MI355X: FP4 vs FP8 精度对比
在 MI355X(AMD CDNA 4)上对比 FP4 与 FP8 精度对 GLM 5/5.1 推理的影响。涵盖各类 LLM 工作负载的吞吐量、延迟与成本。使用下方图表控件切换序列和指标——交互方式与主推理图表相同。
在 12–66 tok/s/user 交互性区间的低端,即 GLM 5/5.1(MI355X)上以 25 tok/s/user 运行时:FP4 达到 1169 tok/s/GPU($0.35/百万 token),FP8 达到 987($0.42/百万)。FP4 每 token 成本低 21%;FP4 每 GPU 吞吐量高出 18%。精度变更同时影响推理速度和模型质量——请查阅评估页面的精度基准测试。
在 GLM 5/5.1(MI355X)上以 39 tok/s/user 交互性运行时,FP4 吞吐量为 525 tok/s/GPU,每百万 token 成本 $0.78;FP8 吞吐量为 809 tok/s/GPU,成本 $0.51。FP8 每 token 成本低 53%;FP8 每 GPU 吞吐量高出 54%。低精度量化以模型精度换取吞吐量——请查看评估页面了解质量影响。
FP4 在 GLM 5/5.1(MI355X)上以 53 tok/s/user 运行时达到 255 tok/s/GPU(每百万 token $1.62);FP8 达到 447 tok/s/GPU($0.92)。FP8 每 token 成本低 76%;FP8 每 GPU 吞吐量高出 76%。量化级别的精度差异在评估页面中跟踪。 (数据反映此 URL 的默认 1k/1k 选择——如果您在控件中更改序列或模型,下方表格和图表会自动更新。每一侧取该精度下的最优可用推理配置,可能包含投机解码(如 MTP)——与其他对比页面的口径一致。)
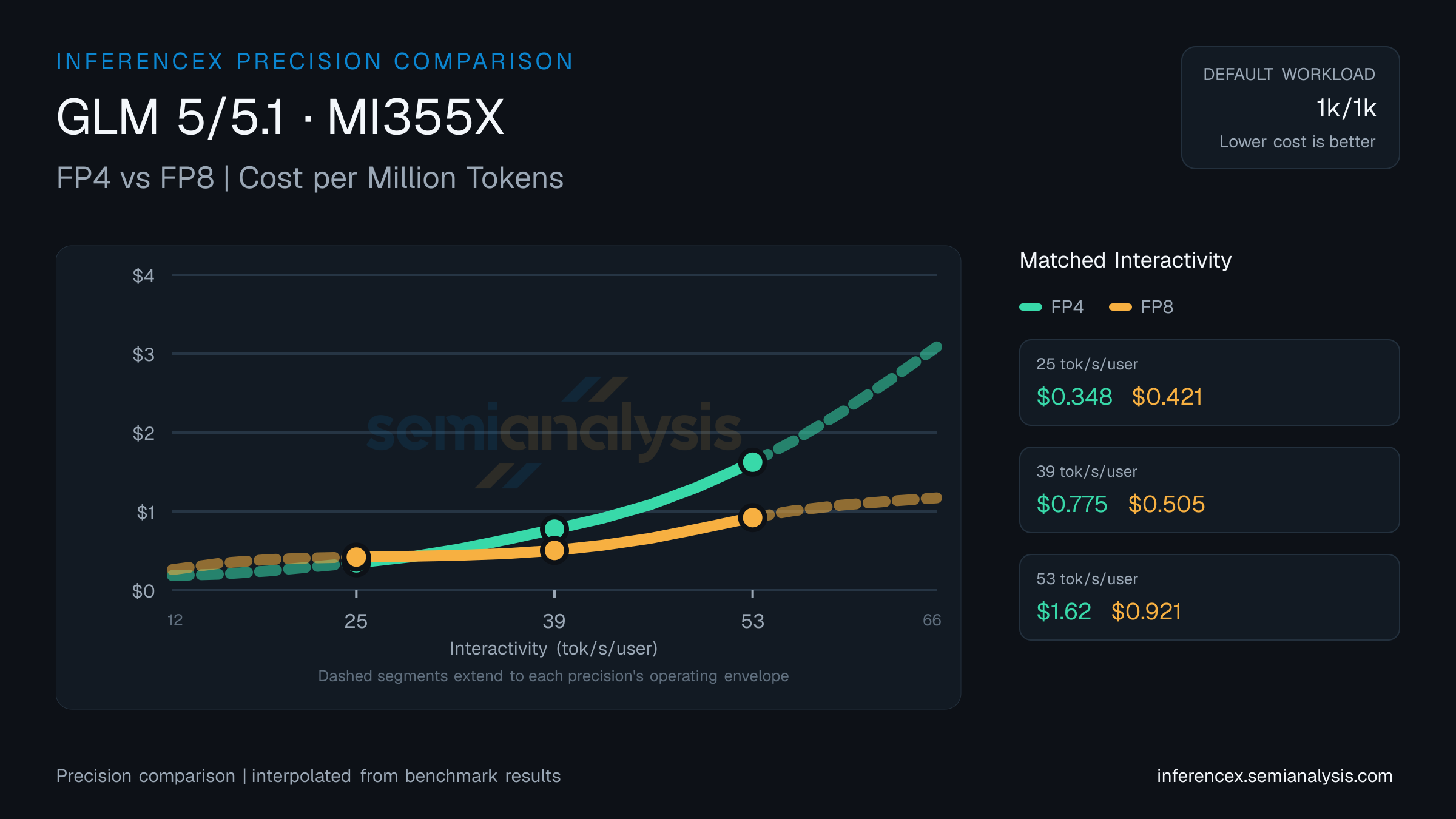
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | FP4:1169.1FP8:987.1 | FP4:525.4FP8:809.1 | FP4:254.9FP8:447.4 |
| Cost ($/M tok) | FP4:$0.348FP8:$0.421 | FP4:$0.775FP8:$0.505 | FP4:$1.624FP8:$0.921 |
| tok/s/MW | FP4:441175FP8:372495 | FP4:198278FP8:305330 | FP4:96182FP8:168835 |
| Concurrency | FP4:~94FP8:~128 | FP4:~27FP8:~108 | FP4:~10FP8:~17 |
推理性能
不同模型、硬件配置和服务参数下的推理性能指标。