LLM 推理性能取决于两大支柱:硬件和软件。硬件创新通过每年发布新型 GPU/XPU 和新系统来驱动性能的阶跃式提升,而软件则每天都在演进,在这些硬件跃升之上持续带来性能增益。
SGLang、vLLM、TensorRT-LLM、CUDA 和 ROCm 等 AI 软件通过内核级优化、分布式推理策略和调度创新实现持续的性能改进,以仅相隔数天的增量更新不断推高性能的帕累托前沿。
这种软件进步的速度带来了一个挑战:在某个固定时间点进行的基准测试很快就会过时,无法反映使用最新软件包所能达到的真实性能。
InferenceMAX 是一个开源的自动化基准测试项目,旨在与软件生态系统本身同步快速迭代,专为应对这一挑战而设计。
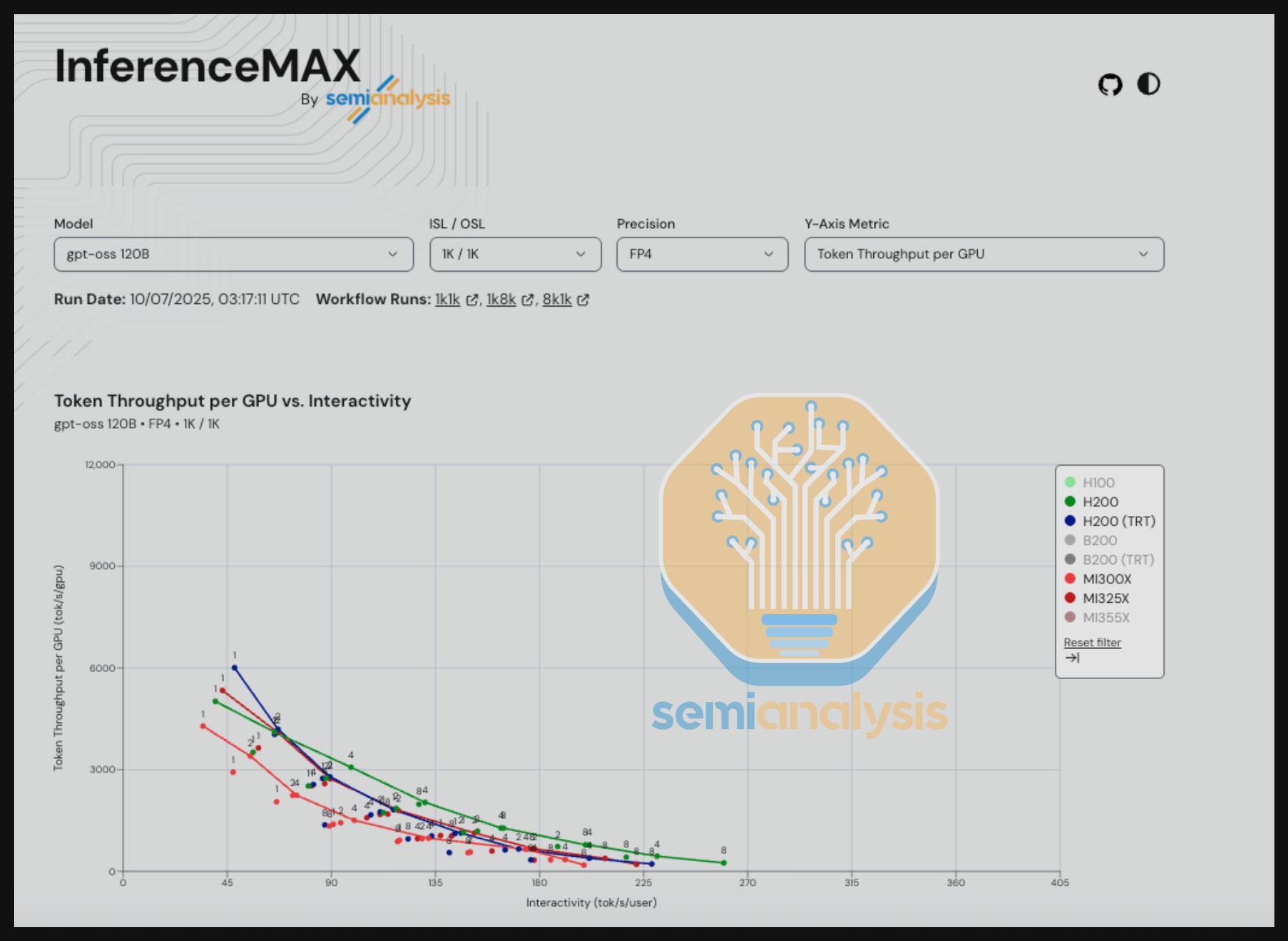
InferenceMAX 每夜在数百块芯片上运行我们的完整基准测试套件,持续对全球最流行的开源推理框架和模型进行重新测试,以实时追踪真实性能。随着这些软件栈的不断改进,InferenceMAX 近乎实时地捕捉这些进展,提供推理性能进步的实时指标。免费的公开实时仪表板可在 https://inferencemax.ai/ 访问。
AMD 和 Nvidia GPU 都能在不同的工作负载下提供有竞争力的性能,AMD 在某些类型的工作负载上表现更好,而 Nvidia 在其他类型上表现更优。的确,两个生态系统都在快速发展!
在分析 InferenceMAX 的结果时有许多细微差别和需要考量的因素,这在很大程度上是因为它被设计为一个中立的基准测试,不会为了推广任何特定供应商或解决方案而进行数据筛选。因此,存在一些模型和交互性(tok/s/user)水平,在这些场景下 AMD 目前表现优于同代 Nvidia GPU;同样也存在 Nvidia 目前表现更好的交互性水平。InferenceMAX 的目标简单而宏大——提供既尽可能模拟真实应用场景、又反映软件创新持续步伐的基准测试。
在 InferenceMAX v1 的首次发布中,我们对 GB200 NVL72、B200、MI355X、H200、MI325X、H100 和 MI300X 进行了基准测试。在接下来的两个月内,我们将扩展 InferenceMAX 以纳入 Google TPU 和 AWS Trainium 后端,使其成为首个真正跨 AMD、NVIDIA 和定制加速器的多供应商开放基准测试项目。
InferenceMAX v1 远非完美,但我们相信它是朝着正确方向迈出的良好第一步。在未来的版本中,还有优化工作负载、扩展模型覆盖范围以及更好地反映真实工作负载的空间。
致谢
感谢 Lisa Su 和 Anush Elangovan 为这个免费开源项目提供了 MI355X 和 CDNA3 GPU。我们要感谢 Anush、Quentin Colombet 以及数十位 AMD 贡献者对各类问题的快速响应,以及他们在 AMD GPU 的调试、优化和性能验证方面给予的帮助。每当我们遇到 ROCm 问题(我们注意到,这些问题出现的频率远低于 2024 年底!),他们都会立即介入帮助找到临时修复方案以消除阻塞,随后将永久补丁合入 ROCm 以确保长期稳定性。Quentin 及其团队展现了 AMD 2.0 的紧迫感,这种态度受到 xAI 等众多客户的高度赞赏。
我们也感谢 Jensen Huang 和 Ian Buck 通过提供 GB200 NVL72 机架(通过 OCI)和 B200 GPU 的访问来支持这一开源项目。感谢 Kedar Pandurang Potdar、Sridhar Ramaswamy、Kyle Kranen、ptrblck、NVIDIA 推理团队、NVIDIA Dynamo 团队、NCCL 团队以及 Nvidia 固件/驱动团队在验证和优化 Blackwell 和 Hopper 配置以及快速修复 Bug 方面给予的帮助。
我们还要感谢 SGLang、vLLM 和 TensorRT-LLM 的维护者们构建了世界一流的软件栈并将其开源给全世界。此外,我们要感谢 Simon Mo、Kaichao You、Michael Goin 和 Robert Shaw,他们在解决几个关键的 Blackwell Bug 方面提供了不可或缺的帮助。
最后,我们感谢 Crusoe、CoreWeave、Nebius、TensorWave、Oracle 和 TogetherAI 通过计算资源支持开源创新,使这个项目得以实现,同时也感谢更广泛的社区推动推理基准测试的发展。
我们正在招聘
我们正在寻找一名工程师加入我们的特别项目团队。这是一个独特的机会,可以参与如 InferenceMAX 这样高曝光度的特别项目,并获得众多行业领袖和 CEO 的支持。如果你对性能工程、系统可靠性充满热情,并希望在硬件和软件的交叉领域工作,这是一个产生全行业影响的难得机会。
你将参与的工作:
- 跨多供应商(AMD、NVIDIA、TPU、Trainium 等)构建和运行大规模基准测试
- 设计可复现的 CI/CD 流水线以自动化基准测试工作流
- 确保行业合作伙伴使用的系统的可靠性和可扩展性
我们期望的候选人特质:
- 扎实的 Python 技能
- 站点可靠性工程(SRE)或系统级问题解决的背景
- CI/CD 流水线和现代 DevOps 实践经验
- 对 GPU、TPU、Trainium、多云和性能基准测试的好奇心
申请链接:https://app.dover.com/apply/SemiAnalysis/2a9c8da5-6d59-4ac8-8302-3877345dbce1
InferenceMAX 项目支持者
InferenceMAX 项目得到了许多大型计算资源买家和 ML 社区知名成员的支持,包括来自 OpenAI、Microsoft、PyTorch Foundation 等组织的人士:
"随着我们以前所未有的规模构建系统,ML 社区拥有开放、透明的基准测试来反映推理在各种硬件和软件上的真实表现至关重要。InferenceMAX 的直接对比基准测试消除了噪声,提供了关于 token 吞吐量、性价比和每兆瓦 token 数的实时全景。这种开源努力增强了整个生态系统的实力,帮助从研究人员到前沿数据中心运营者在内的每一个人做出更明智的决策。"
-- Peter Hoeschele,OpenAI Stargate 基础设施与工业计算副总裁
"开放协作正在推动 AI 创新的下一个时代。开源的 InferenceMAX 基准测试为社区提供了透明的每夜测试结果,激发信任并加速进步。它凸显了我们 AMD Instinct MI300、MI325X 和 MI355X GPU 在多样化工作负载下具有竞争力的 TCO 性能,彰显了我们平台的优势以及我们致力于让开发者实时了解软件进展的承诺。"
-- Lisa Su 博士,AMD 董事长兼 CEO
"推理需求正在呈指数级增长,这是由长上下文推理所驱动的。NVIDIA Grace Blackwell NVL72 正是为这个思考型 AI 的新时代而发明的。NVIDIA 通过持续的硬件和软件创新来满足这一需求,为 AI 的下一步发展赋能。通过频繁的基准测试,InferenceMAX 为行业提供了 LLM 推理性能在真实工作负载上的透明视图。结果很明确:搭载 TRT-LLM 和 Dynamo 的 Grace Blackwell NVL72 提供了无与伦比的性价比和能效比——驱动着世界上最高效、最具成本效益的 AI 工厂。"
-- Jensen Huang,NVIDIA 创始人兼 CEO
"速度就是护城河。InferenceMAX 的每夜基准测试与 AMD 软件栈的改进速度保持同步。看到 AMD 的 MI300、MI325 和 MI355 GPU 在多样化工作负载和交互性水平下表现如此出色,令人振奋。"
