MiniMax M2.5/M2.7 · 每美元性能
MiniMax M2.5/M2.7 — H100 vs H200 每美元性能
H100(NVIDIA Hopper)与 H200(NVIDIA Hopper)在 MiniMax M2.5/M2.7 上的每百万 token 成本。基于所属云服务商 TCO 归一化的输出 token 性能——在各类 LLM 工作负载下的每美元性能。在每个目标交互性水平下选出更经济的 SKU。使用下方图表控件切换序列、精度和指标——交互方式与主推理图表相同。
在 MiniMax M2.5/M2.7 上以 59 tok/s/user 运行时,每百万 token 成本分别为:H100 $0.58、H200 $0.41;H200 每美元多产出 41% 的 token。
在 MiniMax M2.5/M2.7 上以 78 tok/s/user 运行时,H100 每百万 token 成本为 $0.94,H200 为 $0.82。H200 在此工作点上的成本效率高出 15%。
H200 在 MiniMax M2.5/M2.7 上以 98 tok/s/user 运行时领先于 H100——每百万 token 成本 $1.05 对 $1.82,差距达 75%。 (数据反映此 URL 的默认 1k/1k · fp8 选择——如果您在控件中更改序列、精度或模型,下方表格和图表会自动更新。)
GPU 定价(所属云服务商): H100 $1.30/GPU/hr · H200 $1.41/GPU/hr. 来源: SemiAnalysis Market August 2025 Pricing Surveys & AI Cloud TCO Model.
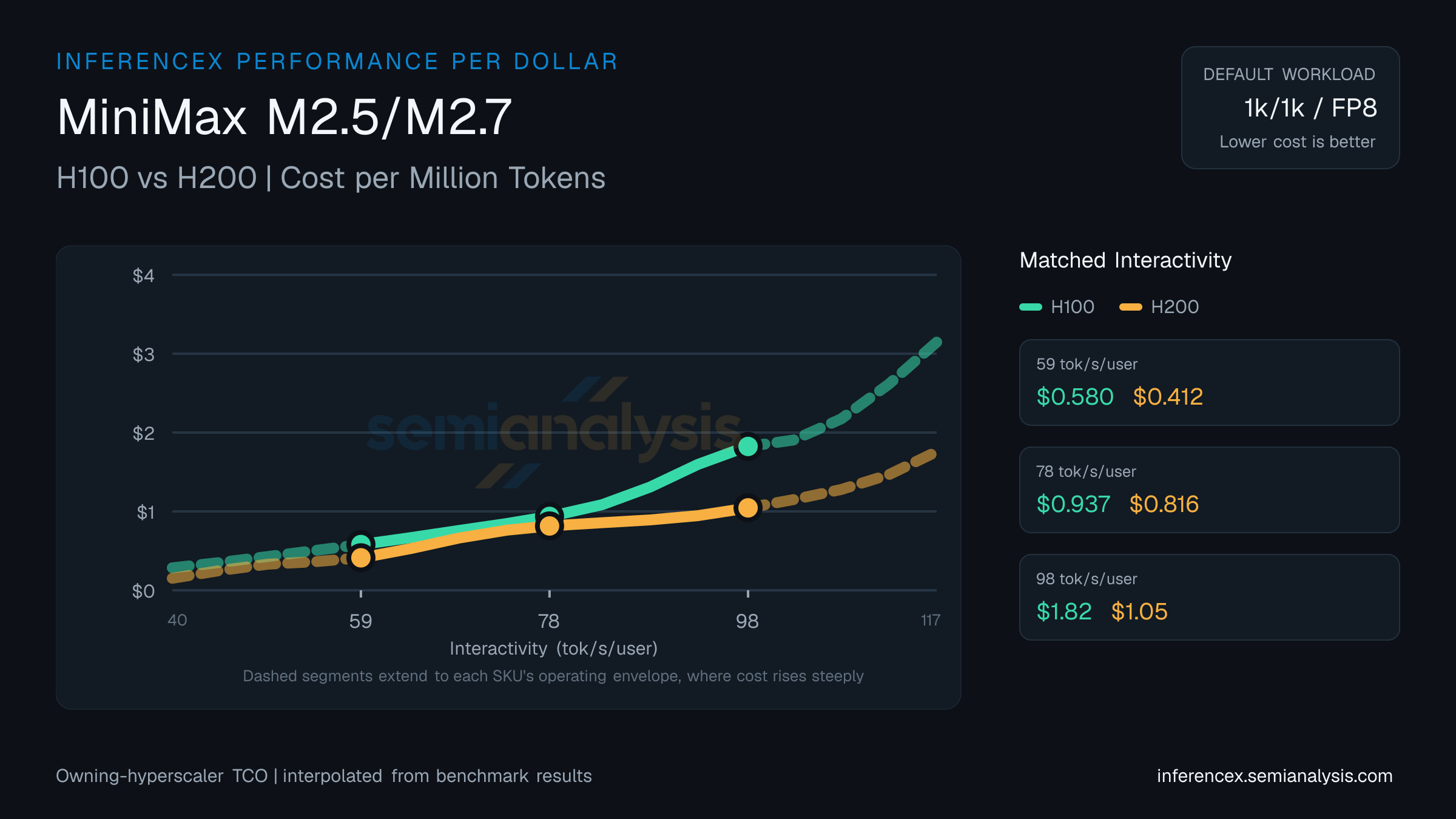
Interpolated from real benchmark data. Edit target interactivity values below to compare at different operating points.
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Dollar per Million Tokens | H100:$0.580H200:$0.412 | H100:$0.937H200:$0.816 | H100:$1.824H200:$1.045 |
| Concurrency | H100:~42H200:~64 | H100:~12H200:~21 | H100:~8H200:~8 |
推理性能
不同模型、硬件配置和服务参数下的推理性能指标。
厂商:
聚合模式:
投机解码: