B200 FP8: MTP vs Off Speculative Decoding
Speculative decoding comparison of MTP versus Off on B200 FP8 (NVIDIA Blackwell) running Qwen 3.5 397B-A17B. Throughput, cost, and interactivity differences across LLM workloads. Use the chart controls below to switch sequences and metrics — same interactions as the main inference chart.
MTP acceptance-rate implementations differ across inference engines. Points from different engines are not directly comparable on the same curve — throughput and cost at matched interactivity may reflect engine-level differences rather than pure speculative decoding gains. Interpret cross-engine comparisons with caution.
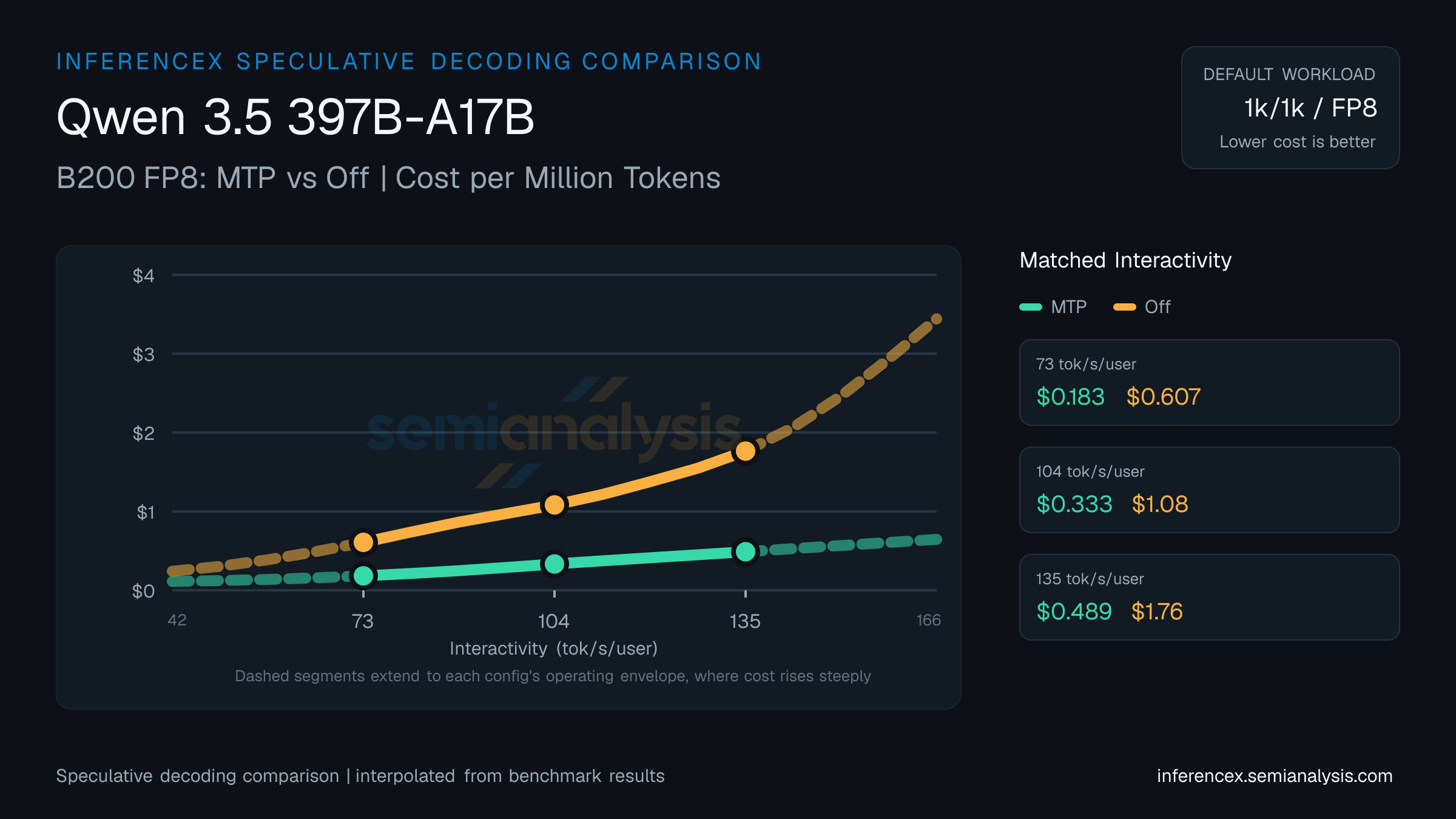
Throughput at 73 tok/s/user on Qwen 3.5 397B-A17B (B200 FP8): MTP hits 2984 tok/s/GPU, Off hits 890. Per-million costs land at $0.18 and $0.61 respectively. MTP is 232% cheaper per token; MTP delivers 235% more tok/s/GPU. Speculative decoding trades extra compute on draft tokens for fewer decoding steps — the payoff depends on sequence length and batch size.
Around the middle of the 42–166 tok/s/user interactivity band, at 104 tok/s/user on Qwen 3.5 397B-A17B (B200 FP8): MTP runs 1640 tok/s/GPU at $0.33/M tokens, Off runs 487 at $1.08/M. MTP is 225% cheaper per token; MTP delivers 236% more tok/s/GPU. Gains from speculative decoding vary by workload; short-output prompts tend to benefit less.
At 135 tok/s/user on Qwen 3.5 397B-A17B (B200 FP8), MTP delivers 1105 tok/s/GPU at $0.49 per million tokens; Off delivers 303 tok/s/GPU at $1.76. MTP is 261% cheaper per token; MTP delivers 264% more tok/s/GPU. Speculative decoding accepts draft tokens to reduce per-token latency — gains vary by workload and prompt distribution. (Numbers reflect this URL's pinned 1k/1k · fp8 workload — changing sequence or model updates both the table and chart; the table stays pinned to this page's precision, so precision toggles in the controls affect the chart only.)
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | MTP:2983.6Off:889.6 | MTP:1640.0Off:487.4 | MTP:1105.5Off:303.4 |
| Cost ($/M tok) | MTP:$0.183Off:$0.607 | MTP:$0.333Off:$1.083 | MTP:$0.489Off:$1.765 |
| tok/s/MW | MTP:1374932Off:409954 | MTP:755773Off:224601 | MTP:509439Off:139809 |
| Concurrency | MTP:~90Off:~25 | MTP:~36Off:~10 | MTP:~18Off:~4 |
Inference Performance
Inference performance metrics across different models, hardware configurations, and serving parameters.