-- Anush Elangovan,AMD GPU 软件副总裁
"InferenceMAX 凸显了 ML 社区关注的工作负载。在 NVIDIA,我们欢迎这些对比,因为它们证实了我们全栈方案的优势——从 GPU 硬件到 NVLink 网络,到 NVL72 机架规模,再到 Dynamo 分离式推理服务,始终在规模化场景下提供行业领先的推理性能和投资回报率。"
-- Ian Buck,NVIDIA 超大规模部门副总裁兼总经理、CUDA 发明者
"InferenceMAX 的每夜测试结果凸显了 AMD 软件栈的快速进步。亲眼见证一个开放项目的诞生令人兴奋——它在 AMD 软件团队的工作与特定 ML 用例在我们 MI300、MI325 和 MI355 GPU 上的实际影响之间建立了紧密的反馈循环。我期待看到 InferenceMAX 的后续发展,并展示 AMD 平台的全部潜力。AMD GPU 将继续每周变得更快。"
-- Quentin Colombet,AMD 高级总监,前 Brium CEO
"我们在 Azure 的使命是为客户提供最高性能、最高效、最具成本效益的 AI 云。SemiAnalysis InferenceMAX 通过提供透明、可复现的基准测试来支持这一使命,这些测试在真实工作负载下追踪不同 GPU 和软件栈的推理性能。这些关于吞吐量、效率和每瓦成本的持续数据增强了我们为规模化调优 Azure 推理平台的能力,帮助客户在 Microsoft Cloud 上自信地构建应用。"
-- Scott Guthrie,Microsoft 云与 AI 执行副总裁
"在 Microsoft,为我们的客户大规模提供最佳推理性能和经济效益需要深入理解 AI 模型如何与真实硬件和软件交互。像 InferenceMAX 这样的开源、可复现的基准测试对于在真实工作负载下产生关于吞吐量、效率和成本的透明洞察至关重要。这些持续信号有助于指导我们的平台战略,使我们能够从硅片到系统再到软件优化整个栈,让每一层协同工作以释放基础设施的全部潜力。"
-- Saurabh Dighe,Azure 战略规划与架构公司副总裁
"理论峰值与真实推理吞吐量之间的差距往往取决于系统软件:推理引擎、分布式策略和底层内核。InferenceMAX 的价值在于它对最新软件进行基准测试,展示了 FP4、MTP、投机解码和 wide-EP 等优化在不同硬件上的实际表现。这样的开放、可复现结果有助于整个社区更快前进。"
-- Tri Dao,Together AI 首席科学家、Flash Attention 发明者
"行业需要更多公开、可复现的推理性能基准测试。我们很高兴从 vLLM 团队的角度与 InferenceMAX 合作。更多样化的工作负载和场景——每个人都可以信赖和引用——将有助于生态系统向前发展。公正、透明的测量驱动着从模型架构到推理引擎再到硬件的每一层进步。"
-- Simon Mo,vLLM 项目联合负责人
"The benchmark is good sir"
-- Michael Goin,vLLM 维护者
"InferenceMAX benchmark is pogchamp & W in chat"
-- Kaichao You,vLLM 项目联合负责人
"InferenceMAX 展示了开放生态系统在实践中的运作方式。vLLM、SGLang 和 TensorRT-LLM 等许多领先的推理栈都构建在 PyTorch 之上,而这样的基准测试展示了内核、运行时和框架层面的创新如何转化为在包括 NVIDIA 和 AMD GPU 在内的各种硬件平台上的可量化性能。通过开源和每夜运行,InferenceMAX 为追踪进展和为 PyTorch 用户提供数据驱动的洞察提供了一种透明的、社区驱动的方法。"
-- Matt White,PyTorch Foundation 执行总监
"Oracle Cloud Infrastructure 旨在为前沿实验室和企业提供灵活性和选择权,拥有多种 GPU SKU 可用于大规模 AI。InferenceMAX 通过提供开源、可复现的基准测试来增强这一使命,这些测试反映了最新硬件和软件上的真实性能、效率和成本。凭借这种透明度,客户可以自信地选择最符合其 AI 战略的平台。"
-- Jay Jackson,Oracle Cloud Infrastructure 副总裁
"InferenceMAX 通过提供开放、透明的基准测试来提升标准,追踪推理在最新 GPU 和软件栈上的真实表现。对于客户而言,拥有测量真实每美元 token 数和每瓦 token 数的可复现数据,将抽象的营销数字转化为可操作的洞察。在 CoreWeave,我们支持这一努力,因为它为快速变化的领域带来了清晰度,帮助整个生态系统自信地构建。"
-- Peter Salanki,CoreWeave CTO
"InferenceMAX 通过提供开放、透明的基准测试树立了新标准,揭示了推理在当今领先 GPU 和软件栈上的真实表现。凭借测量真实每美元 token 数和每瓦 token 数的可复现数据,客户可以超越营销宣传,获取可操作的洞察。对于我们 Nebius 而言——作为全栈 AI 云提供商——这一项目帮助我们自信地构建推理平台,确保我们与生态系统保持一致。"
-- Roman Chernin,Nebius 联合创始人兼首席商务官
"在 Crusoe,我们相信成为一个出色的合作伙伴意味着赋予客户选择权和清晰度。这就是我们自豪地支持 InferenceMAX 的原因——它为整个 AI 社区提供了针对最新硬件的开源、可复现的基准测试。通过提供关于吞吐量、效率和成本的透明、真实的数据,InferenceMAX 穿透了炒作,帮助客户自信地为其独特工作负载选择最佳平台。"
-- Chase Lochmiller,Crusoe 联合创始人兼 CEO
"Supermicro 对 InferenceMAX 的发布感到兴奋——这是 SemiAnalysis 打造的基准测试系统,用于测量真实吞吐量、性价比和能源效率。这个开源工具提供了在最新硬件和软件上运行的可复现基准测试,使 AI 实验室和企业能够大规模选择最佳平台。"
-- Charles Liang,Supermicro 创始人兼 CEO
"在 TensorWave,我们正在 AMD GPU 上构建下一代云,因为我们相信当客户拥有强有力的替代选择时,创新才会蓬勃发展。InferenceMAX 通过提供开源、可复现的基准测试来支持这一愿景,这些测试追踪最新硬件和软件上的吞吐量、效率和成本。通过穿透合成数字并凸显真实推理性能,它帮助客户看到 AMD 平台在大规模 AI 方面的全部潜力。"
-- Darrick Horton,TensorWave CEO
"Vultr 致力于提供一个开放的生态系统,为开发者提供自由选择——无论是在 NVIDIA 还是 AMD GPU 上——以构建和扩展 AI。借助 InferenceMAX,客户可以获得开放、可复现的基准测试,清晰地洞察最前沿硬件和软件的吞吐量、效率和成本。通过展示真实性能,我们赋能团队自信地为其 AI 工作负载选择合适的平台。"
-- Nathan Goulding,Vultr 工程高级副总裁
吞吐量(tok/s/gpu)与延迟/交互性(tok/s/user)之间的根本权衡
在大规模服务 LLM 时,核心权衡在于吞吐量与交互性(以每用户每秒 token 数为单位)。吞吐量是每块 GPU 处理 token 的速率(tok/s/gpu),而交互性描述的是为每个单独用户生成 token 的速率(tokens/sec/user)。简单来说,你可以为单个用户提供快速高效的服务——通常通过同时服务较少的用户来实现——但这样做的代价是整体 GPU 吞吐量降低。
