On MiniMax-M2.5 8K/1K with vLLM, NVIDIA's NVFP4 checkpoint of MiniMax-M2.5 on B200 delivers up to 8.2x better performance per dollar than H100 vLLM FP8 at iso-interactivity — H100 at $0.74/M tokens vs B200 NVFP4 at $0.09/M tokens at 110 tok/s/user. The lift grows monotonically across H100's 21–111 tok/s/user operating range, from 4.0x at the low end (22 tok/s/user, $0.12 vs $0.031) to 8.2x at the high end. Measured on InferenceX on 2026-05-22.
The 8.2x factors cleanly at the peak. At 110 tok/s/user, B200 vLLM FP8 delivers 2.94x better performance per dollar than H100 vLLM FP8 — the Blackwell generation step alone, riding on the same MiniMaxAI/MiniMax-M2.5 checkpoint and the same vLLM build on both SKUs. Swapping the B200 weights to nvidia/MiniMax-M2.5-NVFP4 stacks another 2.77x — the precision step alone, unlocked by vllm-project/vllm #36307 which added a modular variant of the trtllm-gen FP8 MoE kernel so MiniMax's non-standard routing method can finally use it. 2.94 × 2.77 ≈ 8.14. The precision step widens with interactivity (1.65x at 22 → 2.77x at 110) because the trtllm-gen kernel's headroom over the older triton path opens up as the GEMM ceiling becomes the binding constraint.
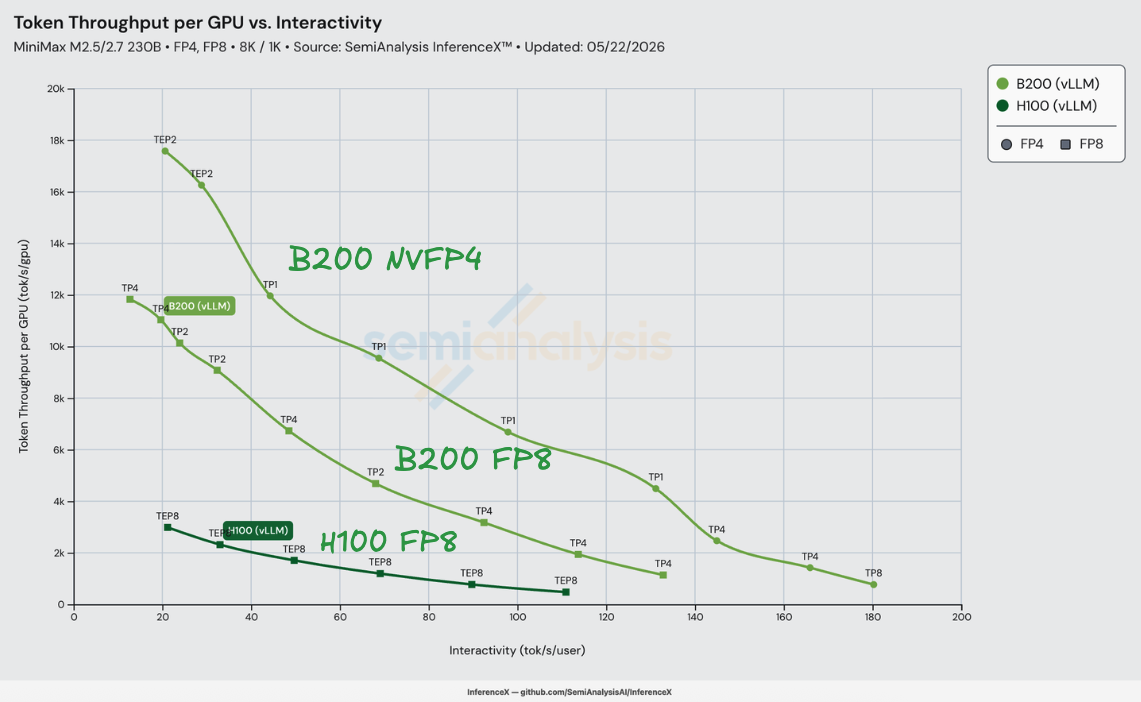
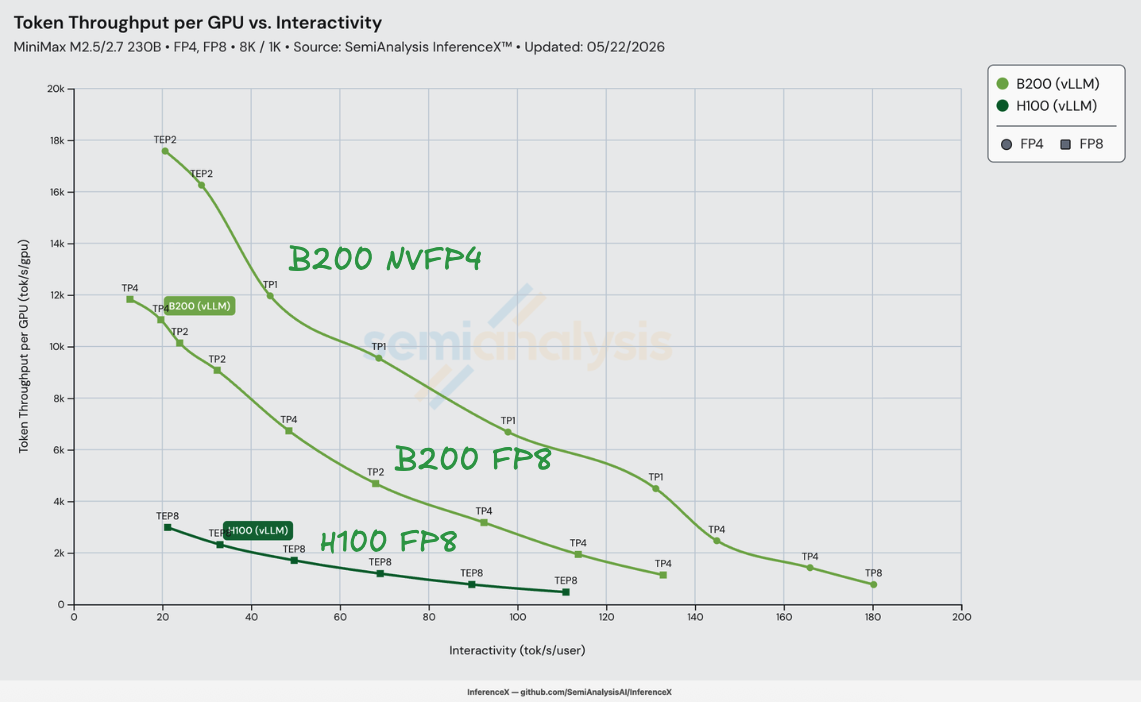
