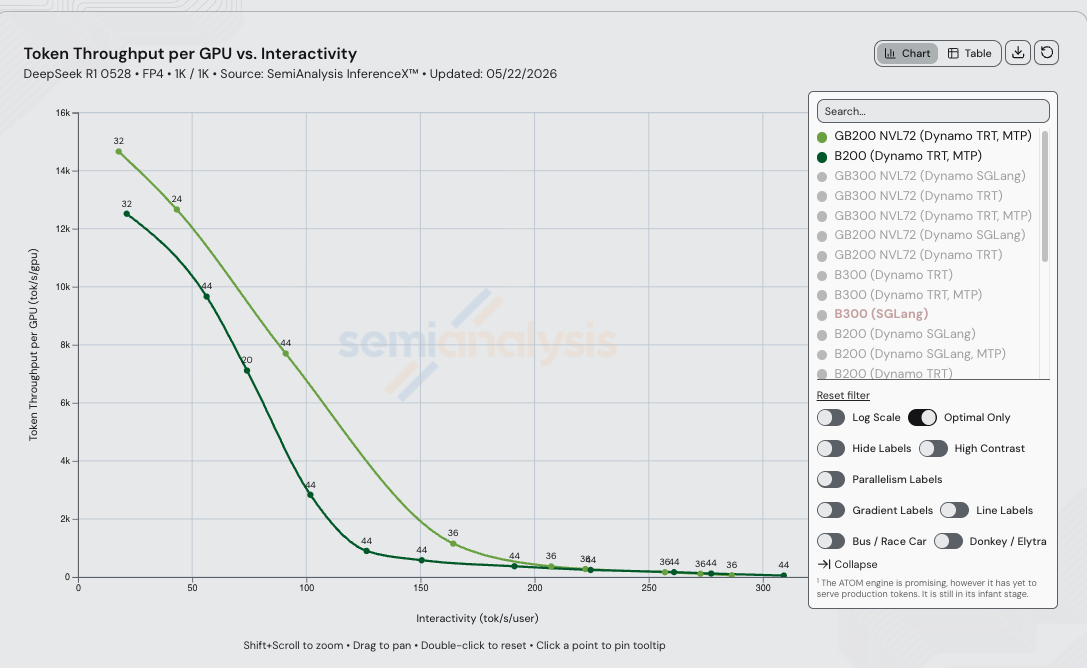
On DeepSeek R1 0528 FP4 1k/1k with Dynamo TRT-LLM + MTP and disaggregated prefill/decode on both SKUs, GB200 NVL72 delivers up to 4.39x throughput per GPU vs B200 at iso-interactivity — peaking at 125 tok/s/user (4,130 tok/s/GPU on GB200 NVL72 vs 941 tok/s/GPU on B200).
NVIDIA GB200 NVL72 connects all 72 GPUs over NVLink 5 at 900 GB/s per GPU uni-directional (1.8 TB/s jensen math bidi rx + tx). A B200 server connects only 8 GPUs over NVLink; once decode EP needs more than 8 ranks, the all-to-all has to leave the NVLink island and cross ConnectX-7 RoCEv2 Ethernet at 400 Gbit/s per GPU. So per-GPU bandwidth available to any wider-than-8 EP collective drops from 900 GB/s to 50 GB/s, 18x. DeepSeek R1's 256 routed experts amortize beautifully when the all-to-all stays on NVLink end-to-end across 16 or 32 ranks.


DeepSeek R1 0528 is the 671B-parameter MoE that DeepSeek released in May 2025 — Multi-head Latent Attention (MLA) for KV-cache compression, 256 routed experts with 8 active per token plus 1 shared expert, and 61 transformer layers. Every MoE layer fires a routed all-to-all dispatch followed by an all-to-all combine on each forward pass: roughly 120 all-to-alls per token. That collective volume is exactly what NVLink-class scale-up bandwidth is for.
