GB300 NVL72 FP4: MTP vs Off Speculative Decoding
Speculative decoding comparison of MTP versus Off on GB300 NVL72 FP4 (NVIDIA Blackwell) running DeepSeek R1. Throughput, cost, and interactivity differences across LLM workloads. Use the chart controls below to switch sequences and metrics — same interactions as the main inference chart.
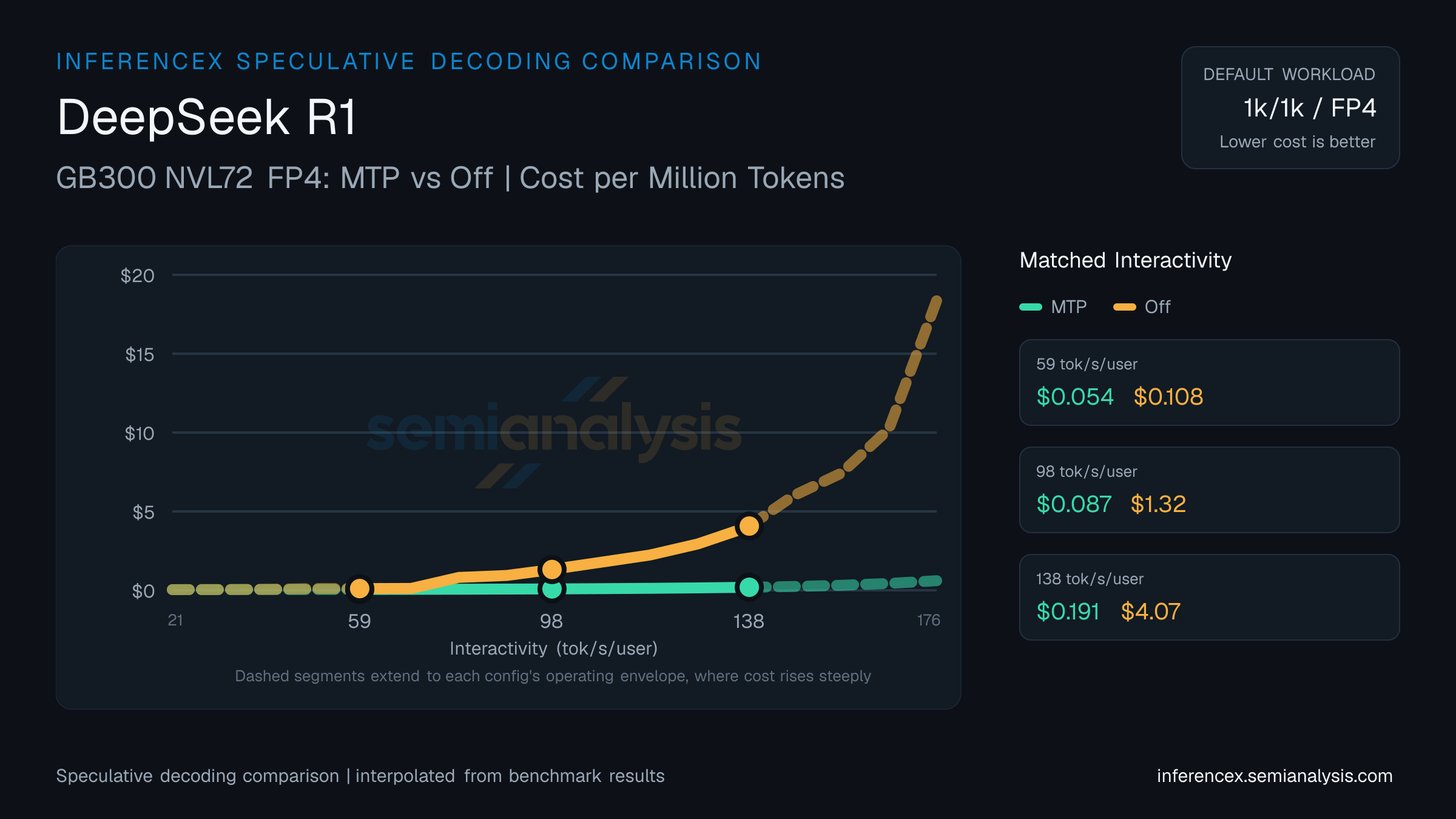
MTP acceptance-rate implementations differ across inference engines. Points from different engines are not directly comparable on the same curve — throughput and cost at matched interactivity may reflect engine-level differences rather than pure speculative decoding gains. Interpret cross-engine comparisons with caution.
At 59 tok/s/user on DeepSeek R1 (GB300 NVL72 FP4), MTP delivers 13357 tok/s/GPU at $0.05 per million tokens; Off delivers 6821 tok/s/GPU at $0.11. MTP is 101% cheaper per token; MTP delivers 96% more tok/s/GPU. Speculative decoding accepts draft tokens to reduce per-token latency — gains vary by workload and prompt distribution.
MTP posts 8316 tok/s/GPU for $0.09 per million tokens at 98 tok/s/user on DeepSeek R1 (GB300 NVL72 FP4); Off posts 560 tok/s/GPU for $1.32. MTP is 1416% cheaper per token; MTP delivers 1384% more tok/s/GPU. Draft-token acceptance rates determine whether speculative decoding helps or hurts at a given concurrency level.
Throughput at 138 tok/s/user on DeepSeek R1 (GB300 NVL72 FP4): MTP hits 3821 tok/s/GPU, Off hits 180. Per-million costs land at $0.19 and $4.07 respectively. MTP is 2028% cheaper per token; MTP delivers 2022% more tok/s/GPU. Speculative decoding trades extra compute on draft tokens for fewer decoding steps — the payoff depends on sequence length and batch size. (Numbers reflect this URL's pinned 1k/1k · fp4 workload — changing sequence or model updates both the table and chart; the table stays pinned to this page's precision, so precision toggles in the controls affect the chart only.)
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | MTP:13357.0Off:6821.1 | MTP:8315.8Off:560.5 | MTP:3821.2Off:180.0 |
| Cost ($/M tok) | MTP:$0.054Off:$0.108 | MTP:$0.087Off:$1.316 | MTP:$0.191Off:$4.072 |
| tok/s/MW | MTP:6360488Off:3248148 | MTP:3959912Off:266900 | MTP:1819613Off:85733 |
| Concurrency | MTP:~2484Off:~3022 | MTP:~1651Off:~113 | MTP:~702Off:~8 |
Inference Performance
Inference performance metrics across different models, hardware configurations, and serving parameters.