MiniMax-M2.5 is MiniMax AI's MoE flagship: 230B total parameters with 10B activated per token across 256 small experts (different architecture from the older MiniMax-Text-01's 32 large experts). The published checkpoint is MiniMaxAI/MiniMax-M2.5 and NVIDIA shipped a quantized nvidia/MiniMax-M2.5-NVFP4 variant with all MoE GEMM weights re-cast from BF16/FP8 to NVFP4 (16-element blocks, FP8 per-block scales, FP32 per-tensor scale). The KV cache stays FP8. The B200 NVFP4 line in the chart loads the NVIDIA quantized weights; the B200 FP8 and H100 FP8 lines load the original MiniMaxAI checkpoint.
The relevant architectural detail for this post is the routing method. MiniMax M2's expert-routing layer emits routing logits in a dtype the original ("monolithic") trtllm-gen FP8 MoE kernel doesn't accept — which is why MiniMax was stuck on the slower triton MoE path on B200 until vLLM PR #36307 added the modular kernel variant that handles routing externally. We come back to this in "What Shipped".
Why MiniMax-M2.5 Is Worth Optimizing For
MiniMax-M2.5 is the open-weights coding-and-agent model in the M2 series. The 256-small-expert routing layer was tuned for software-engineering workloads (SWE-Bench family, Terminal Bench, agentic tool-use eval), and on the headline coding-quality evals it lands within 1–4 points of Claude Opus 4.5/4.6 on every benchmark and leads Gemini 3 Pro on Multi-SWE-Bench (51.3 vs 42.7) and VIBE-Pro (54.2 vs 36.9). Multi-SWE-Bench specifically — which scores Opus 4.5 at 50.0 and Opus 4.6 at 50.3 — has M2.5 in front at 51.3.
