MI355X FP8: MTP vs Off Speculative Decoding
Speculative decoding comparison of MTP versus Off on MI355X FP8 (AMD CDNA 4) running Qwen 3.5 397B-A17B. Throughput, cost, and interactivity differences across LLM workloads. Use the chart controls below to switch sequences and metrics — same interactions as the main inference chart.
MTP acceptance-rate implementations differ across inference engines. Points from different engines are not directly comparable on the same curve — throughput and cost at matched interactivity may reflect engine-level differences rather than pure speculative decoding gains. Interpret cross-engine comparisons with caution.
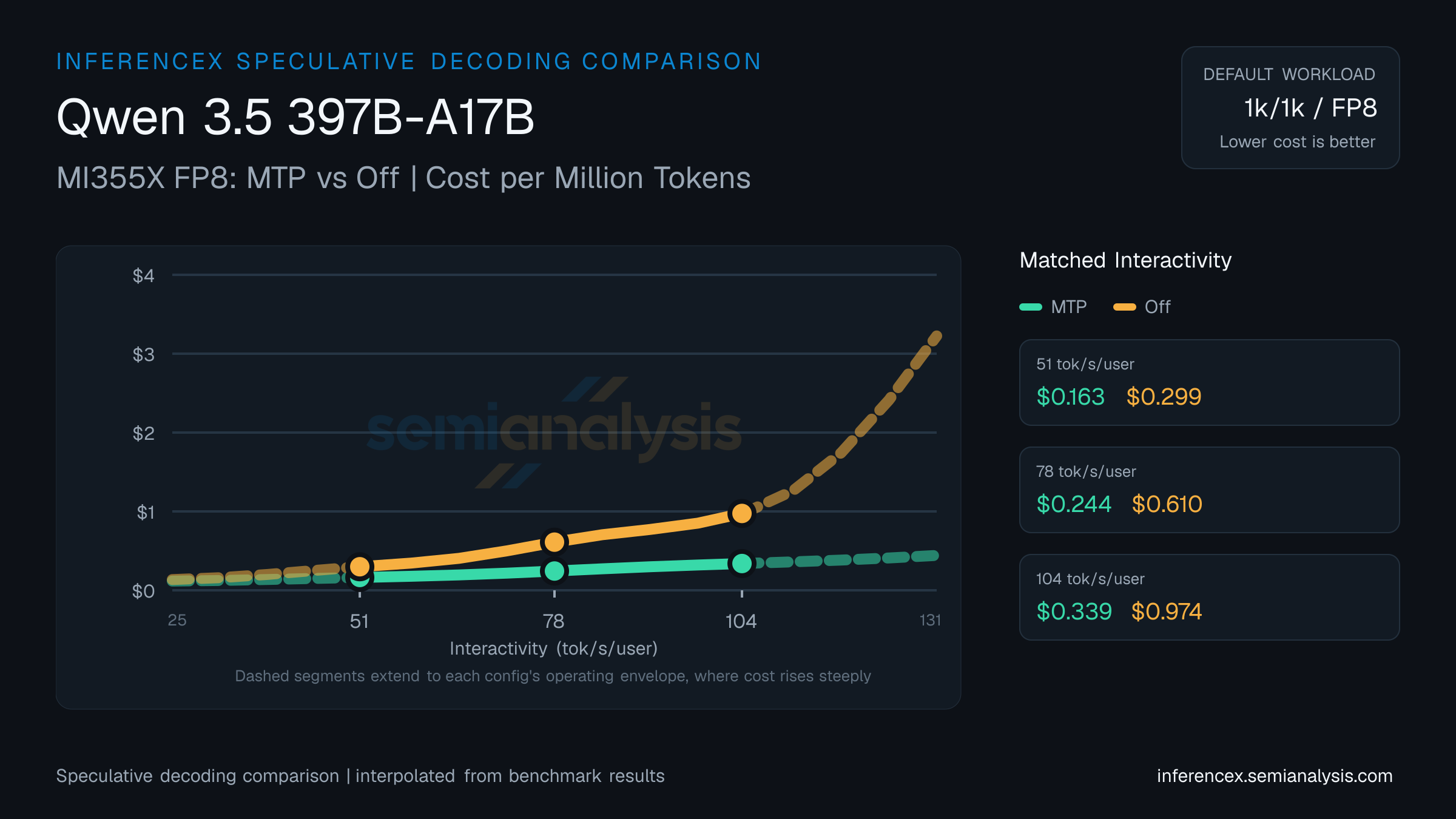
Near the low end of the 25–131 tok/s/user interactivity band, at 51 tok/s/user on Qwen 3.5 397B-A17B (MI355X FP8): MTP runs 2517 tok/s/GPU at $0.16/M tokens, Off runs 1359 at $0.30/M. MTP is 84% cheaper per token; MTP delivers 85% more tok/s/GPU. Gains from speculative decoding vary by workload; short-output prompts tend to benefit less.
At 78 tok/s/user on Qwen 3.5 397B-A17B (MI355X FP8), MTP delivers 1711 tok/s/GPU at $0.24 per million tokens; Off delivers 683 tok/s/GPU at $0.61. MTP is 150% cheaper per token; MTP delivers 150% more tok/s/GPU. Speculative decoding accepts draft tokens to reduce per-token latency — gains vary by workload and prompt distribution.
MTP posts 1183 tok/s/GPU for $0.34 per million tokens at 104 tok/s/user on Qwen 3.5 397B-A17B (MI355X FP8); Off posts 422 tok/s/GPU for $0.97. MTP is 187% cheaper per token; MTP delivers 180% more tok/s/GPU. Draft-token acceptance rates determine whether speculative decoding helps or hurts at a given concurrency level. (Numbers reflect this URL's pinned 1k/1k · fp8 workload — changing sequence or model updates both the table and chart; the table stays pinned to this page's precision, so precision toggles in the controls affect the chart only.)
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | MTP:2517.1Off:1359.4 | MTP:1710.7Off:683.0 | MTP:1182.7Off:421.7 |
| Cost ($/M tok) | MTP:$0.163Off:$0.299 | MTP:$0.244Off:$0.610 | MTP:$0.339Off:$0.974 |
| tok/s/MW | MTP:949848Off:512974 | MTP:645548Off:257728 | MTP:446318Off:159128 |
| Concurrency | MTP:~96Off:~104 | MTP:~44Off:~32 | MTP:~23Off:~9 |
Inference Performance
Inference performance metrics across different models, hardware configurations, and serving parameters.