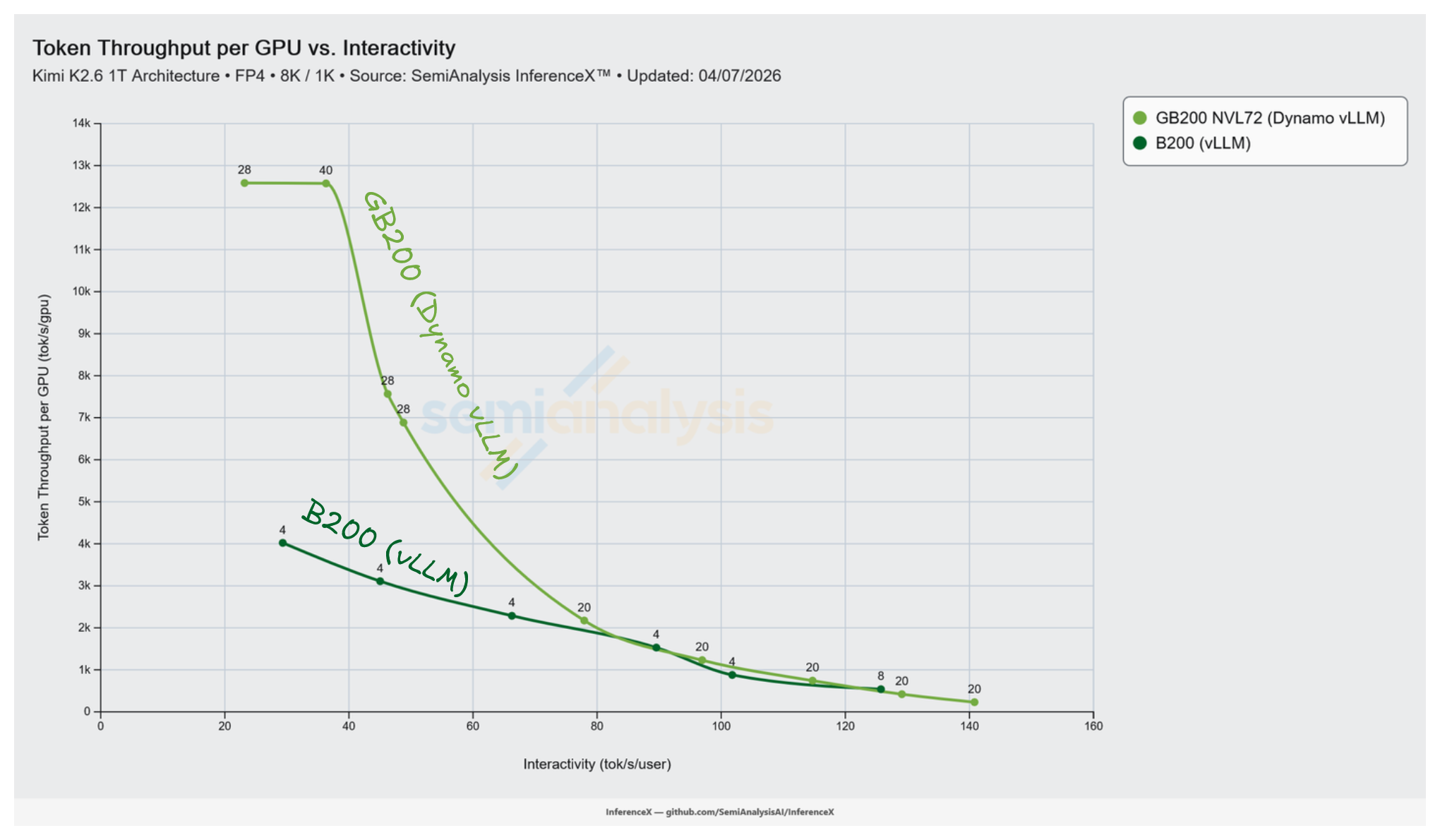
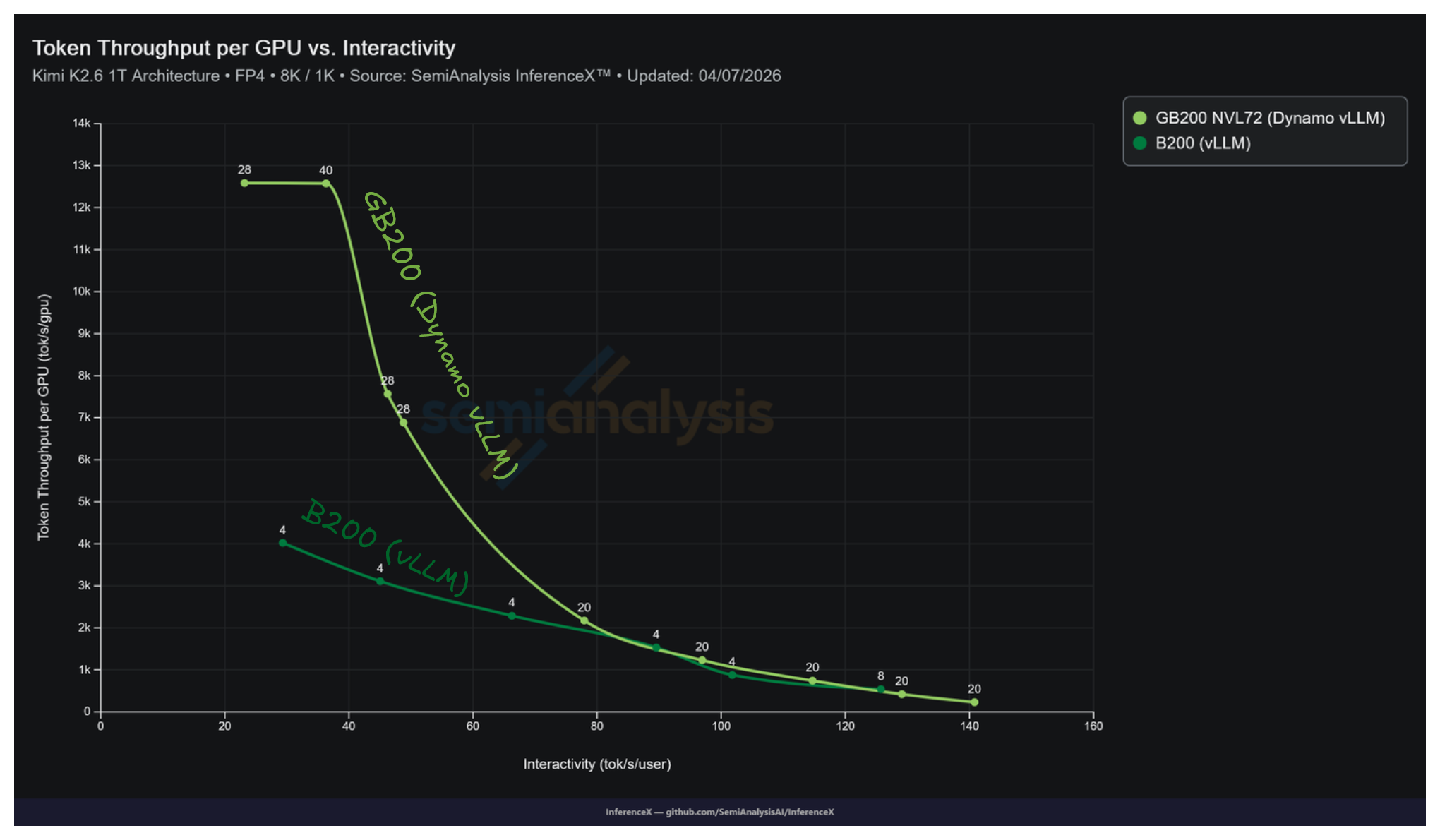
NVIDIA's GB200 NVL72 running Dynamo vLLM peaks at 12,587 tok/s/GPU on Kimi K2.5 NVFP4 8k/1k, while the best B200 single node vLLM recipe peaks at 4,021 tok/s/GPU on the same workload. That is a 3.13x advantage in peak throughput per GPU. NVL72's rack scale NVLink fabric lets decode run with wide expert parallelism up to Decode EP 16 on the tested recipes, with the peak at Decode EP 8 on an 8 GPU decode pool. B200 tops out at Decode EP 4 on the best measured recipe. Past that, the expert all to all starts hitting scale out fabric latencies.
Kimi K2.5 is a 1T parameter MoE with 384 routed experts plus 1 shared expert, 8 experts active per token, and 60 MoE layers. Every MoE layer does a routed all to all dispatch followed by an all to all combine, so a single forward pass runs roughly 120 all to alls across 60 layers. On NVL72 that traffic stays on NVLink 5 at 1.8 TB/s per GPU inside a 130 TB/s aggregate fabric. On B200, wide EP past 8 GPUs leaves the NVLink island. It falls back to ConnectX 7 InfiniBand at 400 Gb/s per GPU, roughly 36x below NVL72's NVLink bandwidth. Sparsity 48 MoEs like K2.5 do not tolerate that gap at scale.
Why Wide EP Matters for Kimi K2.5
At EP 4, each GPU holds 96 of Kimi K2.5's 384 experts. Decode is bound by the HBM bandwidth required to reload those expert weights every step. Widening EP to 16 drops the per GPU expert footprint to 24. Each expert weight read is now amortized across a larger effective batch of peer GPUs dispatching tokens through that rank. This shifts decode from weight bandwidth bound toward compute and communication bound. That is a regime where Blackwell's FP4 tensor cores and NVLink bandwidth both work in your favor.
The cost of widening EP is an all to all collective at every MoE layer. If that collective hits scale out fabric the interactivity budget collapses before the throughput gains pay back. NVL72's scale up domain is what makes wide EP practical at EP 8 through EP 16 for K2.5 decode pools. B200's 8 GPU NVLink island makes Decode EP 4 across two nodes the ceiling before scale out takes over.