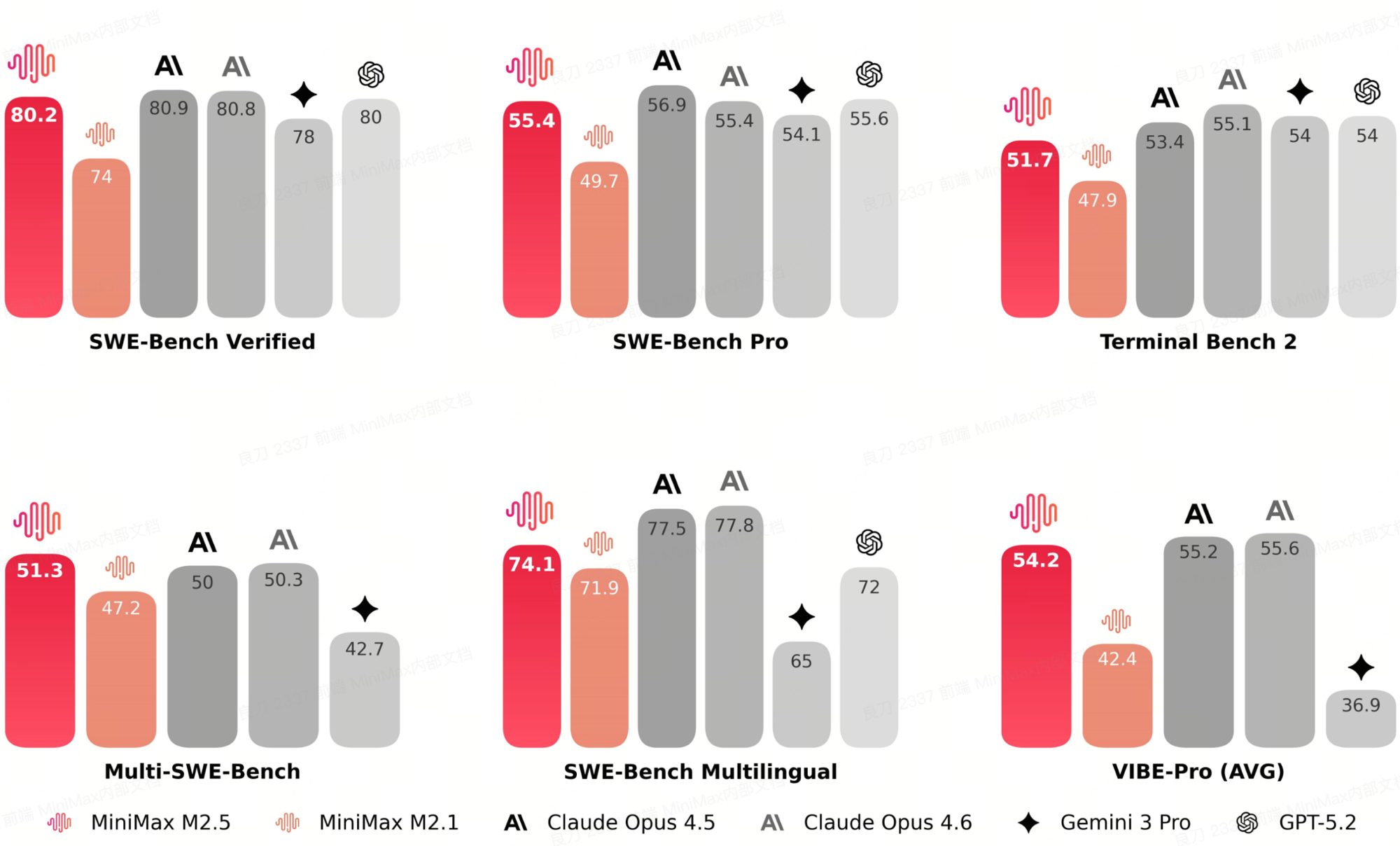
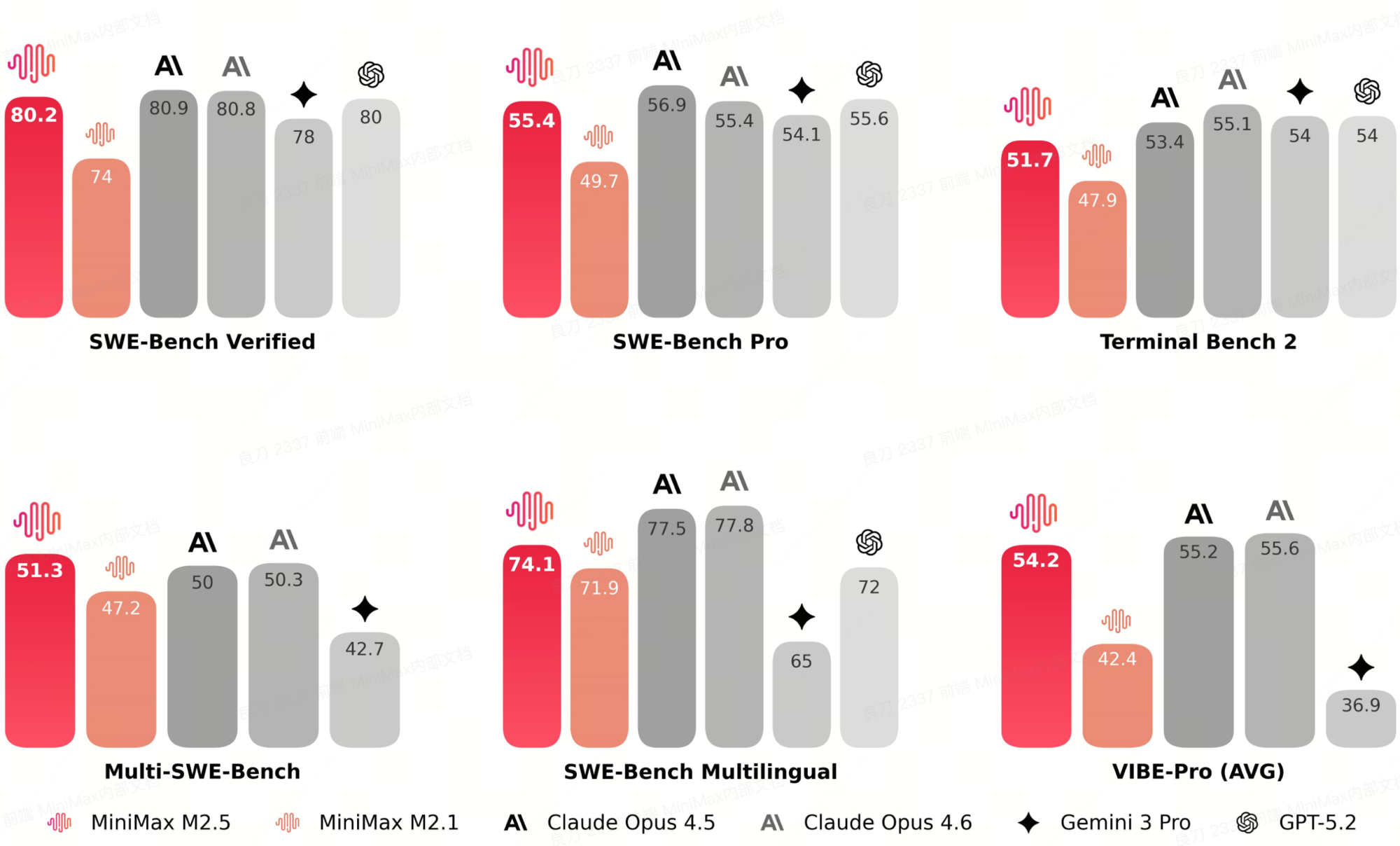
The quality context is what makes the serving cost-per-token story matter. A 10B-active open-weights MoE that holds within striking distance of frontier proprietary coding models — served at $0.031/M tokens at the throughput-anchor point on B200 NVFP4 — is a different cost-of-deployment proposition than routing the same workload to a closed-API frontier model. The vLLM PR + NVFP4 + B200 stack laid out below is what compresses the inference price-tag for that kind of agent / SWE-loop workload from "expensive to run continuously" into the range where you can keep an autonomous coding agent looping on tasks for hours without the bill writing the architecture itself.
On-Paper H100 vs B200 Specs
Before the recipes, the hardware. H100 SXM (Hopper, 2023) and B200 SXM (Blackwell, 2025) sit two generations apart. The radar below normalizes each axis to the maximum across every NVIDIA + AMD SKU in /gpu-specs — so the visible H100 and B200 polygons compress against axes where GB200/GB300 NVL72 set the ceiling (notably scale-up domain memory and scale-up domain memory bandwidth, which scale with the rack-scale 72-GPU NVLink domain).
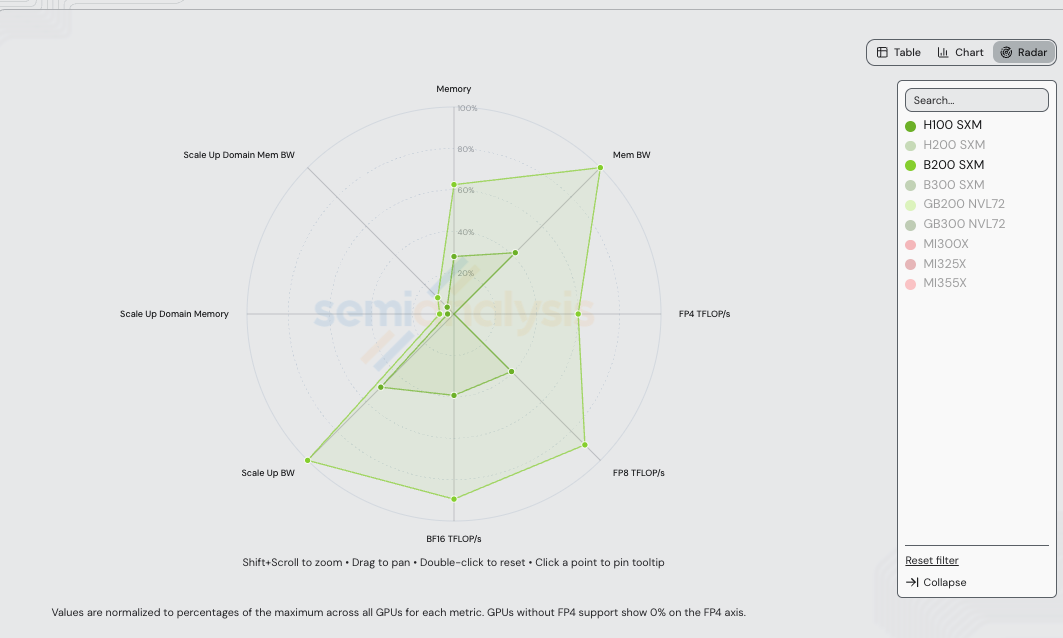
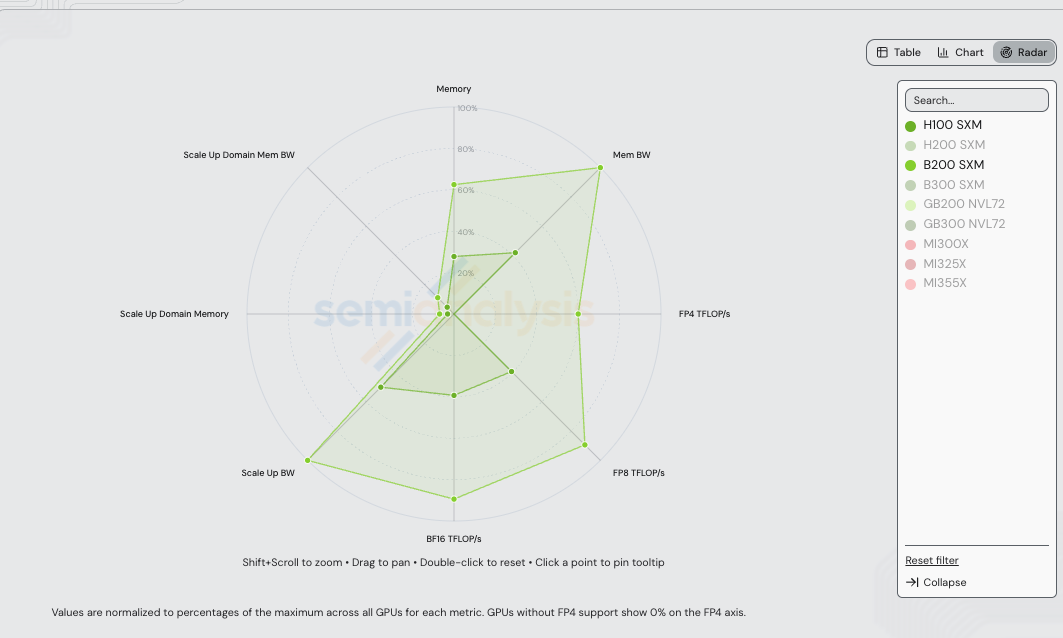
