GB200 NVL72: FP4 vs FP8 精度对比
在 GB200 NVL72(NVIDIA Blackwell)上对比 FP4 与 FP8 精度对 DeepSeek R1 推理的影响。涵盖各类 LLM 工作负载的吞吐量、延迟与成本。使用下方图表控件切换序列和指标——交互方式与主推理图表相同。
FP4 在 DeepSeek R1(GB200 NVL72)上以 75 tok/s/user 运行时达到 12503 tok/s/GPU(每百万 token $0.05);FP8 达到 5790 tok/s/GPU($0.11)。FP4 每 token 成本低 116%;FP4 每 GPU 吞吐量高出 116%。量化级别的精度差异在评估页面中跟踪。
DeepSeek R1(GB200 NVL72)在 120 tok/s/user 交互性下的吞吐量:FP4 为 9356 tok/s/GPU,FP8 为 3988。每百万 token 成本分别为 $0.07 和 $0.15。FP4 每 token 成本低 134%;FP4 每 GPU 吞吐量高出 135%。低精度带来的成本-吞吐量权衡只是全貌的一部分——请参阅评估页面的精度数据。
在 31–208 tok/s/user 交互性区间的高端,即 DeepSeek R1(GB200 NVL72)上以 164 tok/s/user 运行时:FP4 达到 3995 tok/s/GPU($0.16/百万 token),FP8 达到 818($0.81/百万)。FP4 每 token 成本低 419%;FP4 每 GPU 吞吐量高出 389%。精度变更同时影响推理速度和模型质量——请查阅评估页面的精度基准测试。 (数据反映此 URL 的默认 8k/1k 选择——如果您在控件中更改序列或模型,下方表格和图表会自动更新。每一侧取该精度下的最优可用推理配置,可能包含投机解码(如 MTP)——与其他对比页面的口径一致。)
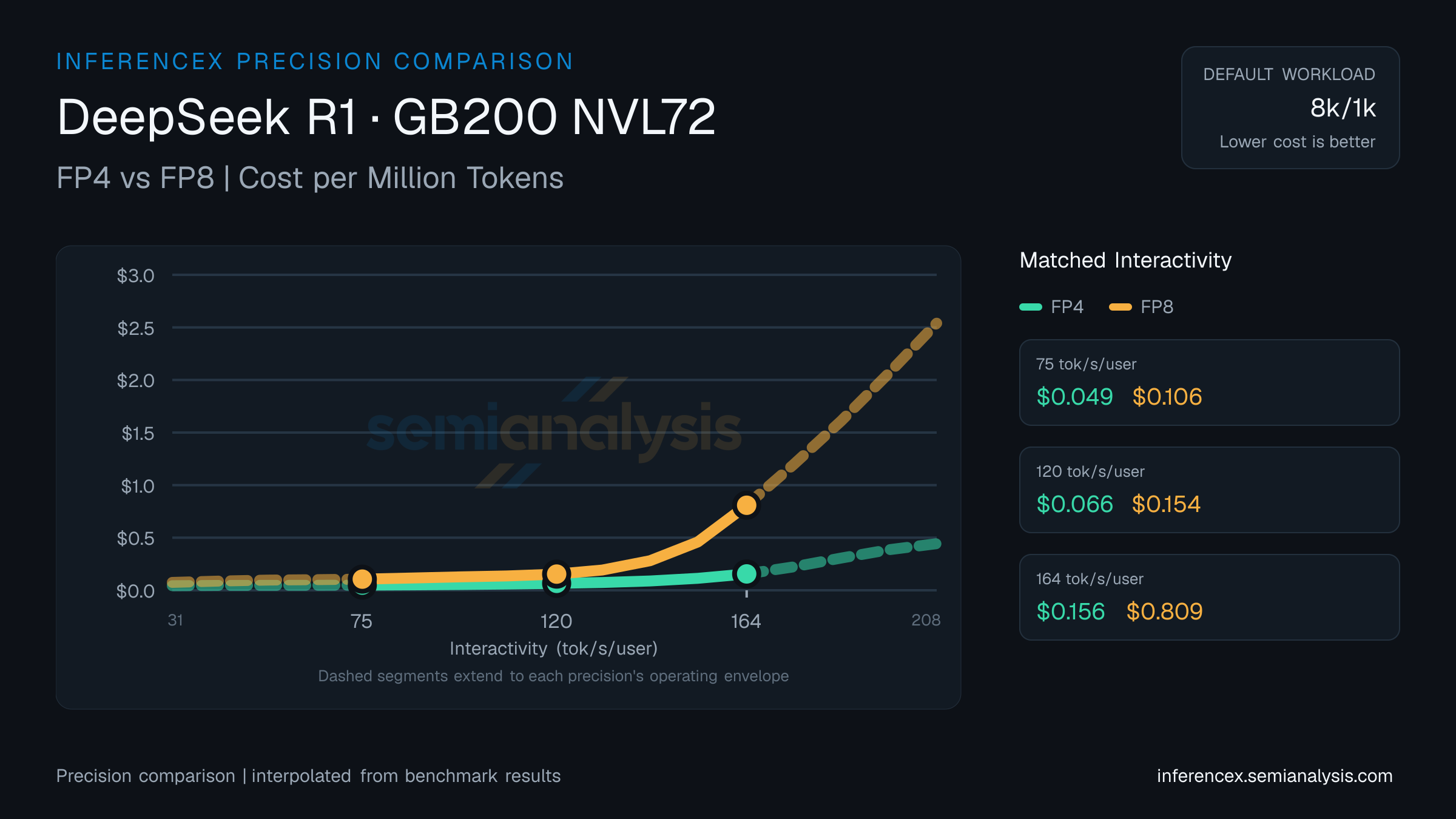
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | FP4:12502.6FP8:5789.6 | FP4:9356.1FP8:3987.5 | FP4:3995.1FP8:817.8 |
| Cost ($/M tok) | FP4:$0.049FP8:$0.106 | FP4:$0.066FP8:$0.154 | FP4:$0.156FP8:$0.809 |
| tok/s/MW | FP4:5953630FP8:2756947 | FP4:4455294FP8:1898817 | FP4:1902445FP8:389416 |
| Concurrency | FP4:~1090FP8:~649 | FP4:~721FP8:~333 | FP4:~164FP8:~27 |
推理性能
不同模型、硬件配置和服务参数下的推理性能指标。