这种权衡的存在是因为 LLM 推理依赖于矩阵乘法运算,而这些运算受益于将多个请求批量处理——即同时服务更多用户。大批量处理能够实现更好的 GPU 利用率和更高的 token 吞吐量,但它将可用资源分配给了更多请求,从而降低了每个用户的 token 处理速度。反之,小批量将 GPU 资源集中在较少的请求上——即更少的用户,以整体吞吐量为代价换取高交互性。在实践中,大多数提供商的目标是在这两个极端之间取得平衡。在这一权衡曲线上的最优点取决于具体用例:一些应用优先考虑响应速度,而另一些则优先考虑吞吐量。然而,目标交互性水平直接决定了推理成本。更高的交互性意味着更高的成本。
拥有或租用 GPU 系统进行推理通常带来固定的每小时美元成本。因此,随着交互性增加和整体吞吐量下降,每小时处理的 token 数量减少,推高了每 token 的单位成本(以每百万 token 成本衡量)。为保持盈利,提供商必须将每 token 价格设定在其服务成本之上。这意味着高交互性用例需要更高的每 token 价格以支撑这一更高的成本,而高吞吐量应用可以以更低的价格提供服务。
一个简单的类比可以说明整个权衡关系。一辆公交车和一辆法拉利的绝对拥有成本可能非常相似,但公交车将这一成本分摊到几十名乘客身上,而法拉利只服务一两个人。法拉利通过即刻出发、直达路线和优质体验提供卓越的响应性,但每位乘客的成本从根本上更高。LLM 服务运营受制于类似的约束。
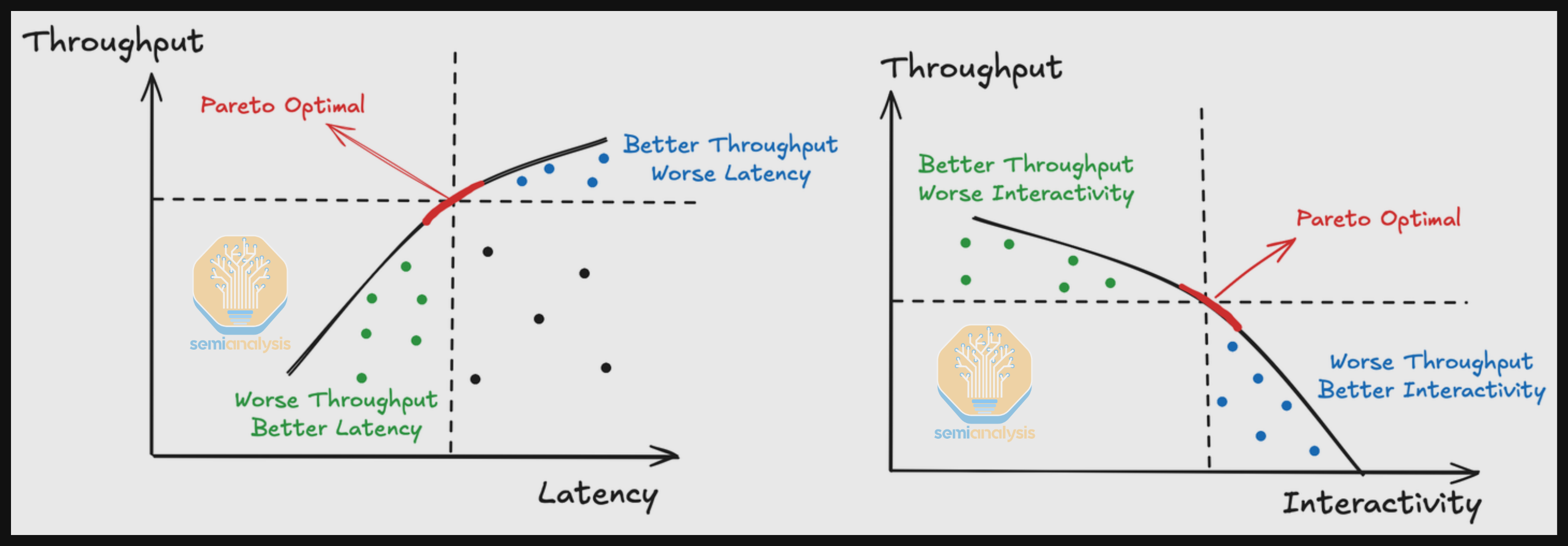
帕累托前沿曲线
吞吐量和延迟之间始终存在权衡。为了确定帕累托前沿曲线,我们尝试找到每一个数据点 P,使得不存在任何一个点在吞吐量和延迟两个维度上都优于点 P。这意味着数据点 P 是帕累托最优的,即没有其他点能在改善一个维度的同时不牺牲另一个维度。当我们将这些帕累托最优点连接起来,就得到了帕累托前沿曲线。
InferenceMAX v1 基准测试方法论
提供反映不同 GPU、推理引擎和工作负载在多种交互性水平下全部可能性的基准测试,是 InferenceMAX 的核心目标。本节将介绍基准测试方法论如何被设计来实现这一目标。
对于每次基准测试运行,我们设置一个推理服务器和一个基准测试客户端。推理服务器监听请求并处理它们。我们根据模型使用 vLLM、SGLang 和 TRT-LLM。对于基准测试客户端,我们使用移除了 vLLM 依赖的 vLLM benchmark serving 脚本。基准测试客户端发送请求、记录运行时间,并保存与推理作业相关的指标。
我们选择使用随机序列的基准测试请求以避免前缀缓存(prefix caching),因为目前将前缀缓存纳入考量的复杂度较高。前缀缓存因工作负载不同而差异显著,需要仔细调查请求模式以选择具有代表性的前缀比率。在 InferenceMAX 的未来迭代中,我们将使用 shareGPT 等数据集替代随机数据。我们将请求速率设置为无限,并设置最大并发请求数,从而捕获推理服务器在处理特定数量请求时的行为。我们还将总请求数设置得足够大,以摊销冷启动不稳定因素,例如 JIT 编译时间。
对于输入/输出序列长度,我们最终确定了三组:1024 输入 token / 1024 输出 token 代表对话工作负载,1024 输入 token / 8192 输出 token 代表推理(reasoning)工作负载,8192 输入 token / 1024 输出 token 代表摘要工作负载。为了模拟真实请求具有不同输入序列长度的情况,我们将每个请求的输入长度在指定输入序列长度的 80% 到 100% 之间随机变化。
基准测试运行的配置选项如下:
- 模型:LLaMA 70B、DeepSeek R1、gpt-oss 120B
- 精度:MXFP4 weights、FP8、FP4
- GPU:H100、H200、B200、GB200 NVL72、MI300X、MI325X、MI355X
- 开源框架:vLLM、SGLang、TRT-LLM
- 并行度:1、2、4、8 等
- 最大并发数:4、8、16、32、64 等
在模型方面,我们选择 LLaMA3 70B 作为稠密企业模型部署的代表。
对于稀疏 MoE 模型的基准测试,我们选择了 DeepSeekV3 670B。从算术强度、近似活跃参数数量、总参数量和内存访问模式来看,DeepSeekV3 的模型架构是最接近 OpenAI 4o/5 等前沿闭源模型架构的模型。因此,DeepSeek 是用于基准测试以推断 OpenAI 内部模型架构可能表现的最佳代理模型。
对于较小的稀疏 MoE 模型,我们选择了 GPT-OSS 120B MoE,因为它在算术强度、近似活跃参数数量、总参数量和内存访问模式方面最接近 GPT-5 mini。
我们根据硬件支持情况,在各模型上对 FP8、FP4 和 MX4 weights 进行基准测试。我们扫描不同的最大并发用户数(一个类似于 batch size 的概念)来绘制完整的吞吐量和延迟曲线。我们还扫描不同的模型并行方案,因为更大的模型并行度可以减少内存加载时间,从而在一定程度上提高低延迟区间的吞吐量,以找到帕累托前沿曲线。
为了防止 SGLang 与 vLLM 基准测试大战的重演并节省计算时间,我们决定首先为每个模型只选择 vLLM 或 SGLang 中的一个作为默认引擎。早在 7 月份,我们就告知 AMD 和 Nvidia,我们将使用 SGLang 作为 DeepSeek 670B 的引擎,使用 vLLM 作为 Llama3 70B 和 Llama4 的引擎。后来我们用 GPT-OSS 120B 替换了 Llama4,因为没有人使用 Llama4,而 GPT-OSS 120B 更接近较小的 "mini" 前沿模型。
我们希望服务器配置尽可能反映真实部署情况,因此要求 AMD 和 Nvidia 提交与其文档指南中讨论如何在其硬件上部署这些模型时相当接近的配置:
- https://docs.nvidia.com/llm-inference-quick-start-recipes/index.html
- recipes.vllm.ai
- https://rocm.docs.amd.com/en/docs-7.0-docker/benchmark-docker/inference-vllm-gpt-oss-120b.html
我们之前没有明确说明 InferenceMAX 是否允许预热(warmup),所以 Nvidia 在其 SGLang DeepSeek 提交中包含了一个预热阶段来处理某些 JIT 编译的内核。在基准测试开发接近尾声时,AMD 注意到了上述关于 Nvidia 提交的情况,并询问是否允许预热,因为他们没有意识到自己也可以这样做。经过 AMD、Nvidia 和 SemiAnalysis AI 工程团队之间的讨论,各方同意目前禁止预热,并将 DeepSeek 基准测试的时长延长最多 5 倍以确保公平。这次沟通混乱是我们的失误,因为从一开始就没有明确预热规则。我们计划在发布后重新审视这一议题,因为在真实生产推理中,预热通常在 Kubernetes 控制平面将 Pod 报告为健康之前发生。
讨论:DeepSeek R1 服务策略
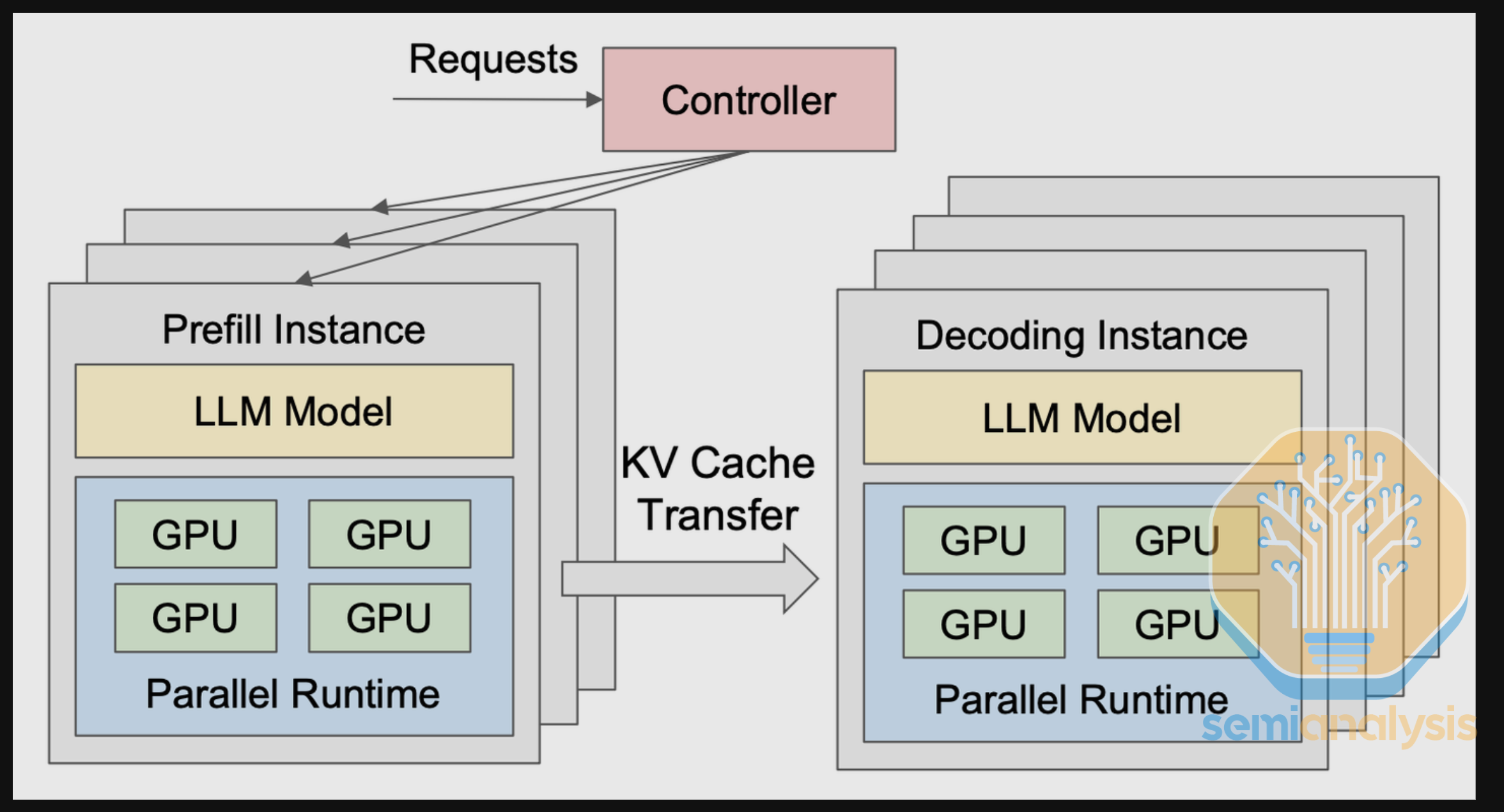
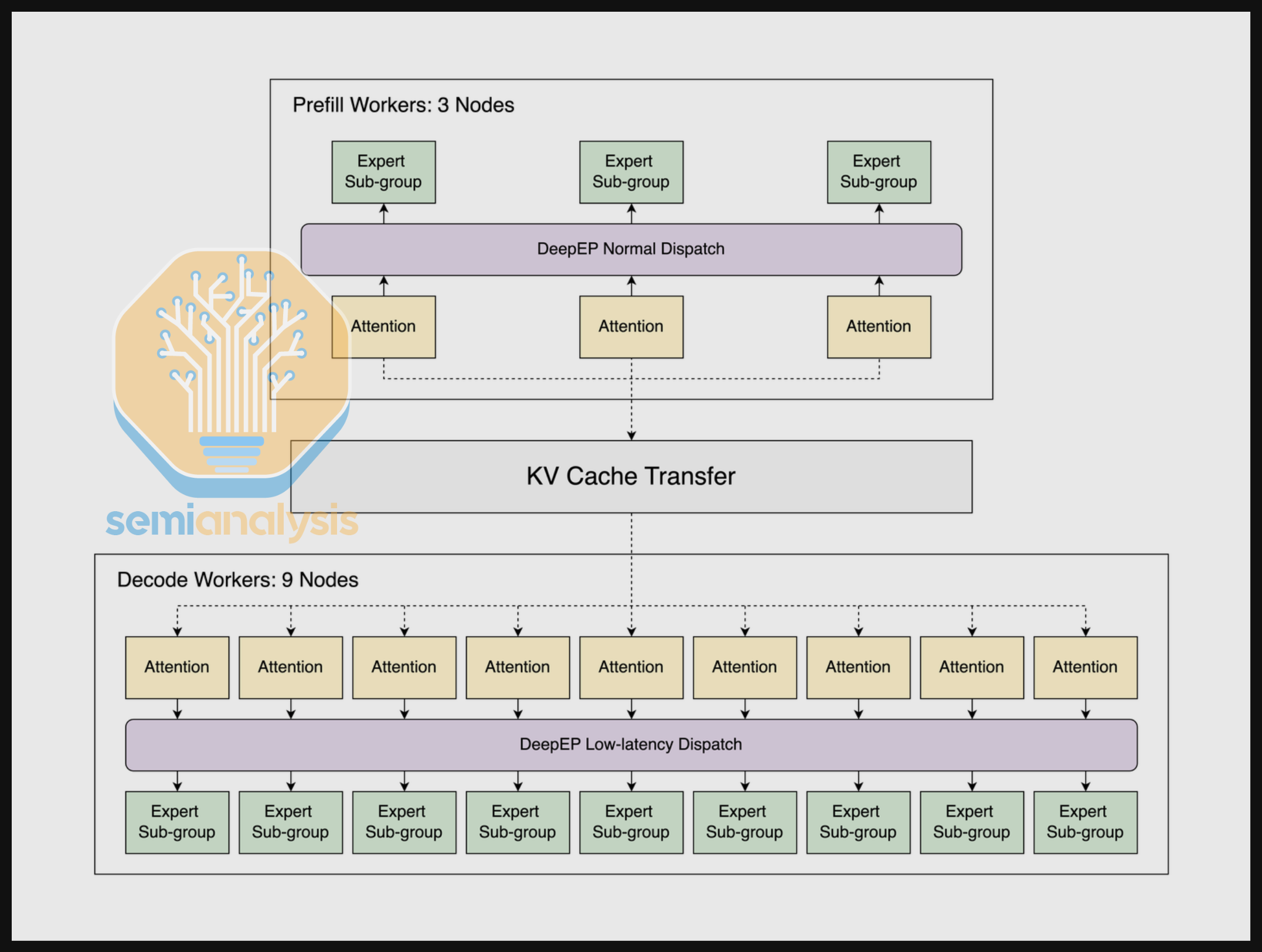
我们允许供应商可选地为 DeepSeek R1 提交分离式服务(disaggregated serving)配置。分离式服务将推理的两个阶段——预填充(prefill)和解码(decode)——分配给不同的 GPU 资源。通过分离这两个阶段,处于不同阶段的请求不会相互干扰,从而实现更好的 SLA 保障,尤其在高并发场景下。