Absolute values for the two SKUs in this benchmark:
| Spec | H100 SXM | B200 SXM | B200 / H100 |
|---|---|---|---|
| HBM capacity | 80 GB (HBM3) | 180 GB (HBM3e) | 2.25x |
| HBM bandwidth | 3.35 TB/s | 8.0 TB/s | 2.39x |
| Dense FP4 (TFLOP/s) | — | 9,000 | — |
| Dense FP8 (TFLOP/s) | 1,979 | 4,500 | 2.27x |
| Dense BF16 (TFLOP/s) | 989 | 2,250 | 2.28x |
| Scale-up BW per GPU (uni-di) | 450 GB/s (NVLink 4) | 900 GB/s (NVLink 5) | 2.00x |
| Scale-up world size | 8 | 8 | 1.00x |
| Scale-up domain HBM capacity | 640 GB | 1,440 GB | 2.25x |
| Scale-up domain HBM BW (aggregate) | 26.8 TB/s | 64.0 TB/s | 2.39x |
| TCO (SemiAnalysis AI Cloud Model) | $1.30/GPU/hr | $1.95/GPU/hr | 1.50x |
What does the silicon buy on its own? B200 has 2.27x more FP8 compute than H100 (4,500 vs 1,979 TFLOP/s), 4.55x more FP4 compute than H100 has FP8 compute (9,000 vs 1,979 TFLOP/s — Hopper has zero FP4 tensor cores, so the precision step is a cross-precision compute lift, not an apples-to-apples one), and 2.39x more HBM bandwidth (8.0 vs 3.35 TB/s), all at 1.50x the TCO. Those raw ratios bound the perf/$ ceiling: 1.51x for FP8 vs FP8 on a compute-bound workload (2.27 / 1.50), 1.59x if HBM bandwidth is the constraint (2.39 / 1.50), or 3.03x for B200 NVFP4 vs H100 FP8 on the cross-precision compute axis (4.55 / 1.50).