Why GB200 NVL72 Wins in the Middle of the Curve
In the middle of the curve — roughly 75–175 tok/s/user on this workload — decode becomes network-bound on the EP dispatch and combine collectives. Each MoE layer fires two all-to-all collectives per token: a dispatch that routes each token to the 8 of 256 experts it was assigned to (which generally live on remote ranks under wide EP), and a combine that gathers the expert outputs back to each token's home rank. Across DeepSeek R1's ~60 MoE layers that is roughly 120 collectives per forward pass.
When the network is fast enough, the runtime overlaps each dispatch and combine with the matmul compute it is serving: issue the dispatch, start the expert GEMM on tokens that have already arrived, finish the GEMM in roughly the time it takes for the remaining bytes to land, then issue the combine. The collective latency mostly disappears from the critical path because the GPU was busy doing useful compute throughout.
On ConnectX-7 RoCEv2 Ethernet at 50 GB/s per GPU — 18x less per-rank bandwidth than NVLink — that overlap collapses. The same collective takes up to 18x longer per byte moved, no longer fits inside the GEMM time budget, and exposes itself as raw communication time.
The Numbers
All rows are DeepSeek R1 0528 FP4 at ISL 1024 / OSL 1024, Dynamo TRT-LLM with MTP enabled, disaggregated prefill/decode on both SKUs, multinode in both cases, measured on InferenceX on 2026-05-22 (run 26306422380). Cost per million total tokens is computed as TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6), with B200 at $1.95/GPU/hr and GB200 NVL72 at $2.21/GPU/hr per the SemiAnalysis AI Cloud TCO Model.
GB200 NVL72 (Dynamo TRT, MTP), DeepSeek R1 FP4 1k/1k disagg:
| Conc | Prefill | Decode | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tok |
|---|---|---|---|---|---|---|
| 4 | 4 GPU, TP=4 | 32 GPU, EP=8 | 60.7 | 286.40 | 3.49 | $10.12 |
| 8 | 4 GPU, TP=4 | 32 GPU, EP=8 | 111.8 | 272.64 | 3.67 | $5.49 |
| 12 | 4 GPU, TP=4 | 32 GPU, EP=8 | 165.2 | 257.11 | 3.89 | $3.72 |
| 24 | 4 GPU, TP=4 | 32 GPU, EP=8 | 274.8 | 222.28 | 4.50 | $2.23 |
| 48 | 4 GPU, TP=4 | 32 GPU, EP=8 | 363.3 | 207.30 | 4.82 | $1.69 |
| 180 | 4 GPU, TP=4 | 32 GPU, EP=32 | 1,149.1 | 164.37 | 6.08 | $0.53 |
| 2,253 | 12 GPU, TP=12 | 32 GPU, EP=32 | 7,698.0 | 90.99 | 10.99 | $0.08 |
| 4,301 | 8 GPU, TP=8 | 16 GPU, EP=16 | 12,659.7 | 43.29 | 23.10 | $0.05 |
| 16,130 | 12 GPU, TP=12 | 20 GPU, EP=4 | 14,659.4 | 17.82 | 56.11 | $0.04 |
B200 (Dynamo TRT, MTP), DeepSeek R1 FP4 1k/1k disagg multinode:
| Conc | Prefill | Decode | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tok |
|---|---|---|---|---|---|---|
| 6 | 4 GPU, TP=4 | 40 GPU, EP=8 | 49.3 | 309.17 | 3.23 | $10.99 |
| 10 | 4 GPU, TP=4 | 40 GPU, EP=8 | 118.7 | 277.39 | 3.61 | $4.56 |
| 15 | 4 GPU, TP=4 | 40 GPU, EP=8 | 168.9 | 261.09 | 3.83 | $3.21 |
| 25 | 4 GPU, TP=4 | 40 GPU, EP=8 | 242.4 | 224.59 | 4.45 | $2.23 |
| 45 | 4 GPU, TP=4 | 40 GPU, EP=8 | 369.9 | 191.18 | 5.23 | $1.46 |