我们还将分离式服务与大规模专家并行(wide EP)相结合。Wide EP 通过多种技术实现,其中最值得注意的是 DeepEP。DeepEP 提供两种分发模式:常规模式和低延迟模式。常规模式专注于提高预填充阶段的吞吐量,而低延迟模式则为降低解码阶段的延迟而定制。
对于 DeepSeek R1 的分离式服务,我们还收到了启用多 token 预测(MTP)的提交。DeepSeek R1 实现了 MTP,即模型通过额外的 MTP 模块在每次前向传播中预测多个 token。根据 DeepSeek 的说法,使用 MTP 训练可以提高模型的规划能力。此外,在推理过程中使用 MTP 模块可以在对模型质量损失极小的情况下提升 token 吞吐量。
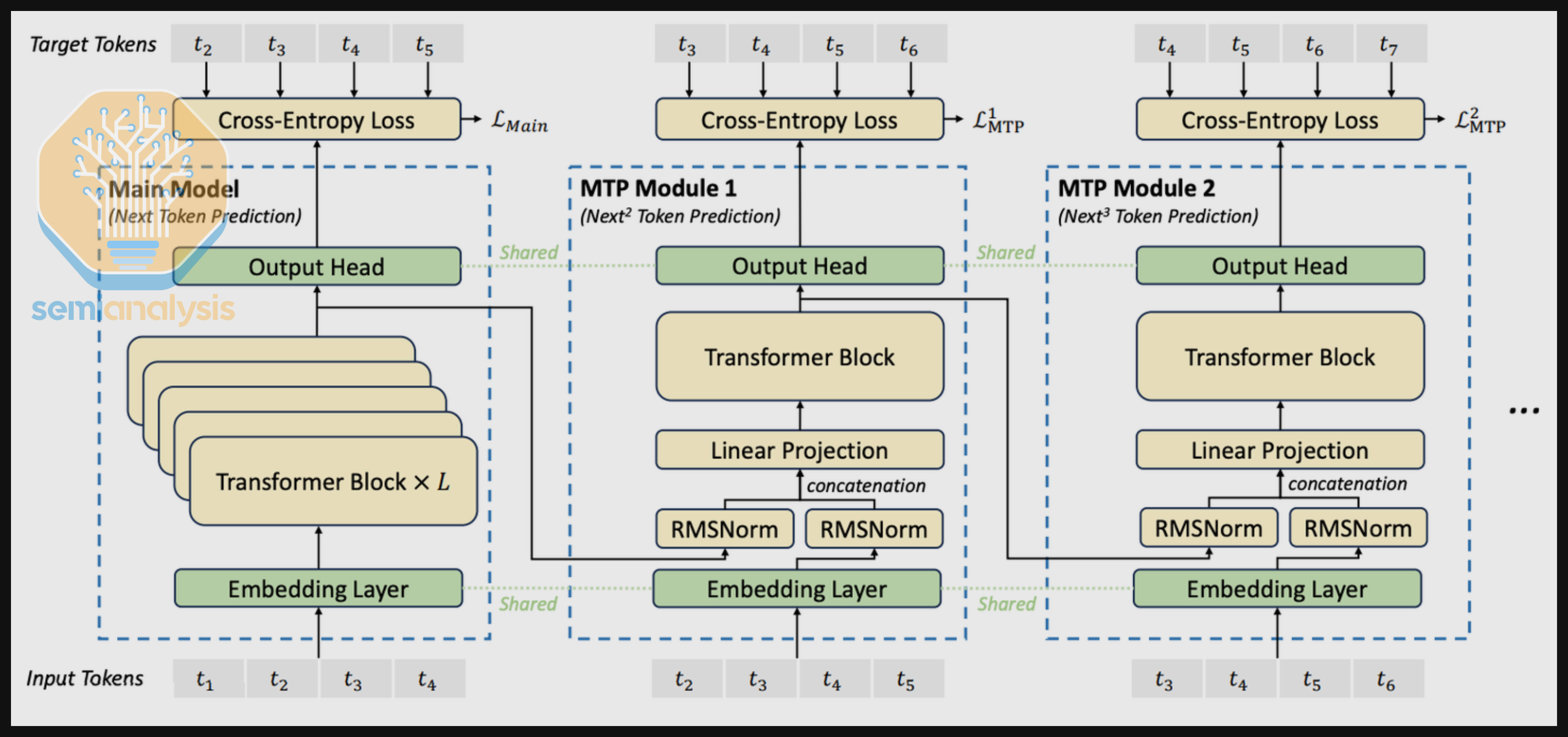
Nvidia 已为 GB200 NVL72 上的 DeepSeek R1 提交了包含分离式服务、wide EP 和 MTP 的运行结果。Nvidia 还提交了特定配置以绘制帕累托前沿,我们计划未来扩展以扫描更大的配置空间。
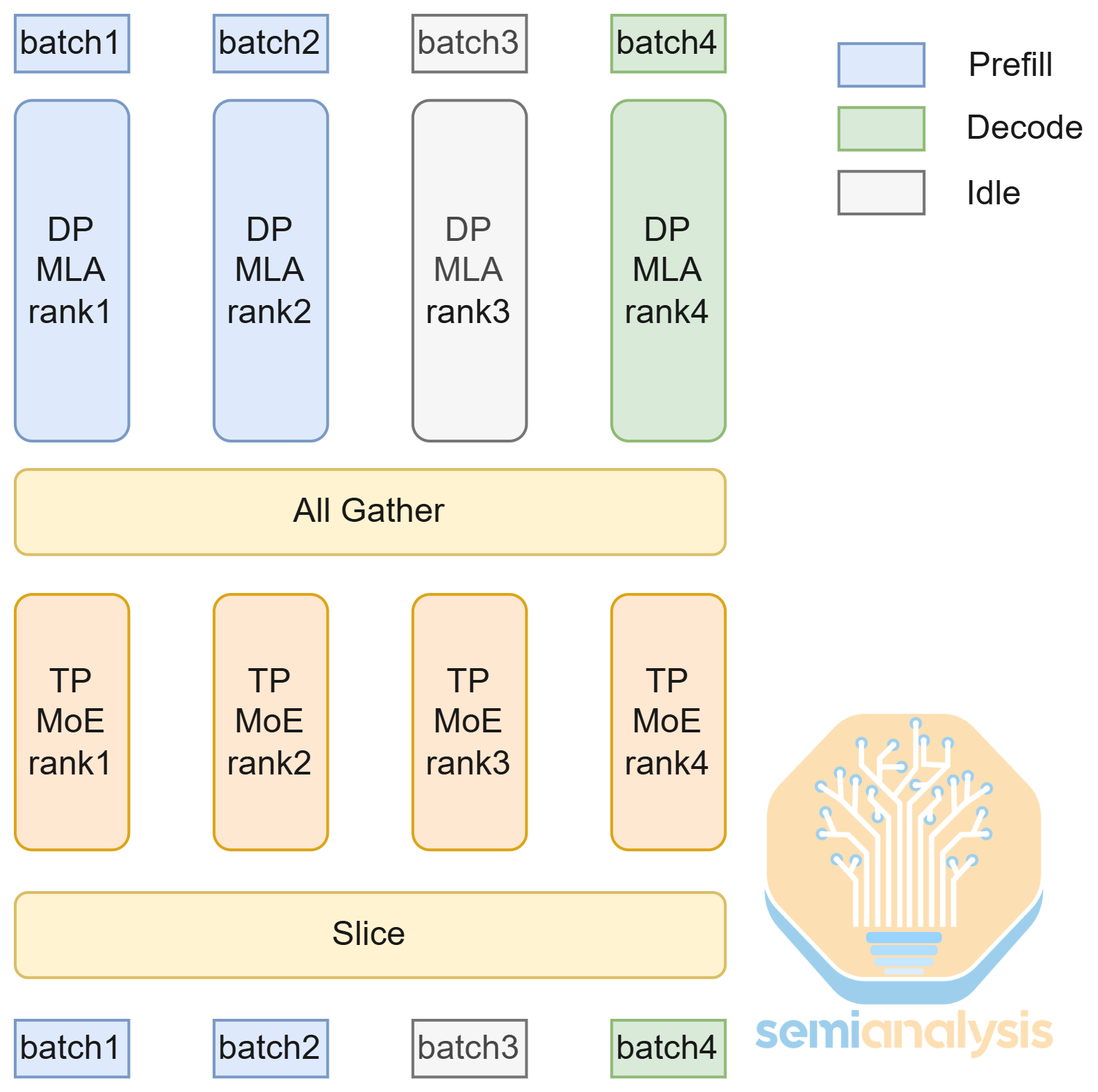
在服务 DeepSeek R1 时,SGLang 提供了多种并行策略,包括张量并行(TP)、数据并行(DP)和专家并行(EP)。并行策略在 GPU 之间分配工作,以降低每块 GPU 的内存使用并提高硬件利用率。
通常,我们使用张量并行沿注意力头数维度(通常为 128)分配注意力层的工作。然而,这不太适合 DeepSeek R1,因为它使用了多头潜在注意力(Multi-Latent Attention, MLA)——这是一种特殊的注意力机制,其中只有一个 KV 头,导致 KV 缓存重复。为了解决这个问题,SGLang 在低交互性场景下使用数据并行注意力,沿 batch 维度分配工作,消除了 KV 缓存重复的需要并减少了通信负载。
DeepSeek R1 还有大量的专家层,因此我们应用专家并行,为每块 GPU 分配一组专家层。这降低了内存使用,但代价是更高的通信负载。
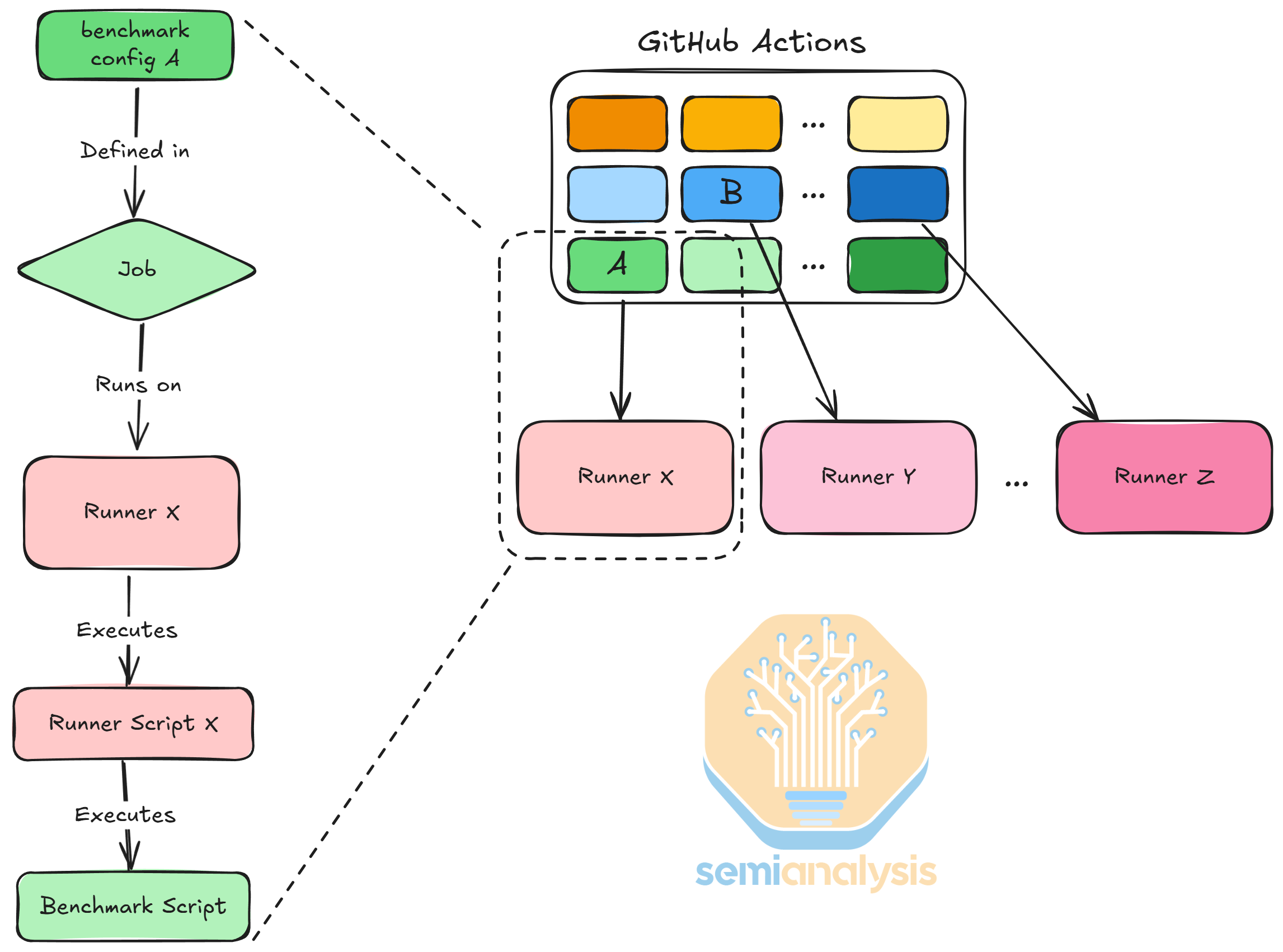
InferenceMAX 架构
InferenceMAX 使用 GitHub Actions 来编排基准测试运行。一个 GitHub Action 将每个基准测试配置作为一个 job 运行,并在 runner 上执行。我们将 GPU 服务器作为 runner 接入 GitHub Actions,使其监听请求并执行 job。在执行 job 时,runner 会执行为该服务器编写的 runner 启动脚本,该脚本反过来使用 Docker 或 SLURM,具体取决于服务器的设置。启动脚本随后执行包含具体基准测试配置的基准测试脚本。
我们将并行策略 + 最大并发数基准测试扫描的逻辑定义为参数化的 workflow,并通过增量组合 workflow 来执行所有 GPU 类型、所有模型和 GPU,以及不同的输入/输出序列长度。
性能结果——吞吐量 vs 端到端延迟/交互性(tok/s/user)
以下是撰写本文时 2025 年 10 月 7 日每夜运行的性能快照。完整的每夜结果请访问我们在 http://inferencemax.ai/ 上的仪表板。
在解读吞吐量 vs 延迟/交互性图表时,请记住大多数实际应用运行在两个极端之间的某个位置。仅测量单一或有限吞吐量或交互性水平的基准测试结果有时可能具有误导性。
例如,如果 GPU A 在给定交互性水平下——以面向人类的 AI 聊天机器人应用为例取 5 tokens/s/user——提供了 GPU B 4 倍的吞吐量,但这个交互性水平实际上太慢而不实用的事实意味着这种性能差异几乎没有真实的实际意义。相反——应该为给定应用选择一个现实的交互性水平。
在本报告的后续部分,我们还将按 GPU 的总拥有成本(TCO)对吞吐量进行归一化。
每百万 token 的 TCO 成本是客户真正关心的北极星指标——性能只是计算这一指标的中间步骤。例如,B200 可能提供比 MI355X 高 1.5 倍的吞吐量,但如果其每小时 TCO 成本是 MI355X 的 2 倍——那么 MI355X 将是更好的选择,因为即使 MI355X 在每 GPU 吞吐量的绝对性能上较低,它的 TCO 性价比更优。
让我们逐步分析几个基准测试示例来解释如何分析结果。
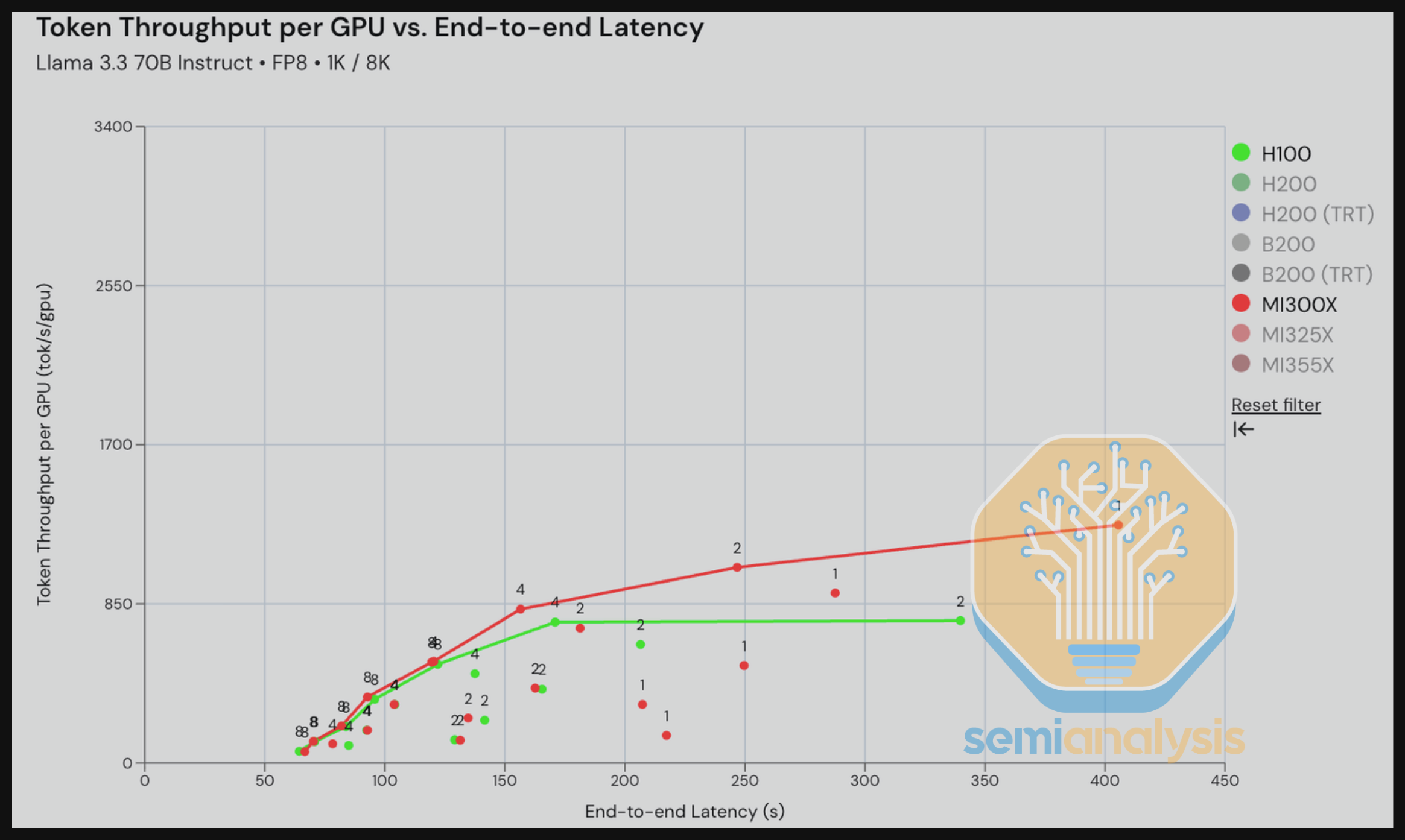
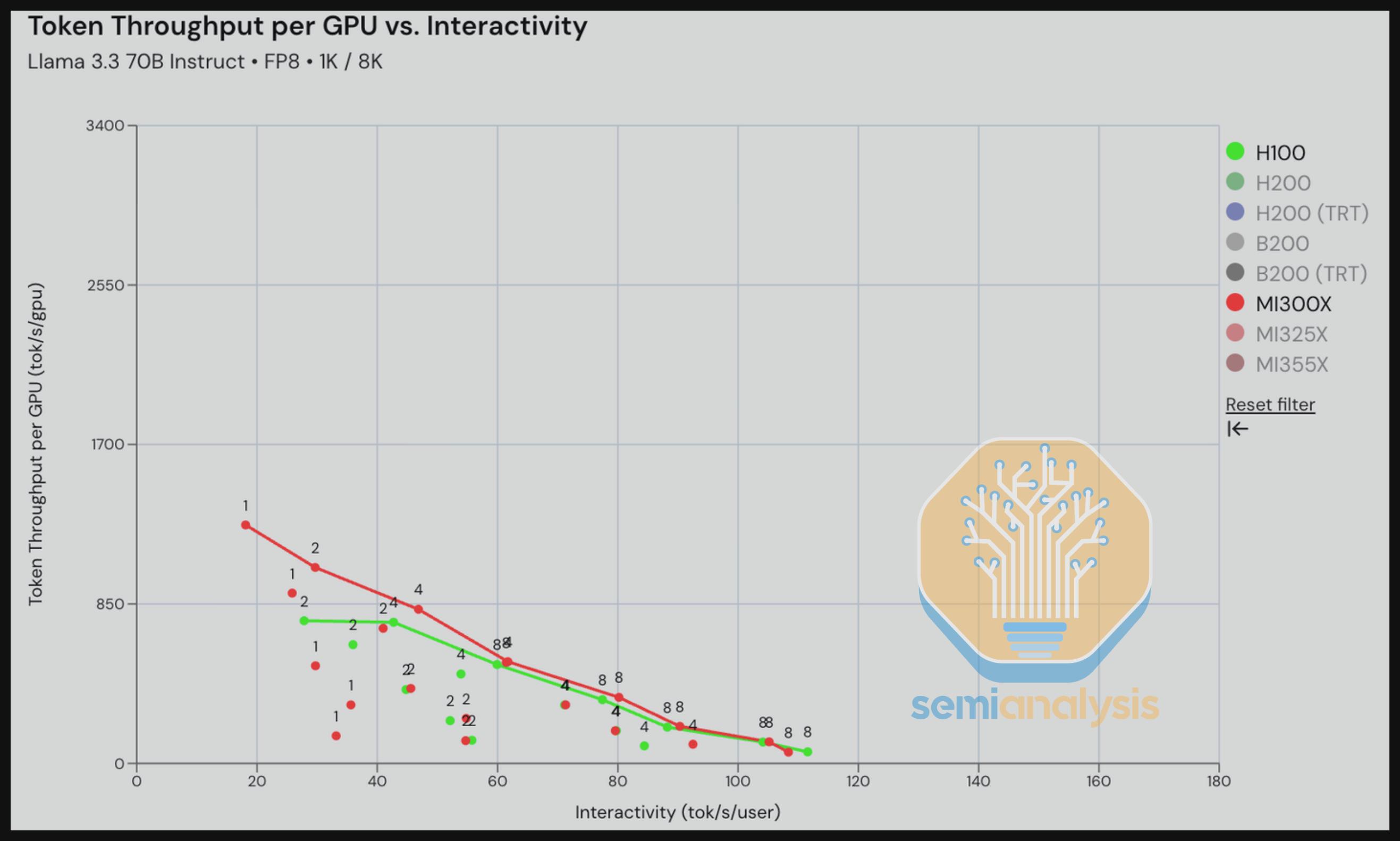
在我们的第一个结果中,H100 vLLM 与 MI300X ROCm 7.0 vLLM 在 Llama 3.3 70B FP8 推理场景(1k in/ 8k out)的对比显示了 MI300X 的强劲性能,尤其在低交互性水平(20 到 30 tok/s/user)下,这得益于 MI300X 在 TP1 运行时更好的内存带宽和内存容量优势。
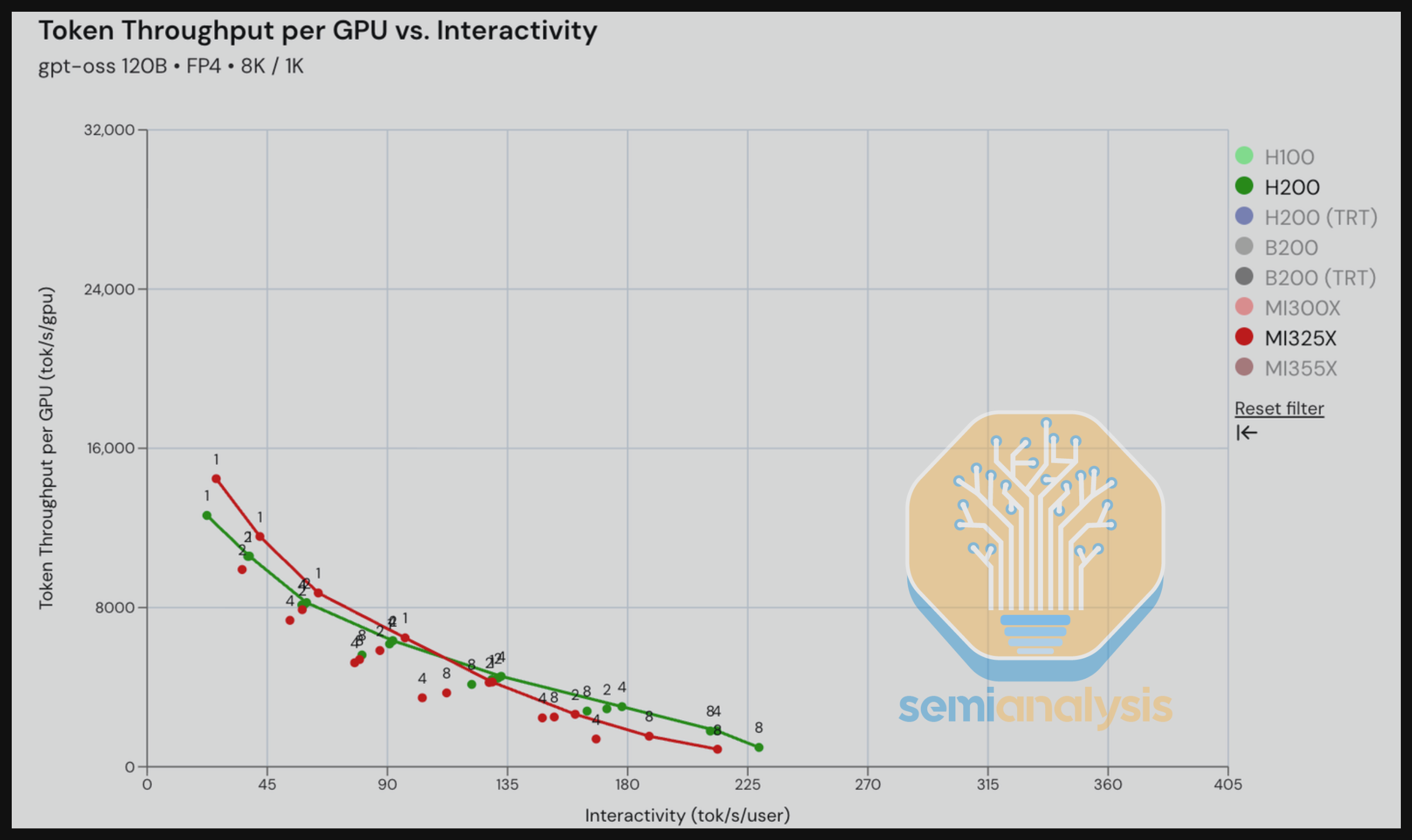
在 H200 与 MI325X 使用 vLLM 运行 GPT-OSS 120B MX4 weights 摘要工作负载的对比中,我们看到了有竞争力的结果。MI325X 在交互性低于 110 tok/s/user 时相对 H200 具有优势,在高于 110 tok/s/user 的水平下仍与 Nvidia 保持一定竞争力。
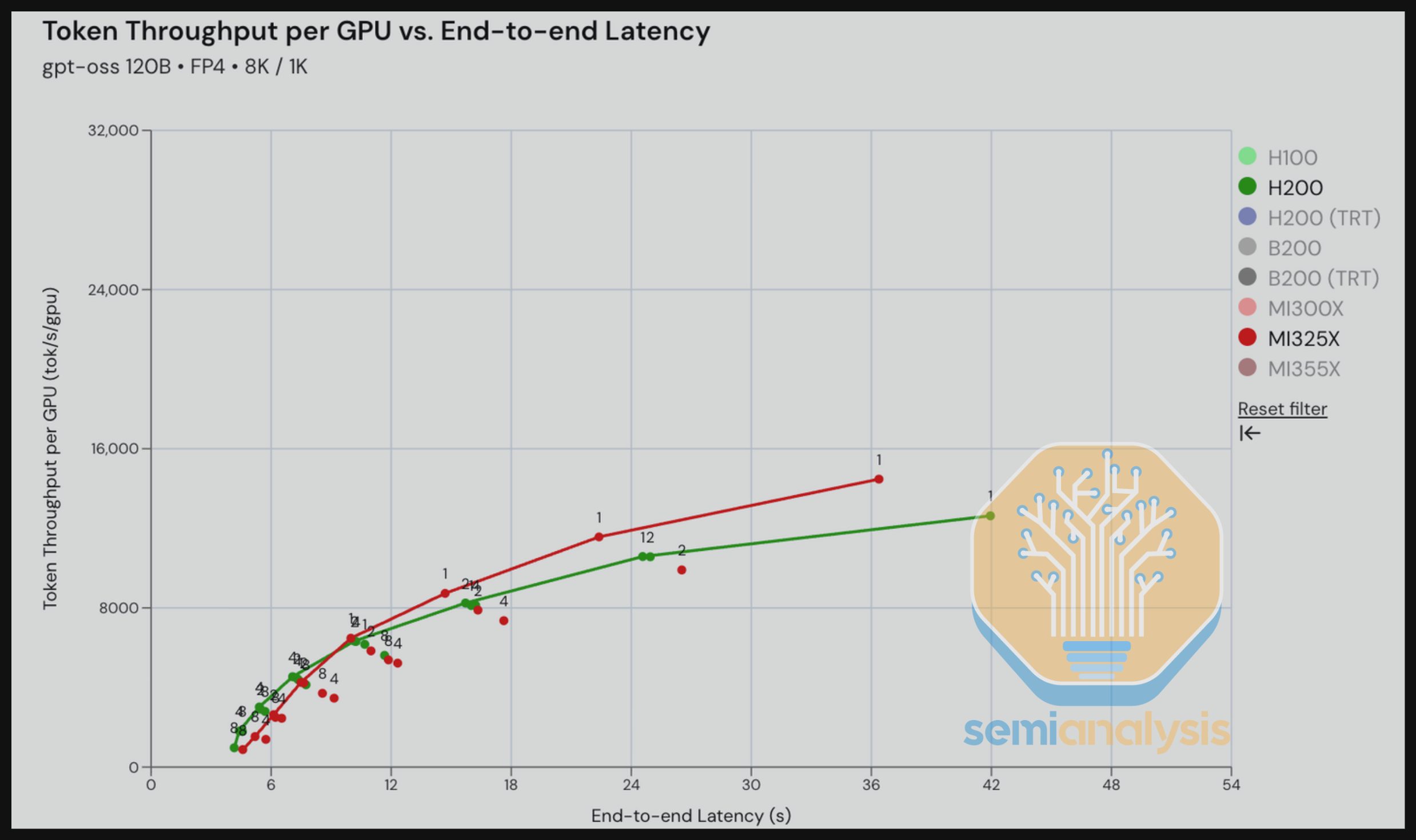
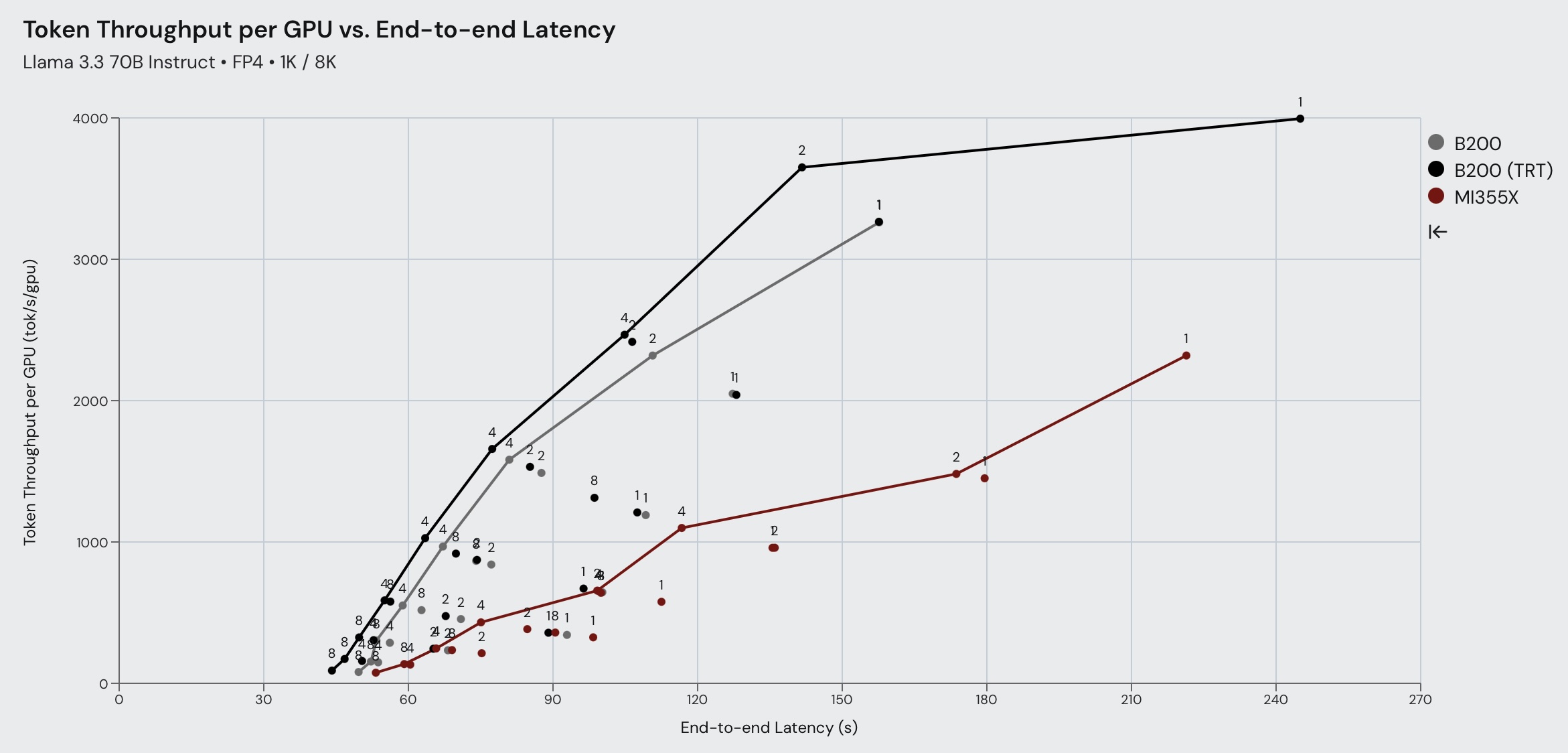
在 LLaMA 70B FP4 方面,B200 在所有三种工作负载类型上的吞吐量性能都大幅超越 MI355X。这表明 AMD 的 FP4 内核仍有改进空间。
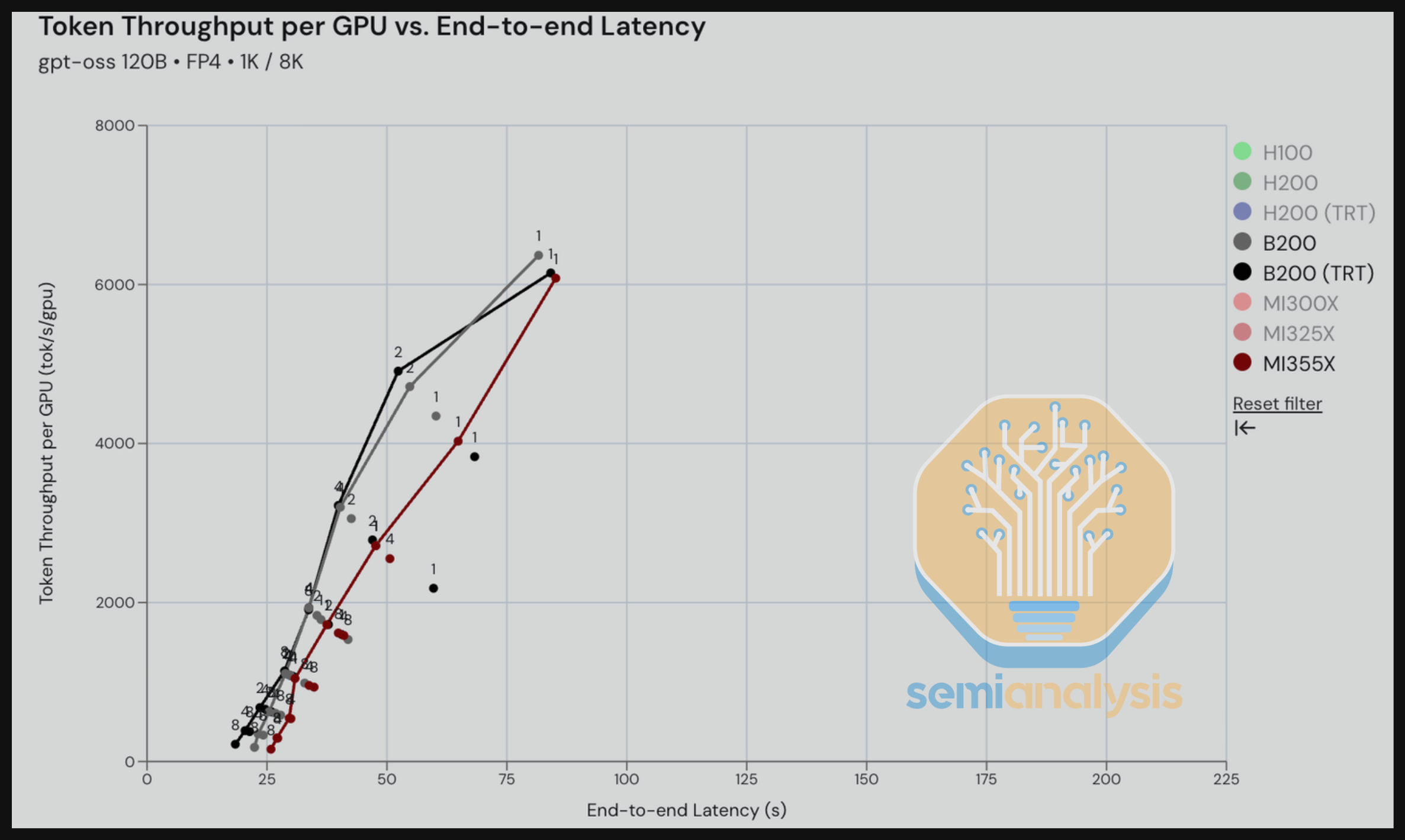
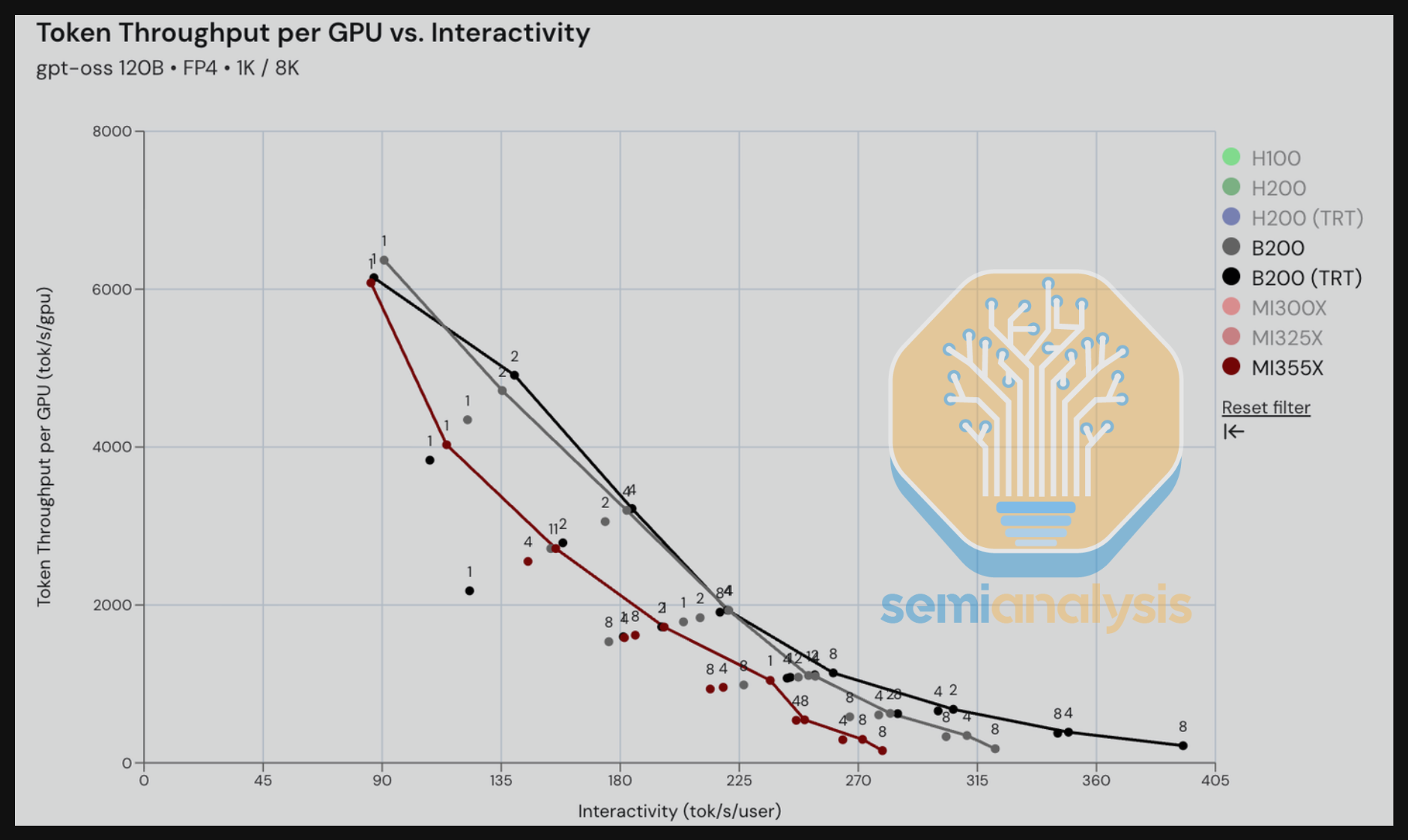
转到 B200(vLLM 和 TRT-LLM)vs. MI355X vLLM 运行 GPT-OSS 120B 的对比,我们可以看到 MI355X 在按 TCO 归一化后与 B200 vLLM 具有竞争力。在下一节中,我们将看到 MI355X 在某些交互性范围内的 TCO 性价比优于 Nvidia。吞吐量-延迟图表显示竞争更为激烈,MI355X 在给定 tok/s/gpu 吞吐量下比 B200 慢不超过约 15 秒。我们在现实中看到的 GPT-OSS 120B 最实用的交互性范围约为 150-200 tok/s/user。
转到 DeepSeek 670B MoE FP8,在 MI325X SGLang 与 H200 SGLang 的对比中,我们观察到 MI355X 在给定吞吐量水平下的延迟和交互性方面均明显落后。H200 SGLang 在相当的吞吐量下始终比 MI325X 的延迟低约 40%。此外,在比较两者的帕累托前沿交互性时,我们也看到了持续的差距。MI355X SGLang 与 B200 SGLang 的对比呈现出与 MI325X vs H200 类似的态势。AMD 在 SGLang 镜像方面似乎有很大的改进空间。
我们还可以看到,对于 GB200 NVL72 SGLang Dynamo FP8 机架级推理,目前尚未完全优化,仍有改进空间。
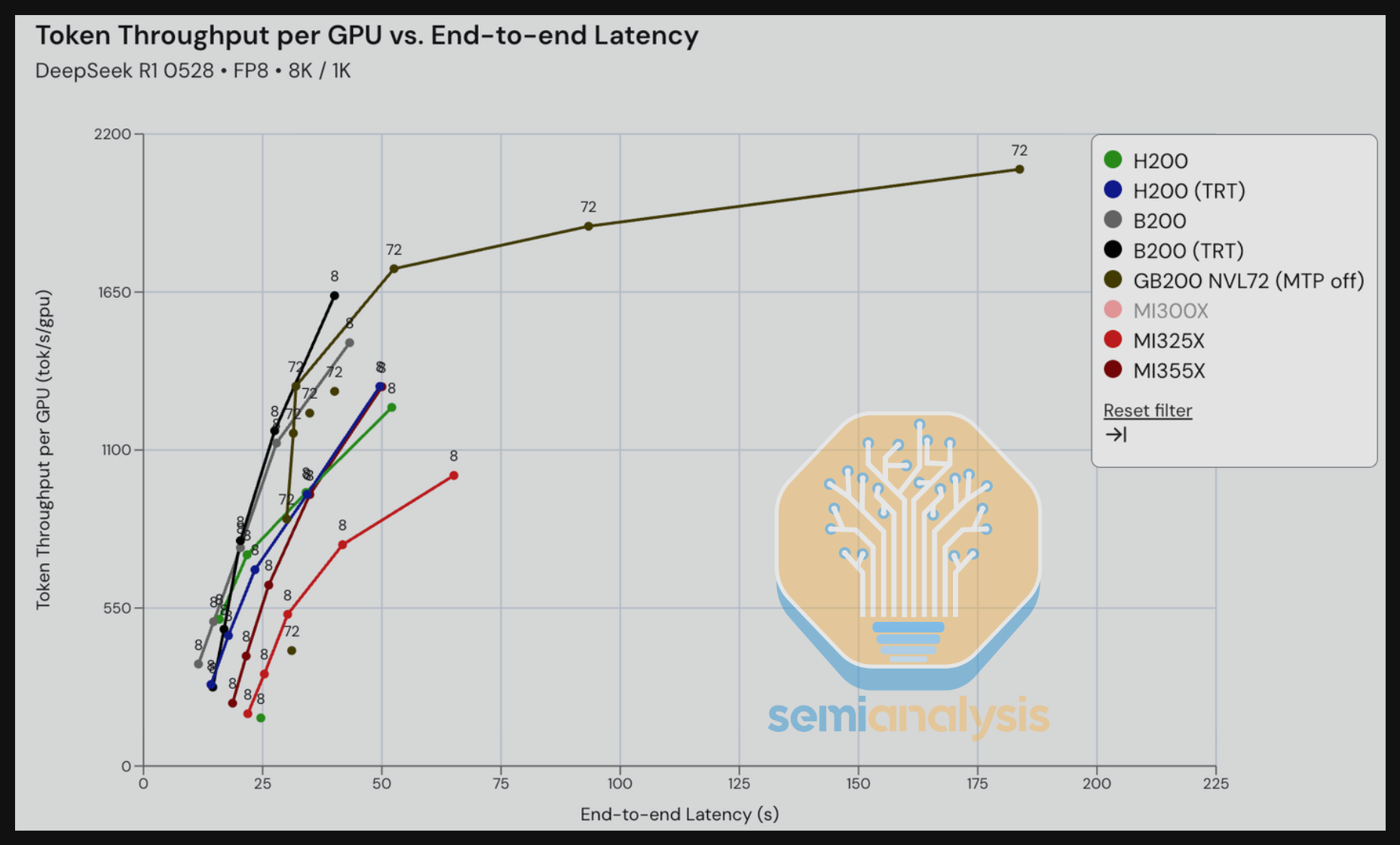
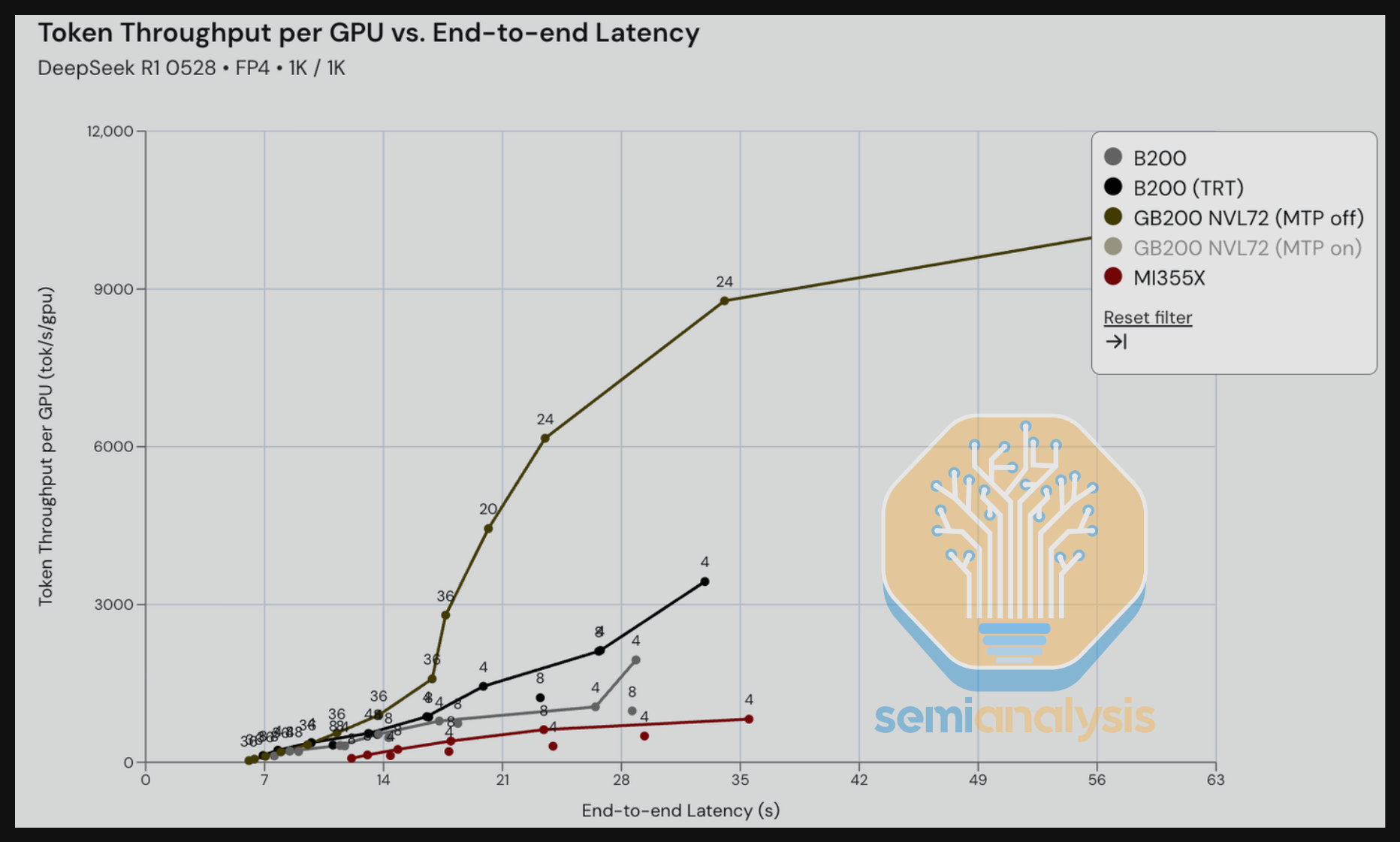