The measured numbers go further. The 2.94x FP8 generation step is almost 2x the FP8 silicon ceiling, and the 8.16x combined lift is ~2.7x the cross-precision FP4 silicon ceiling — the gap above the silicon ceiling is the trtllm-gen modular FP8 MoE kernel (vLLM PR #36307) doing what the older triton MoE path can't. The H100 vLLM stack on MiniMax-M2.5 is leaving substantial headroom on the table compared to what the trtllm-gen kernel path delivers on B200. NVFP4 stacks the precision-step lift on top because the B200 has 9 PFLOP/s of FP4 compute and H100 has none.
TensorRT-LLM MoE Kernel Integration into vLLM
Upstream: vLLM PR #36307 — TRTLLM FP8 MoE Modular Kernel. vllm-project/vllm #36307 by Wei Zhao, merged 2026-03-12, adds a modular variant of the trtllm-gen FP8 MoE kernel for Blackwell. The previous "monolithic" trtllm-gen kernel only accepted routing-logits in a specific dtype, which excluded models like MiniMax M2 whose routing layer emits a different dtype. The modular kernel does routing externally, so the dtype constraint goes away — MiniMax M2 (and a broader set of MoE models) can now use the same fast attention + MoE kernel path that DeepSeek/Kimi/GLM-5 already used on B200. The PR's test plan ran on MiniMaxAI/MiniMax-M2.5 with TP=2 + expert parallelism enabled, the same recipe shape the B200 frontier uses below.
