GB300 NVL72 FP4: MTP vs Off 投机解码
MTP 与 Off 在 GB300 NVL72 FP4(NVIDIA Blackwell)上运行 DeepSeek R1 的投机解码对比。在各类 LLM 工作负载下的吞吐量、成本和交互性差异。使用下方图表控件切换序列和指标——交互方式与主推理图表相同。
MTP 接受率实现在不同推理引擎间存在差异。不同引擎的数据点在同一曲线上不可直接比较——在相同交互性水平下的吞吐量和成本差异可能反映的是引擎层面的差异,而非纯投机解码收益。请谨慎解读跨引擎对比。
在 DeepSeek R1(GB300 NVL72 FP4)上以 59 tok/s/user 交互性运行时,MTP 吞吐量为 13357 tok/s/GPU,每百万 token 成本 $0.05;Off 吞吐量为 6821 tok/s/GPU,成本 $0.11。MTP 每 token 成本低 101%;MTP 每 GPU 吞吐量高出 96%。投机解码通过接受草稿 token 来降低每 token 延迟——收益因工作负载和提示分布而异。
MTP 在 DeepSeek R1(GB300 NVL72 FP4)上以 98 tok/s/user 运行时达到 8316 tok/s/GPU(每百万 token $0.09);Off 达到 560 tok/s/GPU($1.32)。MTP 每 token 成本低 1416%;MTP 每 GPU 吞吐量高出 1384%。草稿 token 的接受率决定了投机解码在给定并发水平下是否有效。
DeepSeek R1(GB300 NVL72 FP4)在 138 tok/s/user 交互性下的吞吐量:MTP 为 3821 tok/s/GPU,Off 为 180。每百万 token 成本分别为 $0.19 和 $4.07。MTP 每 token 成本低 2028%;MTP 每 GPU 吞吐量高出 2022%。投机解码以额外的草稿 token 计算换取更少的解码步骤——收益取决于序列长度和批大小。 (数据反映此 URL 固定的 1k/1k · fp4 工作负载——更改序列或模型时表格和图表都会更新;本页表格始终锁定该精度,图表中的精度切换仅影响图表。)
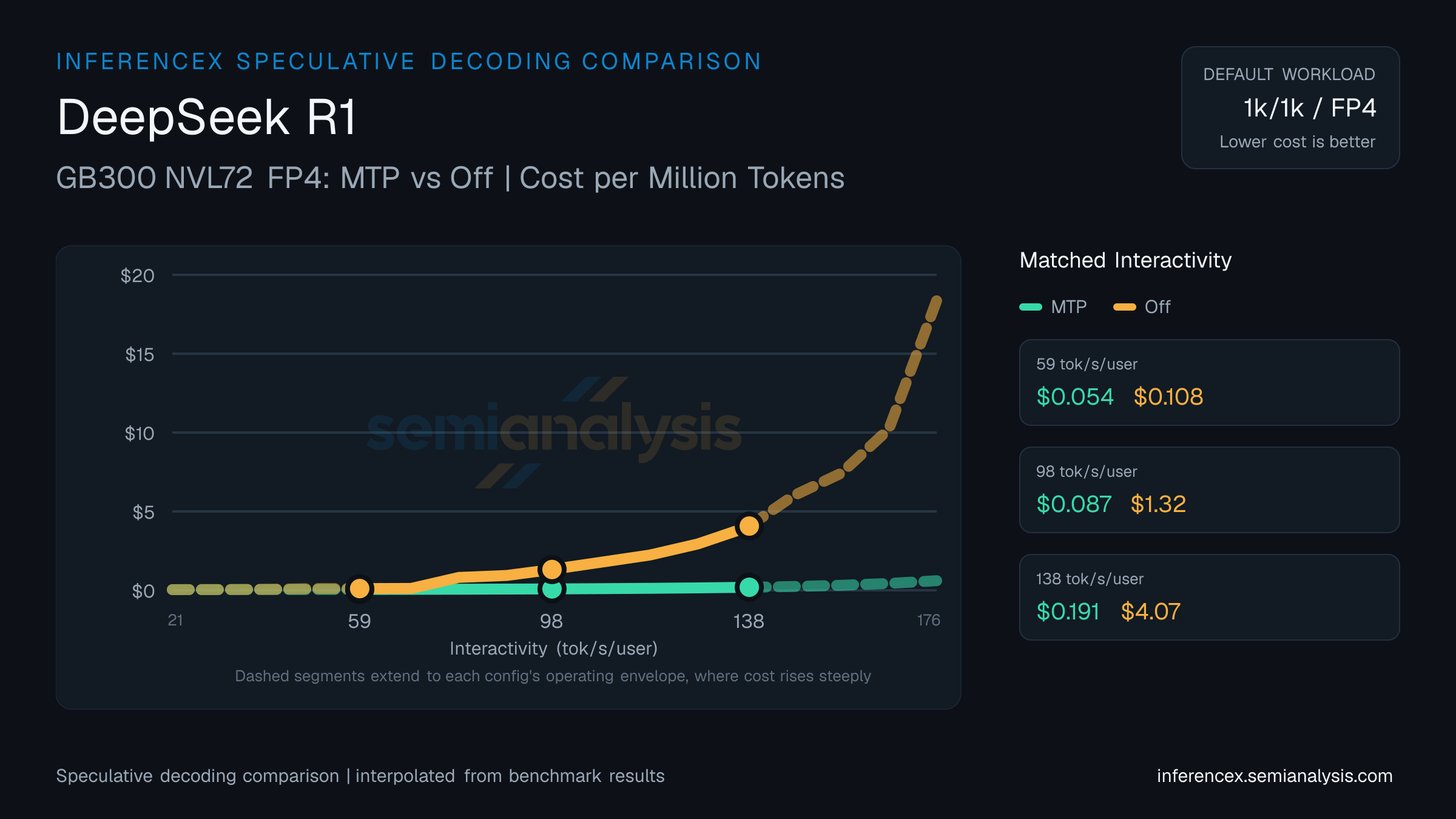
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | MTP:13357.0Off:6821.1 | MTP:8315.8Off:560.5 | MTP:3821.2Off:180.0 |
| Cost ($/M tok) | MTP:$0.054Off:$0.108 | MTP:$0.087Off:$1.316 | MTP:$0.191Off:$4.072 |
| tok/s/MW | MTP:6360488Off:3248148 | MTP:3959912Off:266900 | MTP:1819613Off:85733 |
| Concurrency | MTP:~2484Off:~3022 | MTP:~1651Off:~113 | MTP:~702Off:~8 |
推理性能
不同模型、硬件配置和服务参数下的推理性能指标。