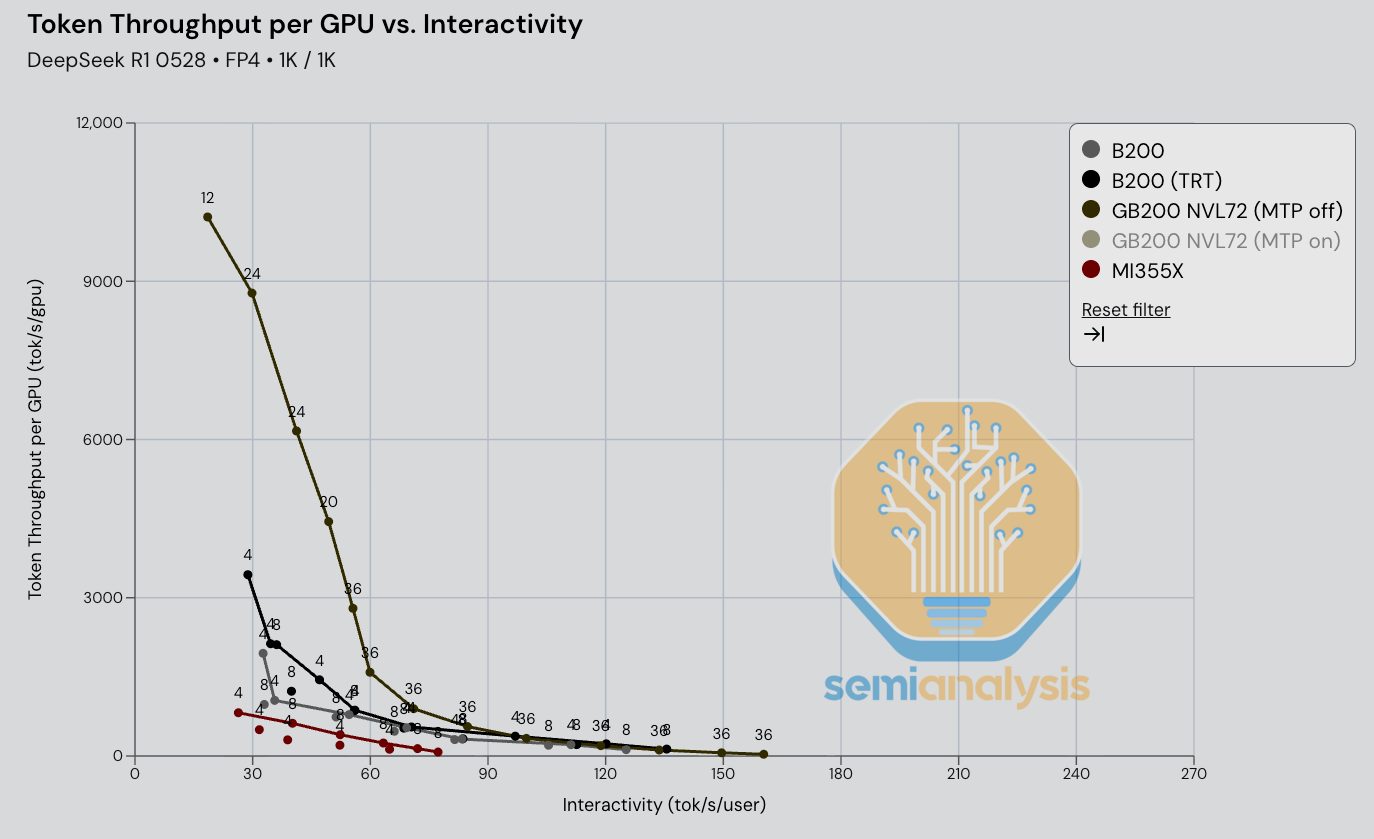
转到 FP4 DeepSeek 670B MoE,我们看到 GB200 NVL72 机架级 TRT-LLM 推理以大幅优势击败了单节点 SGLang 推理。我们期待在未来几个月内在多节点 8-GPU 机器上对 wideEP + 分离式预填充进行基准测试。
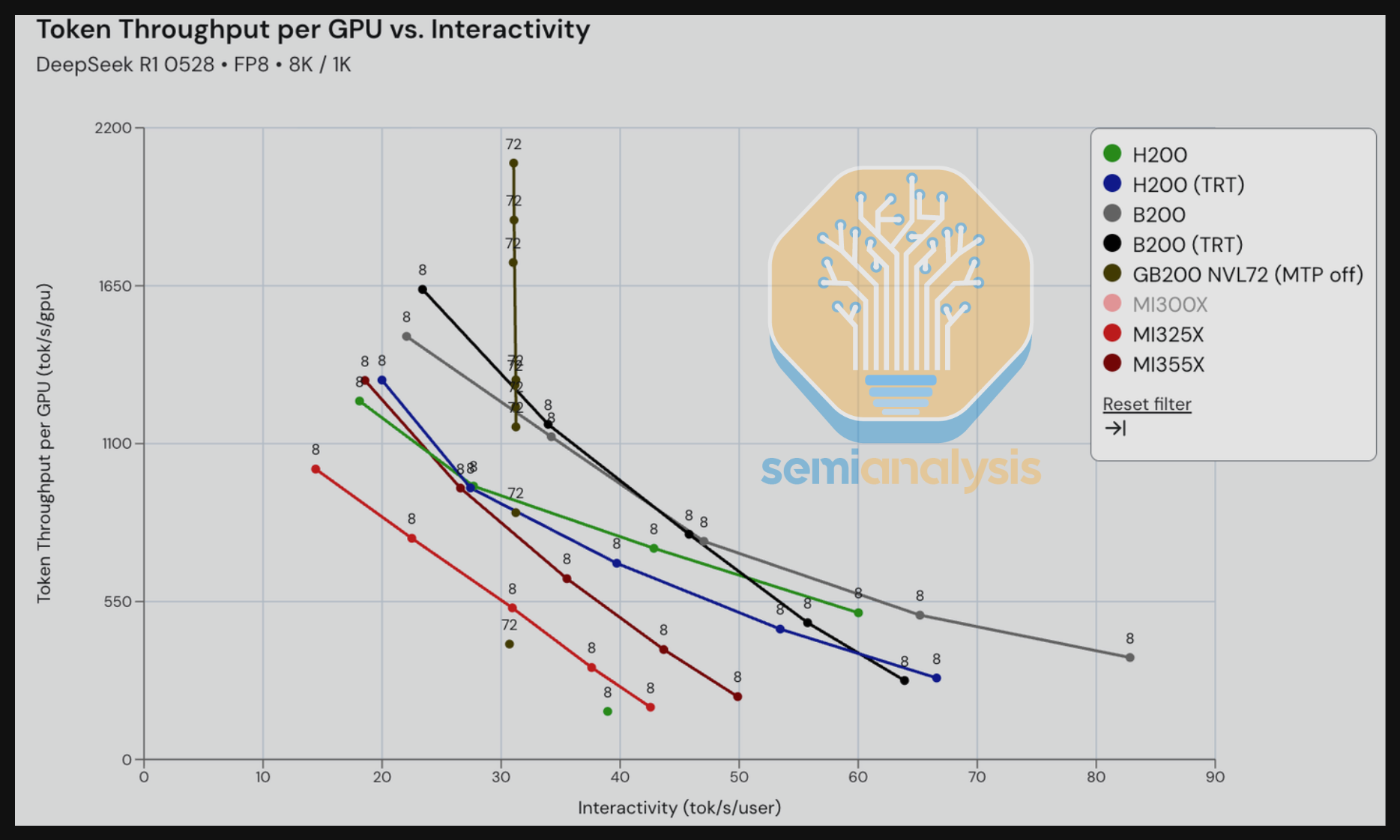
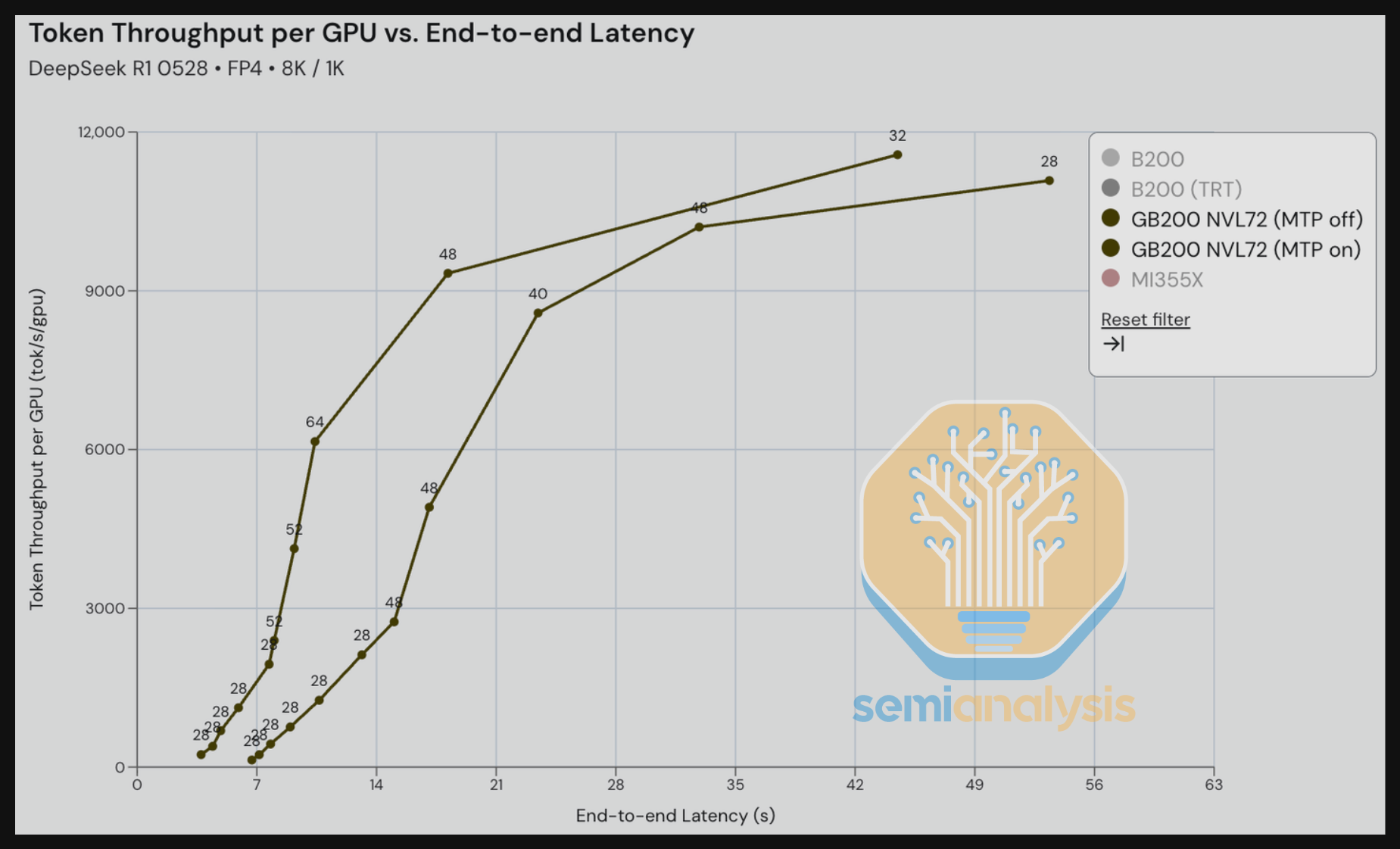
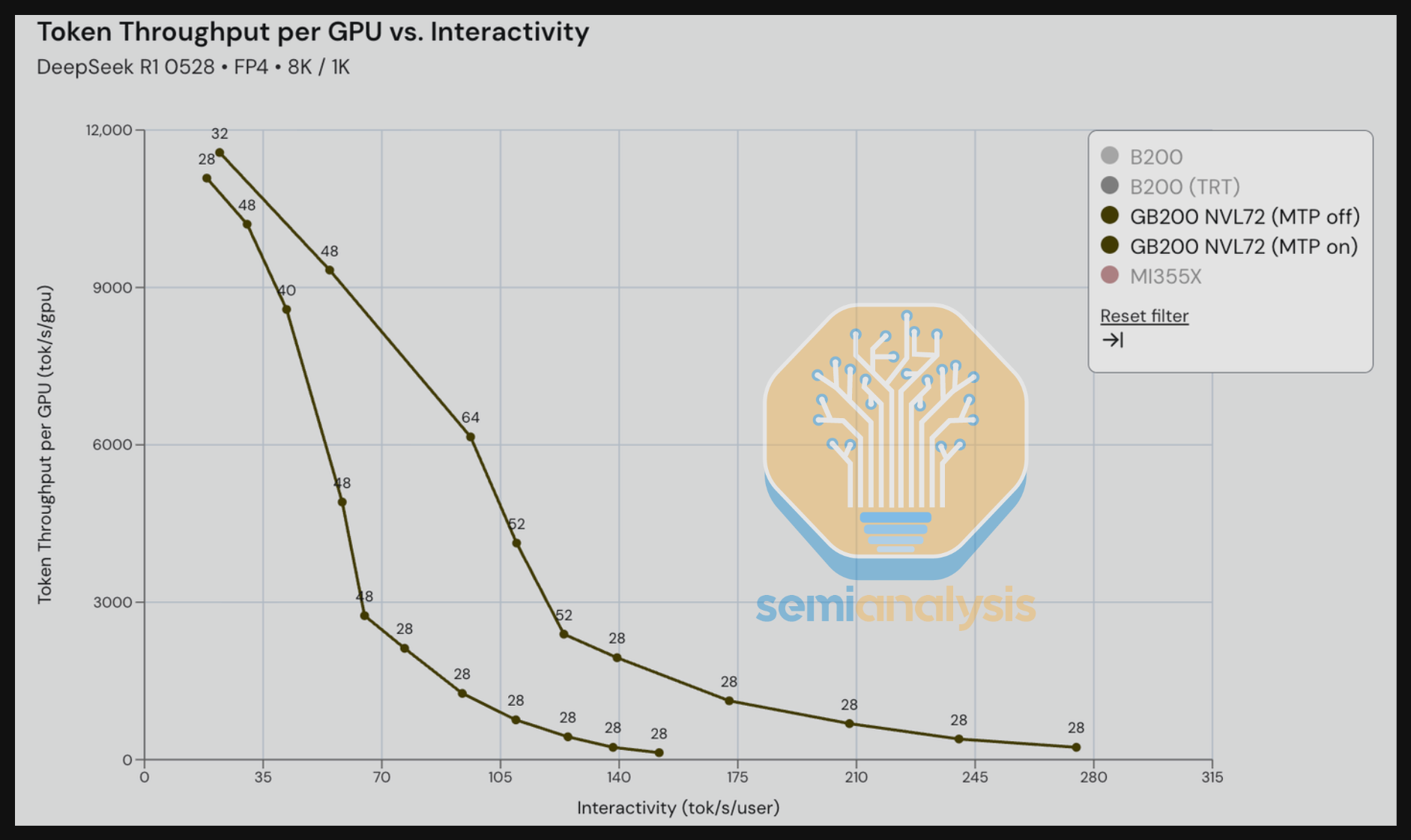
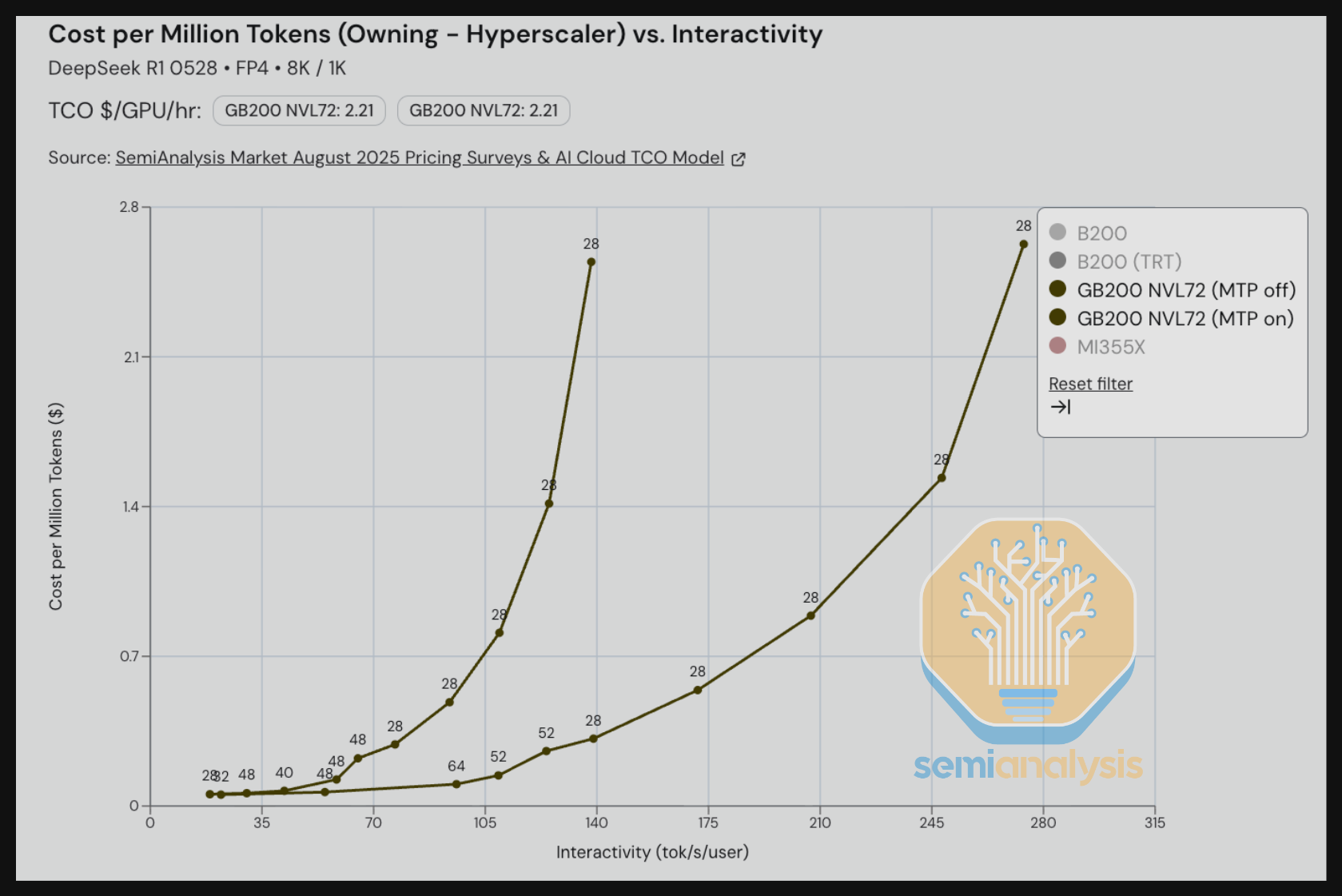
接下来,我们比较 GB200 在 DeepSeek R1 上开启和关闭多 token 预测(MTP)的表现,场景为 8K 输入 / 1K 输出——这一输入/输出比例旨在反映摘要用例。MTP 开启的优势在比较吞吐量 vs. 交互性时尤为明显。在 70-140 tok/s/user 的范围内,我们看到 MTP 开启场景相比 MTP 关闭场景每 GPU 的吞吐量显著更高——在某些等交互性(tok/s/user)水平下甚至达到 2-3 倍的吞吐量。
性能结果——每百万 Token TCO 成本 vs 交互性(tok/s/user)
然而,比较每 GPU 的 token 吞吐量只是得出真正底线——即每 token 总拥有成本(TCO)——所需的几个数据点之一。
ML 推理工程师通常以每百万 token TCO 成本为单位来衡量这一指标。要从每 GPU 吞吐量转换为每百万 token 的 TCO 成本,在比较芯片之间的差异时,我们必须按以 USD/hr/GPU 为单位的总拥有成本进行归一化。例如,如果 B200 提供了比 MI355X 高 1.5 倍的吞吐量但每小时 TCO 成本是其 2 倍——那么 MI355X 将是更好的选择,即使它的绝对性能较低。
在我们位于 http://inferencemax.ai/ 的 InferenceMAX 门户上,我们估算了各种客户群体的每百万 token TCO 成本 vs 延迟/交互性,包括:
- 购买并拥有芯片的超大规模厂商和一级前沿实验室(4 年经济使用寿命)
- 计划拥有自有芯片的新型云巨头和大型托管推理服务提供商(4 年经济使用寿命)
- 从新型云厂商租用 GPU,签订 3 年合同,预付 25%
建模每 Token 总拥有成本绝非易事,涉及 SemiAnalysis 多个团队和业务领域。在 AI Token 工厂经济模型中,我们展示了用于推导这一北极星指标的所有假设,以及用于确定这些数值的 SemiAnalysis 模型。
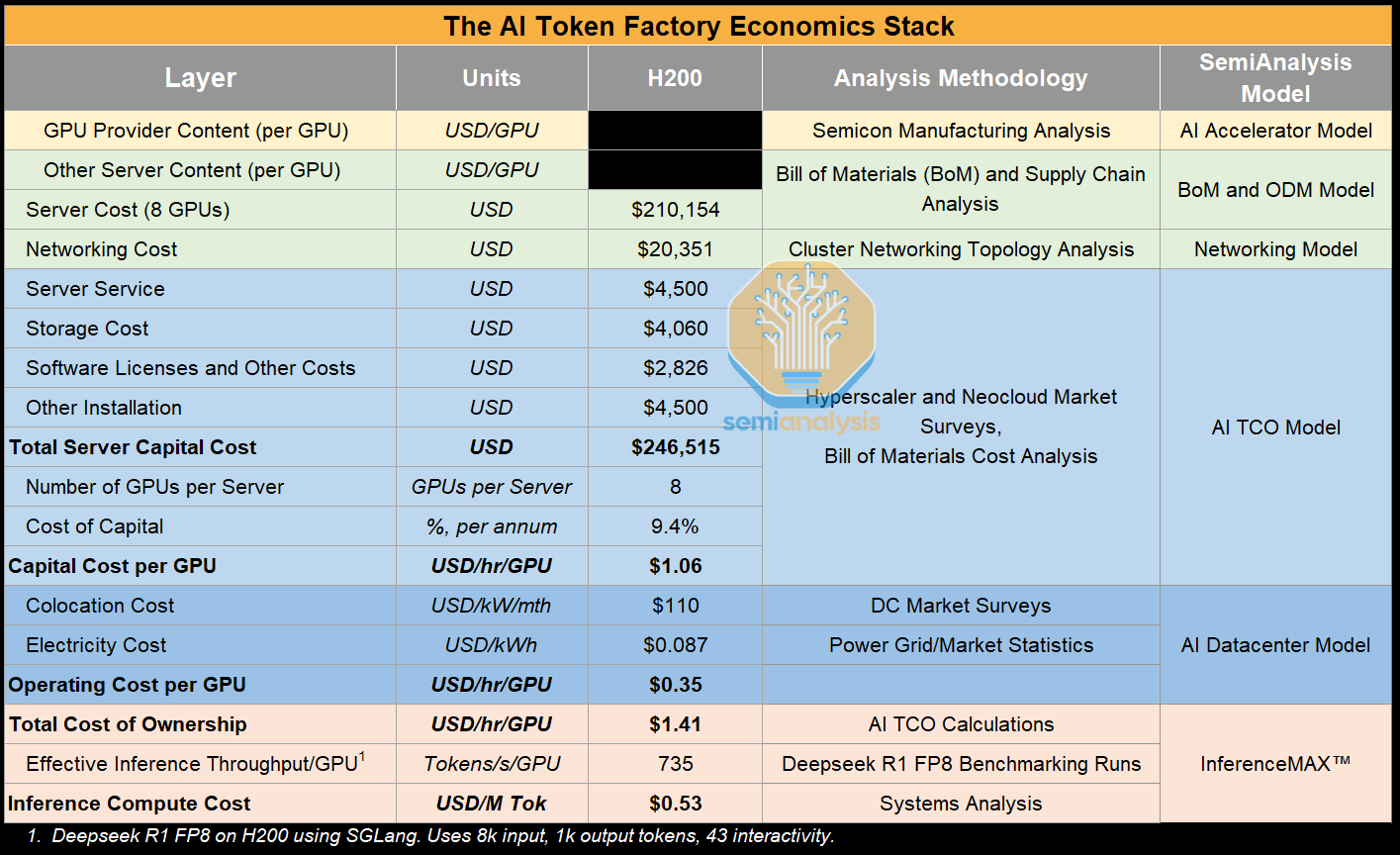
特别是,SemiAnalysis AI TCO 模型 提供了针对各种 AI 服务器方案和网络架构组合(即 InfiniBand vs SpectrumX vs Arista 以太网 vs 白盒以太网)的全面总拥有成本建模,是 InferenceMAX 中使用的每 GPU 总拥有成本以及新型云市场租赁价格的主要来源。
SemiAnalysis GPU 云市场租赁价格报告基于对 70 多家 GPU 云和 100 多个从 GPU 云租赁的终端用户的调研。未来,我们将探索在 InferenceMAX.ai 门户上实现不同租赁定价合同期限(如 1 年或 1 个月)的仪表板。我们还计划允许自定义输入,以便你可以输入自己的 $/GPU/hr 报价,来确定最符合你的交互性目标和成本的 GPU。
在以下分析中,我们聚焦于拥有芯片并将其商业模型基于 4 年经济使用寿命的超大规模运营商级别的每百万 token 成本。
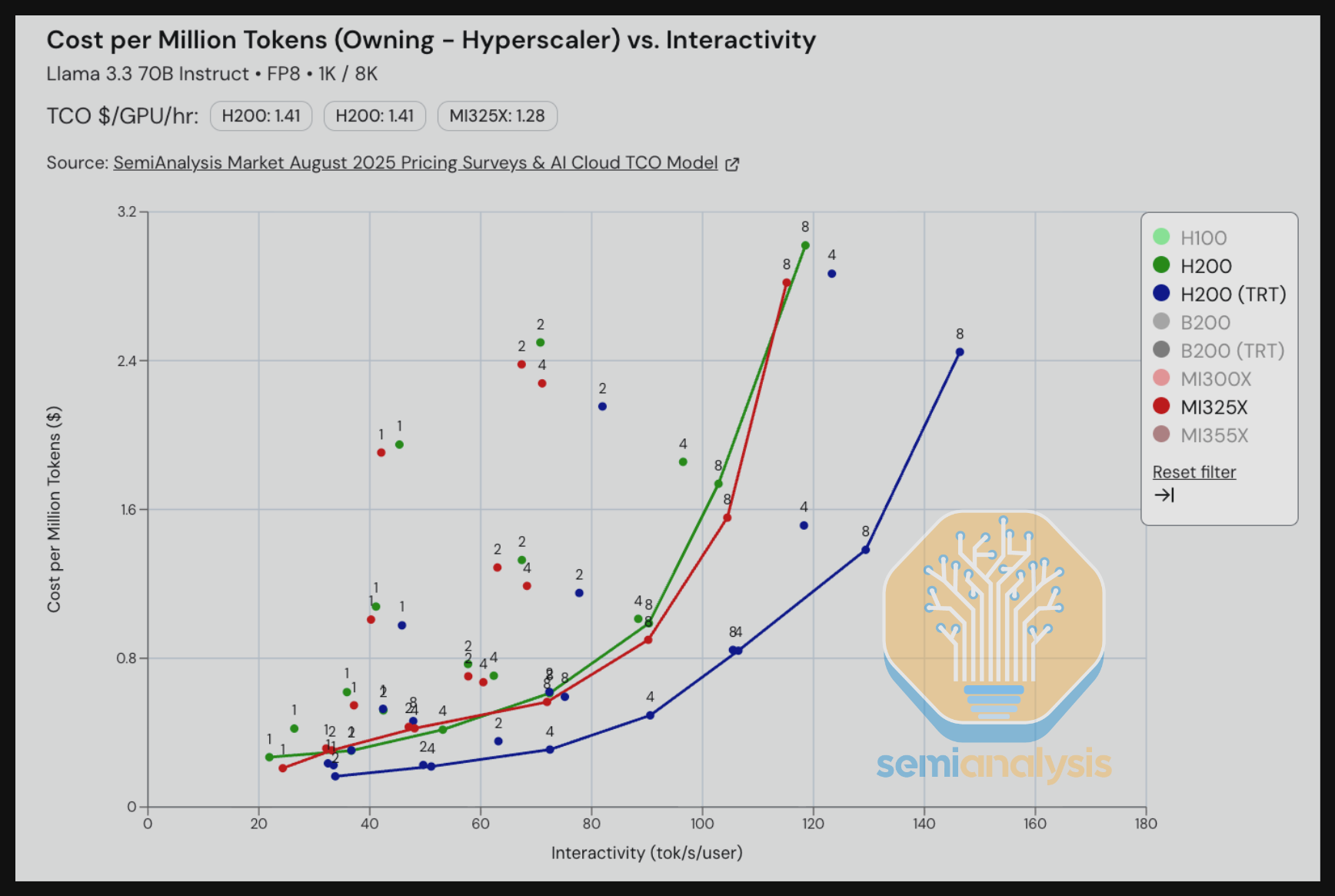
我们看到,在所有交互性水平下,MI325X vLLM 的每百万 token 成本都优于 H200 vLLM。当我们引入 Nvidia(大部分)开源的 TRT-LLM 时,我们看到 H200 当前的软件栈在与使用今天 vLLM 栈的 MI325X 的对比中胜出。
当我们在推理输入/输出长度场景下比较 B200 vLLM 与 MI355 ROCm 7.0 vLLM 运行 Llama3 70B FP4 时,B200 目前表现优于 MI355。这也印证了我们的建议——AMD 应更加专注于优化 FP4 对 Llama3 的支持。
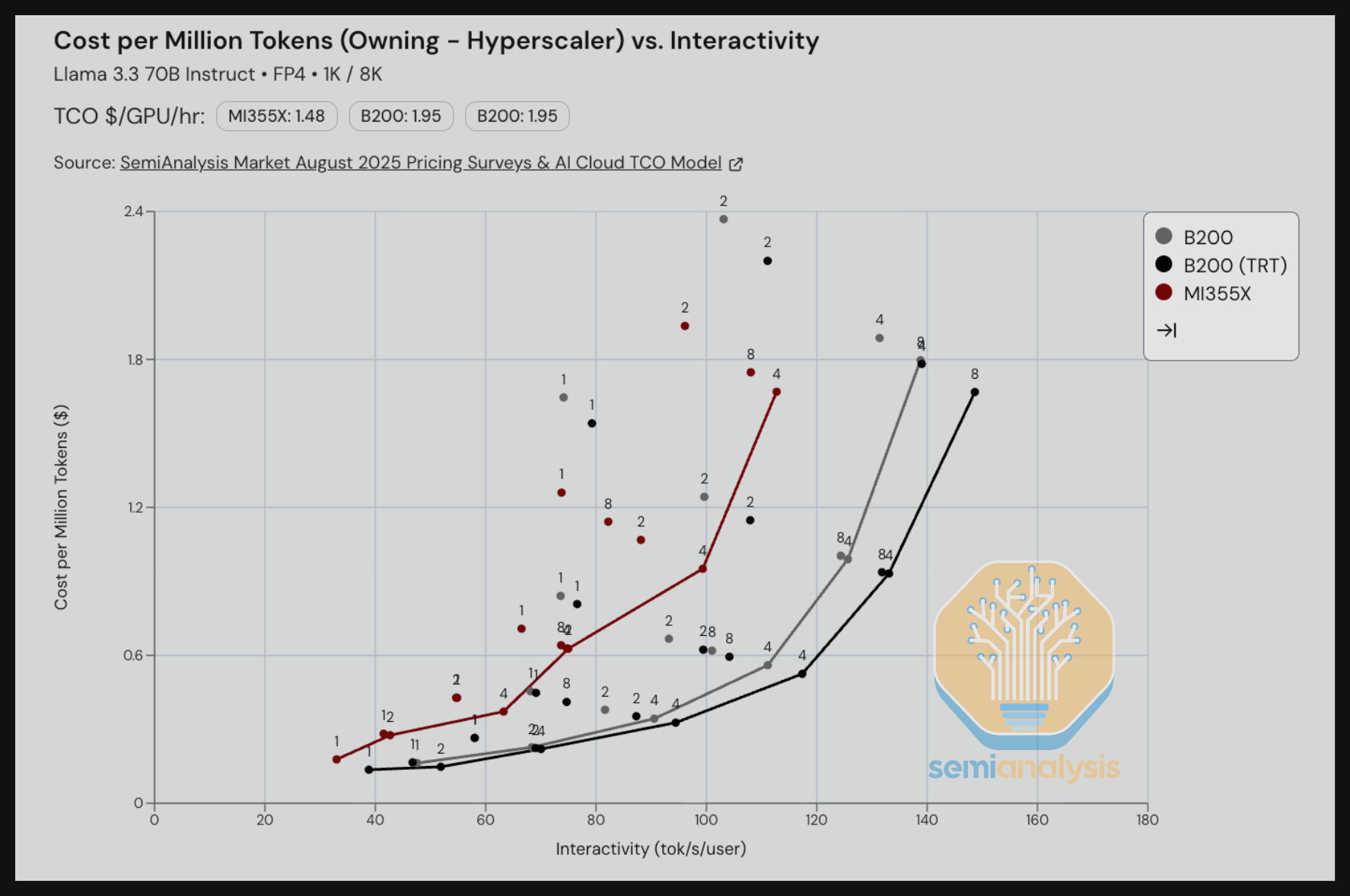
对于 GPT-OSS 120B FP4 摘要任务,我们看到 MI355X vLLM 的每百万 token TCO 成本低于 B200 vLLM,甚至在交互性低于 225 tok/s/user 时可以击败 B200 TRT-LLM。对于高于 225 tok/s/user 的交互性水平,我们看到 B200 TRT-LLM 以及其他推理引擎的优化更到位,能够提供比 MI355X vLLM 更低的 TCO 性价比。
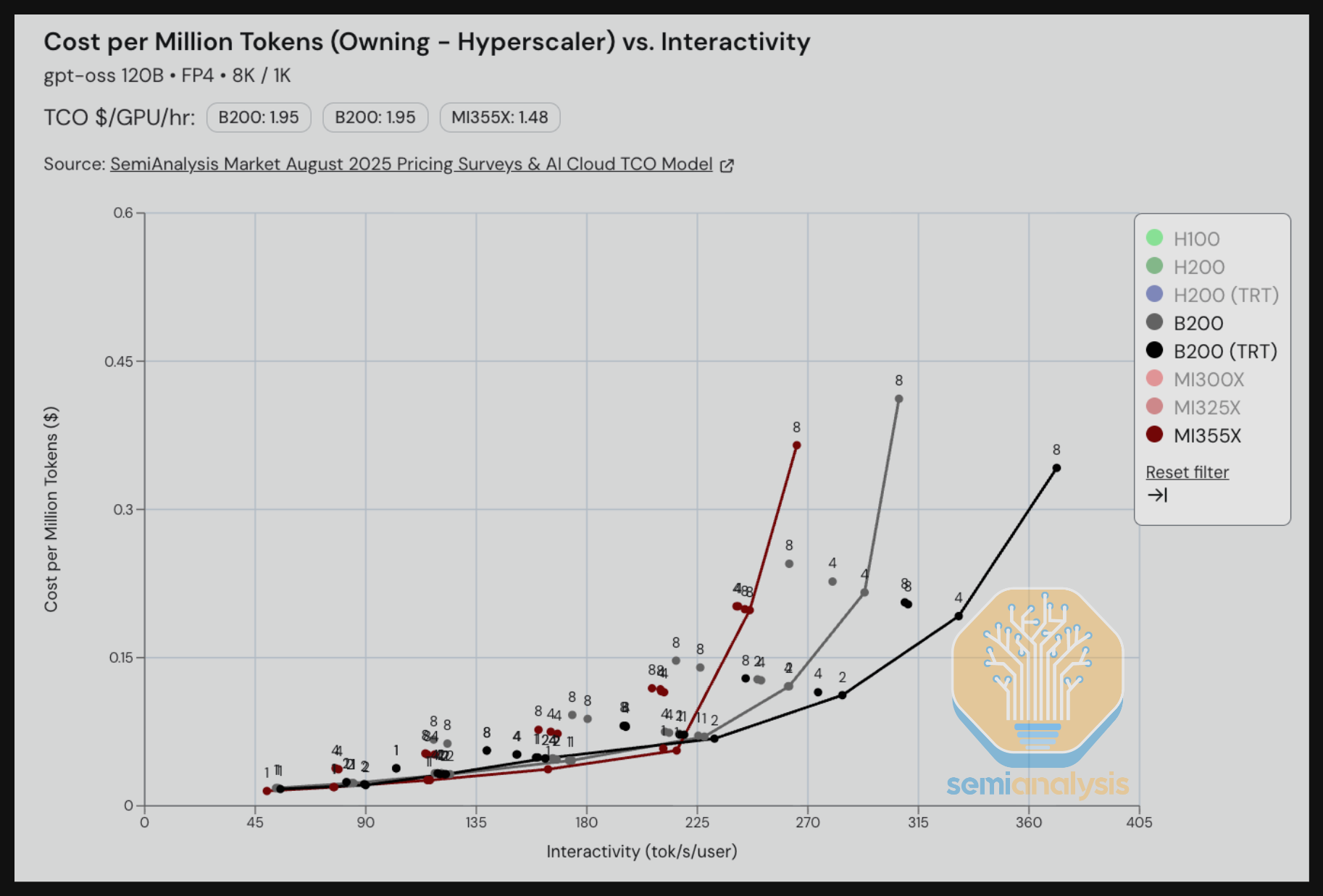
在 GPT-OSS 120B MX4 weights 上,我们看到 MI300X 在整个交互性范围内相对 H100 展现了非常强劲的 TCO 性价比。
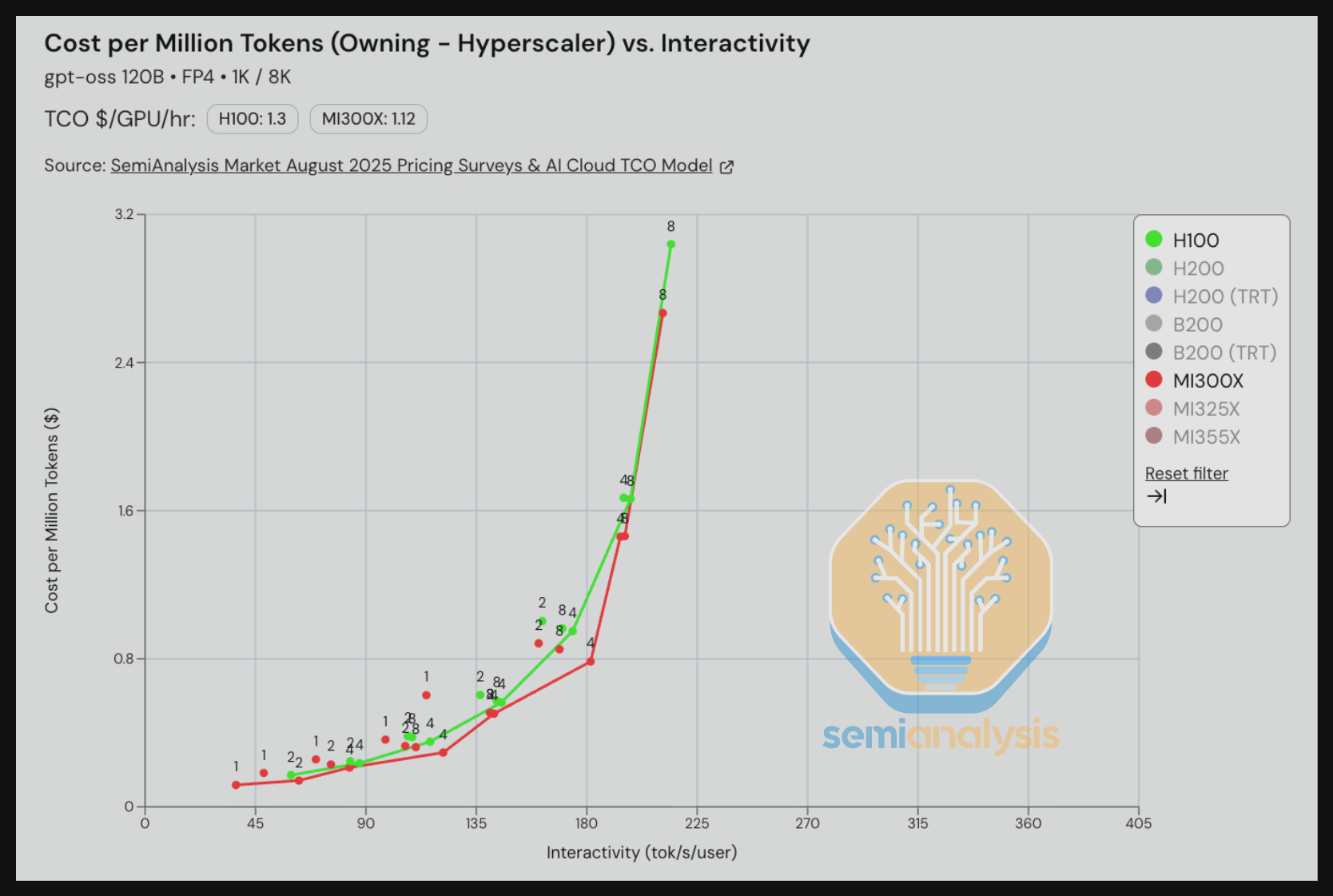
对于 gpt-oss 120B MX4 weights,H200 TRT-LLM 在交互性低于 135 tok/s/user 时与 MI325X 的 TCO 性价比不相上下。在此水平之上,MI325X vLLM 在每百万 token TCO 成本方面领先于 H200 TRT-LLM。
这一结果令人惊讶的是,完全开源的 vLLM Hopper 版本比"大部分"开源的 TRT-LLM Hopper 版本更快。即使是 MI325X vLLM 也在交互性高于 135 tok/s/user 时击败了 H200 TRT-LLM。
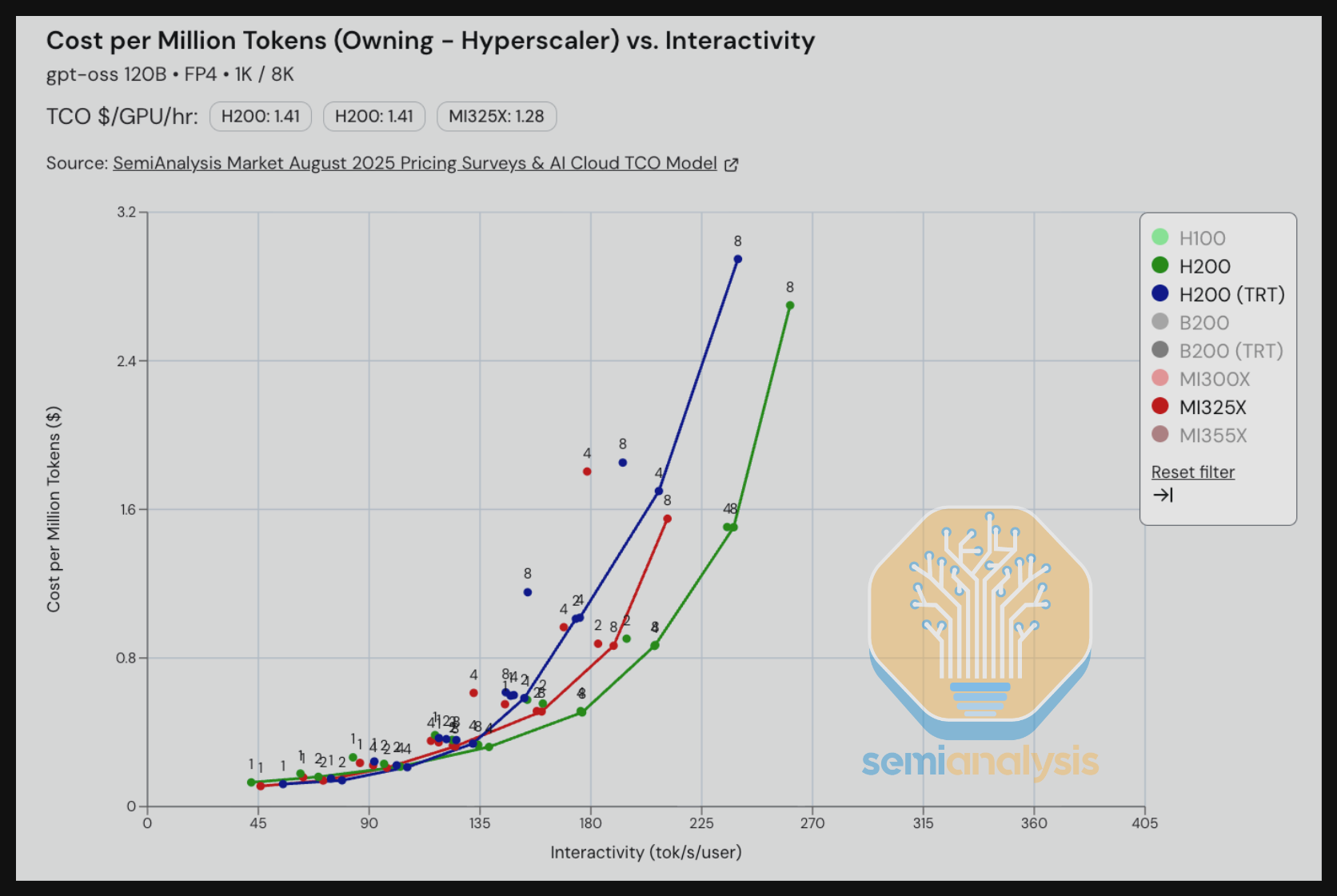
转到 DeepSeek 670B MoE FP8,我们看到在保持每百万 token TCO 成本不变的情况下,B200 SGLang 提供的交互性比 MI355X SGLang 快 1.5 倍。我们注意到 ROCm AITER 中仍有大量优化正在集成到 SGLang 中,因此我们预计 SGLang DeepSeek 670B MoE 的 TCO 性价比将很快得到改善。
在交互性保持在约 35 tok/s/user 时,GB200 NVL72 击败了所有其他方案,提供了 4 倍更优的每百万 token TCO 成本。我们注意到 Dynamo 团队目前只有时间实现足以将并行成本帕累托前沿降低到 30 tok/s/user 区域的优化。他们仍有空间进一步优化,以将 GB200 NVL72 FP8 在约 40 及以上交互性水平的成本帕累托前沿进一步推低。
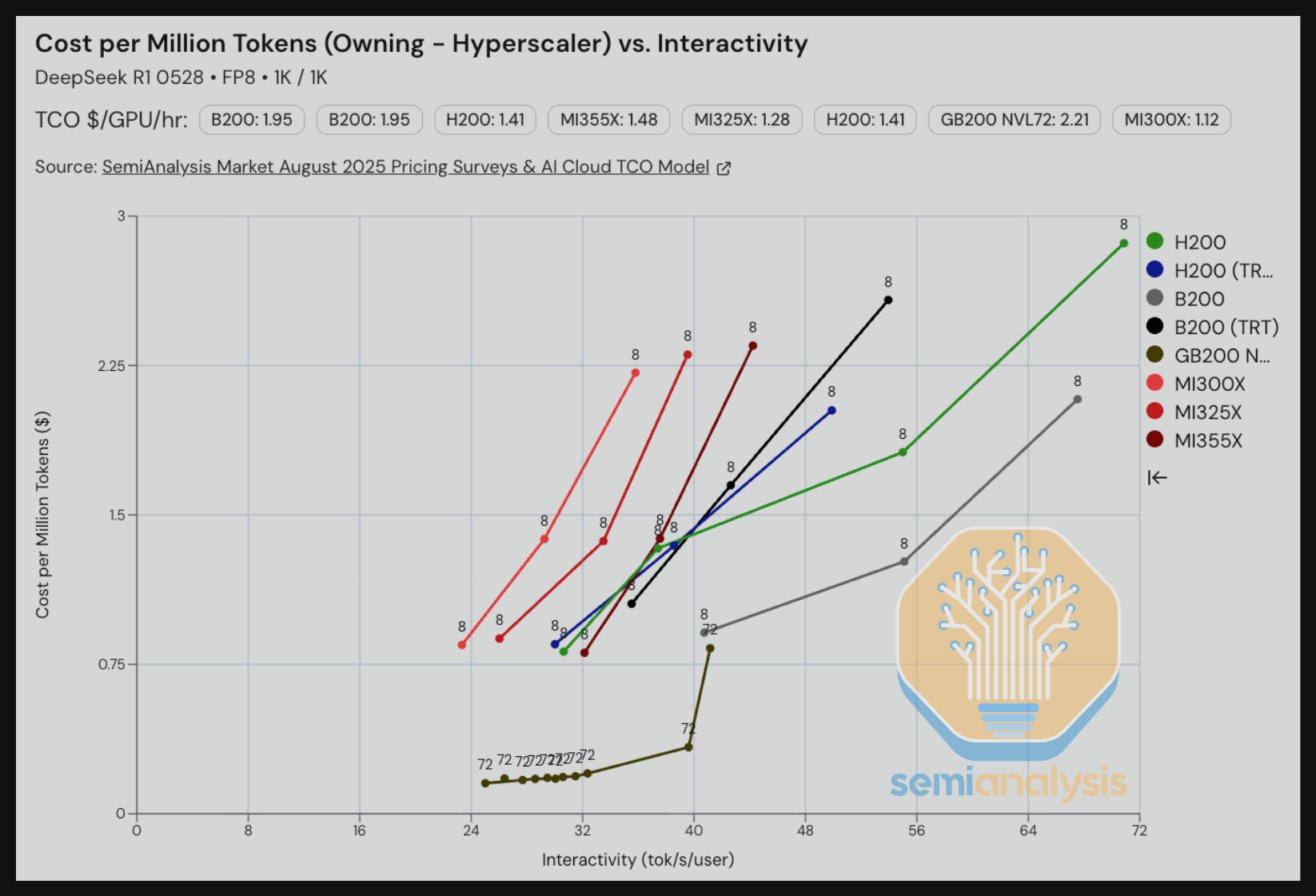
转到 DeepSeek R1 FP4 摘要用例,我们看到在低于 90 tok/s/user 的交互性水平下,GB200 NVL72 使用 TRT-LLM 引擎配合 Dynamo 分离式预填充,在每百万 token TCO 成本上决定性地超越了所有单节点 8-GPU 服务器。有趣的是,在交互性高于 90 tok/s/user 时,B200 TRT-LLM 击败了 GB200 NVL72。然而,就目前而言,单节点 B200 服务器在高交互性用例中可以实现比 GB200 NVL72 更好的 TCO 性价比。