The kernel matters. Below is a per-kernel comparison on MiniMax-M2.5 (1K/1K — not 8K/1K, but the kernel ordering carries) showing what each MoE backend produces in vLLM:
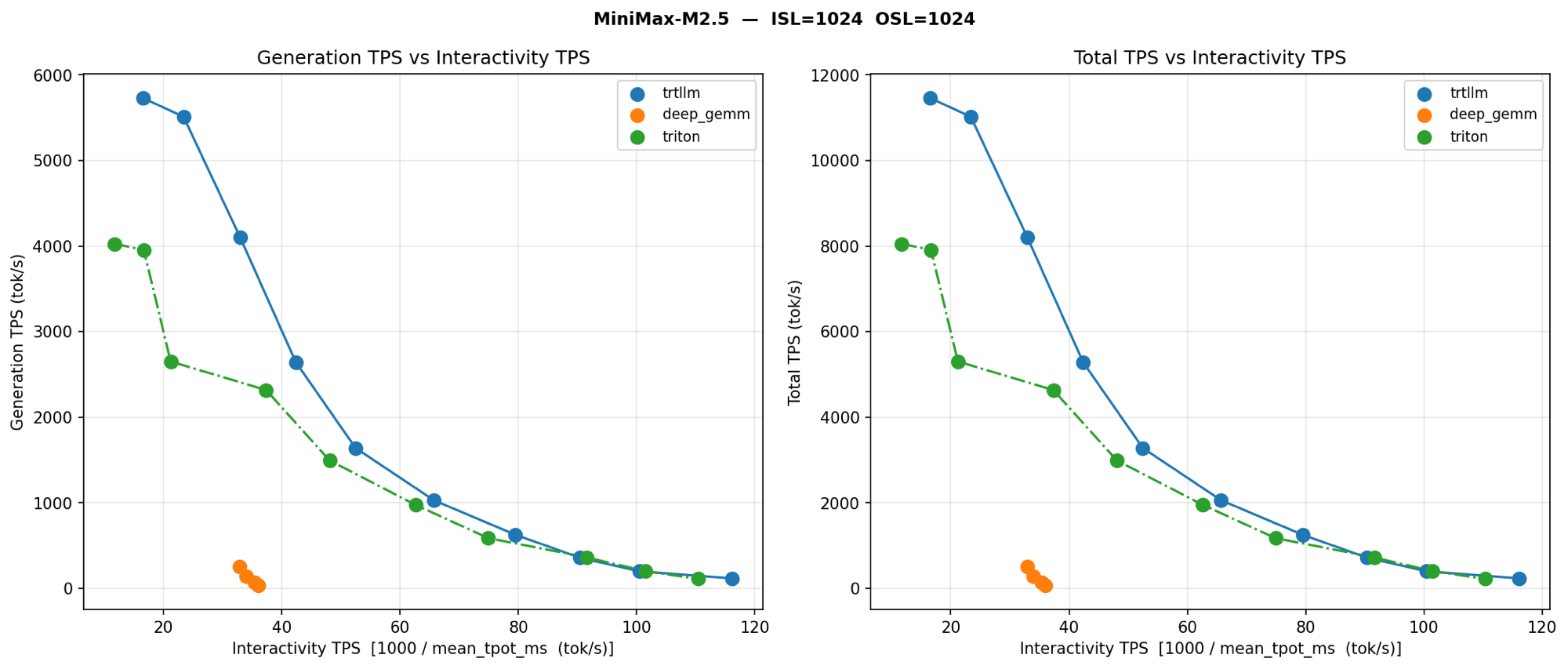
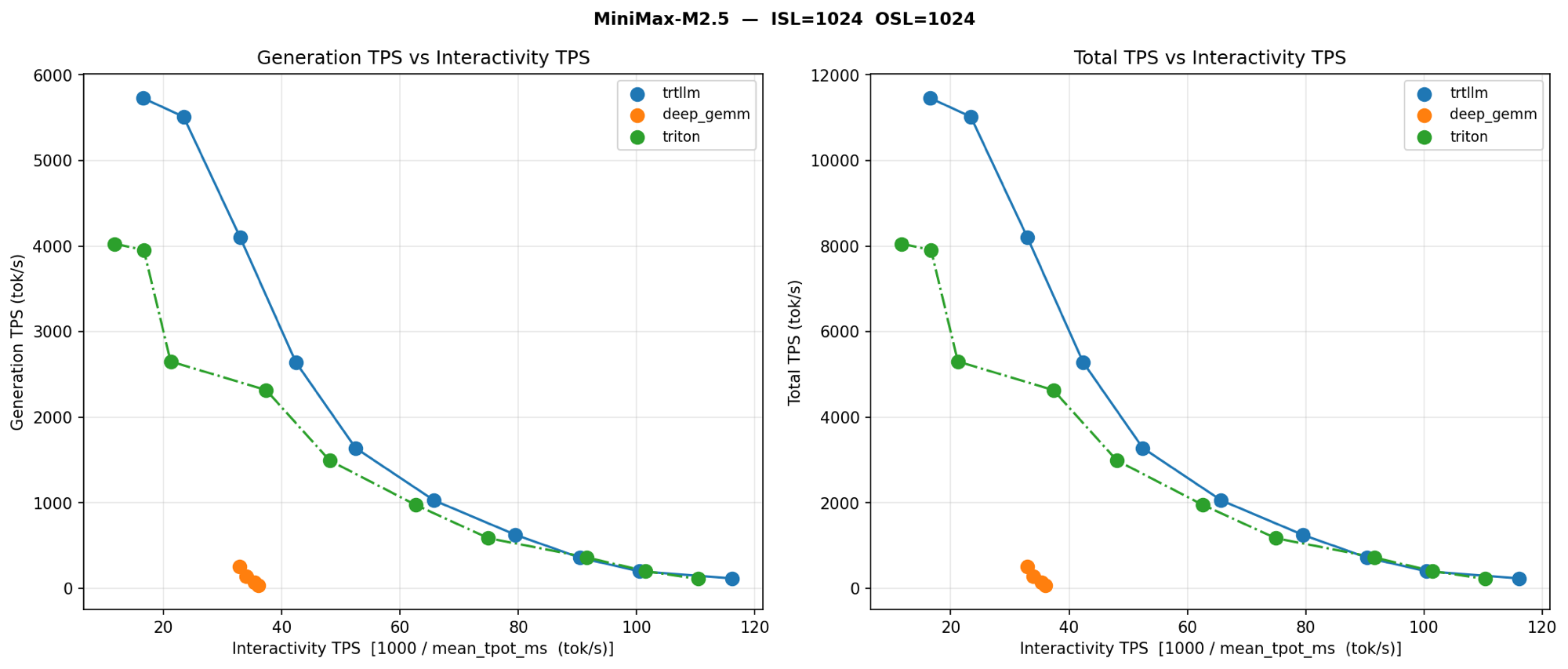
The Numbers
All rows are MiniMax-M2.5 at ISL 8192 / OSL 1024 on a single non-disaggregated node, measured on InferenceX on 2026-05-22 on vLLM. Cost per million total tokens is computed as TCO_$/GPU/hr / (3600 × tput_per_gpu / 1e6), with H100 at $1.30/GPU/hr and B200 at $1.95/GPU/hr per the SemiAnalysis AI Cloud TCO Model.
H100 vLLM FP8, TP=8 on 8 GPUs (model MiniMaxAI/MiniMax-M2.5):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 476.5 | 110.93 | 9.01 | $0.76 |
| 8 | 771.4 | 89.71 | 11.15 | $0.47 |
| 16 | 1,193.7 | 69.09 | 14.47 | $0.30 |
| 32 | 1,707.6 | 49.70 | 20.12 | $0.21 |
| 64 | 2,317.0 | 33.00 | 30.31 | $0.16 |
| 128 | 2,985.6 | 21.19 | 47.19 | $0.12 |
B200 vLLM FP8, TP=2 on 2 GPUs (the throughput anchor across most of the curve):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 1,926.8 | 112.30 | 8.90 | $0.28 |
| 8 | 3,143.5 | 92.25 | 10.84 | $0.17 |
| 16 | 4,684.8 | 68.04 | 14.70 | $0.12 |
| 32 | 6,514.0 | 47.40 | 21.10 | $0.08 |
| 64 | 9,079.0 | 32.35 | 30.91 | $0.06 |
| 128 | 10,053.9 | 23.91 | 41.82 | $0.05 |
| 256 | 10,134.1 | 23.92 | 41.81 | $0.05 |