Peak Throughput and the Concurrency Curve
All numbers are Kimi K2.5 NVFP4 at ISL 8192 / OSL 1024 on InferenceX. B200 data is from the 2026-03-27 run, triggered by InferenceX PR #926 which disabled prefix caching for Kimi K2.5 vLLM benchmarks on random datasets. GB200 NVL72 data is from the 2026-04-07 run, triggered by InferenceX PR #1008 which added the GB200 Dynamo vLLM disaggregated multinode recipe (vLLM 0.18.0, nvidia/Kimi-K2.5-NVFP4, NixlConnector KV transfer, FLASHINFER_MLA attention). The two runs are 11 days apart. Both are the latest available for the peak-throughput recipe on each hardware.
B200 vLLM, 2026-03-27 run, non disaggregated, 16 GPU pool:
| Prefill | Decode | Conc | tok/s/GPU | TPOT (ms) | tok/s/user |
|---|---|---|---|---|---|
| TP 4, EP 4 | TP 4, EP 4 | 4 | 878 | 9.8 | 101.8 |
| TP 4, EP 4 | TP 4, EP 4 | 8 | 1,529 | 11.2 | 89.5 |
| TP 4, EP 4 | TP 4, EP 4 | 16 | 2,286 | 15.1 | 66.3 |
| TP 4, EP 4 | TP 4, EP 4 | 32 | 3,108 | 22.2 | 45.0 |
| TP 4, EP 4 | TP 4, EP 4 | 64 | 4,021 | 34.1 | 29.3 |
GB200 NVL72 Dynamo vLLM, 2026-04-07 run, disaggregated:
| Prefill | Decode | Conc | tok/s/GPU | TPOT (ms) | tok/s/user |
|---|---|---|---|---|---|
| TP 4, EP 4 | TP 4, EP 4 | 4 | 231 | 7.1 | 140.8 |
| TP 4, EP 4 | TP 4, EP 4 | 8 | 421 | 7.7 | 129.1 |
| TP 4, EP 4 | TP 4, EP 4 | 16 | 744 | 8.7 | 114.7 |
| TP 4, EP 4 | TP 4, EP 4 | 32 | 1,230 | 10.3 | 96.9 |
| TP 4, EP 4 | TP 4, EP 4 | 128 | 2,173 | 12.8 | 77.9 |
| TP 4, EP 4 | TP 16, EP 16 | 512 | 6,885 | 20.5 | 48.8 |
| TP 4, EP 4 | TP 16, EP 16 | 1,024 | 7,565 | 21.6 | 46.2 |
| TP 4, EP 4 | TP 8, EP 8 | 2,048 | 12,587 | 43.1 | 23.2 |
| TP 4, EP 4 | TP 16, EP 16 | 4,096 | 12,576 | 27.5 | 36.3 |
B200 saturates per GPU throughput at 4,021 tok/s by concurrency 64, where the 16 GPU pool is fully loaded. NVL72 keeps absorbing concurrency out to 2,048 and beyond. The decode pool is 8 to 16 GPUs of wide EP sitting on a scale up fabric. Adding users keeps the MoE all to all bandwidth bound instead of latency bound.
Iso Interactivity Comparison
At B200's peak throughput operating point (concurrency 64, 29.3 tok/s/user, 4,021 tok/s/GPU), the closest GB200 NVL72 points are:
| Interactivity (tok/s/user) | GB200 NVL72 tok/s/GPU | Config |
|---|---|---|
| 36.3 | 12,576 | Decode TP 16, EP 16 at conc 4,096 |
| 23.2 | 12,587 | Decode TP 8, EP 8 at conc 2,048 |
GB200 NVL72 sits on a roughly flat ~12,580 tok/s/GPU plateau across the 23 to 36 tok/s/user band, giving a 3.13x throughput ratio at iso interactivity near B200's peak.
Live chart, pre-filtered to Kimi K2.5 on April 7th.
vLLM Wide EP on NVL72
vLLM shipped its PPLX all to all backend in v0.9 and added DeepEP shortly after. v0.11 completed the V1 engine migration and extended the dual batch overlap (DBO) path via PR #24845, which adds DeepEP high throughput kernels and prefill support to DBO so all to all communication can be hidden behind compute. The benchmarks above run v0.18.0 without speculative decoding.
The GB200 NVL72 setup runs vLLM as worker runtime inside NVIDIA Dynamo, tagged dynamo-vllm in the InferenceX dataset. Dynamo splits prefill (4 GPUs at TP 4, EP 4) from decode (8 to 16 GPUs with TP and EP both scaled up to 16) and routes requests between them across the NVL72 fabric. SGLang and TRT-LLM have analogous disagg + wide EP paths on NVL72, with SGLang's public GB200 results currently the most mature.
When Each SKU Wins
B200 delivers around 4k tok/s/GPU at 30 tok/s/user on a 16 GPU pool. The TP 4, EP 4 recipe saturates around concurrency 64. Past that, the latency floor collapses.
GB200 NVL72 delivers 12.5k tok/s/GPU at 23 to 36 tok/s/user across concurrency 2,048 to 4,096. The tested single node B200 recipes have no comparable operating point.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.