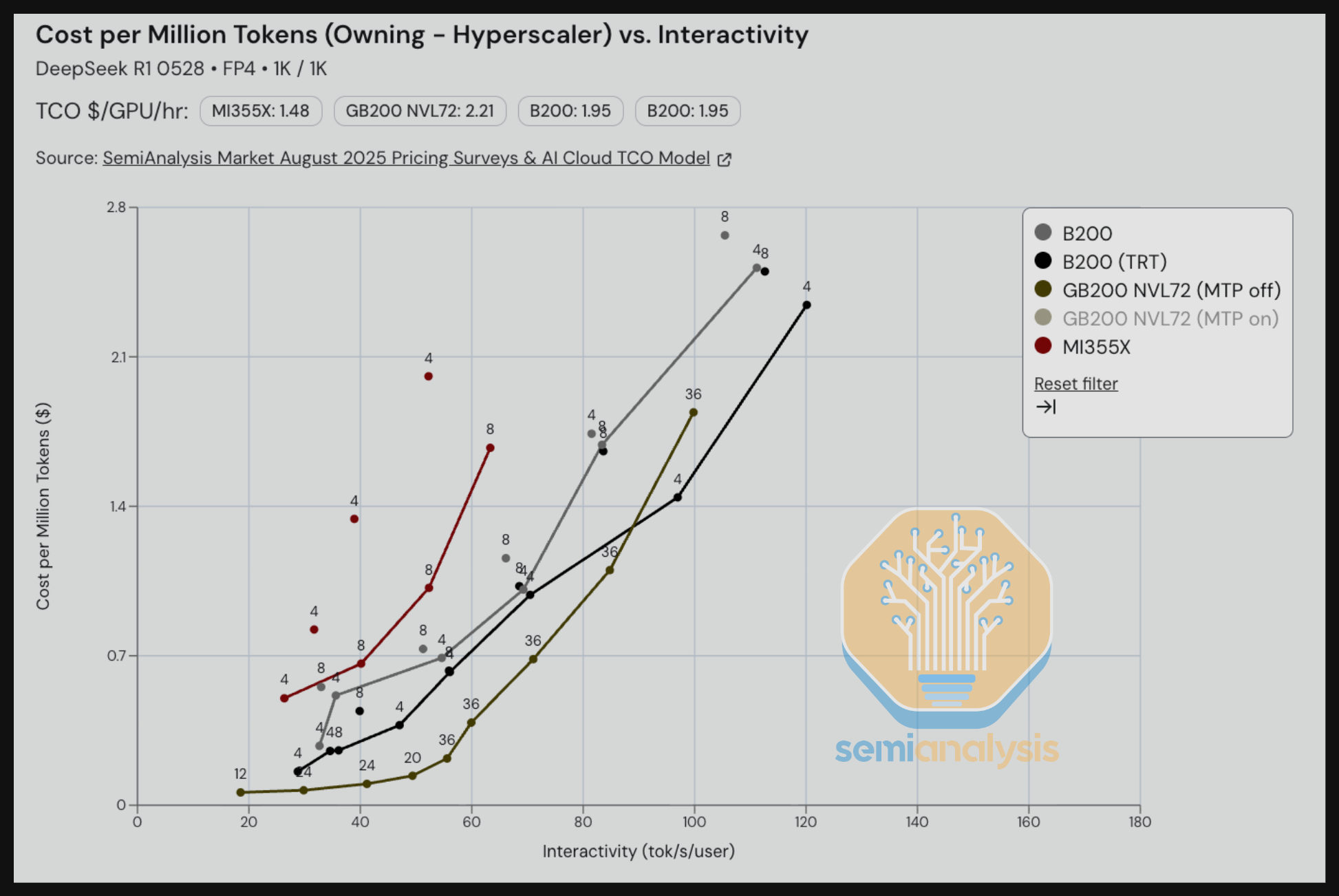
在下面针对推理用例的基准测试中,我们看到 B200 SGLang 目前表现优于 MI355X SGLang。
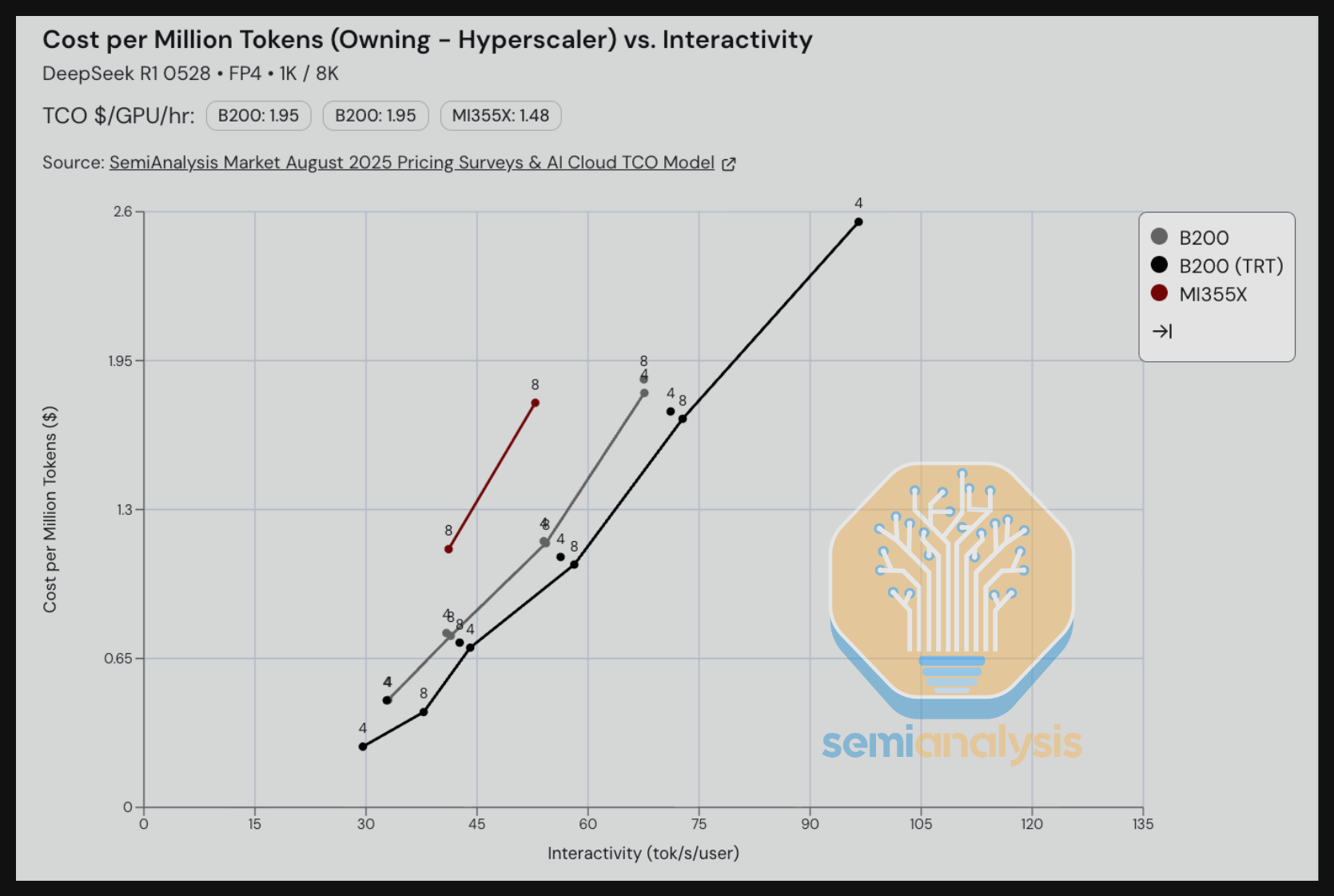
对于摘要场景,GB200 使用当前的 TRT-LLM Dynamo 软件在交互性低于 80 tok/s/user 时表现优于 B200 单节点。比较 MI355X SGLang 与 B200 SGLang,我们看到 B200 提供了更好的每百万 token TCO 成本。
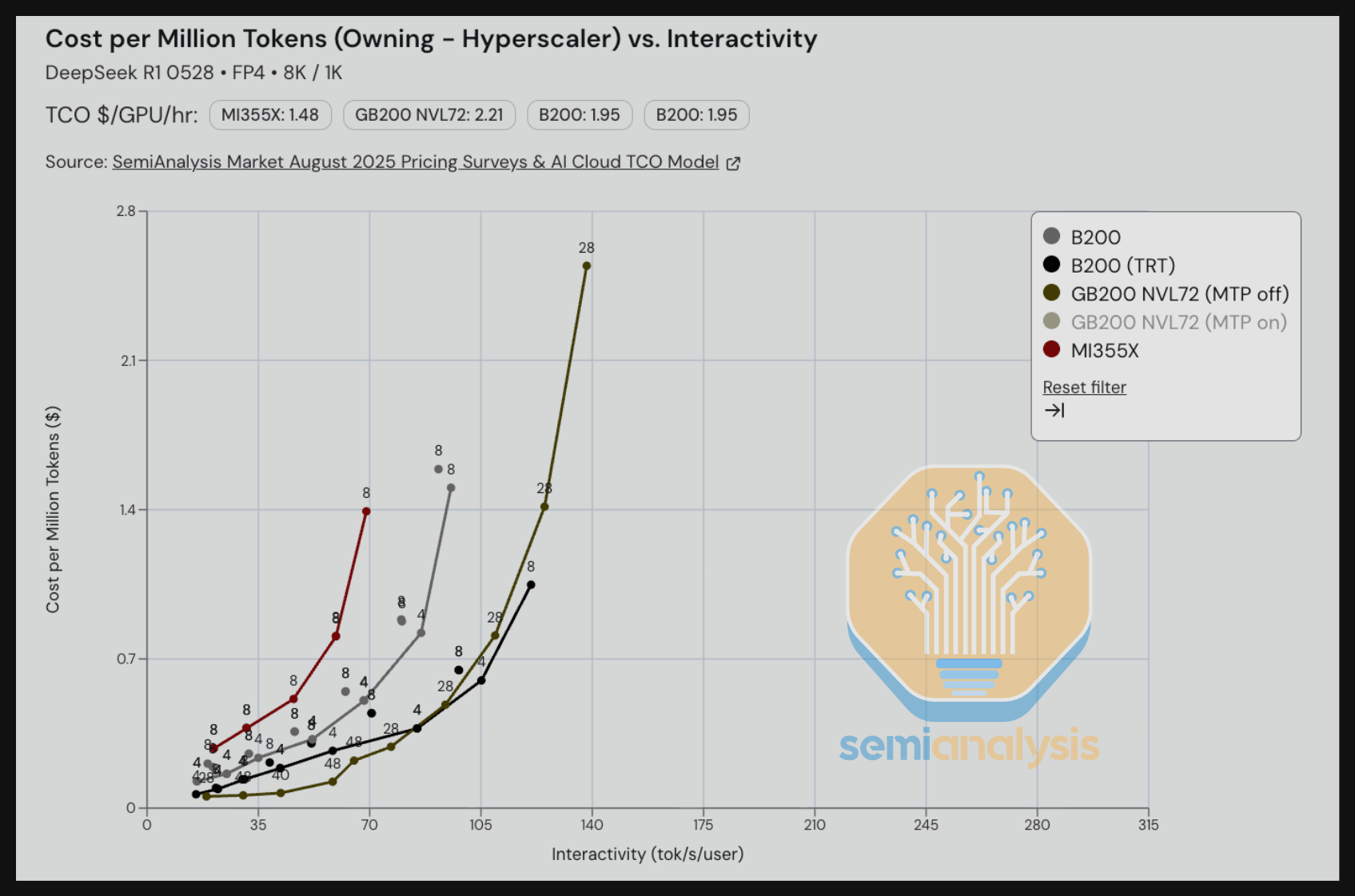
我们还对使用 FP4 配合多 token 预测(MTP)运行的工作负载进行了基准测试。MTP 是 DeepSeek 团队在训练阶段实现的功能。我们看到,在保持每百万 token TCO 成本不变的情况下,MTP 可以在给定成本水平下提供比不使用 MTP 高 2-3 倍的交互性(tok/s/user)。的确,大多数前沿实验室和一级托管 DeepSeek REST API 端点提供商已经在生产工作负载中启用了 MTP。
每全额配置公用事业兆瓦估计 Token 吞吐量 vs 交互性(tok/s/user)
电力是 AI 基础设施的终极约束。每个数据中心都在有限的功率范围内运行,通常以兆瓦(MW)为单位衡量。这直接决定了给定数据中心可以产生多少有用计算——以及最终可以产生多少 token。
推理经济不仅可以通过 GPU 性能(吞吐量/GPU vs TCO)的视角来分析,还可以通过每功率吞吐量来分析——以每全额配置公用事业 MW 的 token/s 来衡量。全额公用事业功率涵盖 GPU、CPU、网络设备、其他相关集群 IT 设备以及设施开销的功率需求。设施开销包括电力分配损耗以及用于冷却设备(如冷水机组、CDU 和冷却塔等)的功率消耗。每 MW 处理的 token 数越多,每单位能源的潜在收入和利润就越大。请注意,对于 InferenceMAX,我们使用的是全额配置公用事业 MW,它考虑了上述设施开销,而不是每全额关键 IT MW 的 token 数(后者不考虑设施开销)。这些指标在不同站点之间有所不同,但我们根据我们的 AI TCO 模型和数据中心模型选择了行业代表性数值。
请注意,托管租金和电力成本通常占总拥有成本的不到 20%。这意味着如果给定 GPU 与另一块 GPU 相比每 MW token 数低 20%,这仅会转化为不到 4% 的总拥有成本差异(即 20% * 20% = 4%)。TCO 贡献的大头来自各 GPU 硬件供应商收取的毛利率。一些厂商收取高达 75% 的毛利率(即售出成本的 4 倍加价),而其他厂商低于 50% 的毛利率(即不到售出成本的 2 倍)。
我们使用速率单位——即 token/s per MW——而非累积的每 token 能量单位(如焦耳每 token)。这是因为数据中心容量以兆瓦(MW)为单位来规划,这是一个速率单位,等同于每秒 1 兆焦耳(MJ)。如果我们将速率单位在给定时间段内积分,就得到该时间段内消耗的绝对能量值。
目前,我们通过加总数据中心中各组件的热设计功耗(TDP)来估算给定集群所需的 MW。TDP 与预期平均功率不同。举例说明:对于内存带宽受限的解码工作负载,系统功耗永远不会达到 TDP,而是会在较低的功率水平——即预期平均功率附近波动。未来,我们将通过 ipmitool 对每个系统(和网络设备)的实际功耗进行基准测试。届时我们将转向每 token 的累积能量单位。
我们基于 InferenceMAX 原始结果结合来自我们 AI 数据中心行业模型的 AI 集群全额公用事业功率数据来估算每配置功率的吞吐量。该模型通过跨供应商、架构和推理栈的功率归一化估算来量化全额公用事业功率。完整的估算和持续的每夜基准测试可在 InferenceMAX.ai 上获取。
每 MW 性能结果
我们看到,对于 gpt-oss 120B 使用 MX4 weights 的推理场景(1K 输入 token / 8K 输出 token),在 90 tok/s/user 交互性水平下,MI300X 每全额配置公用事业 MW 可处理 750,000 token/s(再次强调,这是按公用事业 MW 衡量的,而非按关键 IT 功率 MW),而 MI355X 每全额配置公用事业 MW 可处理 2,550,000 token/s。这代表了从 CDNA3 代到 CDNA4 代约 3 倍的能效提升。
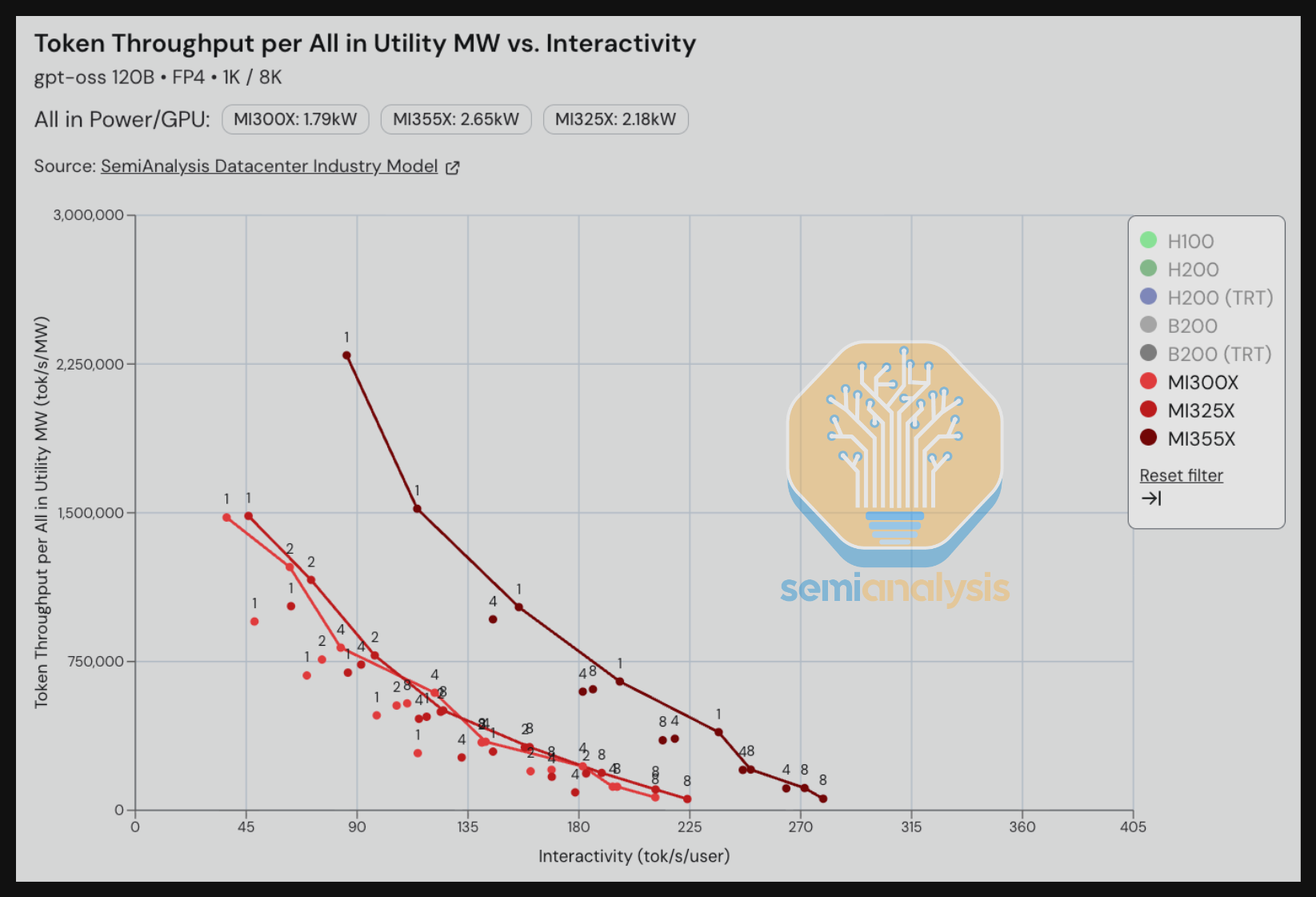
在 Nvidia 阵营中,我们看到了类似的代际趋势。对比 HGX H100 与 HGX B200 运行 gpt-oss 120B FP4 weights,H100 每 MW 可处理 900,000 token/s,而 B200 每 MW 可处理 2.8M token/s——B200 相比 H100 能效提升约 3 倍。当我们看到约 180 tok/s/user 的更高交互性水平时,B200 实现了令人瞩目的 7 倍能效提升。

让我们比较 AMD 和 Nvidia 同代 GPU 的能效。我们首先看 GPTOSS 120B 的每配置全额公用事业 MW token/s。根据我们的初始 InferenceMAX 结果快照,我们看到 Blackwell 在这一吞吐量/功率指标上比 CDNA4 架构能效高 20%。造成这一差异的一个重要因素是 MI355X 单 GPU TDP 明显更高,为 1.4kW/GPU,而 B200 为 1kW/GPU。
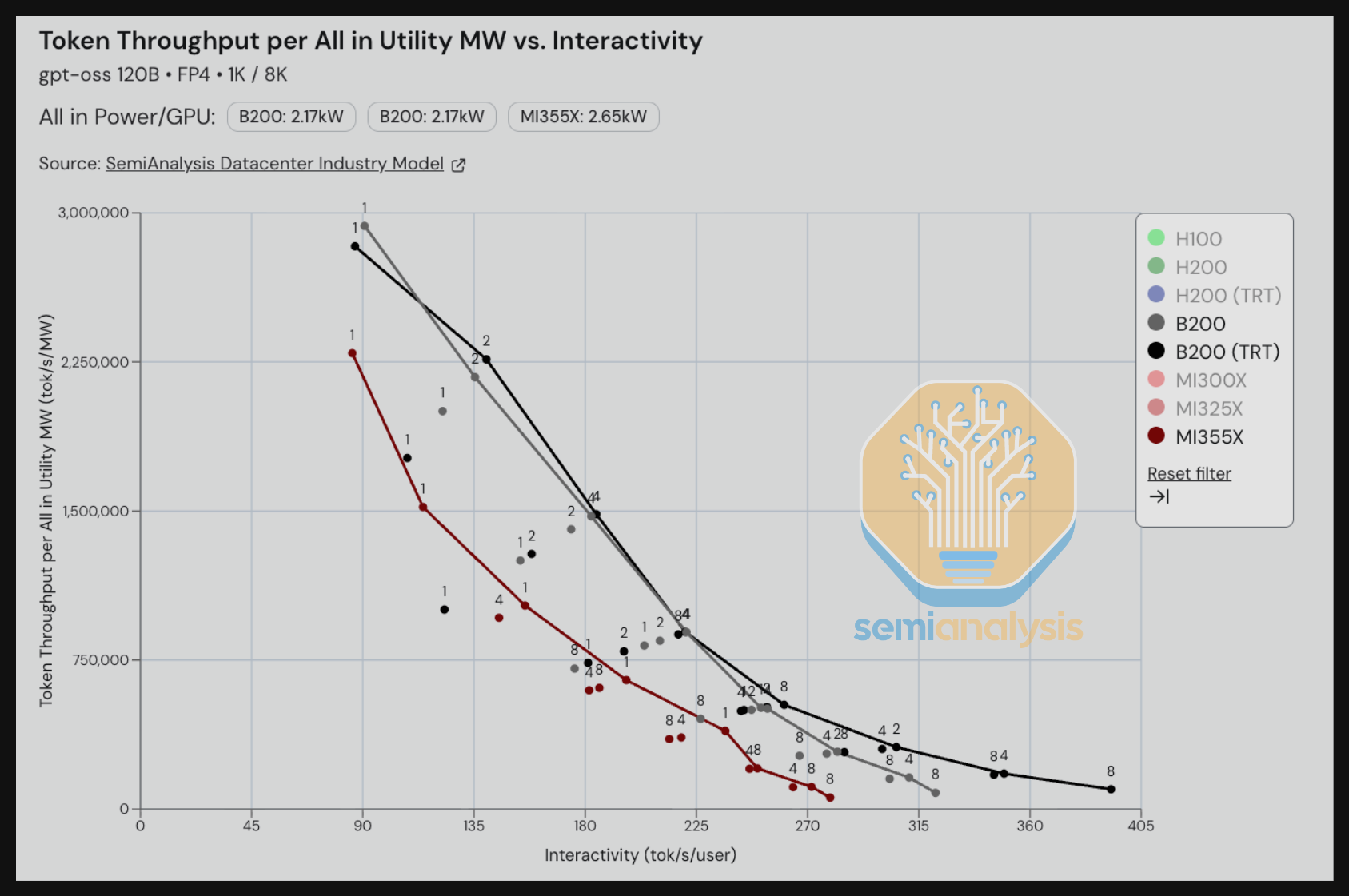
在下一个基准测试中,我们以 30 tok/s/user 交互性水平来看 DeepSeek R1 的每功率 token 数。比较单节点 H200 FP8 与 GB200 NVL72 FP4(不含多 token 预测),GB200 NVL72 在每全额配置公用事业 MW 处理的 token/s 方面提供了约 8 倍的提升。请注意,H200 和 B200 的结果都来自单节点。我们将探索 B200 和 H200 通过在 SpectrumX 以及 InfiniBand 上实现分离式预填充和 wide 专家并行所能释放的更大每 MW token 吞吐量潜力。SGLang 的 GB200 NVL72 分析显示,8-GPU 系统确实可以通过实现 wide 专家并行获得强劲的性能提升。然而,SGLang 的博客也表明,即使 Hopper 同样实现了分离式预填充和 wide EP,GB200 NVL72 仍然胜出。
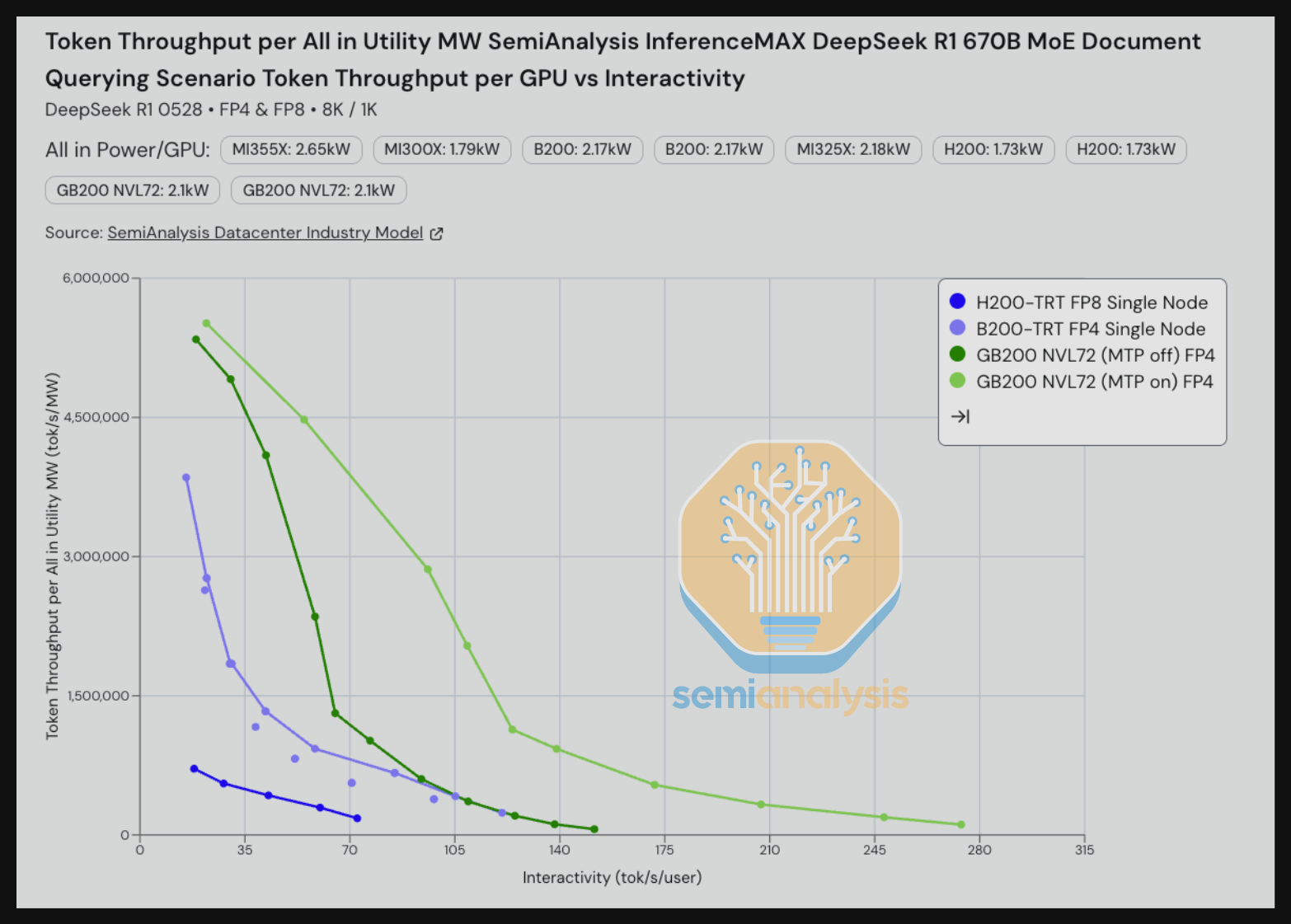
继续 DeepSeek 但转到 FP8,我们看到 GB200 在 tok/s/gpu vs tok/s/user 上也主导了所有单节点系统。我们注意到这里有一些细微差别——B200 和 MI355X 都在运行单节点 SGLang,尽管对于 DeepSeek 而言,vLLM 可能在 MI355X 上比 SGLang 能提供更好的结果。我们将探索为 MI355X 添加 DeepSeek vLLM 支持和/或为所有 8-GPU 服务器添加 SGLang 多节点 wideEP。此外,如前所述,Dynamo 团队目前只有时间实现足以在约 30 tok/s/user 附近实现并行帕累托前沿下移的优化。进一步的优化可以将帕累托前沿进一步推低,从而在更高交互性水平下提升 GB200 NVL72 FP8 的每功率吞吐量。