| 512 | 10,112.2 | 23.85 | 41.93 | $0.05 |
B200 vLLM FP8, TP=4 on 4 GPUs (extends the low-interactivity arm):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 256 | 11,035.8 | 19.67 | 50.85 | $0.05 |
| 512 | 11,827.1 | 12.71 | 78.68 | $0.05 |
B200 vLLM NVFP4, TP=2 on 2 GPUs (the cost-frontier anchor on the left, model nvidia/MiniMax-M2.5-NVFP4):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 128 | 16,256.5 | 28.82 | 34.70 | $0.03 |
| 256 | 17,407.3 | 20.61 | 48.51 | $0.03 |
| 512 | 17,577.0 | 20.63 | 48.47 | $0.03 |
B200 vLLM NVFP4, TP=1 on 1 GPU (the mid/high-interactivity arm):
| Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|
| 4 | 4,488.8 | 131.18 | 7.62 | $0.12 |
| 8 | 6,683.0 | 97.87 | 10.22 | $0.08 |
| 16 | 9,546.6 | 68.76 | 14.54 | $0.06 |
| 32 | 11,698.0 | 44.16 | 22.65 | $0.05 |
| 256 | 11,962.0 | 44.29 | 22.58 | $0.05 |
B200 vLLM NVFP4, TP=4 and TP=8 on 4 and 8 GPUs (extend the high-interactivity arm at conc=4):
| Recipe | Conc | tok/s/GPU | tok/s/user | TPOT (ms) | $/M tokens |
|---|---|---|---|---|---|
| TP=4 / 4 GPUs | 4 | 1,423.3 | 165.92 | 6.03 | $0.38 |
| TP=4 / 4 GPUs | 8 | 2,468.9 | 144.91 | 6.90 | $0.22 |
| TP=8 / 8 GPUs | 4 | 768.6 | 180.26 | 5.55 | $0.70 |
The combined NVFP4 Pareto frontier walks from $0.031/M at 21 tok/s/user (TP=2, conc=512) up to $0.70/M at 180 tok/s/user (TP=8, conc=4).
