B200: FP4 vs FP8 Precision Comparison
How FP4 and FP8 precision affect GLM 5/5.1 inference on B200 (NVIDIA Blackwell). Throughput, latency, and cost across LLM workloads. Use the chart controls below to switch sequences and metrics — same interactions as the main inference chart.
At 41 tok/s/user on GLM 5/5.1 (B200), FP4 delivers 3136 tok/s/GPU at $0.17 per million tokens; FP8 delivers 1507 tok/s/GPU at $0.36. FP4 is 108% cheaper per token; FP4 delivers 108% more tok/s/GPU. Lower-precision quantization trades model accuracy for throughput — check the evaluation page for quality impact.
FP4 posts 2240 tok/s/GPU for $0.24 per million tokens at 68 tok/s/user on GLM 5/5.1 (B200); FP8 posts 1048 tok/s/GPU for $0.52. FP4 is 114% cheaper per token; FP4 delivers 114% more tok/s/GPU. Quantization-level accuracy differences are tracked on the evaluation tab.
Throughput at 95 tok/s/user on GLM 5/5.1 (B200): FP4 hits 1613 tok/s/GPU, FP8 hits 706. Per-million costs land at $0.34 and $0.77 respectively. FP4 is 128% cheaper per token; FP4 delivers 129% more tok/s/GPU. The cost-throughput tradeoff from lower precision is only part of the picture — see the evaluation page for accuracy data. (Numbers reflect the default 8k/1k selection for this URL — table and chart below update if you change sequence or model in the controls. Each side uses the best available serving configuration for that precision, which may include speculative decoding such as MTP where recipes exist — the same convention as the other comparison pages.)
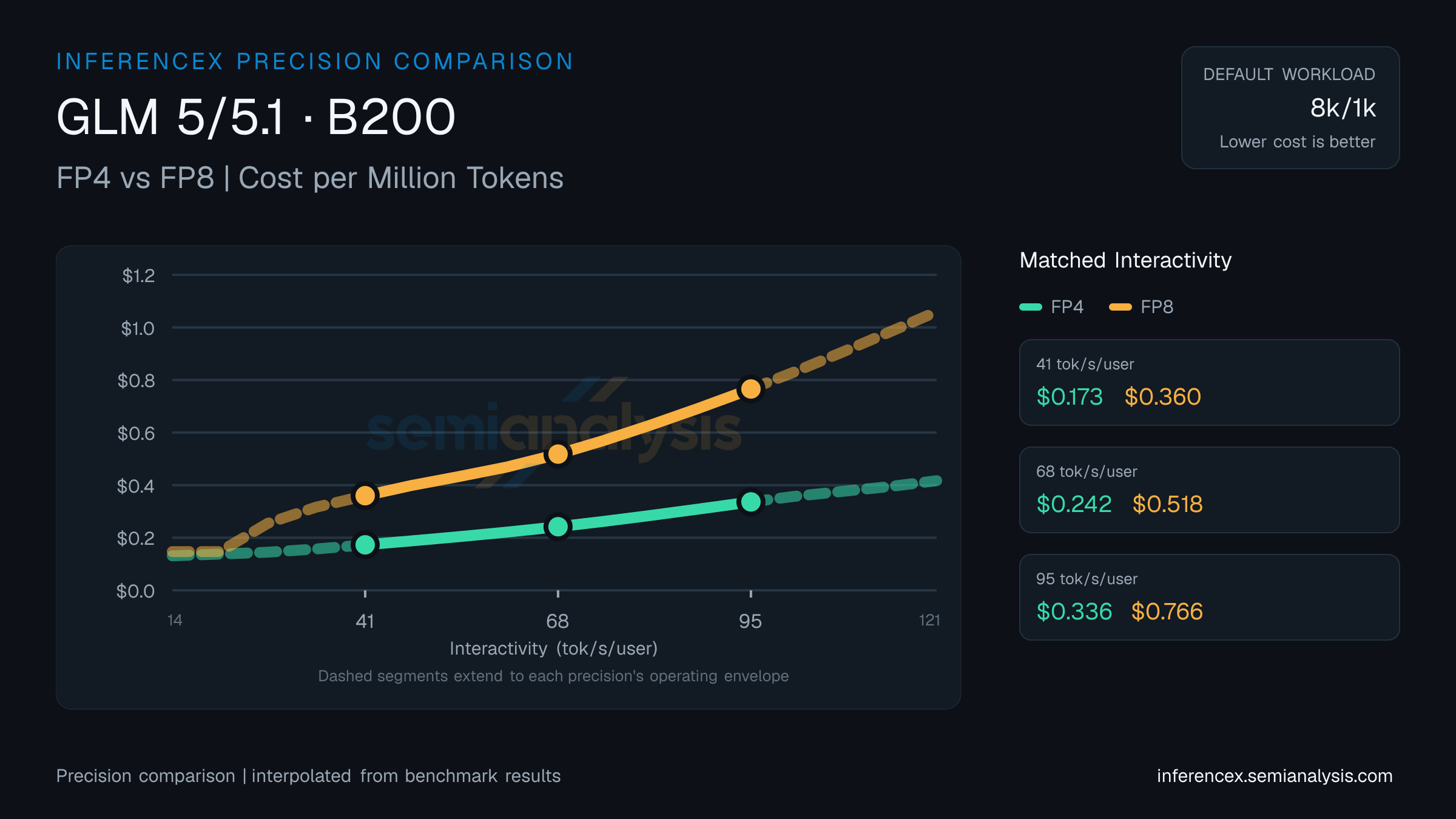
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Throughput (tok/s/gpu) | FP4:3135.7FP8:1507.5 | FP4:2240.1FP8:1047.5 | FP4:1613.4FP8:706.1 |
| Cost ($/M tok) | FP4:$0.173FP8:$0.360 | FP4:$0.242FP8:$0.518 | FP4:$0.336FP8:$0.766 |
| tok/s/MW | FP4:1445043FP8:694691 | FP4:1032326FP8:482732 | FP4:743510FP8:325370 |
| Concurrency | FP4:~35FP8:~58 | FP4:~15FP8:~15 | FP4:~8FP8:~7 |
Inference Performance
Inference performance metrics across different models, hardware configurations, and serving parameters.