AMD Bug 与 NVIDIA Blackwell Bug
在排查过程中遇到了几个有趣的 Blackwell Bug。第一个 Bug 是我们从 2025 年 7 月开始使用的 Blackwell vLLM 镜像会导致实例在我们的裸金属 B200 机器上挂起长达 30 分钟。这特别难以复现和调试,因为其他人尝试在他们的 Blackwell 集群上使用完全相同的镜像时并没有遇到任何挂起问题。
我们用来调试这个挂起问题的第一个工具是 py-spy——一个 Python 性能分析器——用来收集跟踪信息。我们注意到它卡在 ncclCommInitRank 上,这很奇怪——许多 ML 性能工程师都知道,这个函数在单节点上应该运行得非常快。另外值得注意的是,vLLM 由于各种技术原因使用了他们自己的 FFI 绑定来调用 NCCL。
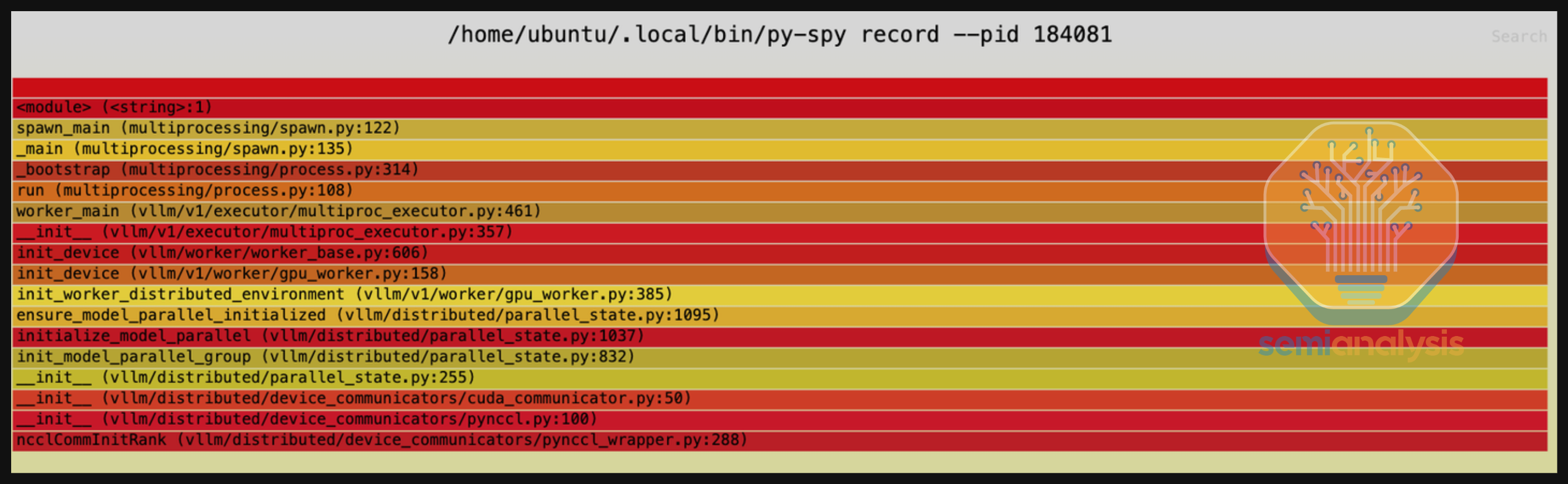
在阅读了 vLLM 的 NCCL 绑定代码后,我们并不认为 FFI 绑定是问题的根本原因。运行 nvidia-smi 时,我们看到 GPU_UTIL 不是 100% 而是 0%——表明没有内核在 GPU 上运行,由此我们得出结论这不是设备端的 NCCL 死锁。
接下来,我们使用 Linux perf top 分析器查看 Python 层之下,试图更深入地了解具体是哪个共享库触发了这个问题。我们注意到该进程(及子进程)的大部分 CPU 周期都花在 "libnvidia-ptxjitcompiler.so" 上。查阅 "libnvidia-ptxjitcompiler" 文档后,我们找到了这样的描述:"PTX JIT Compiler 库(/usr/lib/libnvidia-ptxjitcompiler.so.575.57.08)是一个 JIT 编译器,将 PTX 编译为 GPU 机器码,由 CUDA 驱动使用"。这非常奇怪,因为我们不确定为什么初始化时要调用 PTX 编译器——通常所有 NCCL 内核都是在构建时预编译好的,不应该有需要即时编译的内核。
我们当时太懒了太忙了,无法重建整个容器镜像并从头编译启用了调试符号的 NCCL。因此,我们接下来使用 strace 来确定 ptxjitcompiler 正在进行什么系统调用,以便更深入一层了解正在调用的函数。我们发现 ptxjitcompiler 正在容器内的 ~/.nv/ComputeCache/ 中创建和添加文件。
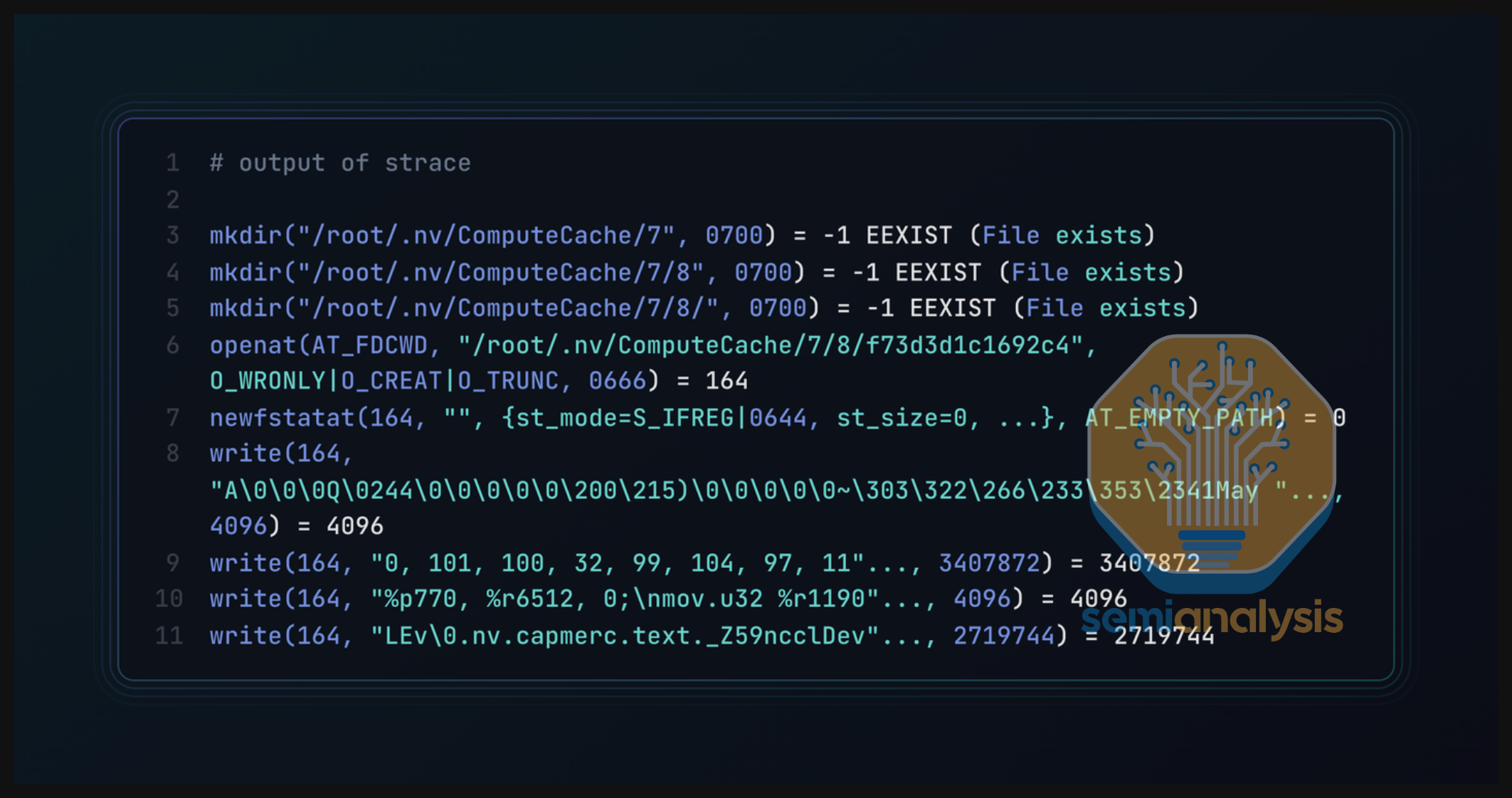
再剥一层洋葱,我们研究了 ~/.nv/ComputeCache/ 的作用。根据文档,它是将 PTX 虚拟 ISA 转换为 SASS 机器码的缓存。这也让我们非常困惑,因为通常 NCCL 在构建时会同时打包机器码和 PTX 虚拟 ISA。我们开始阅读 NCCL 构建脚本,注意到 SM100(Blackwell)在 CUDA 12 中未被启用——而我们正在使用 CUDA 12——发现它们只为即将推出的 CUDA 13 启用了 SM100。这意味着 SM100 SASS 未被打包,我们实际上是在将 compute_90(Hopper)PTX JIT 转换为 SM100 SASS,导致这个过程耗时极长。其他人没有看到这个 Bug 是因为他们使用的是通过 SLURM 手动挂载了 home 目录的内部集群。由于 SASS JIT 缓存存储在 home 目录 ~/.nv/ComputeCache/ 中,SASS 已经被缓存了!
原来 vLLM 7 月份的容器镜像基于 PyTorch 容器镜像,后者使用了一个未预构建 Blackwell SM100 的 NCCL 版本。修复方法是使用修复后的 2.26.2 版本,其中包含了预构建的 Blackwell 支持,这样就不会浪费 30 分钟来编译虚拟 ISA 到机器码。这个 Bug 已在最新的 vLLM 容器镜像中修复。感谢 simon-mo、youkaichao、mgoin、Robert-shaw、ptrblck 和 Kedar Potdar 帮助实施永久修复并快速解决问题。

我们遇到的另一个 Blackwell 问题是 vLLM/SGLang 的子依赖 Flashinfer 存在文件锁竞态条件(race condition)。出于某种原因,Nvidia 决定不将编译好的内核打包到容器镜像中,而是在服务器启动时下载它们。由于我们每个节点最多有 8 个进程(每个 GPU 1 个进程),如果代码不是进程安全的,我们在下载这些编译内核时就会遇到竞态条件。
实际上,这个竞态条件是由于一次旨在防止竞态条件的尝试而引入的!Flashinfer 没有依赖内置 FileLock Python 包的锁清理,而是手动清理锁,这反而导致了竞态条件。这已在 Flashinfer 中修补,但尚未上游到 vLLM/SGLang Blackwell 发布容器镜像。非常感谢 Flashinfer 团队和 Kedar Potar 迅速介入,在与团队对接后仅 4 小时内就完成了调试和修补。
还有一个 Blackwell Bug 是 Flashinfer 将构建环境标志名称改为 FLASHINFER_CUDA_ARCH_LIST,但 Nvidia 方面没有通知 vLLM/SGLang 维护者,也没有提交自己的 PR,因此在几周时间内 vLLM 和 SGLang 都不支持 Flashinfer 的 AOT。
我们发现 Nvidia 容器工具包偶尔会完全出错并显示以下消息:
"docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running prestart hook #0: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: initialization error: driver rpc error: timed out: unknown"
尝试在 CLI 中使用 nvidia-smi 也会触发挂起。这表明整个 Nvidia 驱动实际上已经崩溃。在与 Nvidia 固件/驱动团队和 NVIDIA NCCL 团队进行详细的调试会议后,我们发现自 NCCL 2.26 以来存在一个缓慢的资源泄漏 Bug,因为我们使用了 CUDA graphs 并且每夜启动超过 500 个 Blackwell 容器。
由于我们频繁地启动和停止大量 Blackwell 容器,所有这些启停操作累积起来最终导致驱动崩溃。资源泄漏 Bug 的具体原因在于,当启用 CUDA graph 时,NCCL 默认会启用用户缓冲区(user buffers)。如果没有这个资源泄漏 Bug,NCCL 用户缓冲区功能本应通过让 NCCL 使用应用程序缓冲区实现零拷贝,减少应用层缓冲区和 NCCL 内部缓冲区之间的数据移动。临时修复方案是在过渡期内不启用 NCCL 用户缓冲区,直到 Bug 修复可以推出。修复的预计时间约为 10 月 20 日,预计作为 NCCL 2.28 的一次次要更新发布。感谢 Kedar Potar 和众多 Nvidia 团队成员迅速定位根因并以令人难以置信的速度和支持修复了这个 Bug。
在 AMD 方面,我们在开发 InferenceMAX 过程中遇到的 Bug 较少,而且这些 Bug 更容易修复。其中一个 Bug 是 AMD 的 CUDNN 等价物 AITER 在一个辅助函数中崩溃,因为它没有考虑到 "/opt/rocm/llvm/bin/amdgpu-arch" 不仅返回计算架构(如 gfx942),还会在返回 gfx942 时包含后缀。AITER 旨在通过模式匹配来判断它所使用的架构,但没有考虑后缀存在的情况。编写临时修复很简单,但 AITER 将在接下来几周内推出永久修复。感谢 Quentin 帮助修补了这个问题!