Iso-Interactivity Performance per Dollar
Throughput per GPU and cost per million tokens at matched interactivity, interpolated along each SKU's Pareto frontier. Performance-per-dollar lift in the last column is the inverse of the $/M ratio — B200 NVFP4 perf/$ relative to H100. Cells outside a frontier's measured range render as unreachable.
| Interactivity (tok/s/user) | H100 FP8 $/M | B200 FP8 $/M | B200 NVFP4 $/M | B200 NVFP4 perf/$ vs H100 |
|---|---|---|---|---|
| 22 | $0.12 | $0.05 | $0.031 | 3.96x |
| 30 | $0.15 | $0.06 | $0.034 | 4.32x |
| 40 | $0.18 | $0.07 | $0.042 | 4.23x |
| 50 | $0.21 | $0.08 | $0.048 | 4.39x |
| 60 | $0.25 | $0.10 | $0.052 | 4.85x |
| 70 | $0.31 | $0.12 | $0.058 | 5.36x |
| 80 | $0.38 | $0.14 | $0.065 | 5.84x |
| 90 | $0.47 | $0.16 | $0.073 | 6.41x |
| 100 | $0.60 | $0.20 | $0.083 | 7.19x |
| 110 | $0.74 | $0.25 | $0.091 | 8.16x |
| 130 | unreachable | $0.44 | $0.118 | ∞ |
| 150 | unreachable | unreachable | $0.250 | ∞ |
| 175 | unreachable | unreachable | $0.569 | ∞ |
B200 NVFP4's perf/$ lift over H100 climbs monotonically from 3.96x at 22 tok/s/user to 8.16x at 110 tok/s/user, with the peak at 8.23x at 110.8 tok/s/user — the right edge of H100's measurable range. Unlike a same-generation comparison where the lift is roughly flat across the band, this one grows fast: H100's frontier falls off steeply on the right (its conc=4 point sits at only 476 tok/s/GPU at $0.76/M), while B200 NVFP4 still has 4–5x that throughput at the same interactivity. The precision-only lift (B200 FP8 → B200 NVFP4) widens from 1.65x at 22 tok/s/user to 2.77x at 110 — the trtllm-gen kernel's GEMM headroom over the triton path becomes the binding constraint as batch shrinks. Above 110 tok/s/user the comparison stops being a comparison: H100 has no recipe that delivers another tok/s/user, while B200 NVFP4 extends the regime out to 180 tok/s/user on TP=8.
Live chart, pre-filtered to MiniMax-M2.5 vLLM on H100 + B200 for the 2026-05-22 run. Live cost view of the same comparison.
What's Next for Blackwell on MiniMax-M2.5
Three gaps still expand or sharpen the headline number from here:
- NVL72 disagg (without wide EP). Wider expert parallelism isn't the right lever for this model — at 10B active params on 256 small experts, each rank in a TP=2 / 8-GPU configuration already holds only a handful of experts, so widening EP across a 72-GPU NVLink domain doesn't shrink the per-rank weight footprint enough to matter (unlike DeepSeek R1 or Kimi K2.5, where wide EP compounds via compute-comm overlap on the EP collectives). Disaggregated prefill + decode is still on the table though: today's single-node aggregated recipe puts both stages on the same TP=2 island and contends for HBM bandwidth at the conc 256+ saturation knee; a disagg recipe on GB200/GB300 NVL72 would move KV between dedicated prefill and decode pools over NVLink 5 and let the decode pool absorb more concurrency before saturating. No InferenceX disagg recipe for MiniMax on NVL72 has shipped yet.
For MiniMax-M2.5 serving on vLLM today, B200 NVFP4 is the cheaper choice by 4x–8.2x across every interactivity point H100 can reach.
Acknowledgments
Wei Zhao at NVIDIA merged the trtllm FP8 MoE modular kernel in vLLM on 2026-03-12. Thanks to Wei Zhao and the vLLM TRT-LLM kernel collaborators, the InferenceX recipe maintainers, and the MiniMax AI team for the open-weights releases.
All articles and posts are © SemiAnalysis. All rights reserved. The AGPL-3.0 license covering the application source code does not apply to article content.