Llama 3.3 70B — B200 vs H100 Performance per Dollar
Cost per million tokens of B200 (NVIDIA Blackwell) versus H100 (NVIDIA Hopper) on Llama 3.3 70B. Owning-hyperscaler TCO normalized by output tokens — performance per dollar across LLM workloads. Pick the more cost-efficient SKU at every target interactivity level. Use the chart controls below to switch sequences, precisions, and metrics — same interactions as the main inference chart.
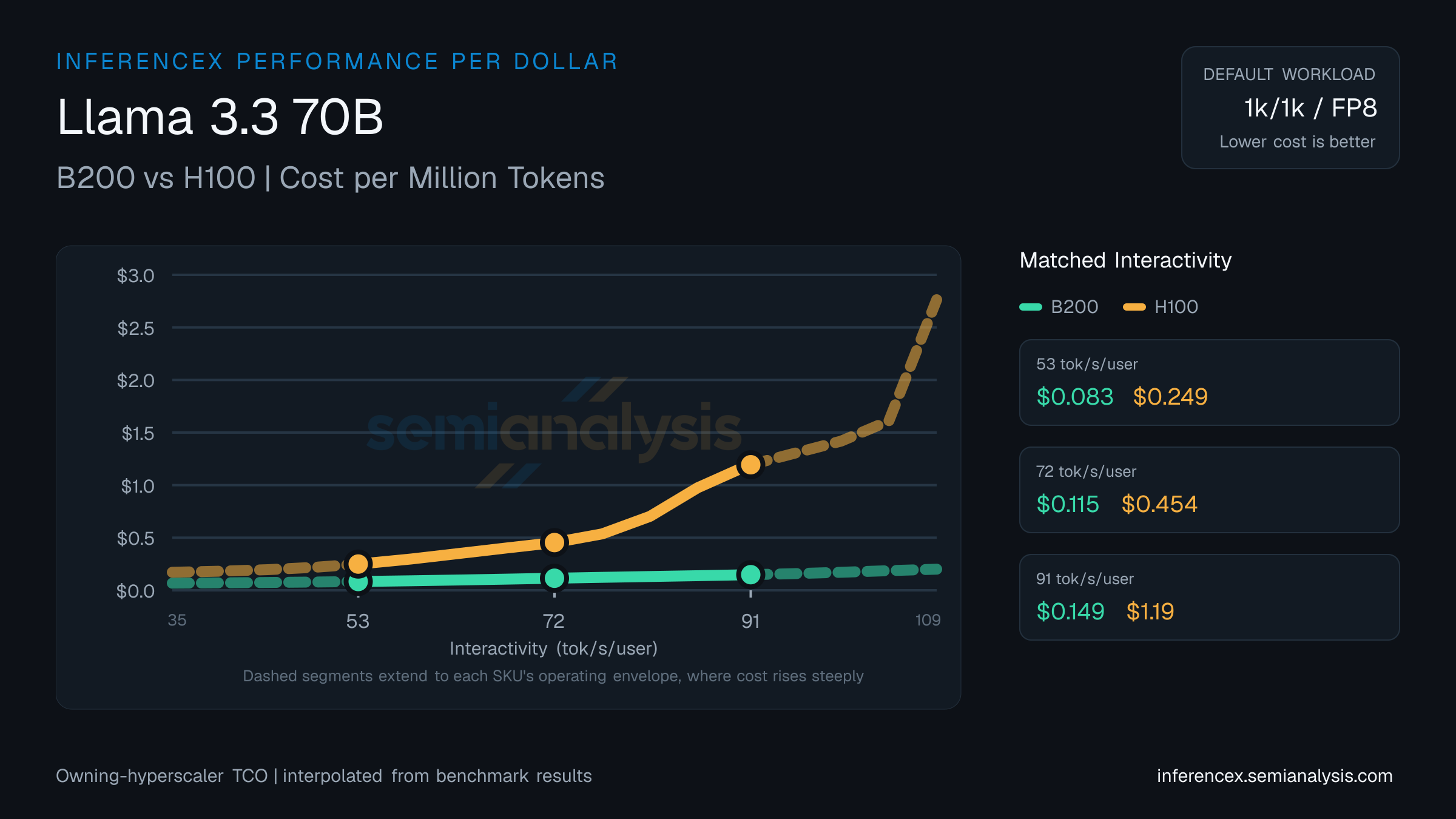
On Llama 3.3 70B at 53 tok/s/user, the per-million math comes out to $0.08 for B200 and $0.25 for H100; B200 delivers 199% more output per dollar.
At 72 tok/s/user on Llama 3.3 70B, B200 costs $0.11 per million tokens; H100 costs $0.45. B200 is 296% more cost-efficient at this operating point.
B200 edges H100 at 91 tok/s/user on Llama 3.3 70B — $0.15 per million tokens versus $1.19, a 704% cost-per-token gap. (Numbers reflect the default 1k/1k · fp8 selection for this URL — table and chart below update if you change sequence, precision, or model in the controls.)
GPU pricing (owning hyperscaler): B200 $1.95/GPU/hr · H100 $1.30/GPU/hr. Source: SemiAnalysis Market August 2025 Pricing Surveys & AI Cloud TCO Model.
| Metric | Interactivity (tok/s/user) | Interactivity (tok/s/user) | Interactivity (tok/s/user) |
|---|---|---|---|
| Dollar per Million Tokens | B200:$0.083H100:$0.249 | B200:$0.115H100:$0.454 | B200:$0.149H100:$1.194 |
| Concurrency | B200:~128H100:~64 | B200:~128H100:~50 | B200:~93H100:~14 |
Inference Performance
Inference performance metrics across different models, hardware configurations, and serving parameters.