| 90 | 4 GPU, TP=4 | 40 GPU, EP=8 | 577.3 | 150.56 | 6.64 | $0.94 |
| 180 | 4 GPU, TP=4 | 40 GPU, EP=8 | 897.9 | 126.42 | 7.91 | $0.60 |
| 875 | 4 GPU, TP=4 | 40 GPU, EP=8 | 2,832.9 | 101.79 | 9.82 | $0.19 |
| 1,214 | 4 GPU, TP=4 | 16 GPU, EP=8 | 7,111.4 | 74.04 | 13.51 | $0.08 |
| 4,968 | 12 GPU, TP=12 | 32 GPU, EP=8 | 9,660.7 | 56.35 | 17.75 | $0.06 |
| 10,860 | 12 GPU, TP=12 | 20 GPU, EP=4 | 12,515.7 | 21.34 | 46.86 | $0.04 |
Iso-Interactivity Throughput Comparison
| Interactivity (tok/s/user) | GB200 NVL72 tok/s/GPU | B200 tok/s/GPU | GB200 NVL72 / B200 |
|---|---|---|---|
| 25 | 14,125 | 12,292 | 1.15x |
| 45 | 12,508 | 10,853 | 1.15x |
| 60 | 11,017 | 9,185 | 1.20x |
| 75 | 9,379 | 6,968 | 1.35x |
| 90 | 7,796 | 4,512 | 1.73x |
| 100 | 6,781 | 3,047 | 2.23x |
| 125 | 4,130 | 941 | 4.39x |
| 150 | 1,922 | 583 | 3.30x |
| 175 | 826 | 429 | 1.93x |
| 200 | 432 | 332 | 1.30x |
| 225 | 262 | 241 | 1.09x |
| 250 | 186 | 193 | 0.97x |
| 275 | 103 | 126 | 0.82x |
| 300 | unreachable | 67 | ∞ (B200 wins) |
And the same comparison normalized to cost per million tokens, which dilutes the GB200 NVL72 advantage by its 13% per-GPU TCO premium ($2.21 vs $1.95 per GPU-hour):
| Interactivity (tok/s/user) | GB200 NVL72 $/M tok | B200 $/M tok | B200 / GB200 NVL72 |
|---|---|---|---|
| 25 | $0.0435 | $0.0441 | 1.01x |
| 45 | $0.0491 | $0.0499 | 1.02x |
| 60 | $0.0557 | $0.0590 | 1.06x |
| 75 | $0.0655 | $0.0777 | 1.19x |
| 100 | $0.0905 | $0.1778 | 1.96x |
| 125 | $0.1486 | $0.5755 | 3.87x |
| 150 | $0.3194 | $0.9292 | 2.91x |
| 175 | $0.7430 | $1.2638 | 1.70x |
| 200 | $1.4215 | $1.6314 | 1.15x |
| 225 | $2.3450 | $2.2454 | 0.96x |
| 250 | $3.2962 | $2.8067 | 0.85x (B200 wins) |
The 4.39x throughput peak (3.87x cost gap) at 125 tok/s/user is where wide EP across the NVLink fabric is doing the most work.
Live chart, pre-filtered to B200 and GB200 NVL72 Dynamo TRT MTP on DeepSeek R1 FP4 1k/1k for the 2026-05-22 run.
When Each SKU Wins
- GB200 NVL72 Dynamo TRT is the right choice for everything in the 75 to 200 tok/s/user band where wide EP across the 72-GPU NVLink fabric is the dominant factor. The cost gap peaks at 3.87x in favor of GB200 NVL72 at 125 tok/s/user — chat-style and reasoning serving at production interactivity targets land squarely inside this band.
NVIDIA's SGLang GB200 NVL72 results show the same scale-up fabric advantage on the SGLang stack. AMD's MI300/MI355X have no rack-scale UALoE72 equivalent shipping until H2 2026 engineering samples per the inferencex-v2 launch piece, so there is no rack scale comparator on the AMD side yet for this workload.
Acknowledgments
Thanks to NVIDIA's Dynamo and TensorRT-LLM teams — including Jatin Gangani, Kedar Potdar, Sridhar Ramaswamy, Ishan Dhanani, and Sahithi Chigurupati — for shipping the disagg recipes on both B200 multinode RoCEv2 and GB200 NVL72. Checkout our other blog post on GB200 NVL72 vs B200 Kimi K2.5 post.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.