我们还在 MI355X 基准测试中遇到了一个 Bug,即基准测试运行崩溃并转储了 1TB 名为 gpucore.XXX 的文件。经过调查,我们发现根因是服务器配置中的 chunked prefill 大小设置过高。将其从 196608 降低到 32768 即修复了这个问题(PR 链接)。
AMD 最近添加了 pyxis 支持,为在 SLURM 中使用容器带来了良好的使用体验,尤其是在多节点训练或多节点离线批量推理作业方面。然而,我们在他们的 ROCm 7.0 SGLang 镜像 "rocm/7.0:rocm7.0_ubuntu_22.04_sgl-dev-v0.5.2-rocm7.0-mi30x-20250915" 上遇到了一个 Bug,当尝试通过 pyxis SLURM 运行此镜像时导致硬崩溃。根因在于组成该 Docker 镜像的某些层的权限处理方式导致了层间的权限冲突。AMD 团队正在研究如何永久修复并防止此类错误再次发生。
早在 7 月份,当我们尝试在 AMD GPU 上为 SGLang 启用 AITER 时,由于 DeepSeek V3 的编译过程缓慢,耗时比正常情况多 10 倍(总共约 30 分钟)(GitHub issue 链接)。这个问题最终在后续版本中得到解决,目前已修复。
GitHub Action CI/CD Bug
GitHub Actions 的自托管 runner 支持为我们在 InferenceMAX 中想要运行的基准测试提供了一个简单直接的解决方案。集成设置快速,允许在各种 GPU 集群上运行可复现的工作流,无需构建自定义基础设施。然而,随着 InferenceMAX 开始扩展以包含更多 job,GitHub Actions 的一些局限性也浮现出来。
每个基准测试变体作为一个单独的 job 运行。对于每个模型,我们对以下不同组合进行基准测试:不同的 GPU、输入/输出序列长度、精度、张量并行度和并发数。这在添加更多配置时导致每个 workflow 的 job 数量产生组合爆炸。
具体来说:InferenceMAX 目前在最多 7 种 GPU 类型上对 3 个模型进行基准测试,涵盖 3 种不同的 ISL/OSL 对、2 种精度设置,以及大约 4 种并发数和张量并行选项。并非每个模型都使用所有可能的配置,但这个最坏情况估算给出 3 _ 7 _ 3 _ 2 _ 4 * 4 = 2016 个不同的 job。在这种规模下,GitHub Actions 工作流可视化遇到了限制:服务器在尝试渲染 DAG 时在十秒后超时,导致错误消息。这使得调试运行变得极其困难。我们的解决方法是将单个每夜 workflow 拆分为三个,按 ISL/OSL 对分拆。这将每个 workflow 的 job 数从大约 1500 减少到 500,服务器似乎可以可靠地处理。
另一个 Bug 涉及使用 download-artifacts@v5 action 时的硬限制。在每次完整扫描 workflow 结束时,会运行一个 job 来收集和汇总所有 job 的性能结果,这些结果作为 workflow 的 artifact 存储。作为收集过程的一部分,会调用 download-artifacts@v5 action。它初始化一个 artifact client,该 client 反过来调用一个 list artifacts 函数(需要列出所有 artifact 然后通过模式匹配找到请求的那个),该函数出于"性能原因"强制执行了 1000 的硬限制。据称当 client 尝试列出超过 1000 个 artifact 时应该会打印一个警告,但我们从未观察到这种行为。
我们要感谢 Scott Guthrie 将我们与 GitHub 的合适人员对接,并感谢这些团队成员帮助我们实施了针对这些 Bug 的临时解决方案。我们期待继续使用 GitHub Actions 来创建开源世界中最大的 GPU CI/CD 集群之一。
对 Nvidia 和 AMD 的建议
尽管大量用户和 GPU 在 SGLang 和 vLLM 上运行,Nvidia 一直将大部分推理工程师资源分配给 TensorRT-LLM 的开发,而投入到支持 SGLang 和 vLLM 的工程资源相对较少。我们建议 Jensen 分配更多推理工程资源来支持和贡献 vLLM 和 SGLang 等流行推理引擎。这将使 Nvidia 更好地履行其加速工作负载的使命,无论用户选择哪种推理引擎。
此外,ML 社区将受益于 Nvidia 为 QA 其 Blackwell 软件投入更多的时间和资源,以最大限度地减少终端用户在新平台上部署应用时遇到的 Bug 数量。在开发 InferenceMAX 的过程中,我们遇到了许多仅在 Blackwell 上出现、而在 Hopper 或其他平台上不存在的 Bug。
在 AMD 方面,我们建议他们减少需要手动启用才能获得合理性能的 ROCm 特定标志数量。AMD 已经认识到这一点,并已开始着手确保优化配置默认启用。事实上,许多减少所需标志数量的更改已经合入了 master 分支。
我们对 Nvidia 的 Blackwell 平台提出了相同的建议,并建议 Nvidia 通过默认启用性能优化来减少获得合理性能所需的标志数量。
InferenceMAX 后续计划
在接下来的几个月内,我们将通过集成 Google TPU 和 Amazon Trainium 来扩展 InferenceMAX 的硬件覆盖范围,我们计划在未来两个月内上线。这将实现跨 AMD、NVIDIA、Google 和 AWS 加速器的统一、同等条件对比。这标志着 InferenceMAX 向成为全行业真正跨供应商的开放基准测试平台迈出了重要一步。
此外,我们还将推出另一项计划——对 FP4 模型进行每夜评估(eval),包括 MATH-500 和 GPQA-Diamond,使社区能够以一致、透明的方式衡量吞吐量与质量的权衡。这将有助于揭示低精度推理如何影响不同模型家族和部署场景下的准确性。此外,我们还将追踪输出 token 吞吐量以创建更全面的洞察。
在 NVIDIA 和 AMD 系统方面,多项令人兴奋的计划正在推进中。我们正在 MI300 和 MI355 系列 GPU 以及 B200 GPU 上开展 DeepSeek 的分离式预填充 + 多节点专家并行配置的工作,测试这些高级并行优化如何在推理工作负载上实现扩展。同时,我们也期待测试 HGX B300 Blackwell Ultra 和 GB300 NVL72 Blackwell Ultra,以了解它们相对于 GB200 NVL72 的性能提升。
InferenceMAX 并不完美,但我们坚信我们正朝着正确的方向前进——打造一个能够跟上 AI 软件进步步伐的基准测试——并将继续整合来自 AI 芯片供应商、前沿实验室和大型加速器消费者的反馈。
接下来,我们将深入分析 InferenceMAX v1 中当前使用的各 GPU(H100、H200、B200、GB200 NVL72、MI300X、MI325X、MI355X)的 TCO 各组成部分。
超大规模厂商总拥有成本——Hopper、Blackwell、GB200 NVL72、MI300X、MI325X、MI355X
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
本文继续发表在我们的 Substack 上。订阅 SemiAnalysis 以阅读完整文章。
本文由英文原文翻译而来,如有歧义以英文版为准。所有文章版权归 © SemiAnalysis 所有,保留所有权利。覆盖应用源代码的 AGPL-3.0 许可证不适用于文章内容。